

Лабораторная работа №6 Факторный анализ
Факторный анализ это процедура, с помощью которой большое число переменных, относящихся к имеющимся наблюдениям, сводится к меньшему количеству независимых влияющих величин, называемых факторами. При этом в один фактор объединяются переменные, сильно коррелирующие между собой. Переменные из разных факторов слабо коррелируют между собой. Таким образом, целью факторного анализа является нахождение таких комплексных факторов, которые как можно более полно объясняют наблюдаемые связи между переменными, имеющимися в наличии.
Первой задачей факторного анализа является выбор взаимодействующих переменных, чья взаимная корреляция обусловливает наибольшую долю общей дисперсии. Эти переменные образуют первый фактор. Затем первый фактор исключается, и из оставшегося множества переменных снова выбираются те, чье взаимодействие определяет наибольшую долю оставшейся дисперсии. Эти переменные образуют второй фактор. Процедура извлечения факторов продолжается до тех пор, пока не будет исчерпана вся общая дисперсия переменных.
Рассмотрим использование факторного анализа для изучения мотивации трудовой деятельности. На материалах анализа данных Всемирного исследования ценностей 1990–1993 гг., В.С. Магун показал, что в сознании людей трудовые ценности образуют определенные сочетания, которые могут быть выявлены с помощью процедуры факторного анализа. В нашем исследовании факторизации было подвергнуто 14 факторов трудовой деятельности работников.
Выберите в меню Analyze (Анализ)/ Data Reduction (Сокращение объема данных)/ Factor... (Факторный анализ). Откроется диалоговое окно Factor Analysis (Факторный анализ) (см. рис. 20). Переменные поместите в поле тестируемых переменных и ознакомьтесь с возможностями, предлагаемыми различными кнопками этого диалогового меню.
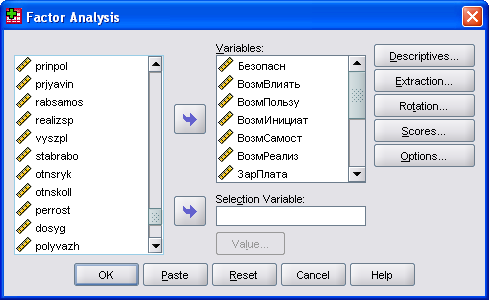
Рис. 20. Вид окна запуска факторного анализа
Зачастую в ходе факторного анализа полученные переменные сложно поддаются интерпретации, тогда будет разумным использовать процедуру вращения. Целью вращения является получение простой структуры, которой соответствует большое значение нагрузок каждой переменной только по одному фактору и малое по всем остальным. Нагрузка отражает связь между переменной и фактором, являясь подобием коэффициента корреляции. Значение нагрузки лежит в пределах от –1 до 1. Идеальная простая структура предполагает, что каждая переменная имеет нулевые значения нагрузок всех факторов кроме одного, для которого нагрузка этой переменной близка к 1 (-1).
Процедура вращения запускается следующим образом. Выключатель Rotation... (Вращение) позволяет выбрать метод вращения. Активируйте метод варимакса и оставьте активированным вывод повёрнутой матрицы факторов (см. рис.21). Если Вы хотите найти значения факторов и сохранить их в виде дополнительных переменных задействуйте выключатель Scores... (Значения) и отметьте Save as variables (Сохранить как переменные).

Рис. 21. Вид окна запуска метода вращения при запуске факторного анализа
После щелчка по кнопке Descriptive Statistics (Дескриптивные статистики) оставьте вывод первичных результатов, которые включают в себя первичные относительные дисперсии простых факторов, собственные значения и процентные доли объяснённой дисперсии (первая часть выведенных результатов). Довольно часто бывает необходим также вывод одномерных статистик и корреляционных коэффициентов (последняя таблица) (см. табл. 8).
