

Точно Не проект 2 / Не books / Источник_1
.pdf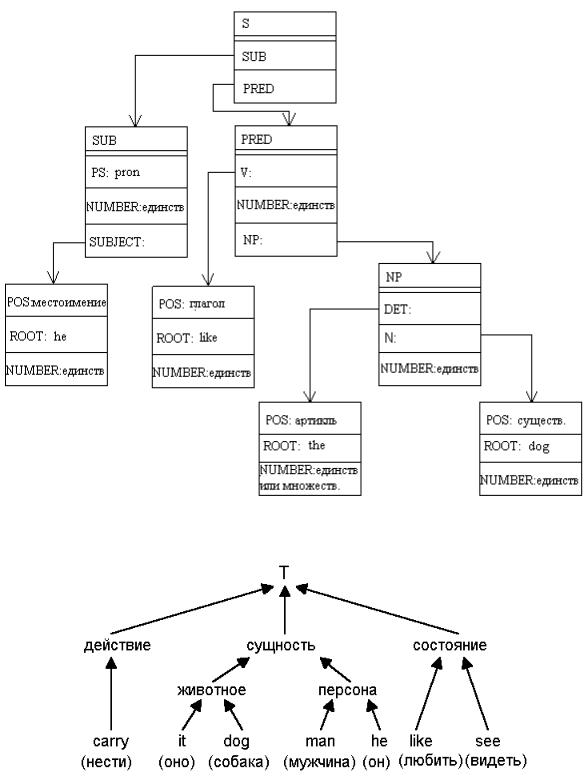
Обработка естественного языка |
501 |
|
|
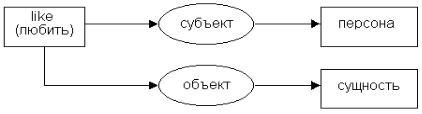
9.13. Дополнительно к понятиям будем использовать лингвистические отношения: агент, субъект, объект, инструмент (см. § 3.4). Понятия, выражаемые глаголами, представляются в базе знаний с помощью падежных рамок (рисунок 9.14).
Рисунок 9.12 – Дерево грамматического разбора предложения
Рисунок 9.13 – Иерархия типов понятий примера
Обработка естественного языка |
503 |
|
|
Procedure P_NOUN (NP); Begin
Вызвать процедуру NOUN (NP.N) для интерпретации существи-
тельного NP.N
If (NP.NUMBER = единственное) and (NP.DET.ROOT = a) Then
Представить понятие, выраженное существительным, в общей форме;
If (NP.NUMBER = единственное) and (NP.DET.ROOT = the) Then
Связать с понятием, представленным существительным, индивидный числовой маркер;
If(NP.NUMBER = множественное) Then
Связать с понятием, представленным существительным, метку множественного числа;
End;
Procedure NOUN (X);
Begin
Извлечь из базы знаний существительное X
End.
Procedure PRONOUN (X);
Begin
Извлечь из базы знаний местоимение X
End.
Артикли английского предложения не представляются в виде отдельных понятий на концептуальных схемах. В рассматриваемом примере они лишь определяют, является ли объект предметной области обобщенным или индивидным. Если объект обобщенный, то на концептуальной схеме он представляется общим понятием с учетом иерархии понятий, изображенной на рисунке 9.13. Если объект индивидный, то он снабжается специальным числовым или именным маркером, отделяющим данное понятие от аналогичных понятий, имеющихся в базе знаний. Указанные особенности интерпретации отражены в тексте процедуры P_NOUN.
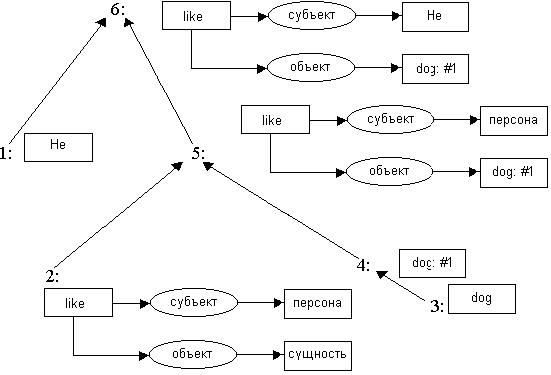
На рисунке 9.15 изображен процесс интерпретации предложения “He likes the dog”, использующий дерево грамматического разбора (рисунок
9.12).
Анализаторы, построенные на основе рассмотренных принципов, оказываются чрезвычайно чувствительными к грамматике входного языка. Если некоторое предложение содержит отклонения от грамматики, что характерно для диалога между людьми, то ATN – анализатор терпит неудачу. Один из подходов преодоления указанного недостатка ATN-анализаторов заключается в параллельном применении нескольких грамматик и объединении результатов интерпретации.
Обработка естественного языка |
505 |
|
|
альных речевых данных. Позже статистические методы обработки речи были распространены на другие области обработки естественного языка.
Одно из первых успешных применений обучающих алгоритмов в лингвистике связано с задачей распознавания частей речи (существительных, глаголов, артиклей, и пр.) в предложении. Современные технологии позволяют решать эту задачу с точностью близкой к точности, которая получается при анализе предложений людьми [61]. Распознавание частей речи – важная составляющая систем понимания высказываний. С появлением больших баз данных, содержащих предложения с соответствующими деревьями грамматического разбора, эмпирические методы распространились на задачу синтаксического анализа предложений. В настоящее время эмпирический подход применяется для установления смысла неоднозначных слов, сегментации дискурса, выделения анафор (повторение в разных частях предложения или текста одного и того же понятия, которое может представляться разными словами), семантического анализа.
