

29-10-2014_11-40-41 / Методические указания к выполнению лабораторной работы ___4 по ОТС
.pdfРис. 4.7. Принцип арифметического сжатия на примере интервала [0, 1)
Таким образом, окончательная длина промежутка будет равна произведению вероятностей всех встретившихся символов, а его начало зависит от порядка следования символов в потоке. Алгоритм арифметического сжатия приведен на рис. 4.8.
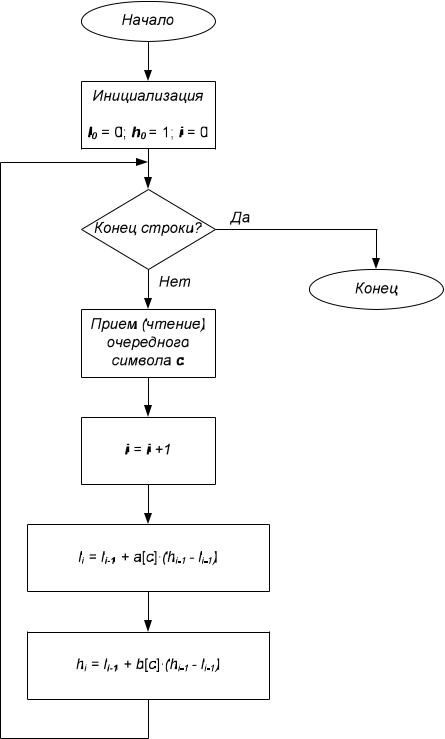
Рис. 4.8. Алгоритм арифметического сжатия
Поскольку конечным результатом работы алгоритма является пара чисел – левая и правая граница интервала, то для восстановления текста на противоположную сторону достаточно будет передать лишь одно число, лежащее в данном интервале. Для нашего случая достаточно будет передать число 0,234.
Процесс декодирования выглядит достаточно просто – по указанному числу мы можем сразу же определить первый символ текста, затем, разбив
выбранный интервал на подынтервалы – второй, затем аналогично третий и т.д.
Заметим также, что передача очень длинного дробного числа может оказаться неэффективной, если будет использоваться обычная форма записи числа с плавающей точкой. Гораздо более компактной формы записи дробного числа можно добиться с помощью двоичной дроби вида
0.a1a2a3…ai = a1·1/2 + a2·1/4 + a3·1/8 +…+ ai·1/2i. В этом случае при сжатии требуется дописывать в дробь дополнительные знаки (1 или 0) до тех пор, пока получившееся число не попадет в требуемый интервал. Для примера, число 0.625 можно представить двоичной дробью 0.101 (а передать нужно лишь 101).
Другой интересной особенностью двоичной дроби является возможность кодирования длинных последовательностей символов на конце текста дробью ограниченной длины. Например, дробь 0.1 (всего один бит, равный 1) в нашем случае задает текст «КАААААААА…», где число символов «А» может быть сколь угодно большим. Важно лишь будет передать на противоположную сторону длину текста.
В заключение следует отметить, что все операции с плавающей точкой выполняются компьютером достаточно медленно, поэтому границы интервалов, такие как и числитель и знаменатель самой дроби, выбираются целыми числами. Например, на практике удобно использовать интервал [0, 65535), а при сужении интервала, чтобы не потерять точность расчетов, полученные значения числителя и знаменателя умножаются на одно и то же число (например, 2).
4.4 Методы сжатия звуковых сигналов
Основной особенностью звуковых сигналов является сильная корреляция между соседними отсчетами речевого сигнала. И
действительно, если для текста характерна слабая корреляция между буквами, например, после буквы A с определенными вероятностями могут появиться буквы П, Р, С, Н, К и т.д., то для звукового сигнала последующий отсчет почти всегда принимает значение, близкое к значению предыдущего отсчета.
Для сжатия звука можно использовать уже известные статистические и словарные методы сжатия, а также алгоритм кодирования длин повторов RLE. Однако следует заметить, что для различных типов звуковых сигналов данные методы приводят к разным результатам.
