

3 Примеры заданий
3.1. Определите вероятность несанкционированного получения информации нарушителями в следующем случае:
в рассматриваемой автоматизированной системе возможны внешние нарушители, не имеющие отношения к системе;
в качестве компонентов, являющихся объектами несанкционированных действий, рассматриваются магнитные носители информации, терминалы ввода-вывода информации и принтеры;
каналами несанкционированного получения информации являются непосредственное хищение носителей, просмотр информации на экране дисплея и выдача ее на печать.
3.2. Априорные вероятности k единственно возможных гипотез об условиях наступления некоторого события B равны соответственно P1, P2, …, Pk. Каждой гипотезе отвечают соответственно вероятности наступления этого события p1, p2, …, pk, не изменяющиеся при повторении испытаний. Известно, что при n испытаниях событие B произошло m раз. Какова вероятность a posteriori каждой гипотезы?
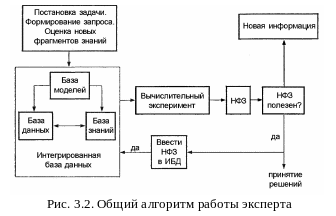
3.3. Определяющей компонентой общего алгоритма работы эксперта при решении задачи оценки уязвимости информации (рис. 3.2) является формирование так называемой интегрированной базы данных (ИБД), представляющей собой взаимосвязанную совокупность собственно базы данных (БД), базы знаний (БЗ) и базы моделей (БМ). Из всех аспектов, связанных с созданием ИБД, решающее значение приобретает проблема оценки достоверности входящей в нее информации. Синтезируйте алгоритм определения достоверности ИБД для прогнозирования показателей уязвимости информации на основе байесовского подхода.
3.4. Синтезировать модель оценки достоверности информации на основе теории игр.
4 Методические рекомендации и ответы
К заданию 3.2. Ответ.
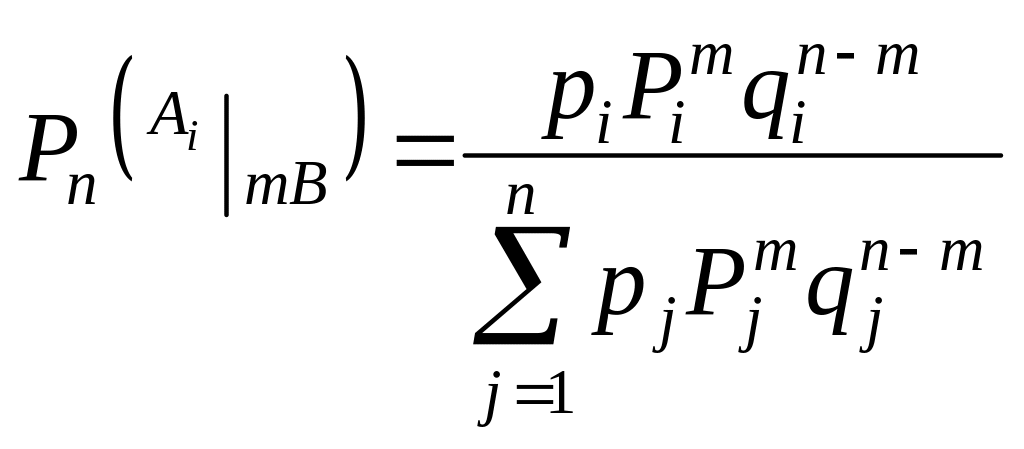 .
.
К заданию 3.3. Указание.
Достоверность (Д) фрагмента, поступающего в ИБД, зависит от достоверности источника информации и методики ее получения. Каждый вновь поступающий в ИБД фрагмент (НФЗ – новый фрагмент знаний) есть пара:
НФЗ = <3, Д>, (3.12)
где 3 - значение фрагмента.
Разделим фрагменты-свидетельства на классы:
прямые свидетельства (ПС);
косвенные свидетельства:
условные (УС);
связанные (СС).
Под прямыми свидетельствами будем понимать фрагменты типа измерения значения фрагмента-гипотезы. Они составляют выборку, на основании которой могут быть рассчитаны оценки значения фрагмента-гипотезы, и регистрируют, в основном, статистические связи между фрагментами.
Под условными свидетельствами будем понимать фрагменты типа: «если А и/или В, то С с достоверностью Р». С их помощью можно регистрировать качественные экспертные оценки, логические связи между фрагментами и априорные знания о фрагменте-гипотезе (условия применения того или иного метода, условные функции распределения и т.п.).
Связанные свидетельства регистрируют функциональные или системные связи между фрагментом-гипотезой и другими фрагментами, т.е. структуру некоторой автономной части ИБД (формулы, модели и т.п.).
