

Формы представления числовых данных в эвм
В математике используются две формы записи чисел: естественная и нормальная.
При естественной форме число записывается в виде целого числа, правильной дроби или неправильной дроби.
При нормальной форме запись одного и того же числа может быть различной в зависимости от ограничений, на нее накладываемых.
Естественное представление чисел. В ЭВМ устанавливается длина разрядной сетки для записи всего числа, а также отдельно количество разрядов для записи целой и дробной частей числа. При этом положение запятой между целой и дробной частями числа фиксируется заранее. В связи с этим естественная форма представления чисел формой с фиксированной запятой.
Представление чисел с фиксированной запятой
Под запись числа в общем случае отводится nразрядов, причемk– целая часть. Вес каждого разряда виден на рисунке.
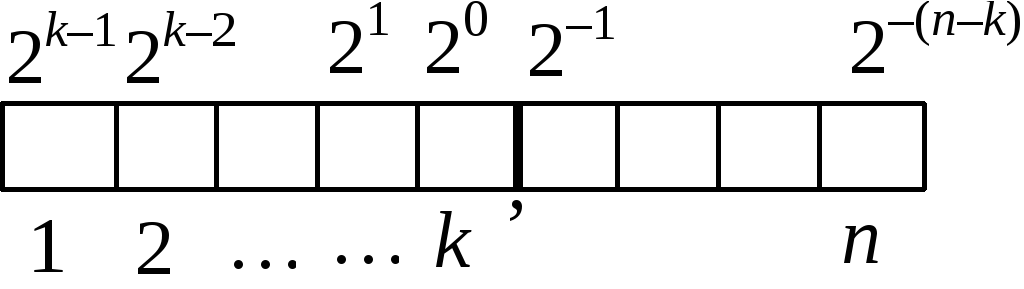
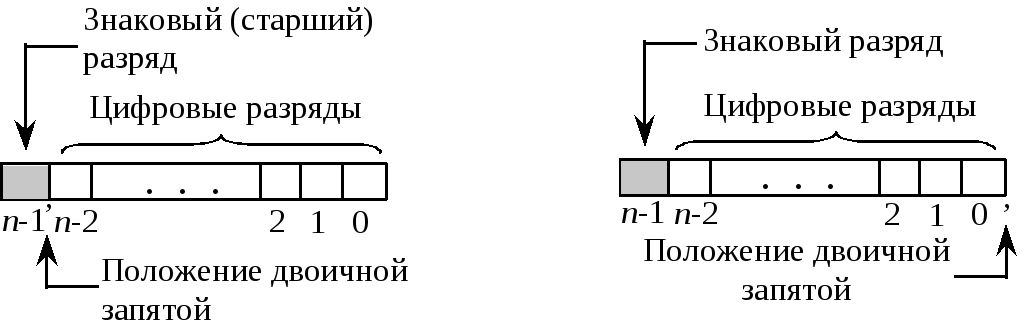
Число Хпри данной записи будет всегда неотрицательным. Для того чтобы можно было представить в такой форме и отрицательные числа, в разрядной сетке крайний левый разряд отводят под запись знака: 0 соответствует положительному числу, 1 – отрицательному числу.
Положение запятой в машинном коде определяет программист. Оно может быть любым в пределах цифровой части представления числа. На практике при представлении чисел с фиксированной запятой её закрепляют либо перед крайним левым разрядом (не считая знакового), либо после крайнего правого. В первом случае все числа по модулю меньше 1. Во втором случае все числа целые. Переход от смешанных чисел к представлению их в ЭВМ как дробных или как целых выполняется введением масштабных множителей.
В ЭВМ число двоичных разрядов и ячеек памяти фиксировано, что накладывает ограничения на систему представления чисел. Ограничения касаются диапазона чисел и точности их представления. Система машинных чисел оказывается конечной и дискретной.
В любой ЭВМ есть максимально представимое число Xmaxи минимально представимое числоXmin. Между ними находится конечное множество допустимых чисел. Область чисел от –Xmin до Xmin, за исключением истинного нуля, называют машинным нулем.
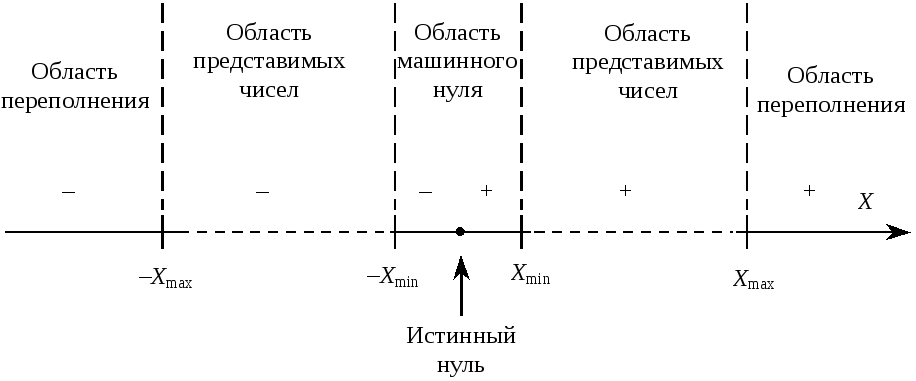
Если результат операции превышает по абсолютной величине Xmax, возникает переполнение, и дальнейшее выполнение программы не имеет смысла. Избежать переполнения можно правильным выбором масштабного множителя.
Форма представления чисел с фиксированной запятой имеет следующие недостатки:
- при организации выполнения вычислительных операций над числами все данные должны быть предварительно масштабированы с тем, чтобы конечное значение числа попало в принятый диапазон представления чисел (либо целые числа, либо меньшие единицы). Процесс масштабирования должен быть выполнен до начала вычислений и, как правило, вручную;
- все числа могут иметь разные масштабы, что может привести к неверным результатам, если это не учитывать;
- при выполнении действий над числами даже при одинаковых масштабах может произойти переполнение разрядной сетки, что приведет к автоматическому прерыванию процесса вычисления. Для избежания переполнения необходимо выбирать соответствующий масштаб числа;
- так как длина разрядной сетки ограничена и заранее установлена, то выбор соответствующего масштаба приводит к потере значащих цифр в конце числа, т. е. будет возрастать погрешность вычислений.
