

Точно Не проект 2 / Не books / Источник_1
.pdfЭкспертные системы |
411 |
|
|
иск заканчивается, иначе рекурсивно вызывается предикат найти(Н1,Х), и весь процесс повторяется. В результате поиска возвращается значение переменной Х, которое фиксирует возможную причину неисправности. Основной предикат, обеспечивающий запуск ЭС, можно определить следующим образом:
/* ЭС, основанная на фреймовой модели */
инициализация:- retractall(сообщено( _ , _ )), !. причина(автомобиль).
диагностика: – инициализация, причина(Н), /* гипотеза */ найти(Н, Х),
объект(Х, объяснения, Е), nl, write(E),
возврат.
диагностика: – nl, write(‘Больше нет гипотез’). возврат: – nl, nl, write(‘Следующее решение ?:’),
read(no).
Для приведенного фрагмента базы знаний можно получить следующее решение:
?- диагностика.
Что случилось с Вашим автомобилем?
1:не заводится
2:не едет
3:другое
1.
Температура ниже –20 ?
1:да
2:нет
1.
Низкая температура. Нагрейте двигатель. Следующее решение? да.
Больше нет гипотез.
Рассмотренная ЭС является простейшей, и она не использует в полной мере достоинства фреймовой модели представления знаний. В частности, иерархическая упорядоченность объектов предметной области здесь фиксировалась косвенным способом, посредством значений списка возможных обоснований R. В то же время фреймовая модель позволяет делать это явно с помощью слотов is_a или ako. Кроме этого, в примере не использовались присоединенные процедуры и значения по умолчанию.
ГЛАВА 8
РАСПОЗНАВАНИЕ ОБРАЗОВ И ОБУЧЕНИЕ
Распознавание образов – одна из основных функций интеллектуальных систем. Любой интеллект, в том числе и искусственный, начинается с восприятия и распознавания объектов внешнего мира. Поэтому подсистемы распознавания образов называют “ушами и глазами” СИИ [55]. Существует большое множество задач ИИ, решение которых связано с автоматизацией процессов восприятия и распознавания образов. Например, автоматическое чтение рукописных текстов, распознавание речи, анализ изображений и сцен, дистанционная идентификация объектов, медицинская диагностика и др.
В главе изложены общие принципы распознавания образов, не учитывающие специфику конкретных задач, обусловленную физической природой восприятия. Особенности восприятия и распознавания речевых и зрительных образов рассматриваются в следующих главах.
Распознавание образов неразрывно связано с обучением, которое осуществляется на основе анализа и обобщения имеющихся данных. Поэтому значительная часть главы посвящена рассмотрению обучаемых классификаторов образов. Большое внимание при этом уделяется коннекционистским моделям обучения, к которым относят нейронные сети. Нейронные сети находят широкое применение при решении многих задач искусственного интеллекта. В главе подробно рассматриваются модели нейронных элементов, структуры нейронных сетей и основные алгоритмы их обучения.
Если распознаваемые объекты представляются с помощью системы примитивов и отношений между ними, то их распознавание может выполняться на основе синтаксического (структурного) подхода, использующего теорию формальных грамматик. В этом случае обучение рассматривается как процесс построения грамматики. Структурный метод распознавания рассматривается в заключительном параграфе главы.

Распознавание образов и обучение |
415 |
|
|
ров, невозможно выполнить классификацию объектов. Поэтому из сигналов рецепторов выделяют необходимые признаки, которые формируют описание объекта в пространстве признаков. С помощью полученного описания выполняется распознавание объекта, т.е. отнесение его к тому или иному классу. Возможность разделения образов в пространстве признаков основана на гипотезе компактности, которая формулируется так: если некоторые множества объектов представляют собой образы, то обязательно существует такое пространство признаков, в котором этим объектам соответствуют компактные множества точек [10]. Следовательно, решение задачи распознавания образов в значительной степени зависит от выбора множества признаков, обеспечивающих компактное представление объектов одного класса в пространстве признаков. Если указанные признаки выделены, то задачу распознавания образов можно рассматривать как задачу построения разделяющей поверхности, отделяющей одно компактное множество точек от другого.
В тех случаях, когда имеющиеся априорные данные о распознаваемых объектах недостаточно полны, чтобы по ним найти определенную разделяющую поверхность, применяют обучаемые системы распознавания образов. Обучение осуществляется путем показа примеров с указанием принадлежности объектов тому или иному классу (обучение с учителем) или без указания (обучение без учителя). В ходе обучения система определяет множество признаков, на основе которых можно классифицировать объекты. Важно отметить, что после обучения система должна приобрести способность к опознаванию объектов не только из обучающей последовательности, но и тех, которые ей не предъявлялись.
8.2. Геометрический метод распознавания
Геометрический метод распознавания основан на использовании функции расстояния в качестве меры сходства векторов признаков, представляющих образы.
