

Основные команды меню spss
FILE: обеспечивает доступ к файлам данных, к выходным файлам и программам преобразования данных. С файлами данных связываются окна. Если текущее окно соответствует данным наблюдений, то команда FILE обслуживает сохранение и замену данных.
EDIT: редактирование командных файлов, выходных файлов и файлов данных статистических наблюдений и др.
DATA: обеспечивает операции над данными - сортировку, слияние файлов данных, агрегирование, организацию подвыборки из данных.
TRANSFORM: преобразование данных.
ANALIS: реализация методов анализа данных
GRAPHS: графическое представление данных.
UTILITIES: обслуживающие программы.
WINDOOW: переключение окон.
HELP: справочная информация.
Ввод данных с экрана
В большинстве социологических исследований анализируется анкетная информация. Условно эти данные можно представить в виде матрицы, строкам которой соответствуют объекты (анкеты), а столбцам - признаки (отдельные вопросы и подвопросы анкеты) (см. рис.1). В современных статистических пакетах такую информацию принято представлять в виде таблицы, визуально это напоминает таблицу Excel.
Данные можно вводить непосредственно с экрана в листе Data View (лист базы данных). По умолчанию переменные будут иметь имена VAR0001.. Var0002 и т.д. Для изменения имен переменных, назначения их типов и расширенных названий (меток) можно щелкнуть мышкой дважды на существующих названиях столбцов. При этом открывается окно диалога по описанию переменной (Variable View). Мы рекомендуем начать ввод данных именно с заполнения листа описания переменных.
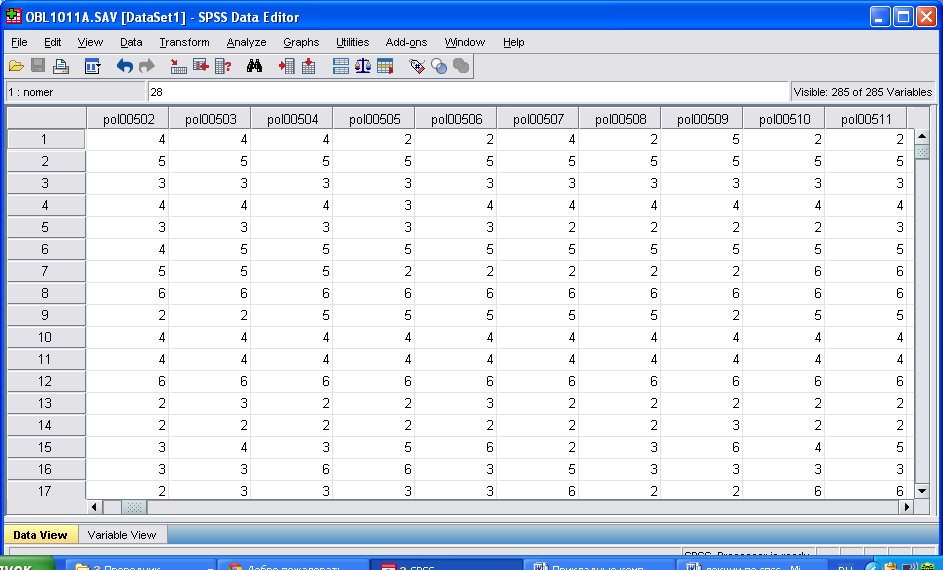
Рис.1. Вид листа ввода переменных
Типы переменных
После выбора листа описания переменных перед вами появится следующая картинка (см. рис. 2). Исследователю предлагается заполнить по каждой переменной (в нашем случае каждой отдельно взятой строке соответствует один вопрос анкеты) следующие поля.
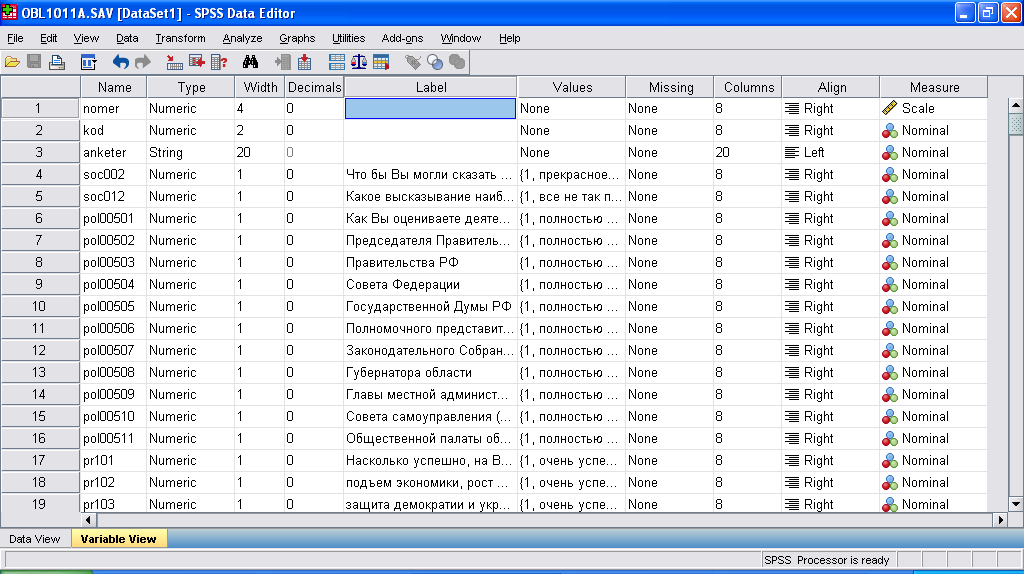
Рис.2. Вид листа описания переменных
Name (имя переменной). К имени налагаются определенные требования: не должно быть больше 8 символов (хотя в более поздних версиях можно и больше), любые символы, но название обязательно начинается с буквы, имена у разных переменных должны быть разными, имена не должны совпадать с зарезервированными словами. Следует отметить, что если вы забудете об этих условиях и неправильно придадите имя – программа в диалоговом окне выдаст реплику, что у вас неправильно выбрано имя и предложит переименовать переменную.