Несмотря на эти недостатки, представление чисел с фиксированной запятой нашло свое применение, особенно в первых вычислительных машинах. Это объясняется тем, что данное представление позволяет упростить схемы машины, обеспечить высокое быстродействие АЛУ. Но так как одним из основных требований к ЭВМ является обеспечение точности вычислений, эта форма представления чисел в настоящее время применяется в простых калькуляторах.
Прямые, обратные и дополнительные коды чисел с фиксированной запятой
ЭВМ выполняет арифметические операции над числами с фиксированной запятой в машинных кодах. Простейшим машинным кодом является прямой код.
Прямой код числа Ханалогичен двоичному коду, но число его разрядов строго определено и положение двоичной точки в самом коде никак не указано.
Прямые коды чисел просты, но плохо приспособлены для выполнения операций алгебраического сложения и вычитания чисел. Проще и быстрее выполняются операции алгебраического суммирования, вычитания и деления в дополнительных или обратных кодах.
Дополнительный код двоичного числа Х, представленного вn-разрядной сетке, определяется как
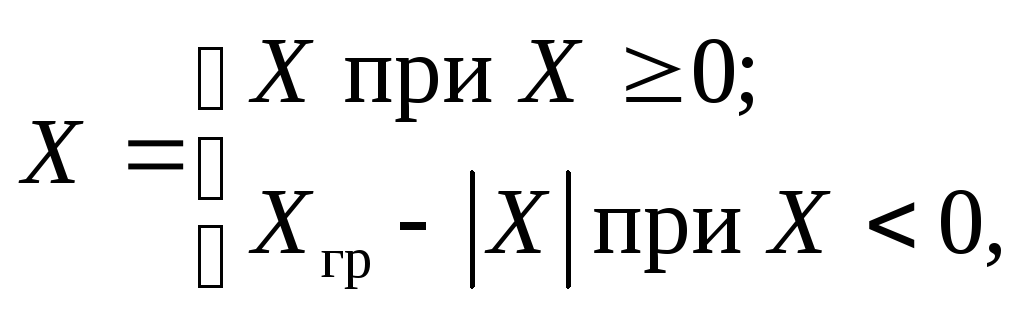
где Хгр– величина, равная весу разряда, следующего за старшим разрядом используемой разрядной сетки. Для правильных дробейХгр=2, для целых чисел Хгр=2n.
Таким образом, дополнительный код положительного числа совпадает с прямым кодом, а дополнительный код отрицательного числа получается как дополнение до граничного числа.
Обратный код двоичного числа Х, представленного вn-разрядной сетке, определяется как
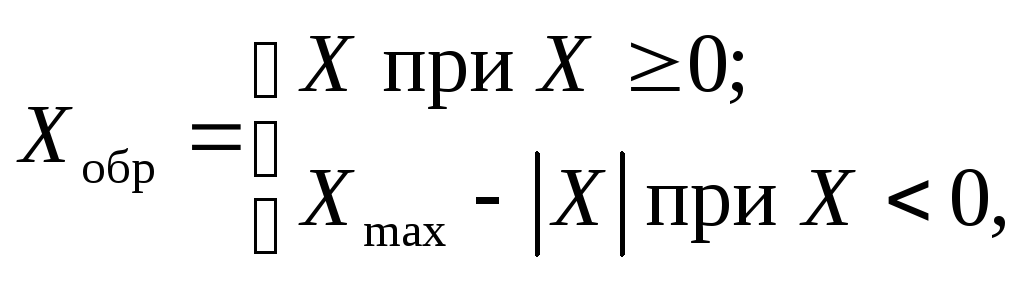
где Хmax– величина наибольшего числа без знака, размещающегося вn‑разрядной сетке. Для правильных дробейХmax=2–2–n+1, для целых чиселХmax=2n–1.
Граничное значение Хгр отличается от максимального значения Хmax на одну единицу младшего разряда (мл. р.):
Хгр = Хmax +1 мл. р.
Для положительных чисел прямой, обратный и дополнительный коды совпадают.
В случае отрицательных чисел дополнительный и обратный коды связаны между собой соотношением:
Хдоп = Хобр +1 мл. р.
Правило представления двоичного числа в обратном коде:
1) представить двоичное число в прямом коде в n-разрядном формате. Если число положительное, то его прямой и обратный коды совпадают и больше никаких преобразований делать не надо;
2) если число отрицательное, то в старшем (знаковом) разряде надо оставить 1, а в цифровых разрядах все цифры изменить на инверсные, то есть вместо 0 записать 1 и вместо 1 записать 0.
Правило представления двоичного числа в дополнительном коде:
1) представить двоичное число в прямом коде в n-разрядном формате. Если число положительное, то на этом представление числа и заканчивается, так как прямой, обратный и дополнительный коды в этом случае совпадают;
2) если число отрицательное, то перейти от его прямого кода к обратному;
3) прибавить к обратному коду отрицательного числа единицу младшего разряда.
Правило преобразования дополнительного кода в прямой код:
1) если в старшем (знаковом) разряде стоит 0, то число положительное и прямой код совпадает с дополнительным;
2) если в старшем разряде стоит 1, то число отрицательное, поэтому из дополнительного кода числа надо вычесть 1 младшего разряда с целью получения обратного кода числа, затем заменить все 0 на 1 и 1 на 0 в цифровых разрядах обратного кода, а в знаковом разряде оставить 1.
Прямой код из дополнительного кода отрицательного числа можно получить и по-другому: в знаковом разряде оставить 1, все цифровые разряды инвертировать и к полученному промежуточному результату прибавить единицу младшего разряда. Дополнительные и обратные коды чисел с фиксированной запятой (точкой) упрощают и ускоряют выполнение арифметических операций в ЭВМ.
