

Точно Не проект 2 / Не books / Источник_1
.pdfКомпьютерное зрение |
591 |
|
|
мируют некоторый граф. В этом случае применяются методы сопоставления графов.
10.8.3.3D-методы
Вотличие от методов, рассмотренных выше и использующих только двумерные проекции трехмерных объектов, 3D-методы учитывают форму поверхности объектов в трехмерном пространстве. Форма поверхности может быть получена по нескольким полутоновым изображениям (сложно) или определена непосредственно по точкам с помощью датчика глубины (проще). Современные недорогие датчики глубины работают при структурированном освещении. Они проецируют последовательность специальных образов, состоящих из полос, на сцену. Камера воспринимает изображения деформированных полос, по которым можно определить глубину. Такой подход обобщает традиционный метод, использующий одну световую плоскость. После определения координат (x, y, z) точек, они представляются группами в виде участков поверхности (заплат) адекватной сложности. Этот шаг обеспечивает сжатие данных, а также сглаживание и упрощение запоминания изображения.
Модели объектов, используемые в ходе распознавания, представляются в памяти компьютера в виде участков поверхности. Сопоставление выполняется непосредственным сравнением восстанавливаемой поверхности с соответствующими поверхностными участками модели или сравнением на основе дедуктивных мер. В некоторых задачах можно обойтись полностью без моделей. В этом случае достаточно иметь представление сцены в виде участков поверхностей (заплат), чтобы установить возможность схватывания объекта манипулятором робота.
10.9.Примеры методов распознавания изображений
10.9.1.2D-методы, использующие глобальные признаки
Несколько версий промышленных систем зрения были разработаны в конце семидесятых годов в Стэнфордском научно-исследовательском институте Г. Эйджином и другими [65].
Проблема состояла в том, чтобы распознавать объекты, находящиеся в некотором рабочем пространстве или на ленте конвейера. При этом объекты не соприкасались друг с другом и не накладывались один на другой. Кроме этого, объекты были плоскими, а если какой-либо объект был
Компьютерное зрение |
593 |
|
|
10.9.2. 2D-методы, использующие локальные признаки
Модель объекта. Модель конструируется для каждого объекта и для каждого устойчивого положения объекта. Модель состоит из последовательности прямолинейных элементов и дуг, которые Перкинс называет связанными кривыми и которые вместе описывают внешние и внутренние контуры объекта [81]. Кроме того, для каждой из связанных кривых вычисляется список свойств. Модели строятся для “благоприятных” условий, которые означают, что изображение имеет хорошую контрастность, и объекты хорошо отделены от фона.
Извлечение признаков. Извлечению “связанных кривых” предшествует применение оператора градиента к полутоновому изображению (образу). Полученные ансамбли краевых пикселей уточняются и связываются в цепочки, образуя краевой сегмент. Эти краевые сегменты локально аппроксимируются отрезками прямых линий и дугами. Затем последовательности соприкасающихся прямолинейных сегментов и дуг идентифицируются, как связанные кривые, которые весьма эффективно описываются и представляются в памяти. Этот шаг не вызывает никаких проблем для случая построения модели при благоприятных условиях, т. е. при хорошем освещении и одиночных объектах. Каждой связанной кривой приписывается список свойств, который включает в себя полную длину, полное изменение угла от начала до конца, энергию изгиба (вычисляемую через кривизну) и др.
Распознавание. Выделение признаков на стадии распознавания, в принципе, выполняется так же, как и при создании моделей. Имеется одно отличие, состоящее в том, что теперь могут быть “неблагоприятные” условия. Это означает, что связанные кривые могут быть обнаружены на заднем плане, или что связанные кривые – фрагментированы. Кроме этого, при склеивании линейных сегментов и дуг, с целью получения связанных кривых, могут ошибочно использоваться элементы разных объектов. Поэтому необходимо проверять несколько возможных комбинаций. Процедура распознавания должна обеспечивать решение подобных проблем.
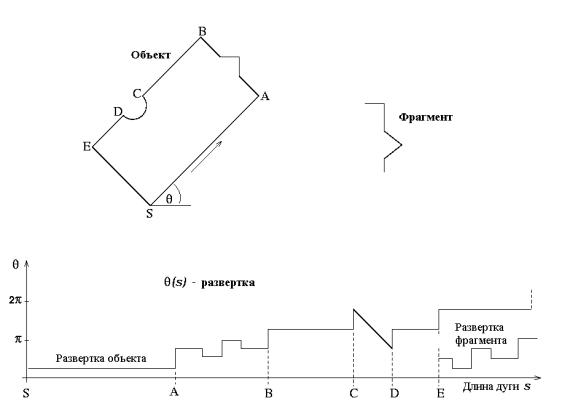
Сначала формируется список всевозможных пар связанных кривых модели и изображения. Степень подобия пар может быть определена на основе списка свойств для каждой связанной кривой. При образовании пар их просматривают одну за другой в порядке их ранжирования по критерию подобия. Для каждого соединения, пытаются найти такой поворот изображения связанной кривой, который даст лучшее совпадение с моделью связанной кривой. Это сравнение предпочтительно выполнять в ( ,s) - пространстве, где – текущий угол контура, а s – длина дуги (рисунок
10.27).
