

29-10-2014_11-40-41 / Методические указания к практическому занятию ___4 (ОТС)
.pdfМетодические указания к практическому занятию №4 по дисциплине «Общая теория связи»
Словарные методы сжатия. Алгоритм Лемпеля-Зива
Красноярск
Золотухин, В.В.
Методические указания к практическому занятию №4 «Словарные методы сжатия. Алгоритм Лемпеля-Зива» по дисциплине «Общая теория связи» / В.В. Золотухин. – Красноярск, 2013. – 7 с.
В данных методических указаниях к практическим занятиям по дисциплине «Общая теория связи» студентам предстоит изучить и закрепить такие словарные методы сжатия информации, как методы Лемпеля-Зива LZ77, LZ78, а также их всевозможные модификации.
Предназначено для студентов, обучающихся по направлению 210700.62.
© В.В. Золотухин
ПРАКТИЧЕСКОЕ ЗАНЯТИЕ №4
Словарные методы сжатия. Алгоритм Лемпеля-Зива
Задача 4.1: Выполните кодирование фразы (табл. 4.1) с помощью метода Лемпеля-Зива LZ77. Рассчитайте количество информации, передаваемой при равномерном кодировании кодом ASCII (8 бит на символ) и словарном кодировании LZ77. Сравните полученные значения. Как можно повысить степень сжатия данного текста?
Таблица 4.1
Вариант |
Фраза |
1 |
Richard's wretched ratchet wrench |
2 |
She slits the sheet she sits on |
3 |
How much wood could a woodchuck chuck |
4 |
She sees seas slapping shores |
5 |
Six stick shifts stuck shut |
6 |
The batter with the butter is the batter that is better |
7 |
Clowns grow glowing crowns |
8 |
Blake's black bike's back brake bracket block broke |
9 |
Peter Piper picked a peck of pickled peppers |
10 |
Rubber baby buggy bumpers |
Решение:
Словарные методы сжатия информации используются для кодирования источников дискретных сообщений с памятью, в которых имеются существенные статистические связи между символами передаваемых сообщений.
Одним из наиболее простых методов словарного сжатия является метод Лемпеля-Зива. Он впервые был опубликован в статье в 1977 году и считается одним из первых словарных методов сжатия, однако реально был разработан не позже 1975 года.
В основу его работы положена идея использования так называемого
скользящего словаря или скользящего окна. В действительности, в
качестве словаря алгоритмом сжатия LZ77 используется блок уже обработанной информации. Естественно, что по мере обработки информации в данный блок добавляются новые символы, то есть он сдвигается или как бы «скользит» по передаваемому потоку информации.
Скользящее окно имеет длину N, причем состоит из двух частей:
-словаря длиной D, представляющего собой последовательность уже закодированных символов;
-буфера предварительного просмотра или просто буфера длиной B =
=N – D, содержащего небольшое количество символов (рис. 4.1).
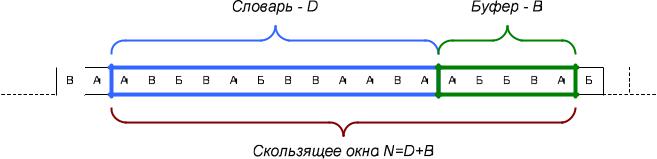
Рис. 4.1. Принцип работы скользящего окна
Идея алгоритма заключается в поиске самого длинного совпадения между строкой из буфера и всеми фразами словаря. Полученная в результате поиска фраза кодируется с помощью двух чисел:
-смещения (offset) от начала буфера (обычно справа налево) – i;
-длины совпадения (match length) – j.
Смещение и длина совпадения играют роль ссылки на фразу из словаря, по которой на приемном конце можно восстановить исходный текст. Дополнительно в выходной поток записывается символ s, непосредственно следующий за совпавшей строкой буфера. Смысл этого символа прост – он позволяет пополнять словарь на приемной стороне новыми фразами, в частности, содержащими новые символы, которых еще нет в словаре.
