

Случайный выбор из конечного множества
Простейшим и наиболее общим типом распределений, необходимым для практики, является распределение целочисленных случайных величин. Чтобы получить случайное целое число x между 0 и k-1 требуется выполнить одно присваивание x=ku, где 0u<1 является выходом датчика равномерно распределенных на [0; 1) случайных величин.
В более общем случае требуется приписать различным целым числам разные веса. Пусть значение x=x1 должно получаться с вероятностью p1 , x=x2 с вероятностью p2, ..., x =xk с вероятностью pk, где p1+p2+...+pk=1. Можно выработать равномерно распределенное на [0; 1) число U и принять
 (15)
(15)
Общие методы для непрерывных распределений
Пусть необходимо получить случайную последовательность, имеющую функцию распределения F(x). Если F(x) непрерывна и строго возрастает (так что F(x1)<F(x2), если x1<x2 ), она принимает все значения между 0 и 1, и существует обратная функция F-1(u), такая, что если 0<u<1, то u=F(x) тогда когда x=F-1(u).
Общий способ вычисления случайной величины X с непрерывной строго возрастающей функцией распределения F(x) заключается в том, что полагают
x=F-1(u). (16)
Поэтому задача сводится к одной из проблем численного анализа для определения хороших методов вычисления F-1(u) с требующейся точностью.
Однако существует ряд важных рациональных приемов, пригодных для ускорения этого общего метода. Например, если X1 и X2 - независимые случайные величины с функциями распределения F1(x) и F2(x), то
-
max(X1, X2) имеет распределение F1(x)F2(x),
-
min(X1, X2) имеет распределение F1(x)+F2(x)–F1(x)F2(x).
Равномерное распределение
Равномерное распределение на полуинтервале [a; b) определяется соотношением
x=a+(b–a)*u. (17)
Нормальное распределение
Нормальное распределение со средним значением, равным 0, и стандартным отклонением, равным 1 можно моделировать с помощью следующего алгоритма:
-
Выработать два независимых случайных числа u1 и u2, равномерно распределенных на [0; 1). Установить v1=2u1–1 и v2=2u2–1.
-
Присвоить S=v12+v22.
-
Если S≥1, то вернуться к шагу 1.
-
Две независимые нормально распределенные случайные величины x1 и x2 получаются из выражений:
![]() . (18)
. (18)
Другой способ получения нормально распределенной величины X с параметрами 0 и 1 основан на центральной предельной теореме:
x=(u1+u2+ ... +u12)–6, (19)
где u1, u2, ..., u12 – независимые равномерно распределенные на [0; 1) случайные величины. Недостатком метода является то, что за пределами =2 ( - среднее, - стандартное отклонение) имеет место сильное расхождение характеристик этого генератора с желаемыми.
Чтобы получить нормально распределенную случайную величину y с параметрами и 2 следует применить преобразование y=+x к нормально распределенной случайной величине x с параметрами =0 и =1.
Экспоненциальное распределение
Для получения экспоненциально распределенной случайной величины x со средним , которое представляет собой время между двумя очередными событиями, следует использовать следующее преобразование (в программах следует избегать случай u=0)
x=-*ln u. (20)
Распределение Пуассона
Оно характеризует число реализаций в единицу времени событий, каждое из которых может произойти в любой момент. Для реализации этого распределения можно использовать следующий алгоритм.
-
Присвоить p=e-, N=0, q=1.
-
Выработать случайное число u, равномерно распределенное на [0; 1).
-
Присвоить q=qu.
-
Если q≥p, то N=N+1 и вернуться на шаг 2. В противном случае N - искомое случайное число.
-
Универсальные и эмпирические тесты для анализа случайных последовательностей.
Универальные тесты
Критерий
χ2.
Предположим, что все возможные результаты
испытаний разделены на k категорий.
Проводится n независимых испытаний
(исход каждого испытания не влияет на
исход остальных). Пусть ps
- вероятность того, что результат
испытания попадет в категорию s,
и пусть Ys
– число испытаний, которые
действительно попали в категорию s.