Согласно результатам факторного анализа, мы имеем три фактора. Для первого фактора, информативность которого составляет 26% (см. первую часть фрагмента – напротив строки №1), при общей важности всех факторов явно выраженным критерием является возможность проявлять инициативу (коэффициент корреляции 0,79), возможность реализации (0,69), возможность работать самостоятельно (0,69) (см. вторую часть фрагмента: в первом столбце выделены жирным). Мы обозначили данный фактор мотивацией достижения.
Таблица 8.
Фрагмент окна вывода результатов факторного анализа
|
Total Variance Explained | ||||||||||||||
|
Component |
Initial Eigenvalues |
Extraction Sums of Squared Loadings |
Rotation Sums of Squared Loadings | |||||||||||
|
Total |
% of Variance |
Cumulative % |
Total |
% of Variance |
Cumulative % |
Total |
% of Variance |
Cumulative % | ||||||
|
1 |
3,653 |
26,092 |
26,092 |
3,653 |
26,092 |
26,092 |
2,546 |
18,189 |
18,189 | |||||
|
2 |
1,629 |
11,636 |
37,728 |
1,629 |
11,636 |
37,728 |
2,054 |
14,668 |
32,857 | |||||
|
3 |
1,071 |
7,652 |
45,380 |
1,071 |
7,652 |
45,380 |
1,753 |
12,523 |
45,380 | |||||
|
4 |
,978 |
6,988 |
52,368 |
|
|
|
|
|
| |||||
|
5 |
,959 |
6,850 |
59,217 |
|
|
|
|
|
| |||||
|
6 |
,841 |
6,010 |
65,227 |
|
|
|
|
|
| |||||
|
7 |
,786 |
5,612 |
70,839 |
|
|
|
|
|
| |||||
|
8 |
,742 |
5,300 |
76,139 |
|
|
|
|
|
| |||||
|
9 |
,654 |
4,673 |
80,812 |
|
|
|
|
|
| |||||
|
10 |
,612 |
4,373 |
85,185 |
|
|
|
|
|
| |||||
|
11 |
,573 |
4,093 |
89,278 |
|
|
|
|
|
| |||||
|
12 |
,539 |
3,851 |
93,129 |
|
|
|
|
|
| |||||
|
13 |
,515 |
3,677 |
96,806 |
|
|
|
|
|
| |||||
|
14 |
,447 |
3,194 |
100,000 |
|
|
|
|
|
| |||||
|
Rotated Component Matrixa |
| |||||||||||||
|
|
Component |
| ||||||||||||
|
|
1 |
2 |
3 |
| ||||||||||
|
Безопасность работы |
0,067 |
0,347 |
0,360 |
| ||||||||||
|
Возможность влиять на работу предприятия |
0,661 |
0,211 |
-0,114 |
| ||||||||||
|
Возможность приносить пользу обществу |
0,496 |
0,434 |
-0,115 |
| ||||||||||
|
Возможность проявлять инициативу |
0,787 |
0,112 |
0,022 |
| ||||||||||
|
Возможность работать самостоятельно |
0,685 |
0,010 |
0,186 |
| ||||||||||
|
Возможность творческой реализации |
0,693 |
0,092 |
0,265 |
| ||||||||||
|
Высокая зарплата |
0,057 |
-,008 |
0,687 |
| ||||||||||
|
Надёжность |
-,033 |
0,109 |
0,635 |
| ||||||||||
|
Отношения с руководителями |
0,123 |
0,402 |
0,466 |
| ||||||||||
|
Отношения с коллегами |
-0,022 |
0,550 |
0,331 |
| ||||||||||
|
Перспективы профессионального роста |
0,364 |
0,141 |
0,446 |
| ||||||||||
|
Работа дает много времени для досуга |
0,035 |
0,518 |
0,297 |
| ||||||||||
|
Работа пользуется уважением в обществе |
0,177 |
0,700 |
0,038 |
| ||||||||||
|
Содержание работы |
0,325 |
0,652 |
-0,044 |
| ||||||||||
Для второго фактора (составляет 12% дисперсии) наиболее значимыми являются такие характеристики, как отношения с коллегами (0,55), работа вызывает уважение (0,7), содержание работы (0,65). Мы условно обозначили данный тип - мотивацией сохранения. Для третьего фактора (8%)значимыми являются такие переменные, как высокая зарплата, надежность места работы. Этот тип мотивации можно охарактеризовать как пассивная мотивация.