Широкое использование в настоящее время эмпирического подхода объясняется различными причинами. Основная причина состоит в том, что эмпирический подход предлагает потенциальные решения давних проблем, связанных с обработкой естественного языка, как-то:
-автоматическое пополнение знаний;
-широту охвата понятий рассматриваемой предметной области;
-устойчивость соответствующих моделей по отношению к шуму и неполноте данных;
-простота расширения систем по отношению к новым данным
или новым предметным областям.
К иным причинам роста популярности эмпирического подхода в последнее время следует отнести:
-относительную доступность высокопроизводительных вычислительных средств для многих исследователей;
-разработку и создание больших баз лингвистических данных, необходимых для обучения и тестирования ЕЯ-систем;
-ориентацию на создание систем, работающих в реальных условиях.
Рассмотрим особенности эмпирического подхода на примере распознавания частей речи. Задача состоит в присвоении словам предложения меток: существительное, глагол, предлог, прилагательное и т.п. Кроме этого, необходимо определять некоторые дополнительные признаки существительных и глаголов, например, для существительного – число, а для глагола – форму.
Формализуем задачу. Представим предложение в виде последовательности слов W w1w2 wn , где w1,w2 , ,wn случайные переменные, каждая из которых получает одно из возможных значений, принадлежа-
Обработка естественного языка |
507 |
|
|
зывают марковскими. Для решения задачи (9.3) привлекают теорию марковских моделей (см.§ 9.3.5).
С учетом марковских предположений (9.3) запишется в виде
|
n |
|
X* argmax P(xi | xi 1)P(wi | xi ), |
(9.5) |
|
x1, ,xn |
i 1 |
|
где условные вероятности P(xi | xi 1)и P(wi | xi ) оцениваются на множестве
обучающих данных. Поиск последовательности меток X* осуществляют с помощью алгоритма динамического программирования Витерби.
Алгоритм Витерби может рассматриваться как вариант алгоритма поиска на графе состояний, где вершинам соответствуют метки слов. Характерно, что для любой текущей вершины множество дочерних вершин всегда одно и то же. Более того, для каждой дочерней вершины множества родительских вершин тоже совпадают. Это объясняется тем, что на графе состояний осуществляются переходы с учетом всех возможных сочетаний меток:
предлог предлог;
предлог глагол; … .
предлог существительное; … .
существительное предлог; … .
существительное существительное.
Если имеется n меток и P(xi | xi 1) 0 для всех значений i, то в каждую вершину-метку будут вести n путей. Наилучшим считается путь с наибольшим значением вероятности P(X1t |W1t ), где X1t x1,x2, ,xt и
W1t w1,w2, ,wt ,t n. Таким образом, на каждом шаге поиска продолжа-
ются n путей. На последнем шаге из n последовательностей (путей) выбирается одна с учетом (9.5). Подробнее алгоритм Витерби будет описан на примере задачи распознавания речи.
Предположения Маркова обеспечивают существенное упрощение задачи распознавания частей речи при сохранении высокой точности назначения меток словам. Так, при наличии 200 меток точность назначения меток примерно равна 97% [77]. Успешное определение частей речи предложения – ключ к решению задачи синтаксического анализа ЕЯпредложений.
Многие достижения в области синтаксического анализа предложений на основе эмпирического подхода стали возможны благодаря созда-
Обработка естественного языка |
509 |
|
|
-пользователю не требуется изучать сложные искусственные языки доступа к БД;
-простота формулировки сложных запросов, содержащих отрицания и кванторы общности, которые весьма трудно сформировать при использовании традиционных “оконных” интерфейсов доступа к БД;
-возможность обработки запросов с учетом дискурса, что допускает ввод запросов, содержащих анафоры и эллипсисы.
Существующие ЕЯ-интерфейсы баз данных используют различные
подходы [59]: метод сопоставления с образцом, синтаксические грамматики, семантические грамматики, некоторый внутренний язык.
Интерфейсы, основанные на методе сопоставления с образцом, являются наиболее простыми. Обобщенный алгоритм сопоставления с образцом и пример его применения к ведению диалога на ограниченном ЕЯ рассмотрен в § 5.25. Уточним особенности анализа ЕЯ-запросов на основе процедуры сопоставления с образцом. Рассмотрим таблицу реляционной БД, содержащую сведения о странах (рисунок 9.16).
Страны
Страна |
Столица |
Язык |
Франция |
Париж |
Французский |
Германия |
Берлин |
Немецкий |
Италия |
Рим |
Итальянский |
… |
… |
… |
Рисунок 9.16 – Таблица реляционной БД
В этом случае при ответе на запрос могут использоваться следующие правила:
образец: … “столиц&” … ?S;
действие: вывести значение поля Столица для строки таблицы, удовлетворяющей условию Страна = S;
образец: … “столиц&” … “стран&”;
действие: вывести значения полей Страна и Столица для каждой строки таблицы.
В соответствии с первым правилом, если в запросе пользователя после слова “столиц&” будет следовать название страны (т. е. одно из возможных значений поля Страна), то необходимо найти строку таблицы, для которой значение поля Страна сопоставимо со значением переменной образца S, и сообщить пользователю соответствующее значение поля Столица. Например, если пользователь введет запрос “Столица Германии ?”, то