

Отбор данных
Отбор данных — это выбор наблюдений по определенным критериям; так, например, при опросе работников предприятия можно отобрать только специалистов - мужчин определенного возраста, а при опросе по уровню жизни только тех, кто относит себя к среднему классу. После этого все вычисления будут проводиться только с этими отобранными наблюдениям.
Для этого в SPSS существует три принципиальные возможности:
1. Выбор наблюдений по определенному условию
2. Извлечение случайной выборки наблюдений из файла данных.
3. Разделение наблюдений на группы в соответствии со значениями одной или нескольких переменных.
Выбор наблюдений
Проведем частотный анализ вопроса по оценке экономического положения страны вологжанами. При этом мы будем учитывать только респондентов-женщин. Поступите следующим образом: выберите в меню команды Data (Данные)/ Select Cases (Выбрать наблюдения). Откроется диалоговое окно Select Cases (см. рис. 5).

Рис. 5. Вид окна отбора данных
По умолчанию в этом диалоге выбран пункт All cases (Все наблюдения). Выберите пункт If condition is satisfied (Если выполняется условие) и щелкните на кнопке If... (Если). Откроется диалоговое окно Select Cases: If
Это диалоговое окно разделено на следующие части (см. рис. 6): список исходных переменных (содержит переменные, содержащиеся в открытом файле данных); редактор условий (здесь записывается логическое выражение, по которому должны быть отобраны наблюдений); клавиатура (содержит цифры, а также арифметические, логические операторы и операторы отношения); список функций (содержит около 140 функций).
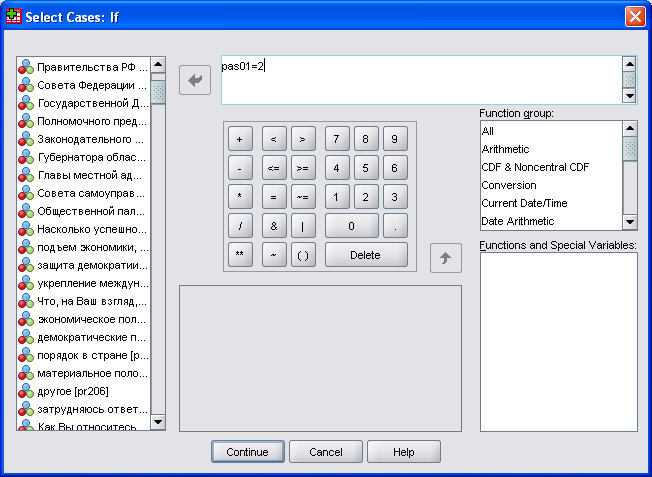
Рис. 6. Вид окна написания условия для отбора данных
Классификация операторов
Обратим внимание на операторы, используемые для написания условий. Операторы делятся на арифметические, логические и операторы отношения. Арифметические операторы применяются в так называемых арифметических выражениях (математических формулах), которые при отборе данных имеют лишь второстепенное значение. Арифметические операторы всегда можно использовать в логических выражениях, однако это встречается нечасто. Решающую роль эти операторы играют при модификации данных.
Логические операторы и операторы отношения применяются исключительно в логических выражениях. Для построения условных выражений могут применяться следующие логические операторы: «&» - логическое И, «|» - логическое ИЛИ, «~» - логическое НЕ.
Операторы отношения. Отношение — это логическое выражение, в котором два значения сравниваются друг с другом посредством оператора отношения. Для построения логических выражений могут применяться следующие операторы отношения:«<» - меньше, « >» - больше, «<=» - меньше или равно, « >=» - больше или равно, « =» - равно, «~=» - не равно. Операторы можно ввести в редактор условий либо щелкнув в диалоговом окне на кнопке с соответствующим знаком, либо введя с клавиатуры альтернативный текст.
