

Точно Не проект 2 / Не books / Источник_1
.pdf
Распознавание образов и обучение |
441 |
|
|
В дальнейшем будет показано, что большинство правил обучения ИНС имеют структуру, подобную правилу (8.45).
Важно отметить, что правило обучения персептрона обеспечивает схождение вектора весов w к требуемым значениям, определяемым условием (8.43), за конечное число шагов при условии существования решения (теорема сходимости) [68]. При этом число шагов в значительной степени зависит от коэффициента , а также от структуры обучающей последовательности.
8.5.4.2. Адаптивный линейный элемент (Adaptive Linear Element).
Адаптивный линейный элемент представляет собой НЭ с линейной функцией преобразования g(u) = u (рисунок 8.14).
Рисунок 8.14 – Адаптивный линейный элемент
В ходе обучения с учителем вектор весовых коэффициентов корректируется так, чтобы выходной сигнал u( ) имел наилучшее приближение к желаемой реакции t( ). В большинстве практических случаев минимизируется среднеквадратическое значение ошибки
|
1 |
P |
2 |
|
1 |
P |
T |
2 |
|
1 |
P |
m |
2 |
||||
E(w) |
|
|
[t( ) u( )] |
|
|
|
[t( ) w x( )] |
|
|
|
[t( ) wjxj( )] . (8.46) |
||||||
2 |
2 |
2 |
|||||||||||||||
|
1 |
|
|
1 |
|
|
|
1 |
j 1 |
|
|||||||
С целью минимизации ошибки (8.46) применяют метод градиента. В этом случае веса wj изменяются в направлении, обратном направлению градиента
|
E |
|
|
|
E |
|
|
|
E |
||||
E(w) ( |
|
|
|
, |
|
|
|
|
,..., |
|
|
|
), |
w |
|
|
w |
|
|
w |
|
||||||
|
|
|
|
2 |
|
m |
|||||||
т.е. |
1 |
|
|
|
|
|
|
|
|||||
|
|
|
|
|
|
|
E |
|
|
|
|||
w j |
|
|
|
|
|
. |
|
|
|||||
|
|
|
|
|
|
||||||||
|
|
|
|
|
|
w j |
|
|
|
|
|||
Найдем частную производную E |
w j |
|
, используя схему |
||||||||||
Распознавание образов и обучение |
443 |
|
|
|
1 |
P n |
|
2 |
1 |
P n |
2 |
||
E(w) |
|
|
[ti ( ) yi (u)] |
|
|
|
[ti ( ) g(neti ( ))] |
, (8.49) |
|
2 |
|
|
|||||||
|
1 i 1 |
|
|
2 |
1 i 1 |
|
|||
|
|
|
m |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
где neti ( ) wiT x( ) wij xj ( ) – значение сетевой функции i–го ней-
|
|
|
|
j 1 |
|
рона при подаче на его вход вектора x( ). |
|
||||
Применив к (8.49) метод градиента, получим |
|
||||
|
E |
|
|
p |
|
|
[ti ( ) g (net i ( ))] g (net i ( )]x j ( ) , |
|
|||
|
wij |
|
|||
|
|
1 |
|
||
где g (neti( )) |
– производная функция преобразования НЭ. Отсюда для |
||||
последовательного обучения |
|
||||
|
wij |
[ti ( ) g(neti ( ))]g (neti ( ))xj ( ) . |
(8.50) |
||
Выражение (8.50) называют дельта-правилом обучения и часто запи- |
|||||
сывают в форме |
|
wij i ( )x j ( ) , |
|
||
|
|
|
|
(8.51) |
|
где |
( ) [ti ( ) g (net i ( ))] g (net i ( )) . |
|
|||
|
i |
|
|||
Таким образом, в дельта-правиле ошибка i( ) пропорциональна производной функции преобразования НЭ.
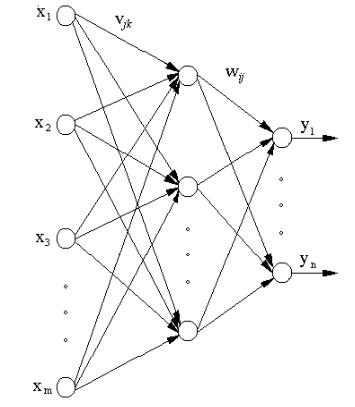
8.5.4.3. Многослойный персептрон. Многослойный персептрон состоит из нескольких слоев нейронов с прямым распространением сигналов (рисунок 8.9,б). Обучение многослойного персептрона выполняется на основе алгоритма обратного распространения ошибки [68,76].
Данный алгоритм получается в результате обобщения дельтаправила на многослойные ИНС с прямыми связями.
Рассмотрим двухслойную нейронную сеть с прямыми связями (рисунок 8.14). Определим реакцию i–го нейрона выходного слоя на входной вектор x( ). Для этого составим сначала выражения, определяющие реакцию нейронов скрытого слоя.
