

Алгоритм PageRank |
111 |
|
|
|
|
Рис. 4.8
Жадный алгоритм основан на эвристике, и нет никаких доказательств того, что решение будет оптимальным.
Теперь ознакомимся с архитектурой алгоритма PageRank.
АЛГОРИТМ PAGERANK
В качестве практического примера рассмотрим алгоритм PageRank, который изначально использовался Google для ранжирования результатов поиска по пользовательскому запросу. Он генерирует число, которое количественно опре деляет релевантность результатов поиска по запросу пользователя. Алгоритм был разработан в Стэнфорде в конце 1990-х годов двумя аспирантами, Ларри Пейджем и Сергеем Брином, которые позже основали Google.
Алгоритм PageRank был назван в честь Ларри Пейджа (Page), который создал его вместе с Сергеем Брином во время учебы в Стэнфордском университете.
112 |
Глава 4. Разработка алгоритмов |
Прежде всего необходимо сформулировать задачу, для которой PageRank был изначально разработан.
Постановка задачи
Всякий раз, когда мы вводим запрос в поисковую систему в интернете, мы полу чаем большое количество результатов. Чтобы сделать результаты полезными для конечного пользователя, необходимо отсортировать веб-страницы по ряду критериев. Отображаемые результаты ранжируются согласно критериям, за данным базовым алгоритмом.
Реализация алгоритма PageRank
Главная составляющая алгоритма PageRank — поиск наилучшего способа из мерения релевантности каждой страницы, возвращаемой в результатах запроса. Для вычисления числа от 0 до 1, которое количественно отражает релевантность конкретной страницы, алгоритм учитывает два компонента информации:
zz Информация, непосредственно относящаяся к пользовательскому запросу. Этот компонент оценивает в контексте запроса, насколько релевантно со держимое веб-страницы. Содержание страницы напрямую зависит от автора страницы.
zzИнформация, которая не относится непосредственно к пользовательскому запросу. Данный компонент пытается количественно оценить релевантность каждой веб-страницы в контексте ее ссылок, просмотров и соседних страниц. Этот компонент трудно рассчитать, так как веб-страницы неоднородны и трудно разработать общие для всей сети критерии.
Чтобы реализовать алгоритм PageRank на Python, сначала импортируем необ ходимые библиотеки:
import numpy as np import networkx as nx
import matplotlib.pyplot as plt %matplotlib inline
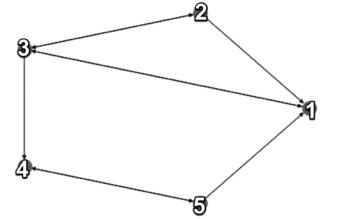
В демонстрационных целях мы будем анализировать только пять веб-страниц в сети. Назовем этот набор страниц myPages, и пусть они находятся в сети с име нем myWeb:
Алгоритм PageRank |
113 |
myWeb = nx.DiGraph() myPages = range(1,5)
Соединим их случайным образом, чтобы смоделировать реальную сеть:
connections = [(1,3),(2,1),(2,3),(3,1),(3,2),(3,4),(4,5),(5,1),(5,4)] myWeb.add_nodes_from(myPages)
myWeb.add_edges_from(connections)
Теперь давайте построим следующий график:
pos=nx.shell_layout(myWeb)
nx.draw(myWeb, pos, arrows=True, with_labels=True) plt.show()
Это создаст визуальное представление нашей сети (рис. 4.9).
Рис. 4.9
В алгоритме PageRank шаблоны веб-страницы содержатся в матрице, называе мой матрицей переходов (transition matrix). Существуют алгоритмы, которые постоянно обновляют матрицу переходов, фиксируя непрерывно меняющееся состояние сети. Размер матрицы переходов равен n × n, где n — количество вер шин. Числа в матрице обозначают вероятность того, что далее посетитель перей дет на эту страницу по предыдущей ссылке.
На графике выше показана наша статическая сеть. Зададим функцию для со здания матрицы переходов (рис. 4.10).

114 |
Глава 4. Разработка алгоритмов |
|
|
|
|
|
|
|
Рис. 4.10
Обратите внимание, что эта функция вернет G, которая и представляет матри цу переходов для нашего графика.
Давайте сгенерируем матрицу переходов (рис. 4.11).
Рис. 4.11
Обратите внимание, что матрица переходов имеет размерность 5 × 5. Каждый столбец соответствует вершине графа. Например, столбец 2 описывает вторую вершину. Существует вероятность 0.5, что посетитель перейдет с вершины 2 на вершину 1 или вершину 3. Обратите внимание, что диагональ матрицы пере ходов содержит 0, так как на нашем графе нет ссылки от вершины к самой себе. В реальной сети такая ссылка вполне может быть.
Обратите внимание, что матрица переходов является разреженной матрицей. По мере увеличения числа вершин большинство ее значений будет равно 0.