

Алгоритмы классификации |
197 |
X представляет вектор признаков и содержит все входные переменные, необхо димые для обучения модели.
Разделение набора данных на контрольную и обучающую части
Теперь разделим набор данных на контрольные (25 %) и обучающие дан ные (75 %) с помощью sklearn.model_selection import train_test_split:
#from sklearn.cross_validation import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.25, random_state = 0)
Это приведет к созданию следующих четырех структур данных:
zz X_train: структура данных, содержащая признаки обучающих данных; zz X_test: структура данных, содержащая признаки контрольных данных;
zz y_train: вектор, содержащий значения метки в наборе обучающих данных; zz y_test: вектор, содержащий значения метки в наборе контрольных данных.
Масштабирование признаков
Для многих алгоритмов машинного обучения рекомендуется масштабировать переменные от 0 до 1. Это также называется нормализацией признаков. Применим масштабирование:
from sklearn.preprocessing import StandardScaler sc = StandardScaler()
X_train = sc.fit_transform(X_train) X_test = sc.transform(X_test)
Теперь данные готовы к использованию в качестве входных для классификато ров, о которых мы поговорим в следующих разделах.
Оценка классификаторов
Как только модель обучена, нужно оценить ее производительность. Для этого сделаем следующее:
1.Разделим размеченный набор данных на две части — для обучения и для контроля. Контрольная часть используется для оценки обученной модели.
2.С помощью признаков контрольной части создадим метку для каждой стро ки. Получим набор предсказанных меток.
3.Чтобы оценить модель‚ сравним предсказанные метки с фактическими.
198 |
Глава 7. Традиционные алгоритмы обучения с учителем |
Если задача не слишком примитивна, при оценке модели будут допу щены некоторые ошибки классификации. Интерпретация этих ошибок зависит от выбора метрик производительности.
Получив наборы как фактических, так и предсказанных меток, можно переходить к оценке модели с помощью метрик производительности. Выбор наилучшей метрики для количественной оценки модели зависит от требований поставлен ной бизнес-задачи, а также от характеристик набора обучающих данных.
Матрица ошибок
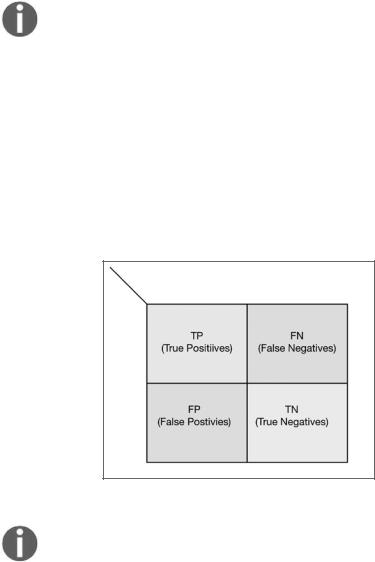
Матрица ошибок (confusion matrix) используется для обобщения результатов оценки классификатора. Матрица ошибок для бинарного классификатора вы глядит следующим образом (рис. 7.4).
Рис. 7.4
Если метка классификатора, который мы обучаем, имеет два уровня, он называется двоичным, или бинарным, классификатором. Первое критически важное использование машинного обучения с учителем относится к Первой мировой войне: двоичный классификатор был применен для различения самолетов и летящих птиц.
Результаты классификации можно разделить на четыре категории:
zz Истинно положительные (true positives, TP). Верно классифицированный положительный пример.

Алгоритмы классификации |
199 |
zz Истинно отрицательные (true negative, TN). Верно классифицированный отрицательный пример.
zz Ложноположительные (false positive, FP). Отрицательный пример, класси фицированный как положительный.
zzЛожноотрицательные (false negative, FN). Положительный пример, класси фицированный как отрицательный.
В следующем разделе мы научимся использовать эти четыре категории для определения различных показателей производительности.
Метрики производительности
Метрики производительности используются для количественной оценки каче ства работы обученных моделей. Исходя из этого, определим следующие четы ре показателя (табл. 7.3).
Таблица 7.3
Метрика Формула
Доля правильных ответов (accuracy)
Полнота (recall)
Точность (precision)
F-мера (F1 score)
Доля правильных ответов — это процент корректных классификаций среди всех прогнозов. При расчете этой метрики разница между TP и TN не учитывается. Оценка модели с точки зрения доли правильных ответов проста, но в опреде ленных случаях она не сработает.
Иногда для оценки производительности модели требуется нечто большее, чем доля правильных ответов. Одна из таких ситуаций — использование модели для прогнозирования редкого события, например:
zz предсказание мошеннических транзакций в банковской базе данных;
zzпредсказание вероятности механического отказа части двигателя воздушно го судна.

200 |
Глава 7. Традиционные алгоритмы обучения с учителем |
В обоих случаях мы пытаемся предсказать редкое событие. Для этого нам по надобятся дополнительные метрики — полнота и точность. Рассмотрим их подробнее.
zz Полнота. Отражает частоту попаданий. В первом примере это доля обнаружен ных и помеченных мошеннических транзакций среди всех таких транзакций. Допустим, в нашем контрольном наборе данных был 1 миллион транзакций, из которых 100 были заведомо мошенническими, и модель смогла идентифи цировать 78 из них. В этом случае значение полноты будет равно 78/100.
zzТочность. Измеряет, сколько транзакций, помеченных моделью, на самом деле являются мошенническими. Вместо того чтобы сосредоточиться на мошеннических транзакциях, которые модель не смогла выявить, мы хотим определить, насколько модель точна в своем выборе.
Обратите внимание, что F-мера объединяет полноту и точность: если эти по казатели идеальны, то и F-мера будет идеальной. Высокий балл F-меры означа ет, что мы подготовили качественную модель, которая обладает оптимальными полнотой и точностью.
Переобучение
Если модель МО дает отличный результат в среде разработки, но гораздо менее эффективна в производственной среде, это значит, что модель переобучена. Такая модель точно соответствует набору обучающих данных. Иными словами, правила, созданные моделью, чересчур детализированы. Лучше всего эту идею отражает дилемма смещения — дисперсии (bias — variance trade-off). Рассмотрим подробнее эти концепции.
Смещение
Любая модель МО обучается на основе определенных предположений. По сути, такие предположения — это аппроксимация явлений реального мира. Они упрощают фактические взаимосвязи между признаками и их характеристиками‚ что облегчает обучение модели. Большее количество предположений означает большее смещение (bias). При обучении модели сильные допущения дадут вы сокое смещение, а незначительные — низкое.
В линейной регрессии нелинейность признаков игнорируется, и они рассматриваются как линейные переменные. Таким образом, модели линейной регрессии по своей сути склонны демонстрировать высокое смещение.