Сетевая функция j–го нейрона скрытого слоя для –го входного вектора равна

Распознавание образов и обучение |
|
447 |
|
|
|
|
|
|
i(k 1) g (neti(k 1) ) wij(k ) (jk ) |
; |
|
|
j |
|
|
6) |
обновить веса связей каждого слоя в соответствии с правилом |
||
|
wij(k ) i(k ) x(jk 1) |
; |
(8.61) |
7) |
если p , то : 1 и перейти к пункту 2, иначе перейти к |
||
|
пункту 8; |
|
|
8) |
проверить значение ошибки Е: если Е < Emax, то закончить вычисле- |
||
|
ния, иначе присвоить Е:=0, : 1 и перейти к пункту 2. |
||
Рассмотренный алгоритм является последовательным, так как предполагает обновление весов при поступлении очередного входного вектора. Возможен альтернативный вариант алгоритма, когда веса связей обновляются в точном соответствии с (8.56) и (8.58) после поступления всех векторов обучающей выборки. Такой режим обновления весов связей назы-
вают блочным.
Рассмотрим некоторые практические рекомендации по выбору ряда параметров алгоритма обратного распространения ошибки, влияющих на скорость обучения, сходимость решения, обобщающие возможности многослойного персептрона.
Начальные веса связей. Начальные веса связей представляют собой небольшие случайные числа, обеспечивающие для заданного входного вектора x( ) такое значение neti( ), при котором используется линейный участок сигмовидной функции преобразования. Обычно это достигается, если значения wij лежат в диапазоне [ 3/
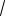 m, 3/
m, 3/
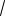 m], где m – число входов соответствующего нейронного элемента [76]. Неправильный выбор начальных весов связей может приводить к решениям, соответствующим локальным минимумам ошибки персептрона, или к “попаданию” в область “плато”.
m], где m – число входов соответствующего нейронного элемента [76]. Неправильный выбор начальных весов связей может приводить к решениям, соответствующим локальным минимумам ошибки персептрона, или к “попаданию” в область “плато”.
Коэффициент обучения. Коэффициент обучения оказывает значительное влияние на скорость обучения многослойного персептрона и сходимость решения. Выбор обычно осуществляют экспериментально. Относительно большие значения обеспечивают быстрое обучение, но при этом существует опасность получить неверное решение. Малые значения затягивают процесс обучения. Диапазон возможных значений от 10-3 до 10 [76]. Кроме этого, конкретные значения , выбранные в начале процесса обучения, могут оказаться не совсем подходящими в конце обучения. Поэтому в ряде случаев изменяют в ходе обучения. Один из способов управления значением заключается в контроле ошибки Е. Если
Распознавание образов и обучение |
449 |
|
|
чтобы исключить осцилляции, в правило обновления весов связей (8.56) вводят момент инерции.
w(k)
Предположим, что изменение веса ij на текущем шаге соответство-
вало wij(k)(t). Для следующего момента времени |
изменение |
веса |
wij(k)(t 1) должно быть пропорционально градиенту |
- E/dwij(k)(t). |
До- |
бавление момента инерции позволяет на каждом шаге частично сохранять предыдущее направление изменения весов связей
wij(k) (t 1) dwij(kE) (t) wij(k) (t) ,
где 0 1.
Переобучение. Множество примеров Х (8.41), содержащее пары (x( ),t ( )), разбивается на два подмножества Х1 и Х2. Для обучения используются только элементы подмножества Х1, которое позволяет сформировать обучающую последовательность, состоящую из пар (x( ),t ( )), где 1 P. Совокупность элементов из Х2 образует проверочную последовательность.
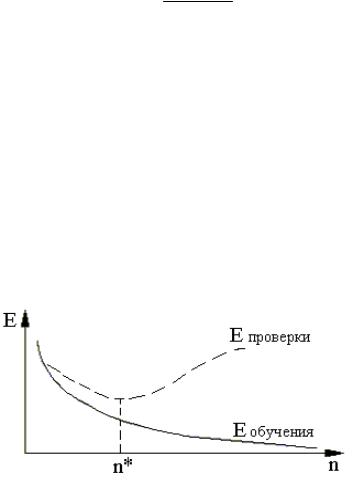
На рисунке 8.15 показан качественный характер зависимости ошибки нейронной сети на этапе обучения Еобучения и на этапе проверки Епроверки от количества циклов обучения n. Один цикл обучения соответствует выбору всех элементов из Х1.
Рисунок 8.15. – Зависимость ошибки нейронной сети от количества циклов обучения.
Вначале обе ошибки уменьшаются. Это означает, что сеть корректно обучается на структуры данных, свойственные пространству входных сигналов. Однако если сеть является излишне гибкой (т.е. обладает большим количеством степеней свободы, чем требуется), то ошибка Епроверки после некоторого числа циклов обучения начинает возрастать. Это означает, что при обучении сеть скорее учитывает особенности свойственные конкрет-