

29-10-2014_11-40-41 / Методические указания к выполнению лабораторной работы ___4 по ОТС
.pdfМетодические указания к выполнению лабораторной работы №4 по дисциплине «Общая теория связи»
Изучение методов эффективного кодирования информации
Красноярск
Золотухин, В.В.
Методические указания к выполнению лабораторной работы №4 «Изучение методов эффективного кодирования информации» по дисциплине «Общая теория связи» / В.В. Золотухин. – Красноярск, 2013. – 29 с.
В данных методических указаниях к лабораторной работе по дисциплине «Общая теория связи» перед студентами ставится задача изучения современных методов эффективного кодирования (сжатия) различных видов информации, среди которых такие методы как алгоритмы Хаффмана и Шеннона-Фано, арифметическое кодирование, кодирование длин повторов RLE, словарные методы сжатия Лемпеля-Зива LZ77 и LZ78, линейное предсказывающее кодирование LPC, дельта-модуляция и нелинейное кодирование.
Предназначено для студентов, обучающихся по направлению подготовки 210700.62 «Инфокоммуникации».
© В.В. Золотухин
Цель лабораторной работы: изучение методов эффективного кодирования информации, алгоритмов их работы и особенностей их программной реализации.
Задание на лабораторную работу: в соответствии с номером варианта требуется реализовать программно алгоритм эффективного кодирования или декодирования текстовой или числовой информации согласно заданию из табл. 4.1. Предварительно требуется выполнить и продемонстрировать преподавателю домашнее задание. В качестве исходных данных для кодирования рекомендуется выбирать последовательности из табл. 4.2 и 4.3.
|
|
Таблица 4.1 |
Задания на выполнение лабораторной работы согласно номеру варианта |
||
|
|
|
Номер варианта |
Домашнее задание |
Программная реализация |
1 |
Хаффмана |
Кодер LZ77 |
2 |
Шеннона-Фано |
Кодер LZ78 |
3 |
RLE |
Декодер LZSS |
4 |
LPC |
Кодер LZSS |
5 |
LZW |
Декодер LZ78 |
6 |
LZSS |
Декодер LZ77 |
7 |
Хаффмана |
Кодер RLE |
8 |
Шеннона-Фано |
Кодер дельта-кодир. |
9 |
RLE |
Кодер LZ77 |
10 |
Дельта-кодирование |
Кодер LZ78 |
11 |
LZ77 |
Декодер RLE |
12 |
LZ78 |
Декодер дельта-кодир. |
13 |
Хаффмана |
Кодер LZW |
14 |
Шеннона-Фано |
Кодер арифм. кодир. |
15 |
RLE |
Декодер арифм. кодир. |
16 |
Дельта-модуляция |
Декодер LZW |
17 |
Нелинейное кодирование |
Кодер дельта-модуляция |
18 |
Нелинейное кодирование |
Декодер RLE |
19 |
LZ77 |
Нелин. кодер |
20 |
LZ78 |
Нелинейный декодер |
|
|
Таблица 4.2 |
Исходные данные для решения домашнего задания |
||
|
|
|
Метод сжатия |
Исходные данные |
|
Хаффмана, |
AABCBCAABCAABABAAABACACABBAAAABAAA |
|
Шеннона-Фано |
ABAABAABABABABAAABAAAAABAABC |
|
Дельта-кодиров. |
5, 6, 5, 6, 7, 10, 11, 12, 13, 15, 18, 22, 15, 13, 10, 8, 5, 2, -1, |
|
|
0, 1, -1, 0 |
|
RLE |
AAABBAAAAABCBABBBBCAAAAAAAABBBCCCC |
|