Так, метод кодирования длин повторов прекрасно сжимает звуковые данные, представляющие собой длинные серии повторяющихся отсчетов, что особенно часто встречается при 8-битном кодировании, когда соседние уровни квантования отличаются на значительную величину и при незначительных колебаниях амплитуды сигнала переход на другой уровень квантования маловероятен. Причин для таких серий отчетов может быть две
– либо это передача низкочастотных сигналов, амплитуда которых меняется
крайне медленно в течение нескольких периодов дискретизации, либо такое сочетание определенной частоты сигнала с частотой дискретизации, при котором все отсчеты выбираются из одной и той же части периода сигнала.
Статистические методы кодирования, например такие, как алгоритм Хаффмана, могут быть использованы для кодирования звуковых сигналов, в которых присутствует преобладание одних амплитудных значений над другими. Так, например, в обычном телефонном сигнале более вероятно появление отсчетов с малой амплитудой, а среднее значение вообще равно нулю.
Словарные методы сжатия, к сожалению, малопригодны для сжатия акустических сигналов по причине отсутствия в них регулярных последовательностей отсчетов (фраз).
В технике связи наибольшее распространение получили следующие два метода сжатия речевых сигналов: подавление пауз, уплотнение и линейное предсказывающее кодирование.
Основная идея метода подавления пауз заключается в отказе от передачи отсчетов речевого сигнала с амплитудой, лежащей ниже порога чувствительности человека. Иными словами, те звуки, которые человеком не слышимы, просто не передаются, а получившиеся длинные серии нулей кодируются уже известным методом RLE. Причина возникновения таких периодов тишины объясняется очень легко: при передаче человеческой речи в сигнале всегда будут присутствовать паузы между слогами, словами, а также паузы во время прослушивания ответа оппонента. Однако следует заметить, что в случае интерактивной связи, например, во время разговора по телефону, человек реагирует на полное исчезновение сигнала (в том числе и шумов) несколько неадекватно, поскольку возникает субъективное ощущение потери сеанса связи. Чтобы устранить этот недостаток, очень часто на приемной стороне (в телефонном аппарате абонента) во время пауз с помощью специального генератора «комфортного шума» искусственно воссоздается «шум молчания».
Уплотнение речевых сигналов основано на том свойстве человеческого восприятия, что разница между громкими звуками менее заметна для человека, чем между тихими сигналами. Таким образом, для громких звуков появляется возможность увеличивать шаг квантования (уменьшать число уровней квантования), а значит, уменьшать длину кодовой комбинации без ущерба для качества звука.
Для этого вместо линейной характеристики квантования на практике используют нелинейное квантование вида:
|
sвх |
|
|
||
sвых 127 2 |
65536 |
1 , |
|
|
|
где sвх– амплитуда (код) входного отсчета;
sвых– амплитуда (код) сигнала на выходе нелинейного преобразователя. При этом на приемной стороне необходимо выполнять обратное
преобразование вида:
|
|
|
|
s |
вых |
|
|
sвх |
65536 log |
2 1 |
|
|
. |
||
127 |
|||||||
|
|
|
|
||||
При этом достигается двукратное сжатие речевого сигнала – вместо исходных 16 битов на один отсчет получаем 8 битов. На практике в технике связи обычно используют несколько иные нелинейные зависимости, в частности, характеристики A- и µ-типа используют квазилогарифмическую зависимость.
4.4.1 Линейно-предсказывающее кодирование
Основная идея метода LPC (Linear Prediction Coding) заключается в передаче по каналу связи не абсолютного значения отсчета звукового сигнала, а ошибки предсказания – разницы между реальным и предсказанным значением. В качестве предсказанного значения в данном случае используется линейная комбинация M предыдущих отсчетов:
j i M
Siпр KjSj,
j i 1
где Sj – j-й отсчет звукового сигнала;
Kj – определенные весовые коэффициенты модели предсказания. Тогда ошибка предсказания Di будет представлять собой разность
вида:
j i M
Di Si Siпр Si KjSj.
j i 1
где Si – реальное значение i-го отсчета звукового сигнала.