Задание 1
1. Откройте базу данных «Мотив. sav». Проведите факторный анализ переменных важности основных аспектов труда (VAR 257-298). Для этого необходимо сначала создать переменные, соответствующие каждому аспекту труда, присваивая шкальные значения ответам: «важно» - 3, «важно отчасти» - 2, «не важно» - 1. Должно получиться 14 переменных.
2. Проанализировать получившуюся матрицу факторных нагрузок. Охарактеризуйте каждый из выделенных факторов.
3. Провести вращение факторов (кнопка ROTATION в диалоговом окне, тип вращения – VARIMAX). Дать интерпретацию факторам. Сохранить факторы в файле в виде переменных (кнопка SCORES в диалоговом окне, SAVE AS VARIABLES).
Задание 2
По результатам факторного анализа было выделено несколько основных типов поведения работников. Каждому типу соответствует выделенный программой фактор. Необходимо:
Построить регрессионную модель каждого фактора (в качестве переменных используются сохраненные переменные по результатам факторного анализа после вращения).
Интерпретировать полученные результаты, описать каждый тип поведения.
Выбрать определенную выборку респондентов (например, работники определенной сферы занятости, работники определенного возраста, работники с разным уровнем дохода). Построить регрессионные модели поведения этих работников. Проинтерпретировать полученный результат.
Лабораторная работа №7
Дисперсионный анализ
С помощью дисперсионного анализа исследуют влияние одной или нескольких независимых переменных на одну зависимую переменную (одномерный анализ) или на несколько зависимых переменных (многомерный анализ). Методов применения дисперсионного анализа в программе достаточно много, остановимся на одном, традиционном "классическом" методе Фишера. Такой анализ выполним за счёт использования процедуры ANOVA. Но сначала напомним о правиле сложения дисперсии.
Правило сложения дисперсий
В статистическом исследовании очень часто бывает необходимо не только изучить вариации признака по всей совокупности, но и проследить количественные изменения признака по однородным группам совокупности, а также и между группами. Следовательно, помимо общей средней для всей совокупности необходимо просчитывать и частные средние величины по отдельным группам.
Различают следующие виды дисперсии. Общая дисперсия измеряет всю вариацию признака под влиянием всех факторов (3) :
![]() (3)
(3)
Межгрупповая дисперсия характеризует систематическую вариацию, т.е. различия в величине изучаемого признака, возникающие под влиянием признака – фактора, положенного в основании группировки (4).
![]() (4),
(4),
где
![]() - средняяi
– той группы,
- средняяi
– той группы,
![]() - общая средняя признака x,
- общая средняя признака x,
![]() - частотаi-той
группы.
- частотаi-той
группы.
Внутригрупповая дисперсия отражает случайную вариацию, т.е. часть вариации, происходящую под влиянием неучтенных факторов. Данная дисперсия рассчитывается отдельно для каждой группы по формуле (5). Далее вычисляется средняя из внутригрупповых дисперсий, как средневзвешенная величина с учетом частоты каждой группы (5).
![]() (5)
(5)
Согласно правилу сложения дисперсий, общая дисперсия, возникающая под влиянием всех факторов, равна сумме дисперсий, возникающих под влиянием случайных факторов и дисперсии, возникающей за счет группировочного фактора (6).
![]() (6)
(6)
В SPSS дисперсионный анализ реализуется следующим образом.
Analyze (Анализ) / Compare Means One-Way-ANOVA (рис.22) Откроется диалоговое окно дисперсионного анализа.

Рис. 22. Вид окна запуска дисперсионного анализа
Таблица 9.