Сформируем статистику: ![]() (3)
(3)
Формулу (3) можно преобразовать к виду,
более удобному для вычислений:
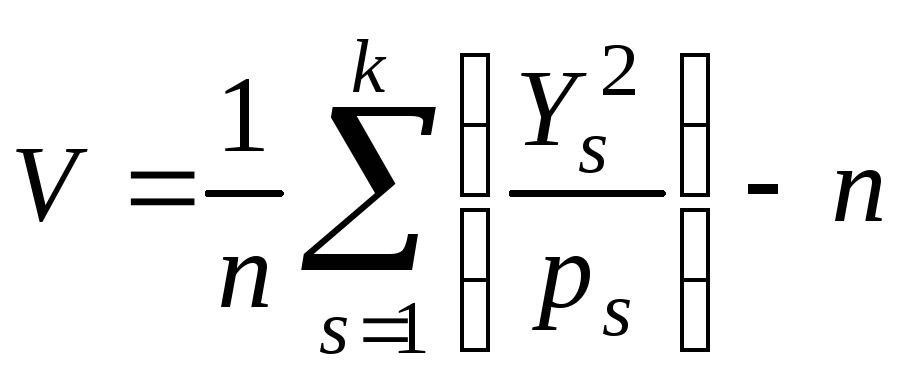 (4)
(4)
Затем V сравнивается с числом из таблицы для распределения 2 при количестве степеней свободы =k–1. Если V меньше значения, соответствующего p=0.99, или больше значения, соответствующего p=0.01, то результаты бракуются как недостаточно случайные. Если p лежит между 0.99 и 0.95 или между 0.05 и 0.01, то результаты считаются "подозрительными". При значениях p, заключенных между 0.95 и 0.90 или 0.10 и 0.05, результаты "слегка подозрительны".
Часто с помощью критерия 2 проверяют по крайней мере три разные части исследуемого ряда чисел. Если не менее двух раз из трех результаты оказываются подозрительными, числа отбрасываются как недостаточно случайные. Возникает вопрос о длине n последовательности случайных чисел, которую необходимо выбрать для данного теста. Теоретические расчеты показывают, что достоверные оценки получаются в том случае, когда в каждую из категорий попали не менее 5 испытаний, т.е. выполняется условие Ys > 4, s=1..k.
Критерий Колмогорова–Смирнова (КС–критерий). Критерий 2 применяется в тех случаях, когда результаты испытаний разделяются на конечное число k категорий. Однако часто случайные величины могут принимать бесконечно много значений. В теории вероятностей и математической статистике непрерывные случайные величины описываются с помощью функции распределения: F(x)=p{Xx} (5)
Используя значения x1,
x2, ..., xn
случайной величины X, можно построить
эмпирическую функцию распределения ![]() (6)
(6)
где
![]() .
.
При увеличении n функции Fn(x) должны все более точно аппроксимировать F(x). КС-критерий можно использовать в тех случаях, когда F(x) не имеет скачков, и он должен указать, насколько маловероятны большие расхождения между Fn(x) и F(x). Для этого используются следующие статистики:
 (7)
(7)
Kn+
показывает, каково максимальное
отклонение для случая Fn>F,
а Kn-
для Fn<F.
Множитель
![]() нормирует статистики (7) таким образом,
чтобы стандартное отклонение не зависело
от n. Далее, как и в случае критерия 2,
сравнивают значения (7) с табличными и
определяют, имеют ли они высокую или
низкую значимость.
нормирует статистики (7) таким образом,
чтобы стандартное отклонение не зависело
от n. Далее, как и в случае критерия 2,
сравнивают значения (7) с табличными и
определяют, имеют ли они высокую или
низкую значимость.
Формулы (7) не годятся для машинных расчетов, так как требуется отыскать максимальное среди бесконечного множества чисел. Однако, учитывая, что F(x) неубывающая функция, а Fn(x) имеет конечное число скачков, можно определить статистики (7) с помощью следующего алгоритма.
-
Определяются выборочные значения x1, x2, ... , xn.
-
Значения xi располагаются в порядке возрастания так, чтобы x1x2...xn.
-
Статистики (7) вычисляются по следующим формулам:
 (8)
(8)
Смешанный критерий (КС–критерий и Критерий χ2)
KС-критерием можно пользоваться в сочетании с критерием 2, чтобы получить лучшую процедуру отбраковки датчиков, чем правило «два подозрительных из трех проверок». Пусть с помощью критерия 2 были независимо обработаны 20 разных участков случайной последовательности, в результате чего были получены значения V1, V2, ..., V20. По этим значениям строится эмпирическая функция F20(x) и сравнивается с теоретической функцией распределения, которую можно получить из таблиц распределения 2. После определения статистик K20+ и K20- формируется окончательное суждение об исходе проверки последовательности с помощью КС-критерия. В результате часто удается выявить как локальные, так и глобальные отклонения от заданного закона распределения.