

Точно Не проект 2 / Не books / Источник_1
.pdf530 |
Глава 9 |
|
|
P([молочнаjа]|“молочная”)=0,28;
P([молошнаjа]|“молочная”)=0,12;
P([малочнаjа]|“молочная”)=0,42;
P([малошнаjа]|“молочная”)=0,18.
Подобные модели могут быть построены для каждого слова, которое распознается системой APP.
Если бы речевой сигнал был эквивалентен последовательности фонем, задаваемых транскрипцией, то, используя цепи Маркова, можно было бы вычислить вероятность P(сигнал|слова) (т.е.P(X|W)) для различных последовательностей слов W. Комбинируя полученную вероятность с априорной вероятностью P(W), вычисляемой на основе МЯ, можно было бы найти последовательность слов W*, максимизирующую вероятность P(слова|сигнал), т.е. P(W|X). К сожалению, в ходе предварительной обработки речевых сигналов и векторного квантования не формируется последовательность фонем. Поэтому в рассматриваемом случае обеспечивается лишь нахождение максимального значения вероятности P(слова|фонемы). Отсюда следует, что для решения поставленной задачи необходимо дополнительно определять вероятность P(сигнал|фонемы). С этой целью приме-
няют скрытые марковские модели (СММ).
СММ описывается с помощью двух вероятностных процессов: скрытого процесса смены состояний цепи Маркова и наблюдаемого процесса формирования выходных символов при смене состояний. Пусть имеется N состояний. Вероятность того, что в момент времени t текущим будет состояние Si , зависит от предыстории смены состояний. В моделях Маркова первого порядка полагается, что данная вероятность зависит только от состояния, в котором находился скрытый процесс в предыдущий момент времени t-1. Именно такие модели используются чаще всего. Наблюдаемый процесс формирования выходных символов описывается с помощью распределения вероятностей bi (x), которое показывает вероятность фор-
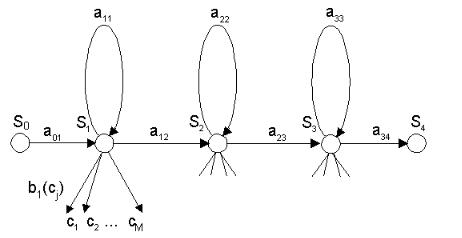
мирования выходного символа x при переходе в состояниеSi . На рисунке
9.25 изображен пример СММ. Здесь в состояниях S1,S2,S3 формируется один из выходных символов c1,c2,...,cM в соответствии с распределением вероятностей bi (x), где x cj . Состояния S0 и S4 называются входным и
конечным состояниями. В этих состояниях не формируются выходные символы.
Формально СММ, имеющая N состояний, характеризуется: - текущим состоянием qt в момент времени t;
Обработка естественного языка |
|
|
531 |
|
|
|
|
|
|
- |
матрицей переходных вероятностей A [aij ], где |
1 i, j N |
и |
|
|
aij P(qt 1 Sj | qt Si ) вероятность перехода из состояния Si в |
|||
|
состояние Sj ; |
|
|
|
- |
матрицей распределения выходных вероятностей |
B [bij ], |
где |
|
|
bij bi (cj ) P(xt cj | qt Si ) |
вероятность того, |
что в момент |
|
|
времени t выходной символ |
xt примет значение |
cj , если теку- |
|
M
щим является состояние Si , bi (cj ) 1;
j 1
- вектором распределения начальных состояний [ i] , где
i P(q1 Si) вероятность того, что в начальный момент време-
ни t=1 текущим будет состояние Si .
Рисунок 9.25 – Пример СММ
Вероятности начальных состояний могут быть включены в матрицу А. В этом случае они представляют собой вероятность смены входного состояния на одно из состояний, которое обеспечивает формирование выходного символа, т.е. i a0i . Тогда СММ представляет собой структуру
(A,B),
характеризуемую параметрами A и B. Эти параметры определяют вероятность формирования последовательности символов Х с помощью модели
, т.е. P(X| ).
Применение СММ при распознавании речи сопряжено с решением трех основных подзадач:
- вычислительной подзадачи;
532 |
Глава 9 |
|
|
-подзадачи восстановления (декодирования);
-подзадачи оценивания.