Результат запуска дисперсионного анализа
|
Вопрос: «Насколько Вы одобряете деятельность Президента» ANOVA | ||||||
|
|
|
Sum of Squares |
Df |
Mean Square |
F |
Sig. |
|
Председателя Правительства РФ В.Путина |
Between Groups |
2264,984 |
5 |
452,997 |
496,198 |
,000 |
|
Within Groups |
1363,926 |
1494 |
,913 |
|
| |
|
Total |
3628,909 |
1499 |
|
|
| |
|
Пол |
Between Groups |
3,767 |
5 |
,753 |
3,071 |
,009 |
|
Within Groups |
366,529 |
1494 |
,245 |
|
| |
|
Total |
370,296 |
1499 |
|
|
| |
|
Образование |
Between Groups |
31,138 |
5 |
6,228 |
4,025 |
,001 |
|
Within Groups |
2311,691 |
1494 |
1,547 |
|
| |
|
Total |
2342,829 |
1499 |
|
|
| |
|
Что бы Вы могли сказать о своем настроении в последние дни? |
Between Groups |
49,618 |
5 |
9,924 |
10,468 |
,000 |
|
Within Groups |
1416,318 |
1494 |
,948 |
|
| |
|
Total |
1465,936 |
1499 |
|
|
| |
|
Политическая обстановка в России |
Between Groups |
191,615 |
5 |
38,323 |
36,733 |
,000 |
|
Within Groups |
1558,662 |
1494 |
1,043 |
|
| |
|
Total |
1750,277 |
1499 |
|
|
| |
Для анализа результатов дисперсионного анализа сравнивают межгрупповую и внутригрупповую дисперсии. Если внутригрупповая дисперсия больше межгрупповой, то изменчивость факторов объясняется не группировочным, а иными признаками. В нашем примере только в первом случае (верхняя часть таблицы) внутригрупповая дисперсия больше межгрупповой. Следовательно, группы респондентов, ответившие по-разному на первый вопрос таблицы, являются наиболее значимыми при распределении ответов по вопросу одобрения оценки Президента, а вот разные группы половозрастные и по настроению практически не значимы.
Задание
Откройте базу OBL1011A.SAV.
Проведите дисперсионный анализ по вопросам одобрения Президента и Председателя Правительства.
Проведите дисперсионный анализ по вопросам одобрения Президента с вопросами социально-демографических и экономических характеристик – пол, возраст, оценка экономической обстановки в России, оценка политической обстановки.
Для подтверждения результатов дисперсионного анализа сделайте таблицы сопряженности между вопросами одобрения Президента и одобрения Председателя Правительства, оценкой экономической обстановки и политической обстановки.
Проведите корреляционный анализ между вопросами одобрения Президента и Председателя Правительства.
Сделайте выводы по результатам анализа.
Итоговая контрольная работа по 1 разделу.
Заведите данные таблицы (см. табл.10) в программу. Для этого необходимо сначала прописать переменные в листе переменных.
Отсортируйте данные по мере возрастания дохода.
Используя описательную статистику, получите распределение ответов по каждой переменной. Определите, используя меры средней тенденции описательной статистики: средний возраст респондентов, максимальный и минимальный доход респондентов, моду доходов.
Создайте новую переменную: доход. При помощи переменной сгруппируйте всех респондентов на три доходные группы. Постройте диаграмму по созданной переменной в программе Excel.
Создайте переменную возраст: разбейте респондентов на нужное количество групп, аргументируйте вашу классификацию. Постройте диаграмму по созданной переменной в программе Excel.
Таблица 10.
