

Практический пример — использование глубокого обучения |
257 |
zz Ускоряется процесс обучения модели.
zz При использовании проверенной и зарекомендовавшей себя модели общее качество нашей модели, скорее всего, улучшится.
zzПеренос обучения (transfer learning) решит проблему недостаточного объема обучающих данных.
Рассмотрим два практических примера.
zz Допустим, нам нужно обучить робота. Для тренировки модели нейронной сети мы используем симуляцию. В ней воссоздаются все те редкие события, с которыми почти невозможно столкнуться в реальности. Затем мы приме няем перенос обучения, чтобы обучить модель для реального мира.
zzПредположим, нам нужна модель, которая выявляет на видеотрансляции ноутбуки Apple и Windows. Уже существуют готовые надежные модели с от крытым исходным кодом для обнаружения объектов; эти модели умеют точно классифицировать различные предметы в видеопотоке. Можно ис пользовать такие модели в качестве отправной точки и идентифицировать объекты как ноутбуки. После этого мы дополнительно обучим модель раз личать ноутбуки Apple и Windows между собой.
В следующем разделе мы применим рассмотренные концепции для построения нейронной сети, классифицирующей фальшивые документы.
ПРАКТИЧЕСКИЙ ПРИМЕР — ИСПОЛЬЗОВАНИЕ ГЛУБОКОГО ОБУЧЕНИЯ ДЛЯ ВЫЯВЛЕНИЯ МОШЕННИЧЕСТВА
Использование методов машинного обучения для выявления фальшивых до кументов является актуальной и сложной областью исследований. Исследова тели пытаются понять, в какой степени для подобных целей можно использовать способность нейронных сетей распознавать шаблоны. Вместо ручного извлече ния атрибутов для некоторых архитектурных структур глубокого обучения можно использовать необработанные пиксели.
Методология
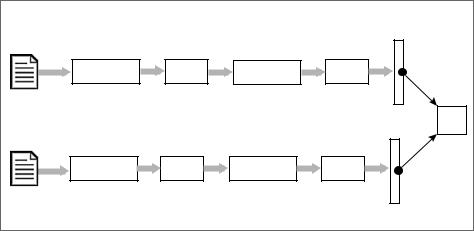
В методике, представленной в этом разделе, используется тип архитектуры нейронной сети, называемый сиамской нейронной сетью (Siamese neural network).
258 |
|
Глава 8. Алгоритмы нейронных сетей |
||
Эта сеть состоит из двух ветвей с одинаковой архитектурой и параметрами. |
||||
Использование сиамских нейронных сетей для маркировки фальшивых доку |
||||
ментов демонстрируется на следующей схеме (рис. 8.24). |
|
|||
|
|
|
|
|
1024 2014 1 |
|
|
1 |
|
|
|
|
|
|
|
|
|
|
|
Подлинный |
|
|
|
|
|
|
|
|
|
документ |
|
|
КС |
|
|
|
|
2 |
|
|
|
|
|
|
|
|
|
|
|
Проверяемый |
|
|
|
|
документ |
|
|
|
|
|
|
Рис. 8.24 |
|
|
Чтобы проверить документ на подлинность, нужно прежде всего классифици ровать его по макету и типу, а затем сравнить с образцом. Если отклонение превышает определенный порог, документ помечается как поддельный; в про тивном случае он считается подлинным или достоверным. В особо важных ситуациях может понадобиться сравнить документы вручную. Это касается пограничных случаев, когда алгоритм не может окончательно классифицировать документ как подлинный или поддельный.
Чтобы сравнить документ с образцом, используем две идентичные сверточные нейросети в нашей сиамской архитектуре. СНС имеют преимущество в обуче нии оптимальных детекторов локальных признаков, инвариантных к сдвигу. Они могут создавать представления, устойчивые к геометрическим искажениям входного изображения. Это хорошо подходит для нашей задачи, поскольку мы будем проводить подлинные и проверяемые документы через одну и ту же сеть, а затем сравнивать результаты на предмет сходства. Для достижения этой цели мы осуществим следующие шаги.