Приведем пример отбора респондентов. Отберем только женщин. Выполните следующие действия: перенесите переменную pas01 (вопрос о поле респондента) в редактор условий, дважды щелкнув на ней или выделив ее и щелкнув на кнопке с треугольником. Щелкните на кнопке со знаком равенства на клавиатуре. Этот знак будет скопирован в редактор условий. Щелкните на кнопке 2 на клавиатуре. Знак будет скопирован в редактор условий. Подтвердите выбор кнопкой Continue (Продолжить). Щелкните на кнопке ОК. Вы снова окажетесь в редакторе данных. Теперь фильтрация наблюдений включена.
О том, что отбор, заданный с помощью диалоговых окон, осуществлен, свидетельствует сообщение Filter on (Фильтр включен), которое появляется в строке состояния в нижней части окна SPSS. Система создает переменную filter_$. Она имеет следующие метки значений: 0 = Not Selected (Не выбрано), 1 = Selected (Выбрано). При всех последующих операциях будут учитываться только наблюдения, для которых значение этой переменной равно 1, то есть те, для которых выполняется наше условие. Номера неотобранных наблюдений отображаются зачеркиванием в левом крае редактора данных.
Обратите внимание, что фильтр действует и при остальных статистических процедурах. Команда SPSS SELECT IF или соответствующие настройки в диалоговых окнах фильтруют наблюдения постоянно, то есть до тех пор, пока фильтр не будет удален или деактивирован. Чтобы удалить фильтр, поступите следующим образом. Щелкните на имени переменной filter_$. Весь столбец будет выделен. Нажмите клавишу <Backspace>. Переменная фильтра будет удалена.
Если требуется не удалять фильтр, а лишь временно деактивизировать его, выполните следующие действия. Выберите в меню команды Data (Данные) / Select Cases... (Выбрать наблюдения). В диалоговом окне Select Cases щелкните на кнопке All cases (Все наблюдения). Условие фильтра будет деактивировано, однако переменная filter_$ сохранится. В любой момент ее можно будет активизировать снова.
Извлечение случайной выборки
При большом количестве наблюдений для экономии времени может быть полезно использовать небольшую случайную выборку при первой предварительной проверке гипотезы. Чтобы извлечь случайную выборку из совокупности всех наблюдений, выполните следующие действия:
Выберите в меню Data (Данные)/ Select Cases... (Выбрать наблюдения)/ Random sample of cases (Случайная выборка), а затем щелкните на кнопке Sample... (Выборка). Откроется диалоговое окно Select Cases: Random Sample (Выбрать наблюдения: Случайная выборка).
В группе Sample Size (Размер выборки) можно выбрать один из следующих способов определения объема выборки (см. рис. 7).

Рис.7. Вид меню выбора объема случайной выборки
Approximately (Приблизительно): Пользователь может указать здесь процентное значение. SPSS создаст случайную выборку с объемом, приблизительно соответствующим указанному проценту наблюдений.
Exactly (Точно): Пользователь должен указать здесь точное количество наблюдений в случайной выборке. Кроме того, здесь надо задать количество наблюдений, из которых будет извлечена выборка. Второе число не должно превышать общего количества наблюдений в файле данных.
Сортировка наблюдений
Данные в SPSS можно сортировать в соответствии со значениями одной или нескольких переменных. Рассмотрим следующий пример: Требуется упорядочить данные файла по возрасту. Для этого поступите следующим образом:
Выберите в меню команды Data (Данные)/ Sort Cases... (Сортировать наблюдения). Откроется диалоговое окно Sort Cases. Переменные файла данных будут отображены в списке исходных переменных. Перенесите переменную «возраст» в список Sort by (Сортировать по). В группе Sort order (Порядок сортировки) по умолчанию выбран вариант Ascending (По возрастанию). Эта опция сортирует наблюдения в порядке возрастания значения переменной сортировки, а следующая опция, Descending — в порядке убывания. Подтвердите настройки кнопкой ОК. В редакторе данных файл будет отсортирован по возрастанию значений переменной.
Разделение наблюдений на группы
В SPSS можно выполнять анализ данных раздельно по группам. Группой в этом контексте называется определенное количество наблюдений с одинаковыми значениями признаков. Такой переменной может быть, например, переменная «пол» или «возраст». В этом случае все переменные со значением признака 1 (женский) образуют одну группу, а все переменные со значением признака 2 (мужской) — другую группу. С каждой группой можно проводить определенные операции, например, выполнять частотный анализ. При этом частотный анализ проводится раздельно для признаков мужской и женский.