Результаты опроса респондентов
|
№ респондента |
Пол |
Возраст |
Доход в месяц, тыс. руб. |
Предпочитаю покупать |
В упаковке(да) или нет |
Какой цвет упаковки Вы любите |
|
1 |
мужской |
21 |
15 |
розы |
да |
синий |
|
2 |
мужской |
25 |
18 |
гвоздики |
да |
белый |
|
3 |
мужской |
30 |
25 |
хризантемы |
да |
розовый |
|
4 |
женский |
45 |
18 |
тюльпаны |
нет |
красный |
|
5 |
мужской |
65 |
4 |
гвоздики |
нет |
голубой |
|
6 |
мужской |
18 |
12 |
хризантемы |
нет |
синий |
|
7 |
женский |
19 |
2 |
тюльпаны |
Нет |
Голубой |
|
8 |
женский |
21 |
6 |
тюльпаны |
Нет |
красный |
|
9 |
женский |
35 |
35 |
розы |
Да |
розовый |
|
10 |
мужской |
45 |
22 |
хризантемы |
Да |
розовый |
|
11 |
мужской |
55 |
5 |
гвоздики |
да |
красный |
|
12 |
мужской |
67 |
6 |
гвоздики |
нет |
синий |
|
13 |
мужской |
32 |
29 |
розы |
да |
Синий |
|
14 |
женский |
42 |
30 |
розы |
да |
Синий |
|
15 |
мужской |
18 |
18 |
гвоздики |
нет |
голубой |
|
16 |
мужской |
33 |
25 |
розы |
да |
Голубой |
|
17 |
женский |
24 |
15 |
хризантемы |
да |
красный |
|
18 |
женский |
46 |
15 |
хризантемы |
да |
красный |
|
19 |
женский |
54 |
24 |
гвоздики |
да |
Голубой |
|
20 |
мужской |
32 |
46 |
розы |
да |
розовый |
|
21 |
мужской |
71 |
8 |
хризантемы |
нет |
розовый |
|
22 |
женский |
35 |
32 |
розы |
нет |
красный |
|
23 |
женский |
31 |
15 |
хризантемы |
нет |
Голубой |
|
24 |
женский |
43 |
18 |
хризантемы |
нет |
Синий |
|
25 |
мужской |
51 |
10 |
гвоздики |
нет |
розовый |
|
26 |
мужской |
19 |
6 |
хризантемы |
нет |
красный |
|
27 |
женский |
16 |
3 |
хризантемы |
нет |
Синий |
|
28 |
мужской |
25 |
14 |
хризантемы |
да |
Синий |
|
29 |
мужской |
34 |
32 |
розы |
да |
красный |
|
30 |
женский |
32 |
19 |
хризантемы |
да |
розовый |
Используя операторы условия, отберите мужчин с доходом выше 20 тыс. рублей и покажите распределение ответов по вопросу о выбранных цветах (розы, тюльпаны и т.д.).
Выберите женщин с этим же уровнем дохода и посмотрите, как они выбирают цветы, сравните с предыдущей категорией.
Используя таблицы сопряженности, посмотрите, есть ли закономерности:
- между полом респондента и доходом (доход по новой переменной, чтобы сравнивать было легче);
- между доходом и выбираемыми цветами;
- между доходом и выбором упаковки;
- между возрастом и доходом;
- между выбором цветов и цветом упаковки
В процессе выполнения заданий записывайте ход ваших действий и полученный результат.
Итоговая контрольная работа по 2 разделу.
Рассчитать индексы одобрения деятельности президента, председателя правительства, губернатора Вологодской области. Для выполнения задания создайте переменные: значениям «полностью одобряю» придайте значение «2», «в основном одобряю» - «1», «в основном не одобряю» «-1», «полностью не одобряю» - «-2», затрудняюсь ответить» - «0». После создания переменных запустите описательную статистику и выберите в опции статистик среднюю величину. Программа выведет вам среднее значение индекса по всей базе.
Проверьте правильность рассчитанного индекса в программе Excel. Для этого скопируйте результаты запуска описательной статистики по вопросам одобрения президента и председателя правительства в Excel и рассчитайте при помощи средневзвешенной величины индексы одобрения.
Изобразите графически в программе Excel распределение ответов по одобрению по разным демографическим группам (пол, возраст). Используйте мастер диаграмм и столбиковые диаграммы.
Посмотрите, насколько взаимосвязаны ответы на вопросы по одобрению между собой двумя способами:
- при помощи коэффициента корреляции;
- при помощи таблиц сопряженности.