Давайте предположим, что мы хотим проверить документ. Для каждого класса документов мы выполняем следующие действия.
Практический пример — использование глубокого обучения |
259 |
1.Получить сохраненное изображение подлинного документа. Мы назовем его истинным документом. Проверяемый документ должен выглядеть как ис тинный.
2.Истинный документ передается через слои нейронной сети для создания век тора признаков, который является математическим представлением шаблонов истинного документа. Назовем его вектором признаков 1 (см. схему выше).
3.Документ, который необходимо протестировать, называется проверяемым документом. Мы передаем его через нейронную сеть, идентичную той, кото рая использовалась для создания вектора признаков истинного документа. Вектор признаков проверяемого документа назовем вектором признаков 2.
4.Используем евклидово расстояние между вектором признаков 1 и вектором признаков 2 для вычисления показателя сходства между истинным и про веряемым документами. Показатель сходства называется коэффициентом сходства, КС (или MOS — measure of similarity). КС — это число в диапазоне от 0 до 1. Большее число означает меньшее расстояние между документами и большую вероятность того, что документы похожи.
5.Если показатель сходства, рассчитанный нейронной сетью, ниже заранее определенного порога, мы помечаем документ как поддельный.
Реализуем сиамскую нейронную сеть с помощью Python.
1. Импортируем необходимые библиотеки Python:
import random import numpy as np
import tensorflow as tf
2.Определим нейронную сеть, которая будет использоваться для обработки каждой из ветвей сиамской сети:
def createTemplate():
return tf.keras.models.Sequential([ tf.keras.layers.Flatten(), tf.keras.layers.Dense(128, activation='relu'), tf.keras.layers.Dropout(0.15), tf.keras.layers.Dense(128, activation='relu'), tf.keras.layers.Dropout(0.15), tf.keras.layers.Dense(64, activation='relu'), ])
Обратите внимание, что мы указали коэффициент dropout = 0.15(dropout — исключение некоторого количества нейронов в процессе обучения для из бежания переобучения).
260 |
Глава 8. Алгоритмы нейронных сетей |
3.Для реализации сиамской сети мы будем использовать изображения из базы данных MNIST. Они идеально подходят для проверки эффективности на шего подхода. Необходимо подготовить данные: каждый образец должен иметь два изображения и флаг бинарного сходства. Этот флаг является по казателем того, что изображения принадлежат к одному классу. Теперь реа лизуем функцию подготовки данных под названием prepareData():
def prepareData(inputs: np.ndarray, labels: np.ndarray): classesNumbers = 10
digitalIdx = [np.where(labels == i)[0] for i in range(classesNumbers)]
pairs = list() labels = list()
n = min([len(digitalIdx[d]) for d in range(classesNumbers)])
- 1
for d in range(classesNumbers): for i in range(n):
z1, z2 = digitalIdx[d][i], digitalIdx[d][i + 1] pairs += [[inputs[z1], inputs[z2]]]
inc = random.randrange(1, classesNumbers) dn = (d + inc) % classesNumbers
z1, z2 = digitalIdx[d][i], digitalIdx[dn][i] pairs += [[inputs[z1], inputs[z2]]]
labels += [1, 0]
return np.array(pairs), np.array(labels, dtype=np.float32)
Обратите внимание, что prepareData() приведет к равному количеству об разцов для всех чисел.
4. Подготовим обучающие и контрольные наборы данных:
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data() x_train = x_train.astype(np.float32) x_test = x_test.astype(np.float32) x_train /= 255
x_test /= 255
input_shape = x_train.shape[1:]
train_pairs, tr_labels = prepareData(x_train, y_train) test_pairs, test_labels = prepareData(x_test, y_test)
5. Теперь создадим две половины сиамской системы:
input_a = tf.keras.layers.Input(shape=input_shape) enconder1 = base_network(input_a)
input_b = tf.keras.layers.Input(shape=input_shape) enconder2 = base_network(input_b)
6.Реализуем коэффициент сходства (measureOfSimilarity), который количе ственно определит разницу между двумя документами, которые мы сравни ваем: