

29-10-2014_11-40-41 / Методические указания к выполнению лабораторной работы ___4 по ОТС
.pdf4.2Словарные методы сжатия информации
4.2.1Алгоритм сжатия Лемпеля-Зива LZ77
Рассмотрим алгоритм сжатия LZ77. Он впервые был опубликован в статье в 1977 году и считается одним из первых словарных методов сжатия, однако реально был разработан не позже 1975 года.
В основу его работы положена идея использования так называемого
скользящего словаря или скользящего окна. В действительности, в
качестве словаря алгоритмом сжатия LZ77 используется блок уже обработанной информации. Естественно, что по мере обработки информации в данный блок добавляются новые символы, то есть он сдвигается или как бы «скользит» по передаваемому потоку информации.
Скользящее окно имеет длину N, причем состоит из двух частей:
-словаря длиной D, представляющего собой последовательность уже закодированных символов;
-буфера предварительного просмотра или просто буфера длиной B =
=N - D, содержащего небольшое количество символов (рис. 4.1).
Рис. 4.1. Принцип работы скользящего окна
Идея алгоритма заключается в поиске самого длинного совпадения между строкой из буфера и всеми фразами словаря. Полученная в результате поиска фраза кодируется с помощью двух чисел:
-смещения (offset) от начала буфера (обычно справа налево) – i;
-длины совпадения (match length) – j.
Смещение и длина совпадения играют роль ссылки на фразу из словаря, по которой на приемном конце можно восстановить исходный текст. Дополнительно в выходной поток записывается символ s, непосредственно следующий за совпавшей строкой буфера. Смысл этого символа прост – он позволяет пополнять словарь на приемной стороне новыми фразами, в частности, содержащими новые символы, которых еще нет в словаре.
Для примера попробуем сжать строку «кот от окон отошел», в которой пробелы будем рассматривать как отдельные символы и обозначать «_». Длину буфера предположим равной 6 символам, а размер словаря предположим гораздо большим длины нашей строки, например, 1000 (так часто и бывает на практике).
Также предположим, что:
-если совпадений нет, то в качестве значения смещения используем 1, а в качестве длины совпадения – 0;
-нулевое смещение – i = 0 зарезервируем для конца кодирования.
|
|
|
|
Скользящее окно |
|
|
Совпадающая |
|
Закодированные |
||||
|
Шаг |
|
|
|
|
|
|
данные |
|
||||
|
|
|
|
|
|
|
фраза |
|
|
|
|||
|
|
|
|
Словарь |
Буфер |
|
|
i |
j |
|
s |
||
|
|
|
|
|
|
|
|
||||||
1 |
|
- |
кот_от |
- |
|
1 |
0 |
|
"к" |
||||
2 |
|
|
к |
от_от_о |
- |
|
1 |
0 |
|
"о" |
|||
3 |
|
|
ко |
т_от_ок |
- |
|
1 |
0 |
|
"т" |
|||
4 |
|
|
кот |
_от_око |
- |
|
1 |
0 |
|
"_" |
|||
5 |
|
|
кот_ |
от_окон |
|
"от_" |
1 |
3 |
|
"о" |
|||
6 |
|
|
кот_от_о |
кон_ото |
|
"ко" |
8 |
2 |
|
"н" |
|||
7 |
|
|
кот_от_окон |
_отошел |
|
"_от" |
7 |
3 |
|
"о" |
|||
8 |
|
|
кот_от_окон_ото |
шел |
- |
|
1 |
0 |
|
"ш" |
|||
9 |
|
|
кот_от_окон_отош |
ел |
- |
|
1 |
0 |
|
"е" |
|||
10 |
|
|
кот_от_окон_отоше |
л |
- |
|
1 |
0 |
|
"л" |
|||
11 |
|
|
кот_от_окон_отошел |
- |
|
- |
|
0 |
- |
|
- |
||
Для представления индекса i нам достаточно пяти битов, для длины совпадения j – 3 бита, а для символа s – один байт. Очевидно, что исходная строка в коде ASCII занимала 18 байтов, а после кодирования будет занимать: 10·(5+3+8) + 8 = 168 битов или 21 байт. Таким образом, для малой строки, когда словарь еще не заполнен, алгоритм Лемпеля-Зива оказывается более расточительным по сравнению с равномерным кодированием. Однако, на больших строках алгоритм показывает хорошие результаты.