Проведем частотный анализ вопроса по настроению раздельно по мужчинам и женщинам. Выберите в меню команды Data (Данные)/ Split File... (Разделить файл). Откроется диалоговое окно Split File (см. рис. 8).
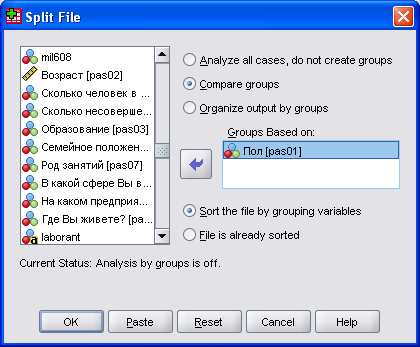
Рис. 8. Вид окна разделения файла
По умолчанию разделение на группы не предполагается. Если выбрать пункт Organize output by groups (Разделить вывод на группы), мы получим вывод результатов по каждой группе отдельно. Эти группы должны быть определены в поле Groups based on (Группы, созданные на основе) на базе соответствующих переменных.
Еще одну возможность предоставляет опция Compare Groups (Сравнить группы). Она организует вывод таким образом, что можно визуально сравнить разные группы друг с другом. Выполните частотный анализ переменной «настроение». Вы получите следующую результирующую таблицу.
Таблица 1.
Таблица вывода результатов распределения ответов на вопрос при включенном меню разделения файла
|
Что бы Вы могли сказать о своем настроении в последние дни? | ||||||
|
Пол |
Frequency |
Percent |
Valid Percent |
Cumulative Percent | ||
|
мужской |
Valid |
прекрасное настроение |
101 |
15,2 |
15,2 |
15,2 |
|
нормальное, ровное |
346 |
52,0 |
52,0 |
67,1 | ||
|
испытываю напряжение, раздражение |
158 |
23,7 |
23,7 |
90,8 | ||
|
испытываю страх, тоску |
25 |
3,8 |
3,8 |
94,6 | ||
|
затрудняюсь ответить |
36 |
5,4 |
5,4 |
100,0 | ||
|
Total |
666 |
100,0 |
100,0 |
| ||
|
женский |
Valid |
прекрасное настроение |
116 |
13,9 |
13,9 |
13,9 |
|
нормальное, ровное |
407 |
48,8 |
48,8 |
62,7 | ||
|
испытываю напряжение, раздражение |
210 |
25,2 |
25,2 |
87,9 | ||
|
испытываю страх, тоску |
48 |
5,8 |
5,8 |
93,6 | ||
|
затрудняюсь ответить |
53 |
6,4 |
6,4 |
100,0 | ||
|
Total |
834 |
100,0 |
100,0 |
| ||
Учтите, что файл данных останется разделенным на подгруппы, пока вы не деактивируете соответствующие опции. Для этого поступите следующим образом. Выберите в меню команды Data (Данные)/ Split File... (Разделить файл). В диалоговом окне Split File выберите опцию Analyze all cases, do not create groups (Анализировать все наблюдения, не создавать группы). Теперь разделение файла убрано.
Задание
Открыть файл OBL1011A.SAV.
Выбор наблюдений по определенному условию. Вам необходимо составить при помощи логических и операторов отношения условия отбора данных. Постарайтесь создать такие условия, которые могут реально пригодиться для анализа результатов представленной вам базы исследования социально-экономической обстановки Вологодской области.
Например, проанализировать, как отличается уровень одобрения власти в зависимости от пола и возраста респондента. Допустим, для этого вы производите отбор переменных с условием: пол=1 И возраст<31 (т.е. отбираете молодых мужчин). После создания переменных вы обязательно запускаете опцию описательная статистика, т.е. узнаете, как ответили на вопрос отобранные вами респонденты. В данном случае запускаем описательную статистику по вопросу: «Одобряете ли Вы деятельность Президента РФ?» Составьте примеры по каждому из операторов отношения и логических операторов.