Компьютерное зрение |
595 |
|
|
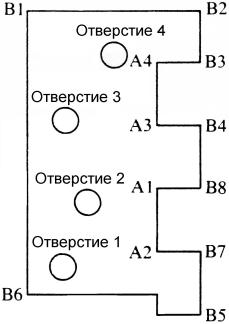
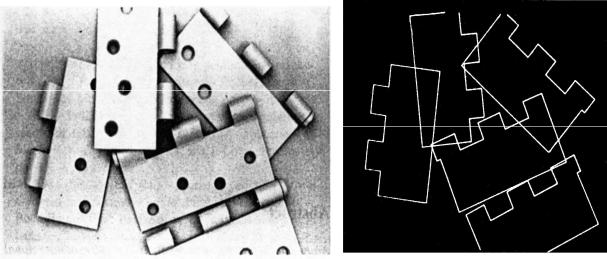
Боллес и Кэйн продемонстрировали их систему на примере класса объектов, представленного шарнирами, которые изображены на рисунке 10.28 вместе с соответствующими признаками. Использование графов отношений характерно для каждого аспекта метода, например, для модели объекта и её конкретизации.
Рисунок 10.28—Схематическое изображение шарнира
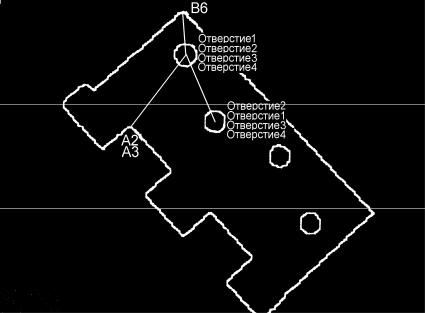
Модель объекта. Модель каждого объекта состоит из трех частей. Первая часть представляет собой контур объекта, аппроксимируемый многоугольником. Вторая часть – список локальных признаков, каждый из которых описывается уникальным именем, типом (из множества типов, которые являются подходящими для задачи распознавания), позицией и ориентацией по отношению к системе координат, связанной с объектом, а также соответствующими стандартными отклонениями. Третья часть спецификации объекта позволяет выделять каждое структурно различимое образование в пределах общего класса “шарнир”. Это характерно для каждого определенного типа признака, например, тип “отверстие” охватывает все возможные конкретизации этого признака во всех моделях шарнира, допустимых в некоторой задаче. Каждый возможный признак может выступать в роли “фокусирующего признака”. На рисунке 10.29 изображен фокусирующий признак, подходящий для распознавания части объекта, на примере шарнира. Данный признак вместе c ближайшими признаками и с учетом их взаимного положения позволяет генерировать хорошие гипотезы относительно экземпляра рассматриваемого объекта. С каждым структурно различимым образованием, соответствующим заданному признаку, связано описание в виде подграфа, содержащее достаточные “вторичные
Компьютерное зрение |
597 |
|
|
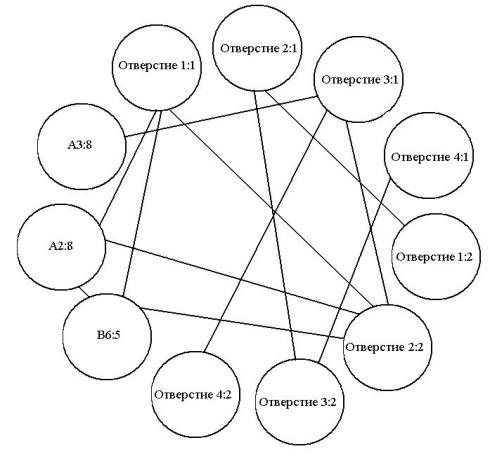
признаков, но не их отличительные особенности. Система устанавливает и обрабатывает множество меток для каждого из найденных признаков, которые совместимы со сведениями, полученными к этому моменту. Затем формируется список возможных соответствий. Этот список может быть представлен графом, в котором узлы представляют возможные признаки, а ребра объединяют признаки, совместимые друг с другом. На рисунке 10.30 изображен пример графа соответствий признаков объекта. При этом несколько соответствий конкурируют между собой за лучшую гипотезу объекта. Алгоритм находит самый большой кластер соответствий, совместимых друг с другом. Данный алгоритм называют алгоритмом максималь-
ной группировки.