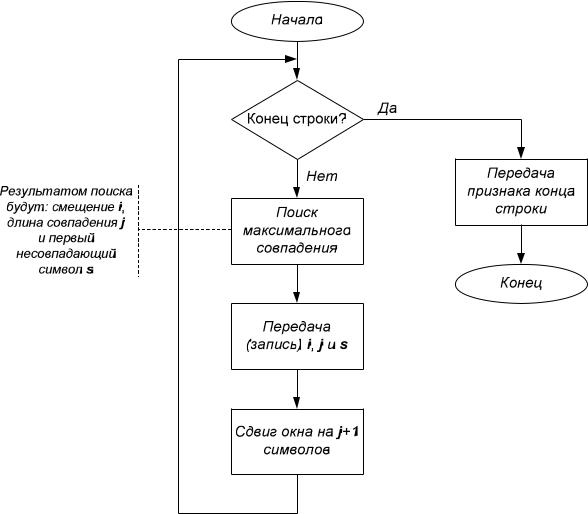
Рис. 4.2. Алгоритм кодирования при использовании LZ77
Для улучшения степени сжатия алгоритма можно использовать следующие приемы. Во-первых, для небольших текстов можно использовать небольшие значения смещения i, поскольку даже при размере словаря в 10 кбайт вряд ли потребуется 14 битов, хватит всего нескольких битов, как в нашем случае. Во-вторых, неправильно кодировать длину смещения равномерным кодом: по статистике чаще всего попадаются фразы длиной 6 символов, чуть реже – 4, 5 и 7 и т.д. Таким образом, полученные значения j также можно сжать с использованием того же метода Хаффмана.
Рис. 4.3. Алгоритм декодирования при использовании LZ77
В качестве итога можно заметить, что алгоритм LZ77 характеризуется значительно асимметричностью операций кодирования и декодирования: кодирование включает в себя достаточно емкую процедуру поиска фразы в словаре, тогда как декодирование осуществляется сравнительно просто – заменой индекса на фразу из словаря, то есть простым копированием.
4.2.2 Алгоритм сжатия LZ78
Впервые данный алгоритм был опубликован в статье 1978 года. Отличительной особенностью алгоритма LZ78 является то, что он не использует принцип скользящего окна и помещает в словарь не все переданные фразы, а только «перспективные» с точки зрения дальнейшего использования.
На каждом шаге в словарь добавляется новая фраза, которая представляет собой соединение (сцепку) одной из фраз словаря S, имеющей самое длинное совпадение со строкой буфера, и символа s. Причем символ s представляет собой символ, следующий за строкой буфера, для которой найдена совпадающая фраза S. Словарь в LZ78 гораздо более компактен, в нем нет повторяющихся фраз.
Алгоритм считывает символы сообщения до тех пор, пока накапливаемая подстрока входит целиком в одну из фраз словаря. Как только эта строка перестает соответствовать хотя бы одной фразе словаря, алгоритм генерирует код, состоящий из индекса строки в словаре и символа, нарушившего совпадение. Затем в словарь добавляется введенная подстрока и новый символ.
На выходе кодера получается только последовательность индексов фраз из словаря S и символов s.
В начале обработки словарь обычно пуст, а после он заполняется новыми фразами и может расти теоретически до бесконечности. На практике же размер словаря ограничивают и при достижении его конца подвергают полной или частичной очистке. Например, из словаря может удаляться наименее используемая фраза.
Для примера закодируем знакомую нам фразу «кот от окон отошел». Для алгоритма LZ78 буфер в принципе не требуется, поэтому будем его изображать для большей понятности алгоритма. Индекс 0 зарезервируем для признака конца строки, а индекс 1 будет обозначать пустую фразу словаря (отсутствие повтора).