Посмотрите взаимосвязи между ответами на вопросы:
- «Какая из приведенных ниже оценок характеризует ваши доходы?»;
- «К какой категории вы себя относите?»;
- «Если говорить о крупных покупках для дома, сейчас хорошее или плохое время для их покупки?»;
6. Проведите дисперсионный анализ по всем вопросам предыдущего задания.
Вопросы для самостоятельной работы
Критерий знаков: теория и компьютерные вычисления.
Критерий Стьюдента для связанных выборок: теория и компьютерные вычисления.
Критерий Стьюдента для анализа независимых нормальных выборок.
Критерий Вилкоксона для анализа произвольных выборок.
Таблицы сопряженности и критерий «хи-квадрат» К. Пирсона.
Коэффициенты корреляции Пирсона и Спирмена.
Однофакторный дисперсионный анализ: теория и методы компьютерного вычисления.
Непараметрический однофакторный анализ: критерии Краскелла-Уоллиса и Фридмана.
Методы оценивания параметров регрессионной модели (МНК-оценки, ММП-оценки).
Теорема Гаусса-Маркова для МНК-оценок. Геометрическая интерпретация МНК. Методы проверки адекватности модели.
Задача множественной регрессии и ее геометрическая интерпретация.
Алгоритм шаговой регрессии. Частные коэффициенты корреляции: постановка задачи, теория и методы компьютерного вычисления.
Анализ социально-экономических показателей с помощью множественной регрессии.
Итоговая самостоятельная работа
Расчет Индекса Потребительских настроений
Изучение динамики ИПН в России дает возможность макроэкономического анализа влияния конечных потребителей (населения) на развитие экономики (в этом состоит основная цель расчетов таких показателей), позволяет количественно описать процессы формирования рыночного сознания и потребительского поведения.
Частные индексы предназначены для изучения и оценки мнения населения по отдельным социально-экономическим аспектам общественной жизни. ИПН (и его составляющие) рассчитывается в процентах (из доли положительных ответов вычитается доля отрицательных), затем к полученному значению прибавляется 100, чтобы не иметь отрицательных величин. Таким образом, полностью отрицательные ответы дали бы общий индекс 0, сплошь положительные – 200, равновесие первых и вторых – индекс 100, являющийся, по сути, нейтральной отметкой.
ИПН (индекс потребительских настроений) рассчитывается как средний из частных индексов по вопросам о произошедших и ожидаемых изменениях личного материального положения, ожидаемых изменениях экономической ситуации в стране на краткосрочную и долгосрочную перспективы, благоприятности условий для крупных покупок.
ИТС (индекс текущего состояния) рассчитывается как средний из двух частных индексов: индекса текущего личного материального положения и индекса целесообразности приобретения товаров длительного пользования.
ИПО (индекс потребительских ожиданий) рассчитывается как средний из трех частных индексов: индекса ожиданий изменения личного материального положения, индекса перспектив развития экономики страны в ближайший год и индекса перспектив развития экономики страны в ближайшие 5 лет.
Задание
1. Откройте базу OBL1011A.SAV. Определите одномерное распределение по вопросам, относящимся к индексу потребительских отношений. В базе они имеют имена ipn1, ipn2 и т.д.:
1). Как изменилось материальное положение Вашей семьи за последние 6 мес.? (ipn1)
2). Как изменится материальное положение Вашей семьи в предстоящие 6 мес.? (ipn 3)
3) Если говорить об экономических условиях в стране в целом, как Вы считаете, следующие 12 мес. будут для экономики страны хорошим временем или плохим, или каким-либо еще? (ipn 201)
4) Если говорить о следующих 5 годах, то они будут для экономики страны хорошим или плохим временем? (ipn 4)
5) Если говорить о крупных покупках для дома, то как Вы считаете, сейчас в целом хорошее или плохое время для того, чтобы делать такие покупки? ( ipn5)
2. Перенесите данные в Excel. Рассчитайте ИПО, ИТС и ИРН по предложенной методике. Изобразите графически распределение ИПН.