Вычислительная подзадача состоит в следующем. Пусть заданы модель (A,B) и последовательность выходных символов X x1,x2 ,..., xT . Требуется построить алгоритм, вычисляющий вероятности формирования последовательности Х моделью , т.е. P(X| ).
Подзадача восстановления (декодирования) состоит в поиске оптимальной последовательности состояний Q q1,q2,...,qT по известной по-
следовательности X x1,x2,...,xT для заданной модели . Иными словами, требуется выяснить, какая из возможных последовательностей состояний Q в наибольшей степени соответствует, наблюдаемой последовательности символов Х.
Целью подзадачи оценивания является определение параметров модели (A,B), обеспечивающих максимум вероятности P(X| ).
Рассмотрим вычислительную подзадачу. Чтобы вычислить вероятности P(X| ), необходимо рассмотреть возможные последовательности состояний Q q1,q2,...,qT , заданной длины Т, обеспечивающие формирова-
ние последовательности X x1,x2 ,...,xT . Если СММ имеет N состояний, то
общее число таких последовательностей будет равно NT . Так как все последовательности являются взаимно исключающими, то вероятность P(X| ) будет равна сумме совместных вероятностей P(X,Q| ):
P(X| ) P(X,Q| ). |
(9.12) |
Q |
|
Последовательность состояний Q можно рассматривать как путь, |
|
при прохождении которого формируется последовательность |
Х. Тогда |
P(X,Q| ) будет представлять собой вероятность формирования последовательности Х на пути Q моделью . Эта вероятность вычисляется как про-
изведение |
вероятностей переходов aij |
и выходных вероятностей |
bi (xj ) bij |
вдоль пути Q, т.е. |
|
P(X,Q | ) a0,q1bq1 (x1 )aq1,q2bq2 |
(x2 )...aqT 1,qT bqT (xT )aqT ,N , |
|
где a0,q1 |
и aqT ,N – соответственно вероятности смены входного состоя- |
|
ния на состояние q1 , формирующее выходной символ x1, и состояния qT на конечное состояние.
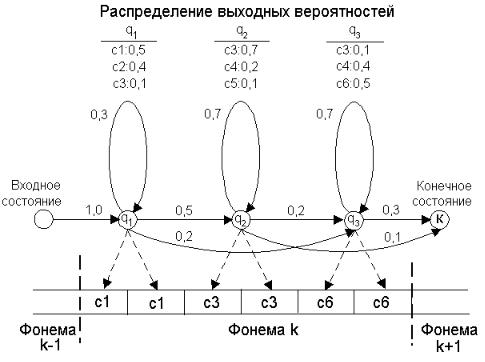
Рассмотрим вычисление вероятности P(X| ) на примере. На рисунке 9.26 изображена типовая СММ фонемы с тремя состояниями: начальным
Обработка естественного языка |
533 |
|
|
(q1), средним (q2 ) и конечным (q3 ). |
Кроме переходных вероятностей на |
рисунке показаны распределения вероятностей выходных символов, ассоциированных с состояниями q1,q2 и q3 . Здесь выходные символы соответствуют номерам эталонных векторов, формируемым в процессе векторного квантования. Предположим, что в результате векторного квантования формируется последовательность X x1x2 x3 x4 x5 x6 , состоящая из номеров эталонных векторов [c1c1c3c3c6c6 ].
Рисунок 9.26– СММ фонемы
В модели фонемы имеются пять путей смены состояний, обеспечивающие формирование последовательности [c1,c1,c3,c3,c6 ,c6 ]. Cуммарная вероятность формирования последовательности моделью фонемы в соответствии с (9.12) равна:
P(X | фонема) P([c1,c1,c3,c3 ,c6 ,c6 ]|фонема)
(0,3 0,5 0,7 0,2 0,7 0,3)(0,5 0,5 0,7 0,7 0,5 0,5)
(0,3 0,3 0,5 0,2 0,7 0,3)(0,5 0,5 0,1 0,7 0,5 0,5)
(0,3 0,5 0,2 0,7 0,7 0,3)(0,5 0,5 0,7 0,1 0,5 0,5)
(0,3 0,3 0,3 0,2 0,7 0,3)(0,5 0,5 0,1 0,1 0,5 0,5)
(0,3 0,2 0,7 0,7 0,7 0,3)(0,5 0,5 0,1 0,1 0,5 0,5)
1,6499 10 4 .