|
|
|
Добавляемая в |
|
|
|
|
Совпадающая |
|
Закодированные |
|||
|
Шаг |
|
словарь фраза |
|
Буфер |
|
|
|
|
данные |
|||
|
|
|
|
|
фраза |
|
|
||||||
|
|
|
Индекс |
Фраза |
|
|
|
|
|
n |
|
s |
|
|
|
|
|
|
|
|
|
|
|
||||
1 |
|
2 |
к |
|
кот_от |
- |
|
1 |
|
"к" |
|||
2 |
|
3 |
о |
|
от_от_ |
- |
|
1 |
|
"о" |
|||
3 |
|
4 |
т |
|
т_от_о |
- |
|
1 |
|
"т" |
|||
4 |
|
5 |
_ |
|
_от_ок |
- |
|
1 |
|
"_" |
|||
5 |
|
6 |
от |
|
от_око |
|
о |
3 |
|
"т" |
|||
6 |
|
7 |
_о |
|
_окон_ |
_ |
|
5 |
|
"о" |
|||
7 |
|
8 |
ко |
|
кон_от |
|
к |
2 |
|
"о" |
|||
8 |
|
9 |
н |
|
н_отош |
- |
|
1 |
|
"н" |
|||
9 |
|
10 |
_от |
|
_отоше |
|
_о |
7 |
|
"т" |
|||
10 |
|
11 |
ош |
|
ошел |
|
о |
3 |
|
"ш" |
|||
11 |
12 |
е |
ел |
- |
1 |
"е" |
12 |
13 |
л |
л |
- |
1 |
"л" |
Для передачи строки из 18 байтов нам потребовалось: 12·(4+8)+4 = 148 |
||
битов или 18,5 байтов. Ниже приведен алгоритм работы кодера и декодера |
||
соответственно. |
|
|
|
Начало |
|
|
Конец строки? |
Да |
|
Нет |
Передача |
|
|
признака конца |
|
Прием (чтение) |
строки |
|
очередного |
|
Пытаемся найти в |
символа s |
|
|
|
|
словаре фразу, |
|
Конец |
представляющую собой |
|
|
соединение |
|
|
родительской фразы с |
Поиск фразы в |
|
номером n и символа s - |
|
|
F(n)+s словаре |
|
|
F(n)+s. |
|
|
|
|
|
Если такая фраза |
|
|
найдена, то функция |
|
|
возвращает её индекс |
|
|
(номер), иначе просто 1. |
|
|
|
Фраза найдена? |
Нет |
|
Да |
Передача |
|
Присвоить |
(запись) n и s |
|
|
|
|
n = индексу |
|
|
найденной |
|
|
совпадающей |
|
|
фразы словаря |
Добавляем фразу |
|
|
n+s в словарь |
|
Продолжить |
|
|
поиск |
|
|
совпадающей |
|
|
фразы |
n = 1 |
|
максимальной |
|
|
длины |
|
Рис. 4.4. Алгоритм кодирования при использовании LZ78 |
||
Таким образом, в отличие от алгоритма LZ77, в данном случае операция декодирования ненамного проще кодирования. Но зато для реализации процедур кодирования и декодирования требуется гораздо меньше памяти.
Коэффициент сжатия колеблется в пределах от 3,5 до 5 битов на символ. Также было замечено одно очень интересное свойство алгоритма LZ78: если исходные данные порождены источником с определенными характеристиками, а именно – он должен быть стационарным (многомерные распределения вероятностей появления слов длиной n символов не меняются во времени, причем n – любое конечное число) и эргодическим (среднее по времени равно среднему по числу реализаций, иными словами для оценки свойств источника достаточно только одной длинной реализации вместо нескольких), то коэффициент сжатия приближается по мере кодирования к максимально возможному. Иными словами, число битов на символ стремится в этом случае к энтропии. Однако это теоретические выкладки и следует также помнить, что сходится он к энтропии достаточно медленно, а кроме того большинство реальных текстов слишком коротки для этого. Кроме того, далеко не каждый источник обладает указанными свойствами.
Также было теоретически доказано, что подобной сходимостью обладает и алгоритм LZ77, однако сходится он гораздо медленнее.