Однако само по себе кодирование разности Di не приводит к сжатию данных – более того, передаваемые данные увеличиваются на один бит, необходимый для кодирования знака разности. Но при точном предсказании в выходной последовательности будет очень много чисел, близких или равных нулю, между которыми также присутствует значительная корреляция, что делает возможным их сжатие другими методами. Поэтому метод линейно-предсказывающего кодирования используется в связке с другими методами сжатия, такими как методы Шеннона-Фано и Хаффмана, арифметическим кодированием и кодированием длин повторов RLE.
Теоретически можно выбирать любые значения M и Kj, причем можно использовать либо статическую модель, в которой коэффициенты Kj задаются до начала кодирования и не изменяют своих значений, либо динамическую модель, в которой параметр M обычно выбирается фиксированным, а вот коэффициенты предсказания Kj меняются динамически в зависимости от особенностей входного сигнала.
Рассмотрим несколько распространенных моделей линейнопредсказывающего кодирования. Самая простая модель использует параметры M = 1 и K = 1, что означает следующее предположение: значение текущего отсчета Si в точности равно значению предыдущего отсчета Si-1:
Di Si Si 1.
Очевидно, что это очень простая модель и ошибка предсказания будет нулевой только в случае полного совпадения значений текущего и предыдущего отсчетов, что бывает крайне редко. Однако учитывая сильную корреляцию между соседними отсчетами звукового сигнала можно сделать вывод, что величина ошибки предсказания будет очень малой, что делает возможным последующее сжатие результата другими известными методами эффективного кодирования. В простейшем случае достаточно преобладание линейной тенденции в росте или убывании амплитуды сигнала – это приведет к появлению на выходе кодера серии одинаковых чисел, которые остается закодировать с использованием метода RLE.
Если, например, значения амплитуд отсчетов звукового сигнала будут иметь следующий вид (7, 9, 10, 12, 14, 16, 19, 22, 22, 21, 19, 17, 19), то после дельта-кодирования получим на выходе значения (2, 1, 2, 2, 2, 3, 3, 0, -1, -2, 2), которые в дальнейшем можно закодировать методом Хаффмана.
Данный метод кодирования известен как дельта-кодирование (Delta Coding) и заключается в передаче разницы между соседними отсчетами. Если такая разница передается кодовой комбинацией из нескольких бит, то получаем дифференциальную импульсно-кодовую модуляцию (ДИКМ),
если же для кодирования разницы использован всего один бит – то получаем дельта-модуляцию (ДМ). При этом на кодирование разницы и в первом, и во втором случае требуется гораздо меньше бит, чем при кодировании абсолютных значений отсчетов звукового сигнала. Так, при использовании классической ИКМ для передачи речевого сигнала используется 8 битов на один отсчет сигнала, а при использовании адаптивной дифференциальной ИКМ (АДИКМ) – всего 4 бита.
На приемной стороне для восстановления исходного значения сигнала Si требуется добавить разность Di к значению предыдущего отсчета Si-1 (полученного таким же образом):
Si Si 1 Di.

Более сложная модель предсказания может использовать более одного элемента, а коэффициенты предсказания данной модели уже будут отличаться от единицы. Так, при M=3 и K=1/3 получаем следующее предсказанное значение:
Siпр Si 1 Si 2 Si 3 . 3
Такая модель оказывается предпочтительной в том случае, когда явная линейная тенденция отсутствует, а значение разницы Di в равной вероятности принимает как положительные, так и отрицательные значения. При этом данная процедура вычисления предсказанного значения представляет собой усреднение значений M предыдущих отсчетов.