Извлечение случайной выборки. Извлеките случайную выборку в 200 случаев из всей базы. Извлеките 10% случаев из всей базы. Запустите описательную статистику по вопросу о настроении, сравните результаты. Отсортируйте данные по оценке экономических реформ, проводимых в России. Затем отсортируйте данные по возрасту.
Разделение наблюдений на группы. Разделите файл на группы по полу, посмотрите оценку настроения. Разделите файл по уровню одобрения президента, посмотрите оценку материального положения. Приведите еще три способа использования данной функции.
Лабораторная работа № 3
Работа с множественными ответами. Модификация данных
В анкетах достаточно часто встречаются вопросы, на которые респондент может выбрать несколько вариантов ответа, их называют неальтернативными (многозначными) вопросами. Например: «Какие суждения из ниже приведенных более всего соответствуют вашему мнению (выберите несколько вариантов ответа)». Неальтернативный признак обычно кодируется следующим образом. Для каждой альтернативы ответа заводится переменная, которая соответствует столбцу матрицы и кодируется с помощью 0 и 1. В нашем исследовании про изучение влияния экономического кризиса на самоидентификацию населения, таковым был вопрос: «С чем Вы столкнулись за последние 2 года?», варианты ответа на который вы можете видеть на рис. 9.
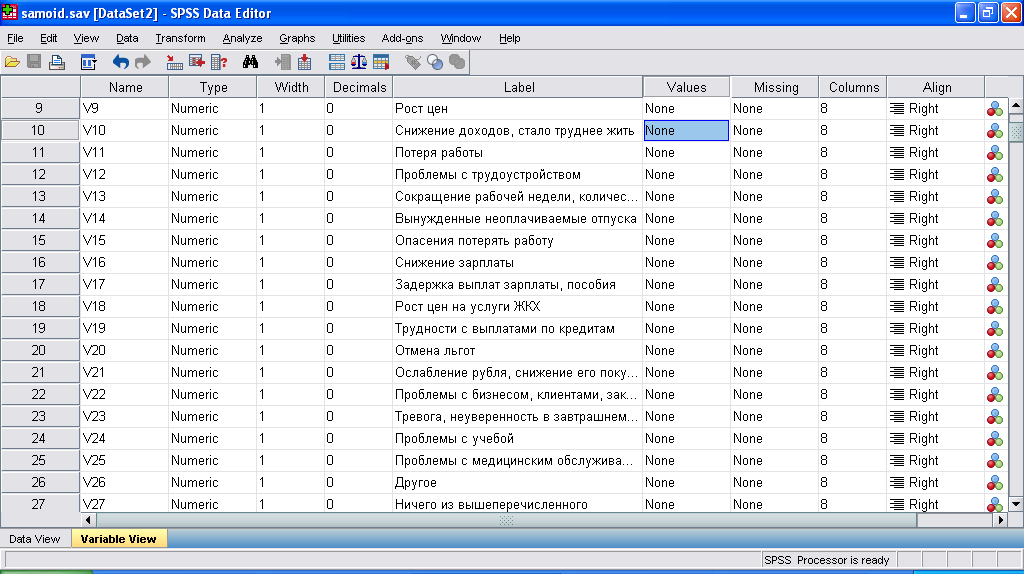
Рис. 9. Вид описания переменных при вводе множественных ответов
Тогда в листе базы данных ответы на наши вопросы будут выглядеть следующим образом (см. рис. 10).