3. При помощи функции создать переменную найдите частные индексы по каждому респонденту и через опцию «среднее» в описательной статистике выведите результаты. Сравните с результатами расчета в Excel.
4. Рассчитайте ИПН и частные индексы у разных социально-демографических и по материальному положению группах. Сделайте выводы.
Вопросы к зачету
Описание интерфейса программы. Структура программы. Вход в программу. Создание новой базы данных. Заполнение листа описания переменных. Типы переменных. Ограничения ввода переменных. Метки переменных. Пропуски. Ввод данных.
Ввод данных для множественных ответов. Таблицы сопряженности для множественных ответов.
Организация описательной статистики. Алгоритм запуска описательной статистики. Составление одномерных таблиц распределения. Меры средней тенденции: среднее, мода, медиана, сумма. Показатели ряда распределения и вариации данных: дисперсия, среднее квадратическое отклонение, минимальное и максимальное значения.
Работа с базой данных. Составление фильтров анализа. Отбор данных. Использование математических и логических операторов. Сортировка данных по одной переменной, сортировка данных по нескольким переменным.
Таблицы сопряженности. Двухмерное распределение ответов. Применение. Алгоритм составления в программе. Расчет реальной и ожидаемой величины. Расчет стандартизированных и нестандартизированных остатков. Составление расчетных значений по столбцу, по строке и базе в целом. Составление трехмерного распределения.
Корреляционный анализ, расчет коэффициентов Спирмена и Пирсона, интерпретация данных. Задачи корреляционного анализа. Коэффициенты корреляции, их математический смысл.
Составление математической модели на основе корреляционно-регрессионного анализа. Пример из социологии.
Факторный анализ. Задачи факторного анализа. Применение редукции данных. Пример из социологии, экономической социологии и психологии. Алгоритм построения факторного анализа в программе.
Анализ полученных факторов. Математический смысл факторов. Процедура вращения переменных методом главных компонент, методом варимакс. Сохранение полученных в результате факторного анализа переменных.
Дисперсионный анализ. Задачи дисперсионного анализа. Алгоритм запуска дисперсионного анализа в программе. Расшифровка полученных данных. Рассмотрение примера из социологии.
ЛИТЕРАТУРА
Основная
Анализ данных на компьютере/ Под редакцией В.Е.Фигурнова.- 3-е изд., перерад. И доп. – М.: ИНФРА-М, 2003. – 544 с
Бююль А., Цефель П. SPSS/ Искусство обработки информации, анализ статистических данных, восстановление скрытых закономерностей. М.: DiaSoft., 2002.
Наследов А.Д. SPSS: Компьютерный анализ данных в психологии и социальных науках. – СПб.: Питер, 2005. – 416 с.
Дополнительная литература
1. Бестужев-Лада И.В. Социальное прогнозирование. Курс лекций. М.: Педагогическое общество России. 2002.
2. Громыко Г.Л. Общая теория статистики: Практикум. - М.: 2000. - 139 с.
3. Давыдов А.А. Анализ одномерных частотных распределений в социологии: эволюция подходов// Социс. - 1995. - № 5. - С.113-116.
4. Давыдов А.А. Интервальный анализ социальных систем// Социс. - 1997. - № 1. - С.106-109.
5. Давыдов А.А., Чураков АН. Модульный анализ и моделирование социума. М., 2000.
6. Котляревский Ю.Л. Игротехническая культура: предметные реалии и рефлексивное восхождение// Социс. - 1995. - № 2. - С.105-117.
7. Толстова. Ю.Н. Анализ социологических данных. М.: Научный мир, 2000.
Оглавление
Введение …………………………………………………………………3
Учебно-методическая карта дисциплины………………………………6
Темы лекционных занятий……………………………………………….6
Задания для лабораторных работ ……………………………………….8
Вопросы для самостоятельной работы………………………………...60
Вопросы к зачету…………………………………………………………63
Литература……………………………………………….………………..65