Пример 1. Представить в 8-разрядном формате прямые, обратные и дополнительные коды целых двоичных чисел: Х1 = 1011;Х2= –1011;Х3= 11 0110;Х4= –11 0110. Найти десятичные эквиваленты заданных чисел.
Решение
Х1 = 1011(2)= 0000 1011(пр)(обр)(доп) = 11(10);
Х2= –1011(2)= 1000 1011(пр)= 1111 0100(обр)= 1111 0101(доп)= –11(10);
Х3= 11 0110(2)= 0011 0110(пр)(обр)(доп)= 54(10);
Х4= –11 0110(2)= 1011 0110(пр)= 11001001(обр)= 11001010(доп)= –54(10).
Пример 2. Представить в 8-разрядном формате прямые, обратные и дополнительные коды дробных двоичных чисел, найти их десятичные эквиваленты: Х1 = –0,11;Х2 = –0,1101;Х3 = 0,0101;Х4 = 0,10101.
Решение
Х1 = –0,11(2)= 11100000(пр)= 10011111(обр)= 10100000(доп)= – (0,5+0,25) = =–0,75;
Х2 = –0,1101(2)=11101000(пр)= 10010111(обр)= 10011000(доп)=
=–(0,5+0,25+0,0625) = –0,8125;
Х3 = 0,0101(2)= 00101000(пр)(обр)(доп)= 0,3125(10);
Х4 = 0,10101(2)=01010100(пр)(обр)(доп)= 0,65625(10).
Пример 3. Числа представлены как целые в дополнительных кодах: Х1 =10111101(доп); Х2 = 00101010(доп). Найти десятичные эквиваленты.
Решение
Необходимо найти прямые коды чисел, после чего перевести их в десятичные числа.
Число Х1отрицательное, следовательно, необходимо перевести его из дополнительного кода в обратный вычитанием одной единицы младшего разряда, затем в прямой код инверсией всех цифровых разрядов и далее в отрицательное двоичное число.
Х1 =10111101(доп)= 10111100(обр)= 11000011(пр)= –1000011(2)= –67(10).
Число Х2положительное, следовательно, его прямой код совпадает с дополнительным кодом:
Х2 = 00101010(доп)= 101010(пр)= 2+8+32 = 42(10).
Двоичные коды для десятичных цифр
ЭВМ оперирует с числами, представленными чаще всего в двоичной системе счисления, а программист всегда пользуется числами, представленными в общепринятой десятичной системе.
Прямой и обратный перевод чисел из десятичной системы счисления в двоичную сводится к последовательному делению или умножению, то есть к тем операциям, которые могут и должны выполняться машиной автоматически по специальным программам. Затруднения же с вводом и выводом десятичных чисел в ЭВМ преодолеваются простым и оригинальным приемом: предварительно в двоичную систему счисления переводят не все число, а только его цифры. На практике десятичные цифры переводят в двоичную систему и обратно тоже не вручную. В результате получается смешанная двоично-десятичная система, которая не является, строго говоря, позиционной. В ЭВМ обычно используют двоично-десятичную систему лишь как некоторую промежуточную при переводе чисел из десятичной системы счисления в двоичную и наоборот, но иногда ведут и обработку десятичной информации не в двоичных, а в двоично-десятичных кодах.
К о д – это совокупность знаков (символов) и система определенных правил, при помощи которых информация может быть представлена (закодирована) в виде набора из таких символов для передачи, обработки и запоминания.
Обычно десятичные цифры изображают с помощью четырех двоичных цифр, т. е. четырехразрядных слов. Иногда десятичные цифры изображают пяти-, шести- или семиразрядными двоичными числами.
Между каждой десятичной цифрой 0, 1, ..., 9 и двоичными кодами устанавливается однозначное соответствие.
Широкое распространение для двоичного кодирования десятичных цифр получил двоично-десятичный четырехразрядный код "8-4-2-1", в самом названии которого отражаются весовые множители, приписываемые соответствующим битам в кодирующей группе (таблица).
Кроме кода "8-4-2-1" для представления десятичных чисел в ЭВМ, с целью упрощения математических операций, находят применение код "8-4-2-1 с избытком 6" и некоторые другие.
Применение того или иного двоичного кода для представления десятичных цифр может обеспечить получение разнообразных, порою неожиданных, преимуществ. Например, в коде "8-4-2-1 с избытком 3" дополнения от десятичных цифр до 9 получаются обращением двоичных цифр, то есть заменой нулей единицами и единиц – нулями.
В коде "Два из пяти" содержится одинаковое количество единиц в изображении любого числа. Если важно обеспечить одинаковую нагрузку на источник питания, то можно применить этот или какой-либо аналогичный код.
|
Десятичные цифры
|
Двоично-десятичные коды
| ||||
|
"8-4-2-1" |
"8-4-2-1 с избытком 3" |
"8-4-2-1 с избытком 6" |
"5-4-2-1"
|
Два из пяти | |
|
0 |
0000 |
0011 |
0110 |
0000 |
11000 |
|
l |
0001 |
0100 |
0111 |
0001 |
00011 |
|
2 |
0010 |
0101 |
1000 |
0010 |
00101 |
|
3 |
0011 |
0110 |
1001 |
0011 |
00110 |
|
4 |
0100 |
0111 |
1010 |
0100 |
01001 |
|
5 |
0101 |
1000 |
1011 |
1000 |
01010 |
|
6 |
0110 |
1001 |
1100 |
1001 |
01100 |
|
7 |
0111 |
1010 |
1101 |
1010 |
10001 |
|
8 |
1000 |
1011 |
1110 |
1011 |
10010 |
|
9 |
1001 |
1100 |
1111 |
1100 |
10100 |
Перевод вручную чисел в двоично-десятичную систему нетруден и требует только использования таблицы.
Пример. Перевести из десятичной системы счисления в двоично-десятичную систему "8-4-2-1" число X = 423,1568.