Рисунок 10.30. – Граф соответствий
После этого становится возможной генерация гипотез относительно вида объекта, его ориентации и позиции. Для этого выполняются два проверочных шага:
-дальнейший поиск локальных признаков, позиция и ориентация которых могут быть предсказаны достаточно точно;
-преобразование построенного контура объекта в изображение в позиции, предсказанной в соответствии с гипотезой.
598 |
Глава 10 |
|
|
При этом в вертикальном направлении к контуру выполняется небольшое проверочное сечение. Аналогичная процедура используется в методе Перкинса (§10.9.2). Перемещаясь из внутренней области объекта к множеству внешних точек объекта, обнаруживают переход “темное – светлое”. Если имеет место перекрытие объектов, то обнаруживается комбинация “темное – темное”. Обнаружение двух других возможностей (из оставшихся) свидетельствует против гипотезы. После подтверждения гипотезы, используемые локальные признаки отмечаются как объясненные. Они не будут использоваться больше в поиске других объектов.
Метод Боллеса и Кэйна может обрабатывать частично перекрывающиеся объекты при условии, что видимые части объектов, т. е. не скрытые другими объектами, являются достаточно большими и содержат необходимые признаки (отверстия, углы, и т.д.), чтобы сделать попытку сопоставления результативной. На рисунках 9.31,a и 9.31,б показаны примеры успешного распознавания различных экземпляров перекрывающихся шарниров, демонстрирующие потенциальные возможности метода. Результаты распознавания могут в дальнейшем использоваться при управлении манипулятором робота.
а) б) Рисунок 10.31. – Результаты распознавания
10.9.4. Пример 3D-метода
Как следует из примеров систем, рассмотренных в предыдущих параграфах, методы анализа изображений для роботов, манипулирующих объектами, разрабатывались в течение многих лет. Большинство из методов основано на визуальных данных, т. е. данных, зафиксированных камерами, которые затем интерпретируются с помощью моделей объектов са-
Компьютерное зрение |
599 |
|
|
мой различной природы и используются для управления действиями робота, например, схватывания распознанных объектов.
Иным стимулом для развития методов анализа изображений стало появление новых типов датчиков и, следовательно, новых видов данных, например данных о глубине. Рассмотрим один из методов, использующий данные о глубине. В этом случае используется весьма простая модель объекта, и основное внимание уделяется действиям, которые могут выполняться системой. Это ближе к процессам, выполняемым естественным интеллектом. Рассмотрим систему, основанную на использовании данных датчиков глубины, разработанную в Швейцарском Федеральном Технологическом Институте [93] .
Сначала опишем входные данные, на которых базируется метод. Рассмотрим метод световой плоскости, позволяющий получать трехмерные данные. Для этого используется тонкий “световой лист”, который проецируется под некоторым углом к сцене и фиксируется камерой с различных направлений. Координаты изображения определяются в точке деформации проекции на основе уравнения прямой линии в трехмерном пространстве, проведенной к этой освещенной точке. Вместе с известным уравнением световой плоскости в трехмерном пространстве это позволяет вычислить x, y и z координаты точки. Без углубления в детали ясно, что этот базовый метод имеет несколько недостатков, которые необходимо устранять. Одна из идей предполагает отказ от использования центра световой плоскости в ходе обработки. Вместо этого лучше использовать границу между тенью и светом, которая определяется намного проще. Имеется большое число усовершенствований основного метода (и устройств). Современные датчики глубины имеют 1024 проекционных направления, реализуемых последовательностью изображений с полосами, проецируемыми одно за другим. Для этого в датчик глубины входит проектор полос, который последовательно во времени проецирует образы с полосами на сцену. Имеется также камера, фиксирующая сцену в направлении соответствующего проектора полосы и регистрирующая образы с полосами последовательно во времени. Для определения глубины изображения требуется ансамбль из n образов с полосами, например n=9 . Каждый образ с полосами характеризуется определенной шириной полос и их положением. Метод очень сложен, так как он использует встроенное кодирование направления проецирования. Для каждой точки сцены код направления можно определить по чередованию черного и белого цветов, которые фиксируются при последовательной подаче образов, что делает возможным решение задачи идентификации различных проекционных плоскостей. Это условие обеспечивает вычисление трехмерных координат точки освещенной проектором датчика глубины и в то же самое время фиксируемой его камерой.