Type (тип). В статистическом пакете SPSS предусмотрено 8 типов кодирования переменных. Мы остановимся лишь на строчных (STRING) и числовых (NUMERIC) переменных. Строчные переменные используются достаточно редко, например, для введения ответов на открытые вопросы или фамилий респондентов, в базе данных по Вологодской области вы увидите, что там заведены фамилии анкетеров, что позволяет по результатам контроля в случае необходимости достаточно легко отбраковать анкеты. Практически все остальные имеют тип (NUMERIC) и заводятся в виде цифр.
Width (ширина). Максимальное количество знаков, которое имеет переменная, включая дробную часть.
Decimals (десятичные значения). Количество знаков после запятой. В номинальных шкалах, как правило, ставится 0.
Label (метка). Прописывается полное название переменной, так как для размера имени у нас есть ограничения. Обычно здесь записывается вся формулировка вопроса.
Values (значения). В данном поле прописываются значения альтернатив ответов по переменной. Например: при описании переменной пол, вы запишите 1 = «мужской, 2 = «женский»
Missing (пропуски) Нередко необходимо исключить из анализа коды переменных, соответствующих неопределенным значениям, например, "затрудняюсь ответить", "отказ от ответа" и "нет ответа" кодируются кодами 997, 998 и 999 соответственно.
Columns (ширина). Ширина столбца данной переменной в листе Data View. По умолчанию стоит 8.
Align (выравнивание). Выравнивание в листе базы данных – по правому, по левому краю или по середине.
Measure (тип шкалы измерения переменных). В зависимости от свойств переменной выделяют шкалы: номинальную, порядковую (ранговую), интервальную и шкалу отношений, вы с ними более подробно ознакомитесь в курсе «Теория измерений в социологии». Техника анализа переменных, измеренных в количественных шкалах (интервальной и шкале отношений) обычно одинакова.
Как только вы в листе описания переменных заводите имя переменных, все остальные поля заполняются автоматически, по умолчанию ставится числовой тип переменных, максимальное кол-во знаков 1, кол-во знаков после запятой 0, ширина 8, выравнивание по правому краю, шкала номинальная. Таким образом, вы только определяете для себя, есть ли необходимость заводить формулировку вопроса в метке и прописывать значения альтернатив ответов.
Статистический анализ при помощи диалоговых окон
При выполнении статистического анализа при помощи SPSS Вы должны пройти три основных шага:
1. Выбрать файл данных. Это может быть файл, который вы создали в редакторе данных, ранее определенный файл данных SPSS, файл электронной таблицы или текстовый файл.
2. Выбрать статистическую процедуру из меню.
3. Выбрать переменные, которые необходимо включить в анализ и любые дополнительные параметры из диалоговых окон.
Для выбора файла данных для анализа необходимо File/ Open/ Data в подменю. Это приведет к раскрытию диалогового окна Open Data File. По умолчанию SPSS ищет все файлы с расширением .sav в текущей директории. Щелкаете на необходимый вам файл, щелкните на OK или нажмите Enter.
Раздел меню Statistics содержит список общих статистических категорий. Каждая из них заканчивается значком стрелки, которая указывает, что существует еще один уровень — подменю, в котором и перечислены конкретные статистические процедуры.
Для создания необходимых нам частотных таблиц необходимо выбрать Analyze (Анализ)/ Descriptive Statistics (Описательная статистика)/ Frequencies (Частоты). Появится диалоговое окно частотных распределений (см. рис. 3). Главное диалоговое окно имеет основные компоненты: исходный список переменных (список переменных (полей) текущего файла данных); список (списки) выбранных переменных; кнопки команд.
Если вашей задачей является создание простого одномерного распределения по вопросу, достаточно выбрать необходимый вопрос в левой части меню, кликнуть на стрелочку в середине экрана и нажать OK.
 Рис.
3. Вид окна частотных распределений
Рис.
3. Вид окна частотных распределений
Но этим возможности программы не ограничиваются. Вы можете выбрать опцию «Statistics» и тогда на ваш выбор будет расчет ряда статистических показателей (см. рис. 4).

Рис. 4. Вид окна расчета статистических показателей
Здесь можно задать вычисление следующих статистических характеристик: среднего значения, суммы, стандартного отклонения, стандартной ошибки, дисперсии, минимума, максимума, размаха, эксцесса (вариации), асимметрии.
Задание
Представьте, что вы проводите опрос студентов вашей группы по одной из наиболее актуальных и острых проблем в настоящее время и перед вами стоит задача разработки инструментария, создания базы обработки данных, заведение анкет и первичный анализ результатов исследования.
Для этого вам необходимо:
Разработать анкету опроса, включающую в себя как минимум 6 вопросов и паспортичку, при этом необходимо использовать разные шкалы в вопросах. Обязательным является хотя бы один вопрос, требующий нескольких вариантов ответа, чтобы закрепить навык заведения множественных ответов.
Открыть программу SPSS, ознакомиться со структурой пакета, создать новый файл и в листе описания переменных прописать все вопросы анкеты.
В листе ввода данных завести результаты опроса респондентов. Для получения результатов опроса предлагается опросить студентов группы.
После ввода всех анкет необходимо определить наборы ответов по множественным вопросам.
Провести первичный социологический анализ: запустить опцию «Описательная статистика» по всем вопросам.
Представить графически распределение ответов по вопросам в программе SPSS.
Лабораторная работа 2