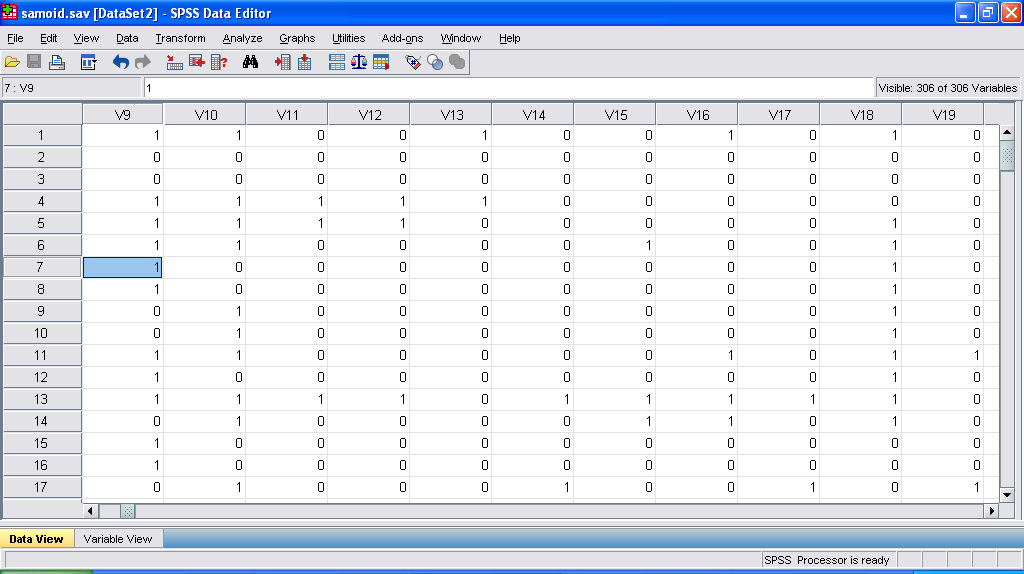
Рис. 10. Вид окна базы данных при вводе множественных ответов
Как получить одномерное распределение ответов по множественным вопросам? Если мы запустим одномерное распределение как для остальных вопросов, перед нами появится ровно столько таблиц, сколько альтернатив ответа мы имеем, что само по себе не очень удобно для пользования.
Приведем пример. Ответы на наш вопрос закодирован в переменных VAR9-VAR26. В первую очередь мы должны сообщить компьютеру, что эти переменные принадлежат к одному "набору переменных".
Выберите в меню команды Analyze (Анализ)/ Multiple Response (Множественные ответы) Define Sets... (Определить наборы). Откроется диалоговое окно Define Multiple Response Sets (Определение наборов ответов) (см. рис. 11).
Выделите в списке исходных переменных переменные и перенесите их в список Variables in Set (Переменные в наборе). Задайте дихотомическую кодировку переменных (опция Dichotomies в группе Variables Are Coded As). Эта настройка выбирается по умолчанию. В поле Counted Value (Учитываемое значение) введите "1". Присвойте набору имя "последствия" и метку, соответствующую полной формулировке вопроса. Щелкните на кнопке Add (Добавить), и созданный набор будет внесен в список наборов множественных ответов (Mult Response Sets). SPSS начинает имена наборов переменных со знака доллара. Щелкните на кнопке Close (Закрыть), чтобы закончить процесс определения набора.
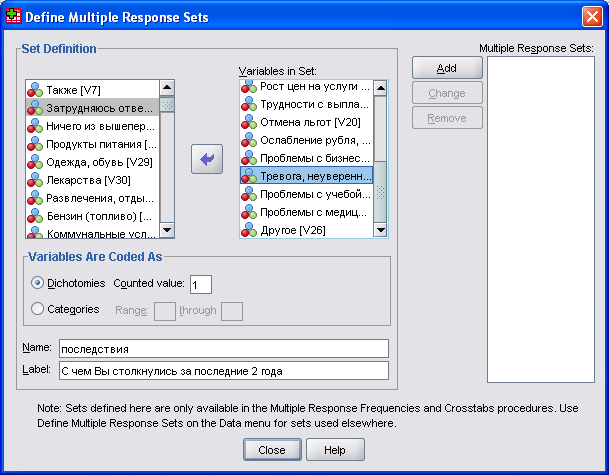
Рис. 11. Вид диалогового окна определения наборов для множественных ответов
Чтобы создать частотную таблицу для дихотомического набора, выберите команды меню Analyze (Анализ)/ Multiple Response (Множественные ответы) Frequencies... (Частоты). Откроется диалоговое окно Multiple Response Frequencies (Частоты множественных ответов). В списке Mult Response Sets этого диалога отображаются уже определенные наборы переменных; в нашем примере это набор «Последствия». Перенесите набор в список Table(s) for (Таблицы для). Щелкните на кнопке ОК. В результате получите одномерное распределение ответов по данному множественному вопросу.