|
AAAAAAAAABBBCCACBBBBACCBBAAAABBBBBA |
|
|
CACCCCCCBBB |
|
LZ |
ABCABABBAAABABCBACCBACBAAABACACABCC |
|
Арифмет. кодир. |
КОМОК |
|
|
Таблица 4.3 |
|
|
Исходные данные для сжатия программой |
|
|
|
|
Метод сжатия |
Исходные данные |
|
Хаффмана, |
AABCBCAABCAABABAAABACACABBAAAABAAA |
|
Шеннона-Фано |
ABAABAABABABABAAABAAAAABAABCAAAABA |
|
|
BCABBBAAAAABAABABCABBCAABBAAAAAAAB |
|
|
AAAAAAABBACAAABBAAAAA |
|
|
Окончание таблицы 4.3 |
|
|
|
|
Метод сжатия |
Исходные данные |
|
Дельта- |
5, 6, 5, 6, 7, 10, 11, 12, 13, 15, 18, 22, 15, 13, 10, 8, 5, 2, -1, |
|
кодирование |
0, 1, -1, 0 |
|
RLE |
AAABBAAAAABCBABBBBCAAAAAAAABBBCCCC |
|
|
AAAAAAAAABBBCCACBBBBACCBBAAAABBBBBA |
|
|
CACCCCCCBBB |
|
LZ |
ABCABABBAAABABCBACCBACBAAABACACABCC |
|
|
BCBCCBABCBCCCCBCACAAACACBCAACBACBAB |
|
|
CCABCCACCCBCAACBBACCABCBCABCBACBBCB |
|
|
ABCBACBCBBBCBACAAAACB |
|
Арифметическое |
TORONTO |
|
кодирование |
||
|
4 Методы эффективного кодирования источников дискретных сообщений
Практически все равномерные коды являются избыточными, то есть используют для кодирования гораздо большее число бит по сравнению с количеством информации, содержащейся в этих символах. Эффективное или статистическое кодирование источника представляет собой процесс устранения избыточности в передаваемом сообщении. Как правило, для этой цели используются неравномерные коды, имеющие переменную длину кодовой комбинации. При этом символам, появляющимся с большей вероятностью, будут соответствовать короткие кодовые комбинации, а символам, появляющимся относительно редко, - длинные кодовые комбинации.
Основная теорема кодирования, предложенная Клодом Шенноном,
устанавливающая связь между средней длиной кодовой комбинации l и

энтропией источника дискретных сообщений H(A), формулируется следующим образом:
Для любого однозначно декодируемого кода всегда выполняется неравенство
l H(A),
при этом существует однозначно декодируемый код, для которого выполняется неравенство
l H(A) 1.
Таким образом, теоретически невозможно закодировать сообщения источника таким образом, чтобы средняя длина кодовой комбинации была меньше энтропии источника. Энтропия представляет собой тот минимум, до которого в идеальном случае удается сжать информацию. С другой стороны, существуют такие методы эффективного кодирования, средняя длина кодовых комбинаций для которых всего на 1 бит больше энтропии.
Далее рассмотрим методы статистического кодирования источников дискретных сообщений, предложенные Шенноном и Фано, а также Хаффманом. Следует заметить, что такие методы предполагают наличие статистических данных о вероятностях появления символов алфавита p(ai) или хотя бы их оценок.
4.1Статистическое кодирование источников дискретных сообщений
4.1.1Метод кодирования Шеннона-Фано
Данный метод был предложен независимо Клодом Шенноном (Claude Elwood Shannon) и Робертом Фано (Robert Fano). Алгоритм кодирования источника состоит из следующих трех этапов: сортировки, разделения и кодирования. Более полно алгоритм кодирования можно описать следующими этапами:
1.Расположить все символы алфавита в порядке убывания вероятностей.
2.Разделить весь алфавит на две группы таким образом, чтобы суммарные вероятности появления символов в каждой из групп были примерно равны. Первой или верхней группе в качестве первого символа кодовой комбинации присвоить 0, второй или нижней – 1.
3.Продолжаем процесс разделения: теперь каждую из групп вновь делим на две подгруппы с примерно одинаковыми вероятностями. Теперь уже в качестве вторых символов кодовых комбинаций для верхних подгрупп выбираем 0, а для нижних – 1.
4.Весь процесс повторяется до тех пор, пока не в каждой из подгрупп не останется по одному символу.

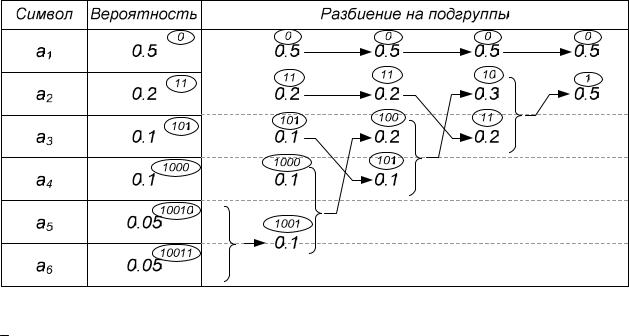
Для примера рассмотрим процесс получения кодовых комбинаций для источника с алфавитом из 6 символов:
Достаточно часто построение кода Шеннона-Фано удобно проиллюстрировать с помощью дерева:
При этом построение дерева начинается с корня, где на первом шаге происходит разделение на две ветви (группы) с примерно одинаковыми вероятностями, причем выбору левой ветви соответствует 1, а правой – 0. Далее процесс разделения ветвей дерева продолжается, а в конечных узлах дерева размещаются символы алфавита. Путь до каждого символа в виде последовательности выбора вершин как 1 и 0 – представляет собой кодовую комбинацию для данного символа.
В случае равномерного кодирования символов данного алфавита потребуется 3 бита на символ – l = 3 бита.