Ответ:
Х=423,1568(10)=0100 0010 0011,0001 0101 0110 1000(2/10)
4 2 3 , 1 5 6 8
Обратный перевод двоично-десятичного числа в десятичную систему также не представляет большого труда. Для этого исходное число необходимо разбить на тетрады влево и вправо, начиная от точки, и каждую тетраду перевести в десятичную систему. Если крайние тетрады получаются неполными, то они дополняются нулями.
Пример. Перевести из двоично-десятичной системы "8-4-2-1" в десятичную число Х=100110100001010001,00101000001.
Решение.
Выполняем разбиение исходного числа на тетрады:
Х=0010 0110 1000 0101 0001,0010 1000 0010(2/10).
Используя таблицу, заменяем двоичные тетрады на десятичные цифры и сразу получаем ответ:
Х= 26851,282(10).
Следует обратить внимание, что хотя в двоично-десятичной записи числа используются только цифры 0 и 1, эта запись отличается от двоичного изображения данного числа. Например, десятичное число 925 в двоично-десятичной системе запишется как 1001 0010 0101(2-10). Но число 100100100101(2) дает число 2341(10). Однако для систем, когдаP =Ql, гдеP – новая система счисления, например, восьмеричная,Q – старая система (двоичная),l– целое положительное число, запись какого-либо числа в смешанной системе тождественно совпадает с изображением этого числа в системе счисления с основаниемQ. Это относится к известным нам восьмеричной и шестнадцатеричной системам счисления.
Кодирование алфавитно-цифровой информации в вычислительных системах
ЭВМ работает с программами и данными, записанными на так называемом машинном языке, на котором вся информация представляется в виде двоичных слов.
Программа вычислений – это последовательность команд, определяющих машинные операции. Программа кодируется в цифровую форму и помещается в память машины. Программа содержит в себе последовательность команд, выполнение которых обеспечивает получение требуемого результата.
Машинная команда – символьный оператор, опознаваемый и выполняемый техническими средствами машины. Код команды обеспечивает выработку в ЭВМ сигналов, требуемых для выполнения определенных операций машинами над заданными числами. Код команды и данные, с которыми работает ЭВМ, – это комбинации двоичных цифр 0 и 1.
Для первых электронных вычислительных машин программы составлялись программистами в машинных кодах в восьмеричной системе счисления и ЭВМ использовались в основном для выполнения арифметических операций.
В дальнейшем сфера применения ЭВМ быстро расширялась. В настоящее время ЭВМ применяются не столько для научно-технических расчетов, сколько для обработки самых разнообразных данных в области экономики, управления, информационном обслуживании, обучении и т. д. Появились разнообразные алгоритмические языки программирования – ПАСКАЛЬ, ФОРТРАН, C++, ПРОЛОГ и другие, – играющие роль посредников между языком человека и машинным языком. В сообщениях подобного рода содержатся буквы алфавита, цифры от 0 до 9 и некоторые специальные символы. В машине каждому из этих знаков – алфавитно-цифровых символов – соответствует определенный код.
Для ввода алфавитно-цифровых символов в машинах первого поколения применялись пятиразрядные коды. С совершенствованием ЭВМ возникла необходимость использования новых служебных, арифметических, логических и других символов и поэтому появились различные варианты шести- и семиразрядных кодов. В ЭВМ для ввода и вывода информации применяют семиразрядный и восьмиразрядный коды, в микроЭВМ применяются преимущественно семиразрядные коды.
При преобразовании символов (знаков) в цифровой код между множествами символов и кодов должно иметь место взаимнооднозначное соответствие, т. е. разным символам должны быть назначены разные цифровые коды, и наоборот. Это условие является единственным необходимым требованием при построении схемы преобразования символов в числа. Однако существует ряд практических соглашений, принимаемых при построении схемы преобразования исходя из соображений наглядности, эффективности, стандартизации. Таким образом, из соображений наглядности и легкости запоминания целесообразно множества символов, упорядоченных по какому-либо признаку (например, лексико-графическому), кодировать также с помощью упорядоченной последовательности чисел.
Другим важным моментом при организации кодировки символьной информации является эффективное использование оперативной памяти ЭВМ. Так как общеупотребительными являются примерно 100 знаков (сюда помимо цифр, букв русского и английской алфавитов; знаков препинания, арифметических знаков входят знаки перевода строки, возврата каретки, возврата на шаг и т. п.) то для взаимно-однозначного преобразования всех знаков в коды достаточно примерно сотни чисел. Значение этого выбора заключается в том, что для размещения числа из этого диапазона в оперативной памяти достаточно одного байта, а не машинного слова. Следовательно, при такой организации кодировки достигается существенная экономия объема памяти.
При назначении кодов знакам надо также учитывать соглашения, касающиеся стандартизации кодировки. Можно назначить знаковые коды по своему выбору, но также возникнут трудности, связанные с необходимостью обмена информацией с другими организациями, использующими кодировку, отличную от нашей. В настоящее время существует несколько широко распространенных схем кодирования. Например, код BCD (Binary-Coded Decimal) – двоично-десятичный код используется для представления чисел, при котором каждая десятичная цифра записывается своим четырехбитовым двоичным эквивалентом. Этот код может оказаться полезным, когда нужно преобразовать строку числовых знаков, например, строку из числовых знаков «2537» в число 2537, над которым затем будут производиться арифметические действия. Расширением этого кода является EBCDIC (Extended Binary-Coded Decimal Interchange Code) – расширенный двоично-десятичный код обмена информацией, который преобразует как числовые, так и буквенные строки.
В ЭВМ типа PDP (или СМ) применяется код ASCII (American Standard Code for Information Interchange) – американский стандартный код обмена информацией. Этот код генерируется некоторыми внешними устройствами (принтером, АЦПУ) и используется для обмена данными между ними и оперативной памятью ЭВМ. Например, когда нажимаем на терминале клавишу G, то в результате этого действия код ASCII для символа G (1000111) передается в ЭВМ. А если надо этот символ распечатать на АЦПУ, то его код ASCII должен быть послан на печатающее устройство.
Отечественной версией кода ASCII является код КОИ-7 (двоичный семибитовый код обмена информацией), который совпадает с ним, за исключением букв русского алфавита.