Модификация данных
Для проведения анализа часто бывает необходимо выполнить преобразование данных. На основе первоначально собранных данных можно создать новые переменные и изменить кодирование. Подобные преобразования называются модификацией данных.
В SPSS существует много возможностей для модификации данных. К важнейшим из них относятся: вычисление новых переменных путем использования различных арифметических выражений (математических формул); подсчет частоты появлений определенных значений; перекодирование значений; вычисление новых переменных при выполнении определенного условия; агрегирование данных; ранговые преобразования; вычисление весов наблюдений.
Остановимся на основном из них - вычисление новых переменных.
Путем вычислений в SPSS можно образовать новые переменные и добавить их в файл данных. Так, например, нам необходимо вычислить стаж каждого респондента в опросе работников на предприятии, у нас имеется переменная «возраст респондента» и «возраст прихода на предприятии».
Для этого выберите в меню команды Transform (Преобразовать)/Compute... (Вычислить). Откроется диалоговое окно Compute Variable (Вычислить переменную) (см. рис. 12).
В поле Target Variable (Выходная переменная) указывается имя переменной, которой присваивается вычисленное значение. В качестве выходной переменной может служить уже существующая или новая переменная. В поле Numeric Expression (Численное выражение) вводится выражение, применяемое для определения значения выходной переменной. В этом выражении могут использоваться имена существующих переменных, константы, арифметические операторы и функции.
Введите в поле Target Variable имя «стаж», а в поле Numeric Expression формулу «возраст - возр_прихода». Эту формулу можно ввести либо вручную, либо используя список переменных и клавиатуру диалогового окна. Кнопка с треугольником позволяет копировать в поле формулы имена переменных, а кнопки клавиатуры — вставлять цифры и знаки. Щелкните на кнопке Type&Label... (Тип и метка). Откроется диалоговое окно Compute Variable: Type and Label (Вычислить переменную: Тип и метка). Здесь можно задать метку для новой переменной «стаж». В поле Label введите текст: «Стаж работы на предприятии» и щелкните на кнопке Continue. В диалоговом окне Compute Variable щелкните на кнопке ОК. Переменная создана и вы можете посмотреть распределение по ней.
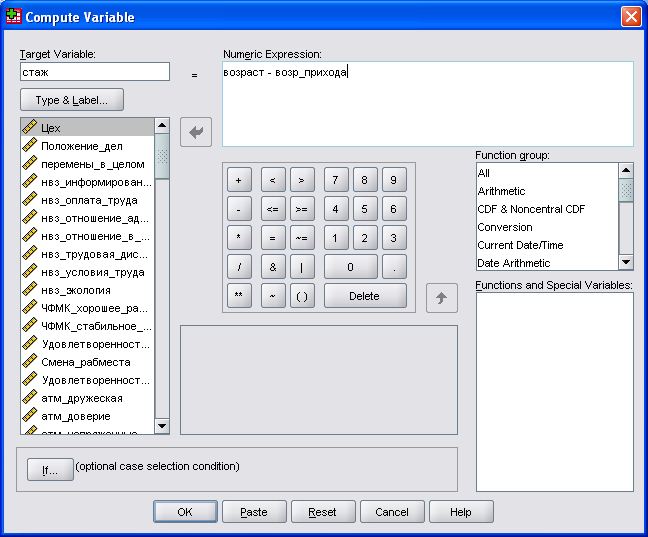
Рис. 12. Вид окна вычисления переменных
Создание переменных по определенному условию
В файле ФМК.sav (изучение морально-психологического климата), в частности, есть переменная «положение_дел» (оценка положения дел на предприятии), которая имеет следующие варианты ответа: «хорошее»; «скорее хорошее, чем плохое», «скорее плохое, чем хорошее», «плохое», «затрудняюсь ответить».