Включаемый в ИБД НФЗ взаимодействует с уже содержащимися в ней фрагментами и гипотезами, изменяя как их значения, так и достоверности. Эта реакция достаточно сложна и вызывает модификацию значений и достоверностей всех старых фрагментов ИБД, так или иначе связанных с НФЗ. Для описания процесса модификации введем понятия системного значения (СЗ) и системной достоверности (СД) фрагмента ИБД, определяемых с учетом всех свидетельств, содержащихся в ИБД.
С учетом введенной классификации проблема оценки достоверности сводится к разработке методов определения в качестве атрибутов фрагмента-гипотезы ИБД системных достоверностей фрагментов, являющихся для данного фрагмента гипотезы свидетельствами, а также системной достоверности данного фрагмента-гипотезы.
Для модификации значения и достоверности фрагмента ИБД при изменении состава свидетельств можно использовать алгоритм, блок-схема которого изображена на рис. 3.3. Предполагается, что фрагменты представлены в ИБД в виде так называемых фреймов (элементов знаний), которые включают в свой состав:
3 – значение фрагмента при поступлении в ИБД;
Д – достоверность фрагмента при поступлении в ИБД;
КПС – кортеж прямых свидетельств для данного фрагмента;
КУС – кортеж условных свидетельств;
КСС – кортеж связанных свидетельств;
ПЗ, ПД – значение и достоверность фрагмента с учетом всех прямых свидетельств;
УЗ, УД – значение и достоверность фрагмента с учетом всех условных свидетельств;
СЗ, СД – системные значение и достоверность фрагмента.
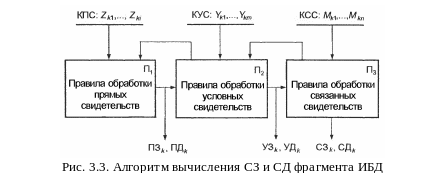
Алгоритм работает следующим образом.
В блоке П1 формируются параметры выборки прямых свидетельств и на их основе – точечные или интервальные оценки (ПЗk, ПДk) параметров распределения значения k-го фрагмента. Эти оценки присваиваются соответствующим элементам данного фрагмента и подаются на вход блока П2.
В блоке П2 вычисляются условное значение и условная достоверность (УЗk, УДk) k-го фрагмента с учетом состояния условий и ограничений блока П2 в данный момент. Полученные УЗk и УДk присваиваются соответствующим элементам фрагмента и одновременно подаются на вход блока П3. До обработки выборки можно пропустить через блок П2 каждое ПС.
В блоке П3 УЗk и УДk рассматриваются как значение и достоверность поступившего нового свидетельства и для каждого связанного свидетельства (модели, содержащей этот фрагмент) уточняется вектор состояния, а результат снова подается на вход П2. Процесс заканчивается при достижении заданного числа итераций или заданной точности оценки. Новые системные оценки получат значения всех фрагментов, являющихся составляющими векторов состояний моделей блока П3. Значения СЗk и СДk присваиваются соответствующим элементам данного фрагмента.
Очевидная проблема, возникающая при реализации описанного подхода – это разрастание числа фрагментов, вовлекаемых в алгоритм, до числа содержащихся в ИБД, включая все модели. Чтобы ее разрешить, необходимо ограничить число связей между фрагментами, регистрируя только самые существенные. Вопрос этот решает сам эксперт. Как следствие появляются варианты системной достоверности:
СДД - по K наиболее достоверным свидетельствам;
СДЦ - по K наиболее ценным свидетельствам;
СДП - по K последним свидетельствам.
Иными словами, для каждой конкретной задачи необходимо актуализировать свою определенную часть ИБД, т.е. уметь выделить наиболее существенные связи и фрагменты (доминант-фрагменты), образующие поле вычислительного эксперимента. Это позволит не только ограничить множество фрагментов и связей, но и повысит непротиворечивость фрагментов, выделенных из ИБД для решения конкретной задачи.
Рассмотрим более подробно методы обработки свидетельств, которые могут быть применены в описанном алгоритме модификации.
П
Рис.