Представление чисел с плавающей запятой
Число в нормальной форме может быть записано как
![]()
где m– мантисса числа;
b– основание системы счисления;
p– порядок числа.
Для задания числа в нормальной форме (НФ) необходимо задать знаки мантиссы и порядка, основание системы счисления и модули мантиссы и порядка в заданной системе счисления. Поскольку взаимное изменение мантиссы и порядка приводит к изменению положения b-ичной запятой в записи числа, то НФ получила название форма с плавающей запятой.
В памяти машины числа с плавающей запятой можно записывать без значения b:
![]()
так как основание системы счисления не меняется от числа к числу, и поэтому нет смысла хранить избыточную информацию.
Записи числа по этому выражению соответствует формат, который принято называть классическим форматом чисел с плавающей точкой. Он состоит из четырех полей: знака мантиссы, мантиссы, знака порядка, порядка (рис.).
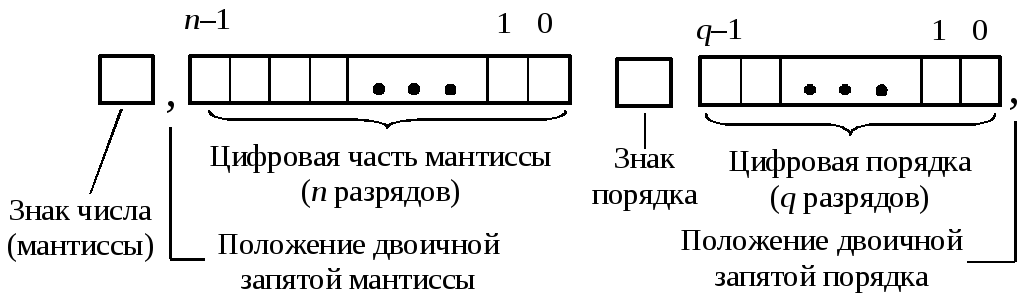
Мантисса и порядок в классическом формате представления хранятся в памяти ЭВМ в прямом коде.
Число, у которого абсолютная величина мантиссы удовлетворяет условию
![]()
называется нормализованным.
Благодаря нормализации устраняются старшие нули мантиссы. Такую нормализацию называют нормализацией справа. Это обеспечивает максимальное количество значащих цифр мантиссы при ее фиксированной длине. При этом повышается точность вычислений и упрощаются действия над порядками и мантиссами. Перед записью в память числа нормализуют.
В процессе вычислений возможно появление одного или нескольких нулей в старших разрядах мантиссы, то есть денормализация мантиссы. Денормализация мантиссы устраняется сдвигом мантиссы влево с соответствующим уменьшением величины порядка. В освободившиеся младшие разряды мантиссы записывают нули.
Примеры:
а) в десятичной системе счисления
372,95 = 0,37295103;
25 = 0,025103 = 0,25102;
0,0000015 = 1,510–6= 0,1510–5=0,01510–4;
б) в двоичной системе счисления
11010,1101 = 0,011010110126= 0,11010110125;
0,011011 = 0,110112–1.
Нормализованная мантисса в двоичной системе счисления всегда представляется десятичным числом mв диапазоне 0,5m<1.
При выполнении арифметических операций над числами, представленными в формате с плавающей запятой, надо отдельно выполнять их для порядков и мантисс. При алгебраическом сложениичисел надо сначала уравнять порядки слагаемых. При умножении порядки надо складывать, а мантиссы перемножать. При делении из порядка делимого вычитают порядок делителя, а над мантиссами совершают обычную операцию деления. После выполнения операций необходимо провести нормализацию результата, если это необходимо, что приводит к изменению порядков, так как каждый сдвиг на один разряд влево соответствует уменьшению порядка на единицу, а сдвиг вправо – увеличению его на единицу. Введение термина «плавающая запятая» как раз и объясняется тем, что двоичный порядок, определяющий фактическое положение запятой в изображении числа, корректируется после выполнения каждой арифметической операции, т. е. запятая в изображении числа плавает (изменятся ее положение) по мере изменения данной величины. А в изображении чисел с фиксированной запятой запятая жестко зафиксирована в определенном месте.
Арифметические операции с числами в форме плавающей запятой намного сложнее таких же операций для чисел с фиксированной запятой. Но зато плавающая запятая позволяет производить операции масштабирования автоматически в самой машине и избавляет отнакопления абсолютной погрешности при вычислениях (хотя не избавляет от накопления относительной погрешности).
Файлы, их виды и организация
Файлом называется именованная совокупность данных на внешнем носителе информации. В ПК понятие файла применяется в основном к данным, хранящимся на дисках (реже на кассетной магнитной ленте), и поэтому файлы обычно отождествляют с участком (областью, полем) памяти на этих носителях информации.
Данные, хранящиеся в файлах, – программы на алгоритмическом или машинном языке; исходные данные для работы программ или результаты выполнения программ; произвольные тексты; графические изображения и т. п. Понятие файла в DOS обобщается на внешние устройства и блоки компьютера (логические устройства), работающие с массивами данных: принтер, клавиатуру, дисплей, оперативную память (виртуальные диски) и т. д.
Файловой системой (ФС) называется совокупность программ, обеспечивающая выполнение операций над файлами. В настоящее время в операционных системах (ОС) для ПК используются десятки файловых систем: в DOS используются FAT16, FAT32 и FAT12 для дискет (FAT – Fail Allocation Table, таблицы размещения файлов), для Windows 9x характерны FAT16 и FAT32, популярными в Windows NT и Windows 2000 является NTFS и т. д. Но наибольшее распространение получили файловые системы DOS: FAT16 и FAT32.
В общем случае при программировании работы с файлами необходимо производить:
- указание области ОЗУ для ввода-вывода информации файла;
- чтение информации (считывания записей) из файла;
- запись информации (включение записей) в файл;
- создание файла (присвоение файлу имени, проверка уникальности этого имени файла, формирование его атрибутов и т. д.);
- изменение атрибута файла;
- открытие файла (отыскания файла на диске и перенос в ОЗУ атрибутов файла);
- закрытие файла (сохранение на диске атрибутов файла для дальнейшего использования);
- переименование файла;
- удаление файла (ликвидация).