Для примера попробуем сжать строку «кот от окон отошел», в которой пробелы будем рассматривать как отдельные символы и обозначать «_». Длину буфера предположим равной 6 символам, а размер словаря предположим гораздо большим длины нашей строки, например, 1000 (так часто и бывает на практике).
Также предположим, что:
-если совпадений, нет, то в качестве значения смещения используем 1,
ав качестве длины совпадения – 0;
-нулевое смещение – i = 0 зарезервируем для конца кодирования.
Таблица 4.2
Кодирование фразы с использованием метода LZ77
|
|
|
|
Скользящее окно |
|
|
Совпадающая |
|
|
Закодированные |
||||||||||
|
|
|
|
|
|
|
|
|
|
данные |
|
|
||||||||
|
Шаг |
|
|
|
|
|
|
|
|
фраза |
|
|
|
|
|
|
||||
|
|
|
Словарь |
|
|
Буфер |
|
|
|
|
i |
|
|
j |
|
|
s |
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
1 |
|
- |
|
|
кот_от |
- |
|
1 |
|
0 |
|
|
"к" |
|||||||
2 |
|
|
к |
|
от_от_о |
- |
|
1 |
|
0 |
|
|
"о" |
|||||||
3 |
|
|
ко |
|
т_от_ок |
- |
|
1 |
|
0 |
|
|
"т" |
|||||||
4 |
|
|
кот |
|
_от_око |
- |
|
1 |
|
0 |
|
|
"_" |
|
||||||
5 |
|
|
кот_ |
|
от_окон |
|
"от_" |
1 |
|
3 |
|
|
"о" |
|||||||
6 |
|
|
кот_от_о |
|
кон_ото |
|
"ко" |
8 |
|
2 |
|
|
"н" |
|||||||
7 |
|
|
кот_от_окон |
|
_отошел |
|
"_от" |
7 |
|
3 |
|
|
"о" |
|||||||
8 |
|
|
кот_от_окон_ото |
|
шел |
- |
|
1 |
|
0 |
|
|
"ш" |
|||||||
9 |
кот_от_окон_отош |
ел |
- |
1 |
0 |
"е" |
10 |
кот_от_окон_отоше |
л |
- |
1 |
0 |
"л" |
11 |
кот_от_окон_отошел |
- |
- |
0 |
- |
- |
Для представления индекса i нам достаточно пяти бит, для длины совпадения j – 3 бита, а для символа s – один байт (табл. 4.2). Очевидно, что исходная строка в коде ASCII занимала 18 байт, а после кодирования будет занимать: 10·(5 + 3 + 8) + 8 = 168 бит или 21 байт. Таким образом, для малой строки, когда словарь еще не заполнен, алгоритм Лемпеля-Зива оказывается более расточительным по сравнению с равномерным кодированием. Однако, на больших строках алгоритм показывает хорошие результаты.
Задача 4.2: Выполните кодирование фразы (табл. 4.1) с помощью метода Лемпеля-Зива LZ78. Рассчитайте количество информации, передаваемой при равномерном кодировании кодом ASCII (8 бит на символ) и словарном кодировании LZ78. Сравните эффективность алгоритмов сжатия LZ77 и LZ78 между собой.
Решение:
Впервые алгоритм LZ78 был опубликован в статье 1978 года. Отличительной особенностью алгоритма LZ78 является то, что он не использует принцип скользящего окна и помещает в словарь не все переданные фразы, а только «перспективные» с точки зрения дальнейшего использования.
На каждом шаге в словарь добавляется новая фраза, которая представляет собой соединение (сцепку) одной из фраз словаря S, имеющей самое длинное совпадение со строкой буфера, и символа s. Причем символ s представляет собой символ, следующий за строкой буфера, для которой найдена совпадающая фраза S. Словарь в LZ78 гораздо более компактен, в нем нет повторяющихся фраз.