Допустим, нам требуется образовать из вариантов ответов на этот вопрос индекс оценки по шкале от «2» до «-2». То есть, если респондент ответил, что положение дел «хорошее», необходимо придать шкальное значение «2»; «скорее плохое, чем хорошее» - «1»; «затрудняюсь ответить» - «0»; «скорее хорошее, чем плохое» - «-1»; «плохое» - «-2». Это можно выполнить следующим образом.
Transform (Преобразовать)/ Compute... (Вычислить). В открывшемся диалоговом окне в поле выходной переменной задайте, например, «индекс_положения», а для численного выражения «2» (см. рис. 13).
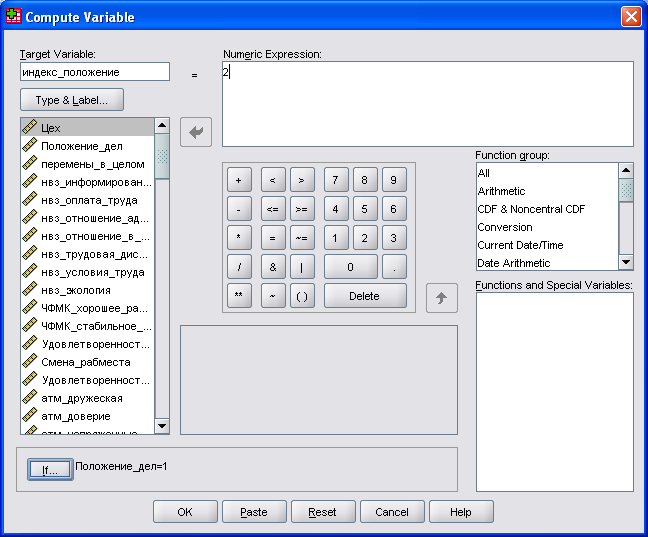
Рис. 13. Вид окна создания переменной при выполнении условия
Щелкните на кнопке If... (Если). Откроется диалоговое окно Compute Variable: If Cases (Вычислить переменную: Если выполняется условие). Измените начальную на стройку Include all cases (Включить все наблюдения) на Include if case satisfies condition (Включить, если для наблюдения выполняется условие). В поле под этой опцией введите условие: «положение_дел» =1. Закройте это диалоговое окно, щелкнув на кнопке Continue, и диалог Compute Variable кнопкой ОК.
Теперь в файле данных появилась новая переменная, которая в случаях, когда заданное условие не выполняется, содержит системное отсутствующее значение.
В нашем случае следует записать далее в этой же переменной:
- если «положение дел»=2, то «индекс_положение»=1;
- если «положение дел»=3, то «индекс_положение»=0;
- если «положение дел»=4, то «индекс_положение»=-1;
- если «положение дел»=5, то «индекс_положение»=-2.
Данные преобразования позволят нам вычислить индекс оценки положения на предприятии просто запустив описательную статистику, а в ней среднее значение, и на выходе программа нам выдаст индекс оценки по всей базе данных в среднем.
Задание
Открыть файл мотив.SAV. Изучить кодировку переменных в соответствии с анкетой.
2. Используя опцию «Множественные ответы», ответить на следующие вопросы:
Поровну ли в выборке мужчин и женщин (v410-411)? Какова доля населения моложе 30 лет (v412-413)? Сколько респондентов имеют образование выше среднего (v407-409)?
2. Пользуясь командой COMPUTE построить переменную «зарплата», при этом разбить респондентов по уровню заработной платы на следующие группы: 0-5 тыс. руб., 5-10 тыс. руб., 10-15 тыс. руб., 15-20 тыс. руб., 20 тыс. руб. и более (v341-364)
Пользуясь командой COMPUTE при использовании условия IF
- создать переменную «удовлетворенность» из дихотомических наборов переменных, которая должна показывать уровень удовлетворенности по шкале от 2 до -2) (v252-256);
- удовлетворенность основными параметрами работы (можно по шкале от 1 до 3, где 3 – полностью удовлетворен) (v299-340).
Лабораторная работа № 4.