

3 Оценка адекватности и точности трендовых моделей прогноза
Для анализа рядов динамики и их прогнозирования в простейшем случае можно использовать офисные информационные технологии, реализованные в электронной таблице EXCEL. В более сложных случаях используются модели на нечетких множествах, нейронных сетях и др.
Трендовая модель временного ряда считается адекватной, если она правильно отражает систематические компоненты временного ряда. Это эквивалентно требованию, чтобы остаточная компонента:
ξt = yt - упр , t = 1, 2, ..,n
удовлетворяла свойствам случайной компоненты временного ряда: случайность колебаний, нормальность закона распределения, независимость уровней случайной компоненты.
Исследование остатков ξt полезно начинать с изучения их графика. 0н может показать наличие какой-то зависимости, не учтенной в модели. График остатков может показать необходимость перехода к нелинейной модели (квадратичной, полиномиальной, экспоненциальной) или включения в модель периодических компонент.
График остатков показывает и резко отклоняющиеся от модели наблюдения - выбросы. Подобным аномальным наблюдениям надо уделять особо пристальное внимание, так как их присутствие может грубо искажать значения оценок. Устранение эффектов выбросов может проводиться либо с помощью удаления этих точек из анализируемых данных, (эта процедура называется цензурированием), либо с помощью применения методов оценивания параметров, устойчивых к подобным грубым отклонениям.
Независимость остатков можно проверить расчетом первого коэффициента автокорреляции:
.
Для принятия решения о наличии или отсутствии автокорреляции в исследуемом ряду фактическое значение коэффициента автокорреляции r(1) сопоставляется с табличным (критическим) значением для 5%-ного уровня значимости (вероятность допустить ошибку при принятии нулевой гипотезы о независимости уровней ряда). Если фактическое значение коэффициента автокорреляции меньше табличного, то гипотеза об отсутствии автокорреляции в ряду может быть принята, а если фактическое значение больше табличного – делают вывод о наличии автокорреляции в ряду динамики, т.е. зависимости остатков.
