

Структуры данных в Python |
51 |
СТРУКТУРЫ ДАННЫХ В PYTHON
Влюбом языке программирования структуры данных используются для хранения и управления сложными данными. В Python структуры данных — это контейнеры, позволяющие эффективно управлять данными, организо вывать их и осуществлять поиск. Они организованы в коллекции — группы элементов данных, которые требуется хранить и обрабатывать совместно.
ВPython существуют пять различных структур данных для хранения кол лекций:
zz Список (List). Упорядоченная изменяемая последовательность элементов.
zz Кортеж (Tuple). Упорядоченная неизменяемая последовательность элемен тов.
zz Множество (Set). Неупорядоченная последовательность элементов.
zz Словарь (Dictionary). Неупорядоченная последовательность пар «ключ — значение».
zzDataFrame. Двумерная структура для хранения двумерных данных.
Давайте рассмотрим их более подробно.
Список
В Python список — это основная структура данных, используемая для хранения изменяемой последовательности элементов.
Элементы данных в списке могут быть разных типов.
Чтобы создать список, элементы нужно заключить в квадратные скобки [ ] и разделить запятыми. Ниже представлен пример кода, который создает список из четырех элементов данных разных типов:
>>>aList = ["John", 33,"Toronto", True]
>>>print(aList)
['John', 33, 'Toronto', True]Ex
Список в Python — это удобный способ создания одномерных изменяемых структур данных, необходимых главным образом на различных внутренних этапах алгоритма.
52 |
Глава 2. Структуры данных, используемые в алгоритмах |
Использование списков
При работе со списками мы получаем полезные инструменты для управления данными.
Давайте посмотрим, что можно делать со списками.
zz Индексация списка. Поскольку положение каждого элемента в списке детер минировано, к нему можно получить доступ с помощью индекса. Следующий код демонстрирует этот принцип:
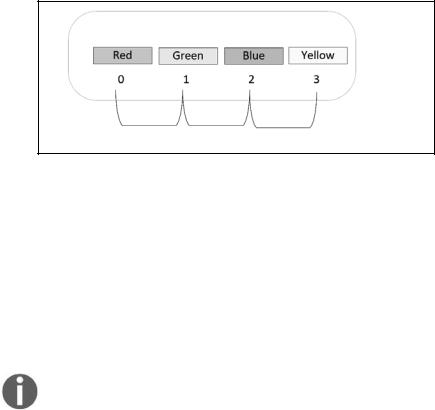
>>>bin_colors=['Red','Green','Blue','Yellow']
>>>bin_colors[1]
'Green'
Список из четырех элементов, созданный этим кодом, показан на рис. 2.1.
Значения
Индексы
Рис. 2.1
Обратите внимание, что индексация начинается с 0, поэтому второй элемент Green извлекается с помощью индекса 1: bin_color[1].
zz Срез списка. Извлечение подмножества элементов списка путем указания диапазона индексов называется срезом. Пример кода среза:
>>>bin_colors=['Red','Green','Blue','Yellow']
>>>bin_colors[0:2]
['Red', 'Green']
Cписок — одна из самых популярных одномерных структур данных в Python.
При срезе списка диапазон указывается следующим образом: первое число (включительно) и второе число (не включительно). Напри мер, bin_colors[0:2] будет включать bin_color[0] и bin_color[1], но не bin_color[2]. Следует учитывать это при использовании списков; не которые пользователи Python жалуются, что это не слишком очевидно.
Структуры данных в Python |
53 |
Рассмотрим следующий сниппет:
>>>bin_colors=['Red','Green','Blue','Yellow']
>>>bin_colors[2:]
['Blue', 'Yellow']
>>> bin_colors[:2]
['Red', 'Green']
Если в квадратных скобках не указан первый индекс‚ это означает начало списка, а если пропущен второй — конец списка. Выше мы видим пример та кого кода.
zz Отрицательная индексация. В Python имеются и отрицательные индек сы, которые отсчитываются от конца списка. Это показано в следующем коде:
>>>bin_colors=['Red','Green','Blue','Yellow']
>>>bin_colors[:-1]
['Red', 'Green', 'Blue']
>>>bin_colors[:-2]
['Red', 'Green']
>>>bin_colors[-2:-1]
['Blue']
Отрицательные индексы особенно полезны, когда в качестве точки отсчета мы хотим использовать последний элемент вместо первого.
zz Вложенность. Элемент списка может относиться к простому или сложному типу данных. Это позволяет создавать вложенные списки и дает возможность использовать потенциал итеративных и рекурсивных алгоритмов.