В зависимости от версии файловой системы набор таких операций может меняться, но при этом всегда обеспечивается возможность создания и удаления файлов, а также чтение их содержимого и запись информации в них. Файловая система включает в себя также:
- правила образования имен файлов и способов обращения к ним;
- иерархическую систему оглавления файлов;
- структуру хранения файлов на дисках;
- методы доступа к содержимому файлов.
Файлы могут создаваться в двух форматах: двоичном и текстовом. Двоичный файл состоит из последовательности байтов, обычно сгруппированных в логические записи фиксированной длины. В двоичных файлах хранятся исполняемые программы и данные во внутреннем (двоичном, кодовом) представлении, Файлы с исполняемыми программами при их запуске на выполнение должны иметь определенную структуру. При выводе двоичного файла на дисплей или принтер прочесть его содержимое невозможно, так как при этом считываемые 8-разрядные двоичные коды (байты) переводятся в произвольные графические символы, звуковые сигналы или вообще не воспринимаются, если данный код не имеет графического представления и никак на устройство не действует.
Текстовой файл (файл ASCII) состоит из последовательности строк переменной длины, каждая из которых является логической записью файла. Каждая строка содержит только текстовые символы и завершается маркером конца строки. Текстовым символом может быть любой символ ASCII, но в отличие от двоичных файлов последовательность символов в текстовом файле непосредственно воспринимается человеком на экране или принтере. Текстовый файл может содержать текст программы на алгоритмическом языке (ассемблер, Basic и т. д.), таблицу, исходные и результатные данные решения задач, документы, научные сообщения и т. п.
Некоторые программные продукты (текстовые редакторы, системы управления базами данных и другие) создают файлы, близкие к текстовым, но содержащие дополнительные управляющие символы, а иногда часть информации и в двоичном коде. При выводе таких файлов на экран или принтер средствами DOS появляются символы редактирования и/или описания баз данных. Однако при чтении этих файлов средствами текстового редактора или СУБД, их создавших, они выводятся в удобочитаемом виде.
С каждым файлом связываются:
- полное имя файла;
- атрибуты (характеристики) файла;
- дата создания файла;
- время создания файла;
- длина файла.
Полное имя файла в общем случае состоит из двух частей:
- идентифицирующей – имени файла;
- классифицирующей – расширения.
Расширение, определяющее тип файла, может отсутствовать.
В имени файла может быть от 1 до 8 символов в DOS и от 1 до 255 символов в современных версиях Windows. Оно является обязательным элементом и должно всегда указываться при доступе к файлу. Расширение содержит от 1 до 3 символов и отделяется от имени файла символом «.» (точка). Хотя операционная система разрешает в имени файла и расширении наличие разных символов, рекомендуется использовать буквы латинского алфавита и цифры, а имя начинать обязательно с буквы. При назначении имен файлам рекомендуется образовывать их так, чтобы они отражали смысловое содержание файла. Расширение указывает тип файла, причем некоторые из расширений являются стандартными для операционной системы, например:
- EXE (EXEcutable – исполняемый) – файл-программа на машинном языке, готовая к выполнению;
- COM (COMmand) – файл-программа на машинном языке, готовая к выполнению (небольшая программа);
- ВАT (BATch – пачка, группа) – пакетный исполняемый командный файл;
- SYS – системный файл;
- BAS – файл-программа на языке BASIC;
- PRG – файл-программа на языке DBase;
- ASM –файл-программа на языке ассемблер;
- ТХТ – текстовый файл DOS;
- DOC – текстовый файл Windows;
- XLS – файл электронных таблиц Excel;
- ВАК– копия файла, создаваемая при перезаписи оригинала;
- ARJ – архивный файл;
- ZIP –архивный файл.
Приведенный выше список расширений содержит наиболее часто встречающиеся расширения и является далеко не полным. В трансляторах, системных программах и пакетах прикладных программ применяются расширения, являющиеся стандартными для конкретного программного продукта. Применение стандартных расширений в именах файлов позволяет компьютеру автоматически выбирать нужную процедуру обработки файла по укороченному сигналу (например, нажатие клавиши Enter).
DOS предоставляет средства для указания не одного, а сразу группы существующих на диске файлов путем задания так называемых шаблонов. Шаблоном является имя файла, в полях имени и/или расширения которого используются символы-заменители, называемые также глобальными символами. Шаблон обозначает не единственный файл, а группу существующих файлов, имена и/или расширения которых сопоставляются с данным шаблоном. Область действия шаблона ограничивается содержимым определенного каталога.
DOS использует в шаблонах глобальные символы ? и *. Вопросительный знак (?) в имени файла (расширении) означает, что в данной позиции может стоять любой (но только один!) допустимый символ. В имени файла (расширении) может быть несколько вопросительных знаков. Если символ ? стоит в конце имени или расширения, то в этой позиции может быть пусто. Например: PROG?.EXE – это шаблон исполняемого файла, имя которого начинается с букв PROG и содержит в пятой позиции любой допустимый символ. Этими файлами могут быть PROG1.EXE, PROGA.EXE, PROG.EXE и т. п. Звездочка (*) в имени (расширении) файла означает, что на ее месте, начиная с этой позиции и до конца имени (расширения), могут стоять один или несколько любых допустимых символов или не быть никаких символов (пусто). В имени или расширении допускается только по одному символу *, и все символы, стоящие за ним, игнорируются.
Например, *.ASM – все файлы с расширением ASM; Prog.* – все файлы с именем Prog с любым расширением; *.* – все файлы с любыми расширениями; ABC*.D? – все файлы, имена которых начинаются с ABC, а расширения начинаются с буквы D и имеют в его второй позиции любой допустимый символ, например ABCRK.DA, ABC.D1, ABC1.D.
Шаблоны удобно использовать в командах DOS и при работе с программными оболочками (например, Norton Commander) для поиска, копирования, перемещения и удаления групп файлов.