Для обнаружения гетероскедастичности обычно используют три теста, в которых делаются различные предположения о зависимости между дисперсией случайного члена и объясняющей переменной: тест ранговой корреляции Спирмена, тест Голдфельда-Квандта и тест Глейзера [Доугерти].
При малом объеме выборки для оценки гетероскедастичности может использоваться метод Голдфельда - Квандта. Данный тест используется для проверки такого типа гетероскедастичности, когда дисперсия остатков возрастает пропорционально квадрату фактора. При этом делается предположение, что, случайная составляющая ξt распределена нормально. Оценка нарушения гомоскедастичности по тесту Голдфельда-Квандта описывалась ранее в лекции 6.
Нормальность закона распределения остатков приближенно может быть оценена проверкой статистической значимости расчетных коэффициентов асимметрии Ас и эксцесса Эс остатков, которые рассчитываются по формулам:
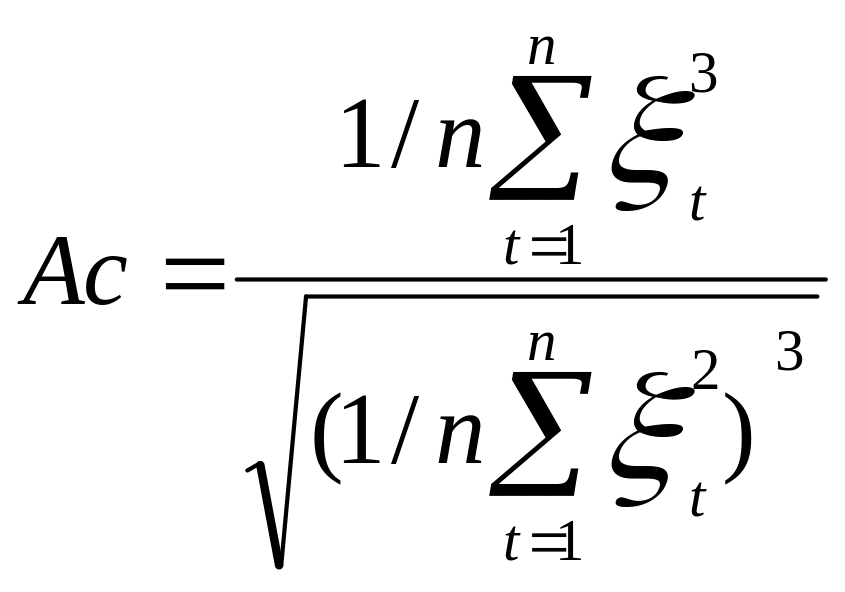 ,
,
![]() ,
,
где
![]() -
стандартная ошибка вычисления коэффициента
асимметрии;
-
стандартная ошибка вычисления коэффициента
асимметрии;
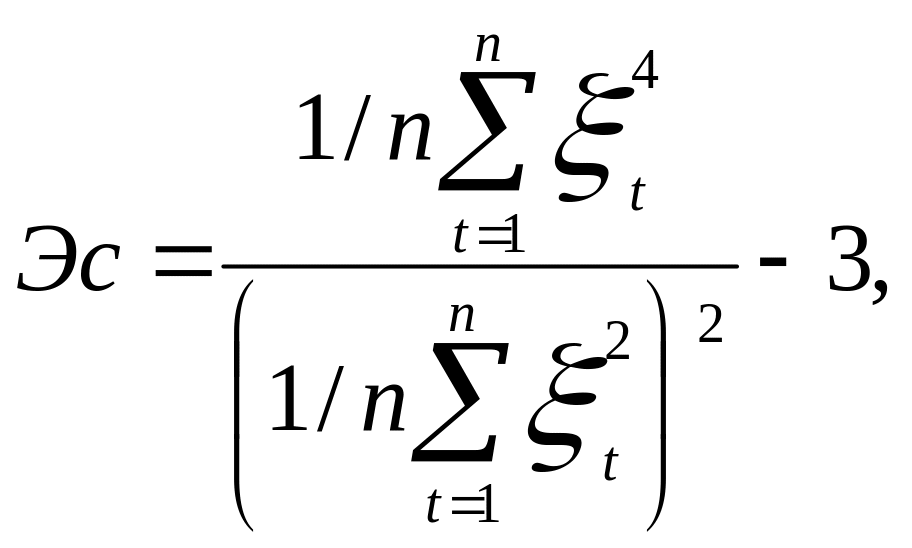
![]() ,
,
где
![]() - стандартная ошибка вычисления
коэффициента эксцесса.
- стандартная ошибка вычисления
коэффициента эксцесса.
При одновременном выполнении неравенств:
| Ас| < 1,5 , | Эс +6/(n+1)| < 1,5 ,
гипотеза о нормальности закона распределения ξt принимается. При соотношении неравенств (>= 2σ) гипотеза нормальности распределения остатков отвергается.
Адекватность модели прогноза оценивается по значению коэффициента детерминации с использованием критерия Фишера. Рассчитывается значение коэффициента детерминации по формуле:
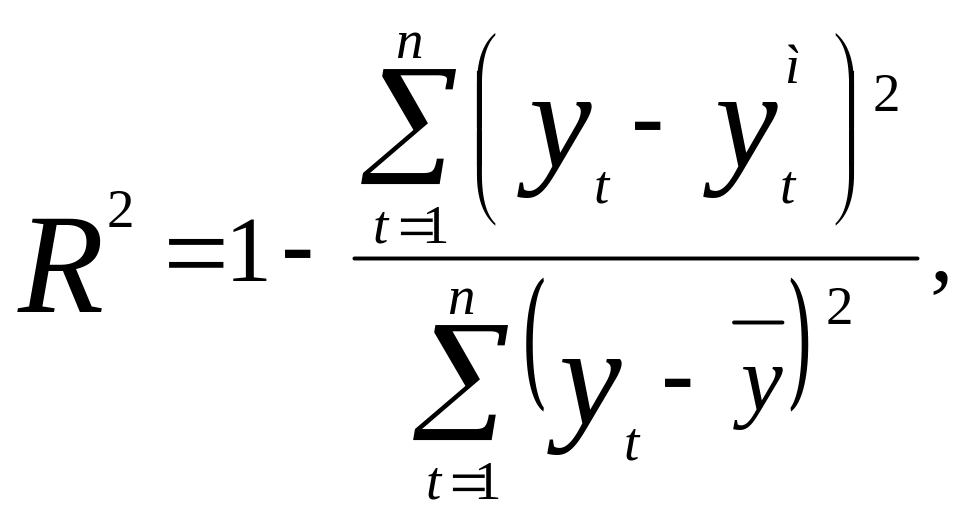
где
![]() -
фактическое значение уровня временного
ряда;
-
фактическое значение уровня временного
ряда;
![]() -
значение уровня
временного ряда, рассчитанное по модели;
-
значение уровня
временного ряда, рассчитанное по модели;
![]() -
среднее арифметическое значение
временного ряда.