3.4. Представление свидетельств
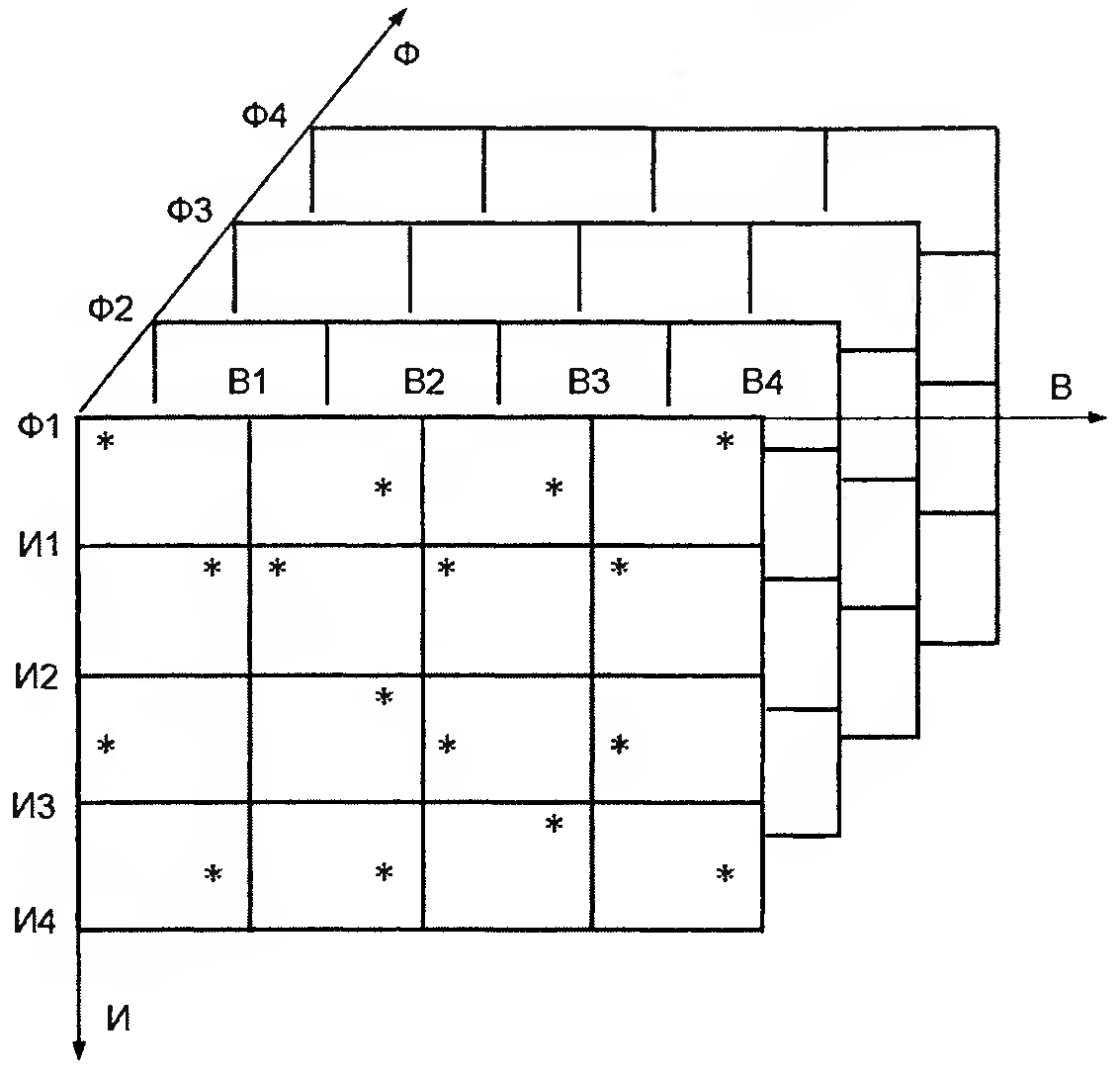
Различные сечения куба позволяют анализировать разные свойства сгруппированной таким образом информации:
зависимости фрагментов Ф1, …, Фk от источников информации И1, …, Иn на некоторый момент времени (статика);
зависимости фрагментов Ф1, …, Фk от времени по сведениям из одного источника (динамика);
зависимости одного фрагмента Фi от времени по сведениям из разных источников (динамика).
Любые достоверные данные, поступившие в ИБД и относящиеся к определенному моменту времени, рассматриваются на этот момент как эталонные, в соответствии с чем на этот же момент времени пересчитываются и достоверности источников информации. Эти методы традиционны для экспертных систем.
Вычислив параметры выборки, возможно:
назначить фрагменту-гипотезе значение и достоверность;
модифицировать всем фрагментам ПС достоверности, оставив их значения прежними;
модифицировать достоверности источников информации.
К заданию. 3.4. Указание.
Предположим, что злоумышленник затрачивает х средств с целью преодоления защиты, на создание которой израсходовано y средств. В результате он может получить защищаемую информацию, количество которой оценивается функцией I(x,y). Положим далее, что f(n) – ценность для злоумышленника n единиц информации, a g(n) – суммарные затраты на создание этого же числа единиц информации. Тогда чистая прибыль злоумышленника V(x,y) = f[I(x,y)] – x, а потери собственника информации и(х,y) = g[1(х,y)] + у.
В соответствии с известными правилами теории игр оптимальные стратегии обеих сторон могут быть определены из условий:
![]()
Для практического использования этой модели необходимо определить стоимость информации, а также задать функции I, f и g, что в условиях отсутствия необходимого объема статистических данных является практически неразрешимой проблемой, если опираться на формальные методы.
Таким образом, мы снова вынуждены возвращаться к рассмотренным в задании 3.3 приемам автоформализации знаний, которые составляют основу методологического базиса теории защиты информации.