Управление файлами
Один из видов управления файлом – доступ. Доступом называется обращение к файлу с целью чтения или записи в него информации.
Файловая система поддерживает два метода доступа к записям файла:
- последовательный метод доступа;
- прямой (непосредственный) метод доступа.
При последовательном доступе записи из файла считываются подряд, строго в порядке их расположения в файле. Поэтому, чтобы обратиться (получить доступ) к определенной записи, необходимо читать все предыдущие. При прямом доступе обеспечивается непосредственное обращение к записи по ее номеру в файле. Механизм доступа к файлу и его записям при программировании также имеет два варианта:
- доступ к файлу с использованием специальной таблицы – управляющего блока файла;
- доступ к файлу по идентификатору.
Управляющий блок файла (FCB– file control block) содержит следующую информацию:
- номер (имя) дисковода, где установлен диск с файлом;
- имя файла и его расширение;
- текущий номер блока в файле;
- длину записи в байтах;
- размер файла в байтах;
- дату последней модификация файла;
- относительный номер записи (текущий номер);
- произвольный номер записи и т. д.
Файл состоит из блоков, объединяющих по 128 записей в каждом. Относительный номер записи – это порядковый номер записи в блоке. Параметры текущий номер блока и относительный номер записи используются при последовательном доступе к записям файла. Номер записи – это параметр, объединяющий номер блока и относительный номер записи в блоке, он используется при произвольном доступе к записям файла. Важный параметр – длина записи (точнее длина логической, кажущейся записи, которая может отличаться от длины физической записи ввиду наличия различных служебных элементов в структуре записи и файла). Длина записи используется при определении числа байт, пересылаемых при обмене информацией с ОЗУ и при определении положения записи внутри блока. Блок FCB позволяет получать доступ к файлам только в текущем каталоге.
Идентификатор файла – ASCIIZ (ASCII-zero)-стpoкa, идентифицирующая файл, содержит следующую информацию:
- номер (логическое имя) дисковода и путь к файлу (если нужно);
- имя файла и его расширение;
- нулевой байт (zero-байт).
Использование FGB для обращения к файлу позволяет реализовать и произвольный, и последовательный методы организации доступа, но часто оказывается довольно сложным; поэтому в версиях MS-DOS, начиная с DOS 2.0 и выше, введено обращение к файлу по идентификатору, которое чаще всего и применяется на практике, если не требуется выполнять детализированные процедуры с отдельными дорожками и секторами диска. Каждый файл и в случае использования FCB, и в случае использования ASCIIZ имеет свой набор атрибутов.
Атрибуты файлов
Атрибут – это набор классифицирующих файл признаков, определяющих способы его использования и права доступа к нему. ОС DOS допускает задание следующих элементов в атрибуте.
R (Read only) – файл предназначен только для чтения и не может быть ни удален, ни изменен. При попытке обновить или уничтожить такой файл системными средствами (при помощи программ DOS) будет выдано сообщение об ошибочных действиях. Атрибут устанавливается для защиты от случайного изменения или уничтожения файла.
H (Hidden) – скрытый файл, игнорируется многими командами DOS, При просмотре каталога командой DIR сведения о скрытом файле не выдаются.
S (System) – системный файл. Системные файлы обеспечивают работу внешних устройств ПК.
A (Archive) – еще не архивированный файл. Этот атрибут позволяет определить, был ли архивирован файл (архивация файла – создание его резервной копии в специальном формате). Атрибут А присваивается каждому вновь создаваемому файлу и сбрасывается (уничтожается) при архивировании файла.
Файлу могут быть присвоены одновременно любые из перечисленных атрибутов или ни один из них.
К группе атрибутов файла можно условно отнести пароль, обеспечивающий разграничение доступа к файлам. Защиту паролем обеспечивают DR DOS версий 5.0 и 6.0 и ОС Windows.
Логическая организация файловой системы
Упорядочение файлов, хранящихся в дисковой памяти, называется логической организацией файловой системы. Основой логической организации являются каталоги. Каталогом называется специальный файл, в котором регистрируются другие файлы. Наряду с термином «каталог» в сообщениях DOS и ее документации для идентификации этого файла используются также термины «раздел», «директория». В каталоге содержится вся информация, характеризующая входящие в него файлы, и сведения о том, в каком месте диска файл расположен. В частности, в каталоге содержатся следующие параметры файла: имя, расширение, атрибут, размер в байтах, дата и время создания или последнего обновления, номер начального кластера размещения файла. Сам же файл хранится как последовательность байтов без каких-либо дополнительных справочных сведений.
Каталог, в свою очередь, может входить в другой каталог – быть его подкаталогом. Самый верхний каталог, который не является ничьим подкаталогом, называется корневым каталогом (Root Directory). Место для корневого каталога резервируется при форматировании (разметке) диска и имеет стандартный размер – 3584 байта (то есть вмещает не более 112 записей по 32 байта, а если больше, то их предварительно надо объединить в подкаталоги). Корневой каталог не может быть удален средствами операционной системы.
Каждый элемент (файл или подкаталог) корневого каталога имеет размер 32 байт и включает 8 полей, для файлов это:
- имя файла – 8 байт;
- расширение имени файла – 3 байт;
- атрибут файла – 1 байт;
- резерв – 10 байт;
- время создания или последней модификации файла (час, минута, секунда) – 8 байт;
- дата создания или последней модификации файла (год, месяц, день) – 2 байт;
- номер кластера, с которого начинается файл на диске, – 2 байт;
- фактическая длина файла в байтах – 4 байт.
Каталог – это файл специального формата, содержащий записи о файлах и каталогах, которые ему подчинены. Каталог, который входит в другой каталог, называется подкаталогом или дочерним каталогом. В свою очередь, каталог, имеющий дочерние каталоги, называется родительским каталогом или надкаталогом. Как правило, если это не вызывает путаницы, употребляют термин «каталог», подразумевая или подкаталог, или надкаталог, в зависимости от контекста. Термины «подкаталог» (дочерний каталог) и «надкаталог» (родительский каталог) обычно применяют, когда речь идет о собственно структуре каталогов. Подкаталоги могут создаваться и уничтожаться пользователем. Правила наименования подкаталогов такие же, как и правила наименования файлов, но имена подкаталогов не имеют расширений. Каталог, не содержащий никаких файлов, называется пустым.
