

164 |
Глава 6. Алгоритмы машинного обучения без учителя |
|
|
|
|
|
|
|
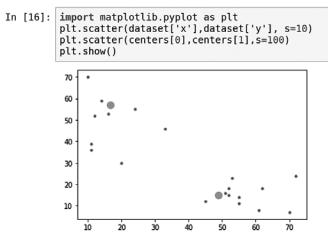
Рис. 6.10
Обратите внимание, что большие точки на графике являются центроидами, которые определил алгоритм k-средних.
Ограничения кластеризации методом k-средних
Алгоритм k-средних разработан как простой и быстрый алгоритм. Но из-за преднамеренной простоты в архитектуре он имеет ряд ограничений:
zz Самое большое ограничение: количество кластеров должно быть заранее определено.
zz Первоначальное назначение центров кластеров является случайным. Таким образом, при каждом запуске алгоритм может давать несколько разные кла стеры.
zz Каждая точка данных привязывается только к одному кластеру. zz Кластеризация методом k-средних чувствительна к выбросам.
Иерархическая кластеризация
Кластеризация методом k-средних реализует подход «сверху вниз», так как мы начинаем алгоритм с наиболее важных точек данных, которые служат центрами кластеров. Существует альтернативный подход к кластеризации, при котором вместо того, чтобы начинать сверху, мы запускаем алгоритм снизу. «Внизу» в этом контексте находится каждая отдельная точка данных в пространстве задачи.
Алгоритмы кластеризации |
165 |
Метод заключается в том, чтобы группировать похожие точки данных вместе по мере продвижения к центрам кластера. Подход «снизу вверх» используется ал горитмами иерархической кластеризации. Давайте рассмотрим его подробнее.
Этапы иерархической кластеризации
Иерархическая кластеризация состоит из следующих шагов:
1.Создаем отдельный кластер для каждой точки данных. Если наше простран ство задачи состоит из 100 точек данных, то алгоритм начнет со 100 класте ров.
2.Группируем только ближайшие друг к другу точки.
3.Проверяем условие остановки; если оно еще не выполнено, то повторяем шаг 2.
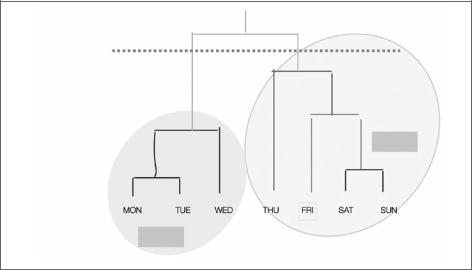
Полученная кластерная структура называется дендрограммой.
В дендрограмме высота вертикальных линий показывает, насколько близко расположены элементы (рис. 6.11).
2
1
Рис. 6.11
Обратите внимание, что условие остановки показано пунктирной линией на рисунке выше.

166 |
Глава 6. Алгоритмы машинного обучения без учителя |
Кодирование алгоритма иерархической кластеризации
Теперь давайте реализуем иерархический алгоритм на Python:
1.Сначала импортируем AgglomerativeClustering из библиотеки sklearn. cluster, а также пакеты pandas и numpy:
from sklearn.cluster import AgglomerativeClustering import pandas as pd
import numpy as np
2. Создадим 20 точек данных в двумерном пространстве задачи:
dataset = pd.DataFrame({ |
|
|
|
|||||
|
'x': [11, 21, |
28, 17, |
29, 33, 24, |
45, 45, 52, 51, 52, 55, |
53, |
|||
55, |
61, |
62, |
70, |
72, 10], |
|
|
|
|
|
'y': [39, 36, |
30, 52, |
53, 46, 55, |
59, 63, 70, 66, 63, 58, |
23, |
|||
14, |
8, |
18, 7, 24, |
10] |
|
|
|
||
}) |
|
|
|
|
|
|
|
|
3.Создадим иерархический кластер, указав гиперпараметры. Используем функцию fit_predict для фактической работы алгоритма:
cluster = AgglomerativeClustering(n_clusters=2, affinity='euclidean', linkage='ward') cluster.fit_predict(dataset)
4.Теперь рассмотрим связь каждой точки данных с двумя созданными класте рами (рис. 6.12).
Рис. 6.12
Вы можете увидеть, что кластеры используются похожим образом как в ие рархических алгоритмах, так и в алгоритмах k-средних.
Оценка кластеров
Цель качественной кластеризации состоит в том, чтобы точки данных, принад лежащие отдельным кластерам, были дифференцируемыми. Это подразумева ет следующее:
zz Точки данных, принадлежащие к одному и тому же кластеру, должны быть как можно более похожими.
Алгоритмы кластеризации |
167 |
zzТочки данных, принадлежащие к отдельным кластерам, должны быть как можно более отличающимися.
Иногда пользователь может самостоятельно оценить результаты кластеризации благодаря визуализации кластеров. Однако для количественной оценки качества кластеров существуют математические методы, например анализ силуэта. С его помощью сравниваются плотность и разделение в кластерах, созданных с по мощью алгоритма k-средних. График силуэта отображает близость каждой точки в определенном кластере по отношению к другим точкам в соседних кластерах. Каждому кластеру присваивается коэффициент в диапазоне [–0, 1]. В табл. 6.2 показано, что означают числа в этом диапазоне.
Таблица 6.2
Диапазон |
Значение |
Описание |
|
|
|
0.71–1.0 |
Отлично |
Кластеризация методом k-средних привела к созда |
|
|
нию групп, которые достаточно отличимы друг от |
|
|
друга |
|
|
|
0.51–0.70 |
Приемлемо |
Кластеризация методом k-средних привела к созда |
|
|
нию групп, которые более или менее отличимы друг |
|
|
от друга |
|
|
|
0.26–0.50 |
Слабо |
Кластеризация методом k-средних привела к группи |
|
|
ровке, но на качество результата полагаться не стоит |
|
|
|
< 0.25 |
Кластериза |
С имеющимися данными и при выбранных параме |
|
ции не |
трах не удалось провести кластеризацию методом |
|
обнаружено |
k-средних |
|
|
|
Обратите внимание, что каждый кластер в пространстве задачи получает от дельную оценку.
Применение кластеризации
Кластеризация используется везде, где нужно обнаружить базовые закономер ности в наборах данных.
Кластеризация может использоваться, например, в следующих областях госу дарственного управления:
zz Анализ очагов преступности. zzСоциально-демографический анализ.