Рассмотрим пример списка внутри списка (вложенность):
>>>a = [1,2,[100,200,300],6]
>>>max(a[2])
300
>>> a[2][1]
200
zz Итерация. Python позволяет выполнять итерацию для каждого элемента в списке с помощью цикла for.
Это показано в следующем примере:
>>>bin_colors=['Red','Green','Blue','Yellow']
>>>for aColor in bin_colors:
print(aColor + " Square")
Red Square
Green Square
Blue Square Yellow Square
54 |
Глава 2. Структуры данных, используемые в алгоритмах |
Обратите внимание, что данный код выполняет итерацию по списку и ото бражает каждый элемент.
Лямбда-функции
Существует множество лямбда-функций, которые можно использовать в списках. Они особенно полезны в работе с алгоритмами и позволяют создавать функцию на лету. Иногда в литературе их также называют анонимными функциями. Рас смотрим их применение:
zz Фильтрация данных. Для фильтрации данных мы должны определить пре дикат — функцию, которая тестирует каждый аргумент и возвращает логи ческое значение. Пример использования такой функции:
>>> list(filter(lambda x: x > 100, [-5, 200, 300, -10, 10, 1000]))
[200, 300, 1000]
В данном коде мы фильтруем список с помощью лямбда-функции, которая задает критерии фильтрации. Функция filter() предназначена для отбора элементов из последовательности на основе определенного критерия и обыч но используется вместе с лямбда-функцией. Ее также можно применять для фильтрации элементов кортежей или наборов. В нашем примере заданным критерием является x > 100. Код проверяет все элементы списка и отсеивает те из них, которые не соответствуют этому критерию.
zz Преобразование данных. Функция map() используется для преобразования данных с помощью лямбда-функции. Пример:
>>> list(map(lambda x: x ** 2, [11, 22, 33, 44,55]))
[121, 484, 1089, 1936, 3025]
Использование функции map()вместе с лямбда-функцией открывает большие возможности. При этом лямбда-функция задает преобразователь, изменяющий каждый элемент последовательности. В приведенном примере преобразова телем выступает возведение во вторую степень. Таким образом, мы использу ем функцию map() для получения квадрата каждого элемента в списке.
zz Агрегирование данных. Для агрегирования данных используется reduce(), которая рекурсивно применяет функцию к паре значений для каждого эле мента списка:
from functools import reduce def doSum(x1,x2):
return x1+x2
x = reduce(doSum, [100, 122, 33, 4, 5, 6])
Структуры данных в Python |
55 |
Обратите внимание, что для reduce() необходимо определить функцию агрегирования данных. В приведенном примере кода такой функцией явля ется functools. Она определяет, как именно нужно агрегировать элементы данного списка. Агрегирование начинается с первых двух элементов, а его результат заменяет эти два элемента. Процесс сокращения будет происходить до тех пор, пока не останется одно агрегированное число. x1 и x2 в функции doSum() представляют собой пару чисел для каждой итерации; doSum() яв ляется критерием агрегирования.
В результате мы получаем единое значение (равное 270).
Функция range
С помощью функции range()можно легко сгенерировать большой список чисел. Она используется для автоматического добавления последовательностей чисел в список.
Функцию range() очень просто использовать — нужно только указать коли чество элементов, которые мы хотим видеть в списке. По умолчанию после довательность начинается с нуля и далее увеличивается с шагом, равным единице:
>>>x = range(6)
>>>x
[0,1,2,3,4,5]
Мы также можем указать конечное число и шаг, например:
>>>oddNum = range(3,29,2)
>>>oddNum
[3, 5, 7, 9, 11, 13, 15, 17, 19, 21, 23, 25, 27]
В результате получим нечетные числа от 3 до 27.
Временная сложность списков
Временную сложность различных функций списка можно обобщить, используя нотацию «О-большое» (табл. 2.1).
Чем больше список, тем больше времени требуется на выполнение операций, представленных в таблице. Это не касается только вставки элемента. По мере увеличения списка влияние на производительность становится все более вы раженным.