Каждый диск хранит свою файловую структуру, которая формируется по следующим правилам:
- файл или каталог может входить с одним и тем же именем в один и тот же каталог только один раз;
- допускается вхождение в различные каталоги файлов и каталогов с одинаковыми именами;
- на порядок следования файлов и подкаталогов в каталоге никаких ограничений не накладывается;
- глубина вложенности каталогов не ограничивается.
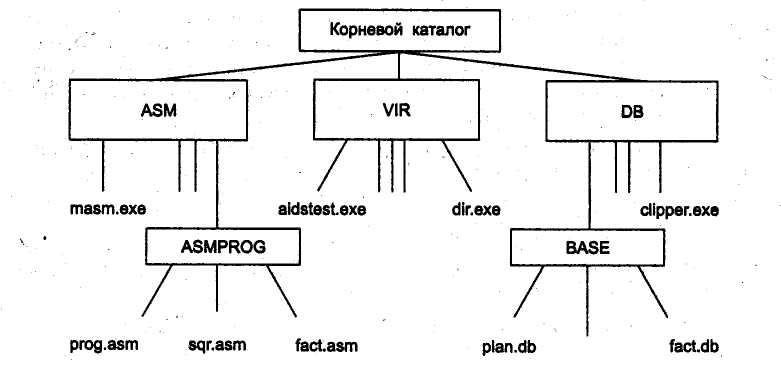
Файловая система обеспечивает формирование иерархической многоуровневой файловой структуры, в корне которой находится корневой каталог, а ветвями являются каталоги и файлы. Рассмотрим пример дерева каталогов (рисунок). Файловая структура данного примера содержит в корневом каталоге подкаталоги ASM, VIR и DB, содержащие файлы компиляторов, программ антивирусной защиты и данных. В свою очередь, подкаталог ASM содержит ассемблер (компилятор) masm .exe и подкаталог ASM PROG, в котором находятся файлы с программами на языке ассемблер. Подкаталог VIR содержит файлы aidstest.exe и dir.exe. Подкаталог DB содержит файлы базы данных.
Рисунок – Пример
дерева каталогов
Объединение файлов в каталоги не означает, что они каким-либо образом сгруппированы в одном месте на диске. Более того, один и тот же файл может быть «разбросан» (фрагментирован) по всему диску. Сведения о местонахождении отдельных частей файла хранятся в таблице размещения файлов (FAT – File Allocation Table), находящейся на том же диске.
Спецификация файла
Для того чтобы операционная система могла обратиться к файлу, необходимо указать:
- диск;
- каталог;
- полное имя файла.
Эта информация есть в спецификации файла, которая имеет следующий формат.
[drive:][\][path\]filename[.type] или в русскоязычном варианте: [дисковод:][\][путь\]имя файла[.расширение]
Квадратные скобки означают, что элементы, заключенные в них, могут отсутствовать. Сами квадратные скобки являются синтаксическими знаками и в спецификации не используются. Вся спецификация не должна иметь пробелов.
Элемент drive (дисковод) обозначает диск, на котором находится файл или куда он записывается, например А:, В:, С:, D: и т. д. Если дисковод не указан, то по умолчанию используется текущий диск. Текущий диск – это диск, с которым в настоящий момент работает операционная система (ОС). Текущий диск устанавливается автоматически после загрузки ОС и может быть переустановлен командой операционной системы. Имя текущего диска всегда выводится в подсказке на экране.
Path (путь) – это каталог или последовательность каталогов, которые необходимо пройти по дереву каталогов к тому каталогу, где находится файл. Имена в пути записываются в порядке от корневого каталога и разделяются символом «\». Путь может начинаться символом «\к в этом случае поиск файла начинается с корневого каталога. Путь может начинаться символами «\»; в этом случае поиск файла начинается с предшествующего надкаталога. Если путь опущен, то по умолчанию подразумевается текущий каталог. Например:
- D:\VIR\aidstest.exe – файл aidstest.exe находится в подкаталоге VIR на диске D:. Путь состоит из корневого каталога и подкаталога VIR. (Если текущий дисковод D, то можно указать \VIR\aidstestexe.)
- D:\ASM\ASMPROG\sqr.asm – файл sqr.asm находится в каталоге ASMPRQG. Путь состоит из корневого каталога и подкаталогов ASM и ASMPROG.
- Masm.ехе – файл masm.exe отыскивается на текущем диске в текущем каталоге. Текущим каталогом должен быть каталог ASM. (Если текущий каталог ASMPROG, то годится спецификация..masm.exe.
Дисковод и путь могут не указываться при обращении к файлам типа СОМ, EXE или ВАТ, даже если диск и каталог не являются текущими. В этом случае сведения о диске и пути указываются в команде PATH, включаемой в файл Autoexec.bat. Для стандартных посимвольных внешних устройств ПК (они выступают здесь как логические устройства) предусмотрены постоянные имена (правда, без расширений), позволяющие обращаться к ним как к файлам:
- PRN или LPT1(2, 3) – принтер;
- CON – консоль (клавиатура при вводе и дисплей при выводе);
- СОМ1(2, 3, 4) – дополнительные посимвольные внешние устройства;
- NUL – фиктивное устройство; используется при отладке программ пользователей.
Литература
1 Информатика : учебник. – 3-е изд., перераб. / Под ред. Н. В. Макаровой. – М. : Финансы и статистика, 2001. – 768 с.
2 Информатика. Базовый курс / Симонович С. В. И др. – СПб. : Питер, 2000. – 640 с.
3 Информатика : практикум по технологии работы на компьютере. – 3-е изд., перераб. / Под ред. Н. В. Макаровой. – М. : Финансы и статистика, 2001. – 256 с.