Для кода Шеннона-Фано на один символ в среднем приходится следующее число битов:
K
lli P(ai) 1 0,5 2 0,2 3 0,1 4 0,1 5 0,05 5 0,05 2,1 бит.
i1
При этом энтропия источника равна:
6
H(A) P(ai) log2 P(ai) 2,061бит.
i 1
Таким образом, избыточность при использовании кодирования Шеннона-Фано составит всего лишь:
R(A) l H(A) 2,1 2,061 0,039 бит.
Следует заметить, что метод Шеннона-Фано может быть использован не только для кодирования отдельных символов, но и для кодирования групп символов, то есть блокового кодирования.
Рассмотрим простой пример. Пусть алфавит источника состоит всего из двух символов – A и B с вероятностями появления p(A)=0,7 и p(B)=0,3 соответственно. Энтропия для такого источника равна:
H(A) 0,7 log2 0,7 0,3 log2 0,3 0,88 бит.
В случае использования обычного равномерного кодирования получаем простейший код, состоящий всего из одного бита:
Символ |
Вероятность |
Кодовое слово |
A |
0.7 |
1 |
|
|
|
B |
0.3 |
0 |
|
|
|
При этом избыточность источника будет равна R(A)=0,12 бит/символ. Теперь попробуем использовать метод Шеннона-Фано для
кодирования всех возможных двухсимвольных комбинаций, которых будет четыре:

Средняя длина кодового кодовой комбинации в таком случае составит l 1,81битов. Однако, учитывая тот факт, что это количество информации приходится на два символа, получаем следующее значение средней длины кодовой комбинации для одного символа:
l 1,81битов 0,905 бит. 2
При этом избыточность составит R(A)=0,905-0,88=0,025 бит/символ, что почти в пять раз меньше исходного значения.
Аналогично можно закодировать и трехсимвольные группы исходного алфавита, при этом можно предположить, что полученное значение средней длины кодовой комбинации будет еще ближе к энтропии.
Метод кодирования Шеннона-Фано является близким к оптимальному, но не оптимальным. Это объясняется тем фактом, что в процессе кодирования возможны ситуации, когда суммарные вероятности двух групп будут одинаковы не только для одного, но и для двух вариантов разделения. В этом случае, даже выбирая оптимальный на данном шаге вариант, можно в конечном счете прийти к неоптимальному решению. Иными словами, для одних и тех же вероятностей появления символов можно построить несколько кодов Шеннона-Фано, лишь некоторые из которых будут оптимальными.
В заключение следует заметить, что другой подобный метод кодирования – метод Хаффмана, обеспечивает еще более эффективное сжатие информации, благодаря чему он и нашел преимущественное распространение в системах связи.
4.1.2 Метод кодирования Хаффмана
Данный алгоритм был разработан в 1952 году аспирантом Массачусетского технологического института Дэвидом Хаффманом в процессе написания им курсовой работы.
Во многом принцип работы алгоритма Хаффмана напоминает алгоритм Шеннона-Фано, но при этом является более сложным, что является его расплатой за оптимальность. Основные этапы работы алгоритма Хаффмана:
1.Расположить все символы алфавита в порядке убывания вероятностей.
2.Два наименее вероятных символа объединяются в один новый символ с суммарной вероятностью. При этом возникает новый алфавит, который также подлежит процедуре упорядочивания.
3.Процесс объединения продолжается до тех пор, пока в новом алфавите не останется всего двух символов.
4.Теперь начинается процедура кодирования: двигаясь в обратном направлении, верхнему из объединенных символов в качестве очередного бита кодовой комбинации добавляется 1, нижнему - 0.
Процесс создания кодовых комбинаций продолжается до тех пор, пока не дойдет до исходного алфавита.
Таким образом, новым этапом в алгоритме Хаффмана является процедура движения в обратном направлении.
Рассмотрим кодирование методом Хаффмана на примере:
В данном случае средняя длина кодовой комбинации составит l 2,1битов. Следует заметить, что данное значение полностью совпало с результатом кодирования методом Шеннона-Фано. Однако, уже математически доказано, что в общем случае код Хаффмана позволяет получить более высокие результаты по сравнению с кодом Шеннона-Фано. Именно по этой причине код Хаффмана широко используется в технике связи – факсимильных аппаратах и модемных протоколах, а также как составная часть в большинстве современных алгоритмов сжатия информации, таких как JPEG, MPEG, MP3.