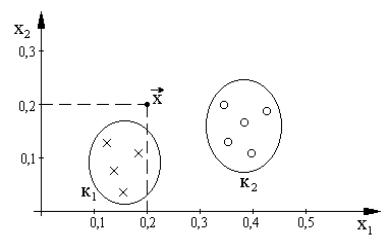
На рисунке 8.2 изображены векторы признаков, объединенные в два класса k1 и k2. Для наглядности использованы только два признака x1 и x2. Так как вектор x, представляющий некоторый объект, находится ближе к векторам класса k1, то объект принадлежит классу k1.
Интуитивно ясно, что результаты классификации с помощью функции расстояния будут удовлетворительными, если выполняются два условия. Во-первых, соблюдаются условия компактности, выражающееся в том, что точки, представляющие объекты одного класса, расположены друг к другу ближе, чем к точкам, представляющим объекты другого клас-
Распознавание образов и обучение |
417 |
|
|
Если каждый класс характеризуется не единственным, а несколькими эталонами zi1,zi2,...,ziN , где N – количество эталонов, определяющих класс, то
D i min |
|
|
|
x |
zil |
|
|
|
, l = 1, 2, …, N. |
|
|
|
|
|
|||||||
l |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
В этом случае для каждого входного вектора x |
вычисляется рас- |
|||||||||
стояние Di. Вектор x относится к классу ki, если Di < Dj |
для всех j i . |
|||||||||
Отметим, что в качестве меры сходства, кроме расстояния Евклида, могут использоваться и другие метрические расстояния, обладающие следующими свойствами:
а) D(x,y) 0;
б) D(x,y) D(y,x) (симметрия);
в) D(x,y) D(x,z) D(z,y)(неравенство треугольника), где D(x, y)
– расстояние между векторами x и y .
Если известны статистические характеристики входных векторов, то в качестве меры сходства может быть использовано расстояние Махалано-
биса |
|
|
|
|
|
|
|
(8.4) |
|||||
D(x,m) (x |
m)T C 1 |
(x |
m), |
|||
где С – ковариационная матрица совокупности векторов признаков; m – вектор средних значений.
Нередки случаи, когда распознаваемые объекты представляются бинарными кодовыми последовательностями или строками символов. В этом случае в качестве меры сходства используют расстояние Хемминга и расстояние Левенштейна.
Рассмотрим два вектора x и y , элементами которых являются бинарные значения 0 и 1 или символы некоторого алфавита. Расстояние Хемминга DH между такими векторами равно количеству несовпадающих элементов векторов. Например, пусть x = (1, 0, 1, 1, 0) и y = (0, 1, 1, 1, 0). Тогда DH (x,y) 2. Или, пусть x=(о, б, р, а, з, е, ц) и y =(о, б, р, а, т, н, о). В этом случае DH (x,y) 3. Заметим, что расстояние Хемминга может быть определено только между векторами (строками) x и y , равной длины.
Расстояние Левенштейна между строками Х и У определяется как наименьшее число преобразований, требуемых для получения строки У из строки Х. Условно это можно записать в виде выражения [73]
Распознавание образов и обучение |
419 |
|
|
мые символы строк одинаковы, то замена не выполняется, и стоимость операции равна 0.
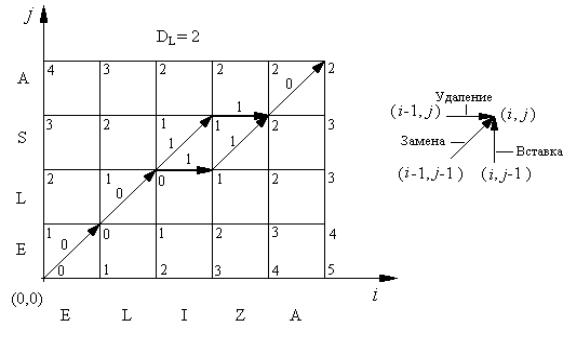
Рисунок 8.3 – Преобразование строки “ELIZA” в строку “ELSA”
Алгоритм динамического программирования позволяет построить оптимальную траекторию преобразования строк, выбирая на каждом шаге элементарное преобразование, обеспечивающее минимум текущего значения расстояния Левенштейна (на рисунке 8.3 указанные расстояния обозначены числами, находящимися в узлах координатной сетки).
Возвращаясь к геометрическому методу распознавания, отметим, что его применение требует задания эталонов классов, которые могут быть определены в результате решения задачи кластеризации. Кластером называют группу объектов, образующих в пространстве признаков компактную область. Выявление кластеров на множестве исходных данных также основано на использовании мер сходства. Рассмотрим алгоритм поиска кластеров для случая, когда в качестве меры сходства используется расстояние Евклида.
Решение задачи выделения кластеров требует введения критерия качества кластеризации. Наиболее часто используют сумму квадратов отклонений входных векторов x от центров кластеров mj [43]
|
N c |
|
|
x |
|
m |
|
|
2 |
|
J |
|
|
|
|
|
|
(8.5) |
|||
|
|
j |
|
, |
||||||
|
j 1 x s |
j |
|
|
|
|
|
|
||