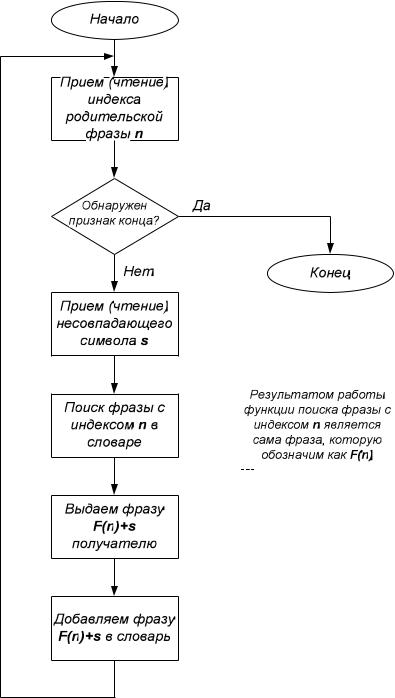
Рис. 4.5. Алгоритм декодирования при использовании LZ78
Следует также заметить, что замедленное распространение алгоритма сжатия LZ78 объясняется также патентными ограничениями, существовавшими в отношении данного алгоритма. Алгоритм LZ77 свободен от патентных ограничений, поэтому широко использовался разработчиками архиваторов для создания различных модификаций.

4.3 Арифметическое сжатие
Арифметическое сжатие является одним из наиболее эффективных методов сжатия, но до некоторого времени его применение сдерживалось патентными ограничениями. Однако, с окончанием срока действия данных патентных ограничений, арифметическое сжатие стало широко использоваться в современных архиваторах и постепенно вытеснять метод Хаффмана.
Дело в том, что метод Хаффмана обеспечивает наиболее эффективное сжатие, близкое к энтропии, только при определенных частотах появления символов, кратных степени двойки (например, если для символов a, b, c и d с вероятностями ½, ¼, 1/8 и 1/8 использовались коды 1, 01, 001 и 000). В теории наилучшее сжатие можно достигнуть, если кодировать каждый символ, встречающийся с относительной частотой f, с помощью – log2(f) битов.
Рис. 4.6. График сравнения кодирования по методу Хаффмана (ступенчатая кривая) с оптимальным кодированием (гладкая кривая)
Как видно из графика, если частоты появления символов отличаются от степеней двойки, то сжатие получается менее эффективным (рис. 4.6). Так, если необходимо закодировать два символа – a и b с вероятностями 5/1000 и 995/1000, то в идеальном случае на цепочку из 1000 символов требуется потратить – log2(5/1000)·5 – log2(995/1000)·995 = 7,644·5 + 0,007·995 = 38,22 + 6,965 = 45,185 битов. Если же применим код Хаффмана, то a и b будем кодировать 1 и 0, поэтому в итоге получим 1·5 + 1·995=1000 битов. Таким образом, получим код, превосходящий энтропию в 20 раз.
Арифметическое сжатие представляет собой очень интересный метод, в котором весь передаваемый текст представляется в виде дроби. Для
удобства кодирования будем рассматривать построение дроби на интервале [0, 1), где 0 – включается в интервал, а 1 – нет. Весь интервал или отрезок разбивается на подынтервалы с длинами, равными вероятностям появления символов текста.
Для примера рассмотрим сжатия текста «КАТАКАНА». Рассчитаем вероятности появления каждого символа в этом тексте (табл. 4.4).
Таблица 4.4
Вероятности появления символов и границы подынтервалов каждого символа
Символ |
Частота |
Вероятность |
Диапазон |
|
А |
4 |
0.5 |
[0.0, 0.5) |
|
К |
2 |
0.25 |
[0.5, |
0.75) |
Т |
1 |
0.125 |
[0.75, |
0.875) |
Н |
1 |
0.125 |
[0.875, 1) |
|
Процесс кодирования заключается в постепенном уменьшении длительности интервала. При кодировании первого символа в качестве рабочего интервала выбирается отрезок [0, 1). В дальнейшем он разбивается на подынтервалы в соответствии с вероятностями появления символов текста, а в качестве следующего рабочего интервала выбирается диапазон, соответствующий текущему кодируемому символу «К», в данном случае это
– [0.5, 0.75). Длина данного интервала пропорциональна вероятности появления символа «К».
После этого та же самая процедура повторяется для второго символа – «А». За начальный интервал в данном случае принимается промежуток [0.5, 0.75), полученный на предыдущем шаге. И вновь данный промежуток разбивается на подынтервалы в соответствии с вероятностями появления символов и вновь выбирается участок, соответствующий очередной передаваемой букве – «А». В данном случае границы нового интервала приведены на рис. 4.7.