-
среднее арифметическое значение
временного ряда.
Значимость коэффициента детерминации проверяется сравнением расчетного значения критерия Фишера с критическим значением:
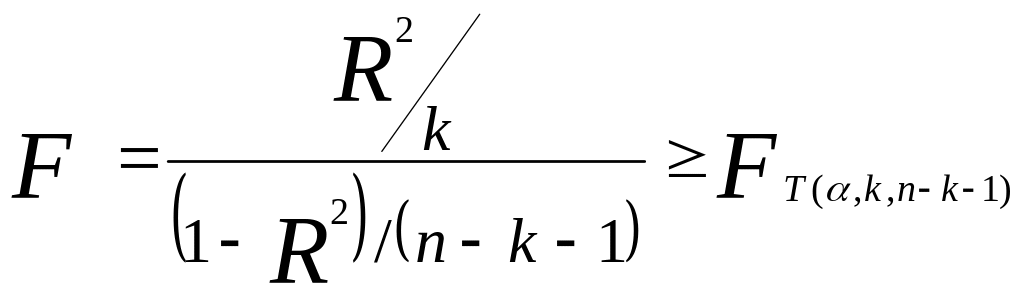 ,
,
где k – количество факторных переменных в функции тренда;
α – уровень значимости, принимается равным 0,05;
n – количество уровней в анализируемом временном ряду;
![]() -
табличное значение критерия Фишера.
-
табличное значение критерия Фишера.
При выполнении неравенства F > FT коэффициент детерминации принимается значимым, модель адекватно описывает анализируемый временной ряд.
Точность прогнозирования модели временного ряда оценивается с использованием ретроспективных данных, не использованных при построении модели временного ряда. Средняя квадратичная ошибка прогнозирования вычисляется по формуле:
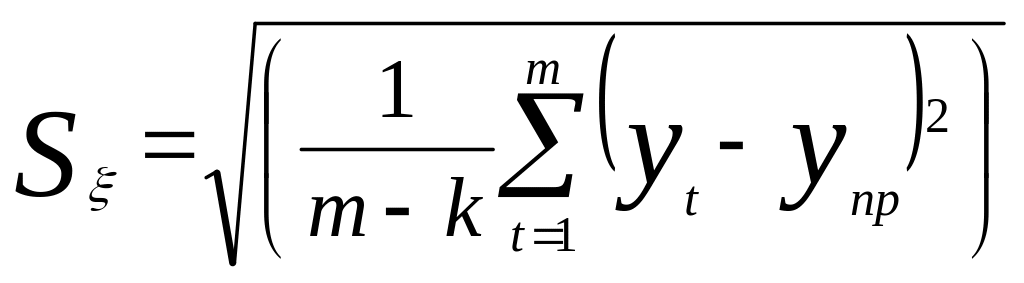
где
![]() - ошибка прогнозирования
в точках t=1,
2, …, m;
- ошибка прогнозирования
в точках t=1,
2, …, m;
k – число параметров в модели прогноза, при временном аргументе t значение k=1.