

100 |
Глава 4. Разработка алгоритмов |
NP-полных задач не существует полиномиального решения. Предыдущая диа грамма основана на этом предположении.
Вопрос 3. Как алгоритм будет работать с большими наборами данных?
Для получения результата алгоритм обрабатывает данные определенным об разом. Как правило, по мере увеличения объема данных требуется все больше времени для их обработки и вычисления результатов. Существуют наборы данных, представляющие особую сложность для инфраструктур и алгоритмов из-за их объема, разнообразия и скорости. Иногда их обозначают термином «большие данные» (big data). Хорошо разработанный алгоритм должен быть масштабируемым: по возможности эффективно работать, использовать доступ ные ресурсы и генерировать правильные результаты в разумные сроки. Архи тектура алгоритма становится еще более важной при работе с большими дан ными. Чтобы количественно оценить масштабируемость алгоритма, необходимо учитывать следующие два аспекта:
zz Увеличение потребностей в ресурсах по мере роста объема входных данных. Оценка такого требования называется анализом пространственной сложности.
zzУвеличение времени, затрачиваемого на выполнение, по мере роста объема входных данных. Оценка данного параметра называется анализом временной сложности.
Мы живем в эпоху лавинообразного роста объемов данных. Термин «большие данные» стал общепринятым, поскольку он отражает размер и сложность данных, которые обычно требуется обрабатывать современным алгоритмам.
На этапе разработки и тестирования многие алгоритмы используют лишь не большую выборку данных‚ поэтому важно учитывать аспект масштабируемости. В частности, необходимо тщательно проанализировать (протестировать или спрогнозировать) то‚ как на производительность алгоритма повлияет увеличе ние объема данных.
ПОНИМАНИЕ АЛГОРИТМИЧЕСКИХ СТРАТЕГИЙ
Хороший алгоритм максимально оптимизирует использование доступных ре сурсов, по возможности разбивая задачу на более мелкие подзадачи. Существу ют различные алгоритмические стратегии для разработки алгоритмов.
Понимание алгоритмических стратегий |
101 |
В этом разделе мы рассмотрим:
zz стратегию «разделяй и властвуй»;
zz стратегию динамического программирования; zz стратегию жадного алгоритма.
Стратегия «разделяй и властвуй»
Одна из стратегий состоит в том, чтобы разделить большую задачу на более мелкие, которые можно решать независимо друг от друга. Промежуточные ре шения, полученные при работе с этими подзадачами, затем объединяются в итоговое решение. Это и называется стратегией «разделяй и властвуй».
Математически, если мы решаем задачу (P) с n входными данными, в рамках ко торой необходимо обработать набор данных d, мы разделяем ее на k подзадач, от P1 до Pk. Каждая из подзадач будет обрабатывать свой раздел набора данных, d. Как правило, у нас будут подзадачи от P1 до Pk, обрабатывающие данные от d1 до dk.
Обратимся к практическому примеру.
Практический пример — «разделяй и властвуй» применительно к Apache Spark
Apache Spark — это платформа с открытым исходным кодом, которую исполь зуют для решения сложных распределенных задач. В ней реализована стратегия «разделяй и властвуй». Задача делится на подзадачи, которые обрабатываются независимо. Мы продемонстрируем это на простом примере подсчета слов из списка.
Давайте предположим, что у нас имеется следующий список слов:
wordsList = [python, java, ottawa, news, java, ottawa]
Мы хотим подсчитать, сколько раз встречается каждое слово в этом списке‚ и для эффективного решения задачи применим стратегию «разделяй и властвуй».
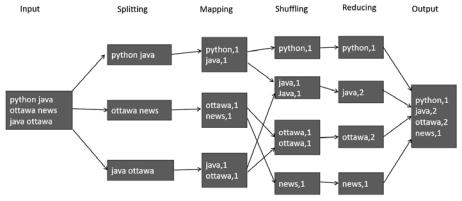
Реализация принципа «разделяй и властвуй» показана на рис. 4.4.
На рисунке показаны следующие этапы, на которые делится задача:
1.Разбиение (Splitting). Входные данные делятся на части (сплиты), которые могут обрабатываться независимо. Это называется разбиением. На рисунке мы видим три сплита.
102 |
Глава 4. Разработка алгоритмов |
|
|
|
|
Рис. 4.4
2.Маппинг (Mapping). Это любая операция, которую можно независимо при менить к каждому сплиту. Как видно на диаграмме, во время маппинга каж дое слово в сплите отображается в виде пары «ключ — значение». В нашем примере имеются три маппера, которые выполняются параллельно, в соот ветствии с тремя сплитами.
3.Перетасовка (Shuffling). Это процесс объединения одинаковых ключей. Как только аналогичные ключи объединены, к их значениям можно применять функции агрегирования. Обратите внимание, что перетасовка — это ресур соемкая операция, поскольку необходимо объединить аналогичные ключи, которые изначально могут быть разбросаны по сети.
4.Сокращение (Reducing). Выполнение функции агрегирования значений оди наковых ключей называется сокращением. На рисунке нам нужно подсчитать количество одинаковых слов.
Давайте посмотрим, как мы можем реализовать решение в коде. Чтобы проде монстрировать стратегию «разделяй и властвуй», нам понадобится платформа распределенных вычислений. Для этого запустим Python на Apache Spark.
1.Чтобы использовать Apache Spark, создадим контекст выполнения Apache Spark:
import findspark findspark.init()
from pyspark.sql import SparkSession
spark = SparkSession.builder.master("local[*]").getOrCreate() sc = spark.sparkContext
Понимание алгоритмических стратегий |
103 |
2.Теперь создадим демонстрационный список, содержащий несколько слов. Мы преобразуем этот список во встроенную распределенную структуру данных Spark, называемую устойчивым распределенным набором данных
(RDD, Resilient Distributed Dataset):
wordsList = ['python', 'java', 'ottawa', 'ottawa', 'java','news'] wordsRDD = sc.parallelize(wordsList, 4)
# Напечатать тип wordsRDD print (wordsRDD.collect())
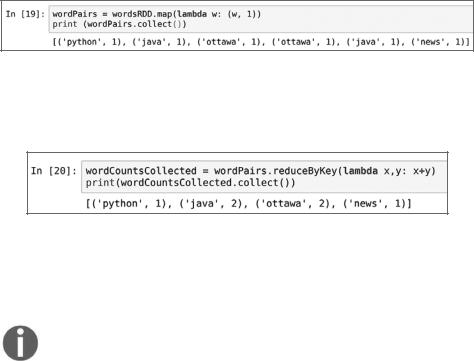
3.Далее используем функцию map(), чтобы преобразовать слова в пары «ключ — значение» (рис. 4.5).
Рис. 4.5
4.Наконец, используем функцию reduce() для агрегирования и получения конечного результата (рис. 4.6).
Рис. 4.6
Данный код демонстрирует, как мы можем использовать стратегию «разделяй и властвуй» для подсчета количества одинаковых слов.
Современные инфраструктуры облачных вычислений, такие как Microsoft Azure, Amazon Web Services и Google Cloud, обеспечивают масштабируемость за счет прямой или косвенной реализации страте гии «разделяй и властвуй».
Стратегия динамического программирования
Динамическое программирование — это стратегия, предложенная в 1950-х годах Ричардом Беллманом для оптимизации некоторых классов алгоритмов. В ее основе лежит интеллектуальный механизм кэширования, который пытается