Алгоритм считывает символы сообщения до тех пор, пока накапливаемая подстрока входит целиком в одну из фраз словаря. Как только эта строка перестает соответствовать хотя бы одной фразе словаря, алгоритм генерирует код, состоящий из индекса строки в словаре и символа, нарушившего совпадение. Затем в словарь добавляется введенная подстрока и новый символ.
На выходе кодера получается только последовательность индексов фраз из словаря S и символов s.
В начале обработки словарь обычно пуст, а после он заполняется новыми фразами и может расти теоретически до бесконечности. На практике же размер словаря ограничивают и при достижении его конца подвергают полной или частичной очистке. Например, из словаря может удаляться наименее используемая фраза.
Для примера закодируем знакомую нам фразу «кот от окон отошел» (табл. 4.3). Для алгоритма LZ78 буфер в принципе не требуется, поэтому
будем его изображать для большей понятности алгоритма. Индекс 0 зарезервируем для признака конца строки, а индекс 1 будет обозначать пустую фразу словаря (отсутствие повтора).
|
|
|
Кодирование фразы с использованием метода LZ78 |
Таблица 4.3 |
|||||||||
|
|
|
|
|
|||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Добавляемая в |
|
|
|
|
Совпадающая |
|
Закодированные |
|||
|
Шаг |
|
словарь фраза |
|
Буфер |
|
|
|
|
данные |
|||
|
|
|
|
|
фраза |
|
|
||||||
|
|
|
Индекс |
Фраза |
|
|
|
|
|
n |
|
s |
|
|
|
|
|
|
|
|
|
|
|
||||
1 |
|
2 |
к |
|
кот_от |
- |
|
1 |
|
"к" |
|||
2 |
|
3 |
о |
|
от_от_ |
- |
|
1 |
|
"о" |
|||
3 |
|
4 |
т |
|
т_от_о |
- |
|
1 |
|
"т" |
|||
4 |
|
5 |
_ |
|
_от_ок |
- |
|
1 |
|
"_" |
|||
5 |
|
6 |
от |
|
от_око |
|
о |
3 |
|
"т" |
|||
6 |
|
7 |
_о |
|
_окон_ |
_ |
|
5 |
|
"о" |
|||
7 |
|
8 |
ко |
|
кон_от |
|
к |
2 |
|
"о" |
|||
8 |
|
9 |
н |
|
н_отош |
- |
|
1 |
|
"н" |
|||
9 |
|
10 |
_от |
|
_отоше |
|
_о |
7 |
|
"т" |
|||
10 |
|
11 |
ош |
|
ошел |
|
о |
3 |
|
"ш" |
|||
11 |
|
12 |
е |
|
ел |
- |
|
1 |
|
"е" |
|||
12 |
|
13 |
л |
|
л |
- |
|
1 |
|
"л" |
|||
Для передачи строки из 18 байт нам потребовалось: 12·(4 + 8) + 4 = 148 битов или 18,5 байтов.
Задача 4.3: Выполните кодирование фразы (табл. 4.1) с помощью метода LZSS. Насколько эффективнее использование данного алгоритма по сравнению с LZ77?
Решение:
Алгоритм LZSS (Лемпеля-Зива-Сторера-Жимански) является модификацией LZ77, которая позволяет значительно уменьшить число бит, необходимое для передачи указателей и символов. При этом к каждому указателю и символу добавляется однобитовый префикс f, позволяющий различать эти объекты. Иными словами, однобитовый флаг f однозначно определяет тип и длину следующих за ним данных. В целом, такой способ кодирования позволяет, с одной стороны, непосредственно передавать символы в явном виде, когда соответствующий им код имеет большую длину и передавать указатель не требуется, а с другой стороны, остается возможность обрабатывать ни разу не встречавшиеся до этого символы. В результате на выходе получаем либо однобитовый флаг символа (например,
0)и следующий за ним символ s, либо однобитовый флаг повтора (например,
1)и следующие за ним значения смещения и длины повторения. Таким образом, во втором случае символ s вообще не передается.