Обработка естественного языка |
535 |
|
|
|
|
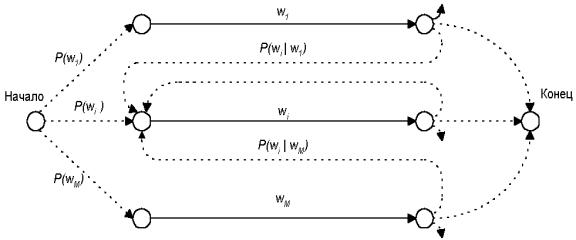
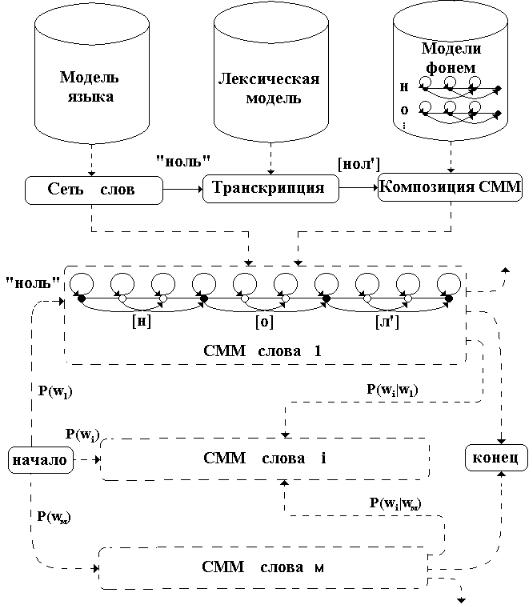
Если каждое слово-состояние биграмной МЯ заменить соответствующей моделью произношения, то можно получить СММ, в которой состояния уже будут соответствовать фонемам. И наконец, если каждую фонему представить в виде модели, соответствующей рисунку 9.26, то можно получить одну большую СММ, в которой каждому состоянию соответствует определенное распределение значений векторов эталонов речевого сигнала. Процесс построения составной модели условно изображен на рисунке
9.28.
Рисунок 9.28 – Композиция моделей
Обработка естественного языка |
539 |
|
|
|
|
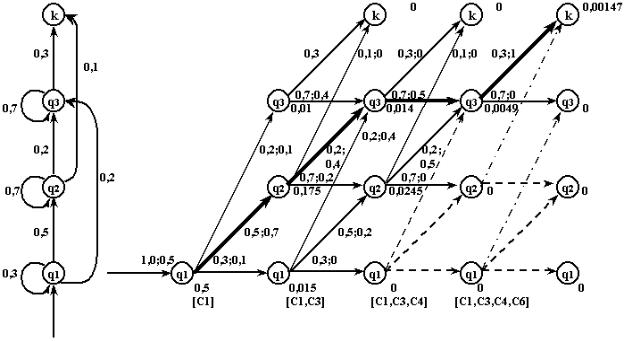
ходы из этого состояния обеспечивают максимум вероятности для путей, оканчивающихся состояниями q2 и q3 .
В соответствии с (9.17) предшествующие состояния запоминаются в массиве t ( j). В рассматриваемой ситуации 3(2) 2, 3(3) 2. Продолжая указанный процесс раскрытия состояний, достигаем конечного состояния с вероятностью 0,00147. Анализируя значение Т ( j), получаем после-
довательность состояний Q q1q2q3q3 , которая с наибольшей вероятно-
стью формирует заданную последовательность [c1c3c4c6 ] . На рисунке 9.29 оптимальный путь изображен жирной линией.
Рисунок 9.29 – Пример реализации алгоритма Витерби
Так как рассматриваемые в системах АРР модели допускают переходы состояний только в направлении слева направо, то общее число вариантов, анализируемых в алгоритме Витерби равно NT, что намного меньше по сравнению с NT , когда учитываются все пути, обеспечивающие формирование заданной последовательности Х (см. выражение 9.12).
Сложность составной модели возрастает по мере увеличения размера словаря. Для больших словарей размеры поисковых пространств оказываются огромными. Поэтому были разработаны различные модификации алгоритма Витерби, сокращающие поисковые пространства. Один из таких алгоритмов соответствует лучевому поиску (см. § 2.2.2). В этом случае на каждом шаге поиска из рассмотрения исключаются состояния, для которых вероятность P(X1t ,Q1t ) ниже оптимального значения минус некоторый порог.