

296 |
Глава 11. Алгоритмы обработки данных |
не могут быть обработаны одной нодой, обычно используется термин большие данные (Big Data).
zz Скорость (Velocity) обозначает скорость, с которой генерируются новые данные. Обычно высокоскоростные данные называют «горячими данными» или «горячим потоком», а низкоскоростные — «холодными данными» или «холодным потоком». Во многих приложениях данные будут представлять собой смесь горячих и холодных потоков, которые сначала необходимо под готовить и объединить в сводную таблицу и только потом использовать в алгоритме.
zzРазнообразие (Variety) относится к различным типам структурированных и неструктурированных данных, которые необходимо объединить в таблицу, прежде чем они могут быть использованы алгоритмом.
В следующем разделе представлены связанные с этим компромиссы и различные варианты разработки алгоритмов хранения.
АЛГОРИТМЫ ХРАНЕНИЯ ДАННЫХ
Надежное и эффективное хранилище данных — это сердце распределенной системы. Если хранилище создано для аналитики, то оно также называется озером данных (data lake). Хранилище объединяет в одном месте данные из разных предметных областей. Прежде всего разберем некоторые вопросы, свя занные с хранением данных в распределенной системе.
Стратегии хранения данных
В первые годы цифровой эры для проектирования хранилища данных использо валась однонодовая архитектура. По мере роста объемов данных основным спо собом стало распределенное хранение. Правильная стратегия хранения данных в распределенной среде зависит от типа данных и ожидаемой схемы их исполь зования, а также от их нефункциональных требований. Для анализа требований к распределенному хранилищу нам понадобится теорема CAP. Она даст основу для разработки стратегии хранения данных в распределенной системе.
Теорема CAP
В 1998 году Эрик Брюер предложил теорему, которая позже стала известна как теорема CAP. В ней освещаются различные компромиссы, связанные с разра боткой распределенной системы хранения данных.
Алгоритмы хранения данных |
297 |
Чтобы понять теорему CAP, определим следующие три характеристики распре деленных систем хранения данных: согласованность, доступность и устойчивость к разделению. CAP — это аббревиатура, состоящая из первых букв этих понятий:
zz Согласованность (consistency, C). Распределенное хранилище состоит из ряда нод. Любая из этих нод может использоваться для чтения, записи или об новления записей. Согласованность гарантирует, что в определенное время t1 независимо от того, какую ноду мы используем для чтения данных, мы полу чим одинаковый результат.
Каждая операция чтения либо возвращает последние данные, согласованные в рамках распределенной системы, либо выдает сообщение об ошибке.
zz Доступность (availability, A). Эта характеристика гарантирует, что любая нода в распределенной системе способна немедленно обработать запрос с со гласованностью или без нее.
zzУстойчивость к разделению (partition tolerance, P). В распределенной систе ме несколько нод соединены через коммуникационную сеть. Устойчивость к разделению гарантирует, что в случае сбоя связи между небольшим под множеством нод (одной или несколькими) система останется работоспособ ной. Обратите внимание, что для обеспечения устойчивости к разделению данные должны быть реплицированы на достаточное количество нод.
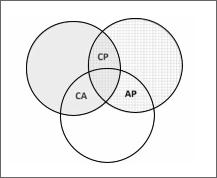
Используя эти характеристики, теорема CAP обобщает компромиссы, связанные с архитектурой и дизайном распределенной системы. В частности, теорема CAP гласит, что система хранения может обладать только двумя характеристиками из представленных.
Это демонстрируется на следующей схеме (рис. 11.1).
C- |
|
|
|
||
|
||
|
||
|
|
Рис. 11.1
298 |
Глава 11. Алгоритмы обработки данных |
Соответственно, существуют три типа распределенных систем хранения данных:
zz система CA (согласованность + доступность);
zz система AP (устойчивость к разделению + доступность); zzсистема CP (согласованность + устойчивость к разделению).
Рассмотрим их по очереди.
Системы CA
Традиционные системы с одной нодой — это системы CA: если система не яв ляется распределенной, то незачем беспокоиться об устойчивости к разделению. В этом случае система обладает согласованностью и доступностью.
Базы данных с одной нодой, такие как Oracle или MySQL, являются примерами систем CA.
Системы AP
Системы AP — распределенные системы хранения, направленные на доступ ность. Это высокочувствительные системы, способные жертвовать согласован ностью, если нужно, для размещения высокоскоростных данных. Благодаря этому системы AP подходят для немедленной обработки запросов пользовате лей. Типичными запросами являются чтение или запись быстро меняющихся данных. Обычно AP используются в системах мониторинга в реальном времени, таких как сенсорные сети.
Высокоскоростная распределенная база данных Cassandra служит хорошим примером системы AP.
Давайте выясним‚ как можно использовать систему AP. Например, Transport Canada намеревается отслеживать движение на одной из автомагистралей в От таве с помощью сети датчиков, установленных в разных местах на шоссе. В этом случае лучшим решением будет использование системы AP для распределен ного хранения данных.
Системы CP
Системы CP обладают как согласованностью, так и устойчивостью к разделению. Они гарантируют согласованность до того момента, пока процесс чтения не извлечет значение.
Типичный случай использования систем CP — это хранение текстовых файлов в формате JSON. Хранилища документов, такие как MongoDB, являются систе