В заключение можно заметить, что чем больше выбирается значение M, тем более консервативной, инерционной будет модель. Такая модель применима в тех случаях, когда в сигнале преобладает шум и усреднение представляет собой способ подавления сигнала шума. Однако в тех случаях, когда уровень шума будет несоизмеримо мал по сравнению с динамикой изменения сигнала, в особенности если сигнал будет меняться очень быстро, такая модель может оказаться слишком медлительной.
Линейно-предсказывающее кодирование подразумевает полное восстановление информации на приемной стороне, то есть относится к методам сжатия без потерь. В принципе, на основе LPC можно реализовать сжатие с потерями информации: для этого требуется передавать не все значение разности Di, а только часть его старших бит. При этом важно на этапе кодирования на каждом последующем шаге использовать не реальное значение Si, а предсказанное значение Sпрi, получаемое при декодировании как сумма предсказанного значения и сжатое значение разницы:
j M
Siпр KjSj Diсж.
ji 1
Впротивном случае возможно возникновение и последующее накопление погрешности.
С целью достижения больших коэффициентов сжатия информации полезно заново вычислять весовые коэффициенты Kj через определенное число шагов N. При этом критерием оптимальности коэффициентов Kj будет являться минимум разности Di между реальным и предсказанным значениями:
min Di min Si Siпр .
Следует заметить, что в качестве модели предсказания может использоваться и нелинейная зависимость от предыдущих значений отсчетов сигнала, однако, такие модели оказались на практике слишком сложны и малопригодны. Метод LPC положен в основу работы многих современных вокодеров.
Порядок выполнения лабораторной работы:
1.Ознакомиться с алгоритмами работы соответствующих методов сжатия информации (список литературы приведен ниже).
2.Разработать программу на любом языке высокого уровня, например, С++, осуществляющую эффективное кодирование информации – некоторого набора исходных данных, приведенных в табл. 1.3.
3.Составить отчет, содержащий описание и блок-схему алгоритма работы программы, исходный текст программы, исходные данные и результаты работы программы, а также выводы о проделанной работе.
4.Представить отчет преподавателю для проверки, продемонстрировать работу программы на персональном компьютере, ответить на контрольные вопросы, в случае успешной защиты сдать отчет преподавателю.
Требования к оформлению отчета: отчет по лабораторной работе должен содержать титульный лист, индивидуальное задание на лабораторную работу, выполненное домашнее задание, исходный код программы, блоксхему алгоритма работы программы, результаты работы программы и заключение. На титульном листе обязательно должна присутствовать подпись студента – автора работы.
Контрольные вопросы:
1.Структурная схема СПДС. Параметры СПДС.
2.Постулаты теории информации.
3.Основные характеристики ИДС.
4.Равномерное и неравномерное кодирование информации.
5.Основная теорема кодирования информации Клода Шеннона.
6.Метод Хаффмана.
7.Метод Шеннона-Фано.
8.Метод кодирования длин повторов RLE.
9.Словарные методы сжатия. Метод LZ77.
10.Метод Лемпеля-Зива LZ78.
11.Метод кодирования LZW.
12.Метод кодирования LZSS.
13.Методы кодирования LZB, LZH, LZMW.
14.Арифметическое кодирование.
15.Методы кодирования звуковых сигналов. Линейно-предсказывающее кодирование.
16.Дифференциальное кодирование. Дельта-кодирование.
Список литературы:
1.Ватолин Д., Ратушняк А., Смирнов М., Юкин В. Методы сжатия данных. Устройство архиваторов, сжатие изображений и видео / Д. Ватолин, А. Ратушняк, М. Смирнов, В. Юкин. – М.: Диалог-МИФИ, 2003. - 384 с.
2.Сэломон Д. Сжатие данных, изображений и звука / Д. Сэломон. – М.: Техносфера, 2006. – 368 с.
3.Сергеенко В.С., Баринов В.В. Сжатие данных, речи, звука и изображений в телекоммуникационных системах / В.С. Сергеенко, В.В. Баринов. – М.: РадиоСофт, 2011. – 360 с.
4.Электронный ресурс – сайт http://www.compression.ru.