

5 Домашнее задание
5.1. Провести классификацию по степени злого умысла угроз безопасности.
5.2. Сравните между собой различные подходы к классификации угроз безопасности информации с точки зрения наибольшего соответствия практическим потребностям создания систем защиты информации.
5.3. Охарактеризуйте основные принципы системной классификации угроз безопасности.
5.4. Перечислите технические средства обработки, хранения и передачи информации в ИТКС, создающие опасные сигналы.
Практическое занятие № 3
Типовые способы вероятностной оценки и анализа уязвимости информации в ИТКС. Методы оценки уязвимости информации в ИТКС
1 Цель занятия
Количественная оценка уязвимости информации в ИТКС.
2 Теоретические сведения
2.1. Допущения и ограничения для моделей оценки уязвимости информации в ИТКС
При решении практических задач защиты информации первостепенное значение имеет количественная оценка ее уязвимости. Ключевым моментом в решении любых задач, связанных с обеспечением информационной безопасности является правильно поставленная работа с исходными данными в условиях высокой степени их неопределенности и адекватное проведение их оценивания и уточнения. Рассматриваемые ниже подходы и модели позволяют в общем случае определять текущие и прогнозировать будущие значения показателей уязвимости информации. Для обеспечения работы моделей необходимы следующие допущения и ограничения:
необходимы исходные данные (формирование которых при отсутствии достоверной статистики сопряжено с большими трудностями);
возможности проявления каждой из потенциальных угроз не зависят от проявления других;
каждый из злоумышленников действует независимо от других, т.е. не учитываются возможности формирования коалиции злоумышленников;
негативное воздействие на информацию каждой из проявившихся угроз не зависит от такого же воздействия других проявившихся угроз;
негативное воздействие проявившихся угроз на информацию в одном каком-либо элементе системы может привести лишь к поступлению на входы связанных с ним элементов искаженной информации с нарушенной защищенностью и не оказывает влияния на такое же воздействие на информацию в самих этих элементах;
каждое из используемых средств защиты оказывает нейтрализующее воздействие на проявившиеся угрозы и восстанавливающее воздействие на информацию независимо от такого же воздействия других средств защиты;
благоприятное воздействие средств защиты в одном элементе системы лишь снижает вероятность поступления на входы связанных с ним элементов искаженной информации и не влияет на уровень защищенности информации в самих этих элементах.
В действительности же события, перечисленные выше, являются зависимыми, хотя степень зависимости различна – от незначительной, которой вполне можно пренебречь, до существенной, которую необходимо учитывать. Однако строго формальное решение данной задачи в настоящее время невозможно, поэтому остаются лишь методы экспертных оценок и, в частности, технология автоформализации знаний эксперта.
Что касается обеспечения моделей необходимыми исходными данными, то практическое использование любых предлагаемых моделей оценки уязвимости упирается в ограничения, связанные с неполнотой и недостоверностью исходных данных. В связи с этим необходима оценка и корректировка интегрированной базы данных моделирования для работы экспертов-аналитиков.
2.2. Вероятностная оценка уязвимости информации в ИТКС
Поскольку воздействие на информацию различных факторов в значительной мере является случайным, то в качестве количественной меры ее уязвимости наиболее целесообразно принять вероятность нарушения защищенности (изменения важнейших характеристик), а также потенциально возможные размеры ущерба, наносимого таким нарушением.
При этом основными параметрами, влияющими на вероятность нарушения защищенности информации, являются:
количество и типы структурных компонентов системы или объекта,
количество и типы случайных угроз, которые потенциально могут проявиться в рассматриваемый период времени,
количество и типы преднамеренных угроз, которые могут иметь место в тот же период,
число и категории лиц, которые потенциально могут быть нарушителями установленных правил обработки информации,
виды защищаемой информации.
Существуют различные подходы к структуризации показателей защищенности информации через формирование полного множества возможных КНПИ. Мы остановимся только на оценке уязвимости информации, связанной с действиями злоумышленников, поскольку в рамках спецкурса наиболее интересны вопросы реализации политики защиты и комплексный характер проблемы.
Территориально потенциально возможные несанкционированные действия могут иметь место в различных зонах:
внешней неконтролируемой зоне – территории вокруг объекта, на которой не применяются никакие средства и не осуществляются никакие мероприятия для защиты информации;
зоне контролируемой территории – территории вокруг помещений, где расположены средства обработки информации, которая непрерывно контролируется персоналом или соответствующими техническими средствами;
зоне помещений – внутреннего пространства тех помещений, в которых расположены средства обработки информации;
зоне ресурсов – части помещений, откуда возможен непосредственный доступ к ресурсам системы;
зоне баз данных – части ресурсов системы, из которых возможен непосредственный доступ к защищаемым данным.
При этом для несанкционированного получения информации необходимо одновременное наступление следующих событий:
нарушитель должен получить доступ в соответствующую зону;
во время нахождения нарушителя в зоне в ней должен проявиться (иметь место) соответствующий КНПИ;
проявившийся КНПИ должен быть доступен нарушителю соответствующей категории;
в КНПИ в момент доступа к нему нарушителя должна находиться защищаемая информация.
Введем следующие обозначения:
P(д)ikl – вероятность доступа нарушителя k-й категории в l-ю зону i-го компонента системы;
P(к)ijl – вероятность наличия (проявления) j-го КНПИ в l-й зоне i-го компонента системы;
P(н)ijkl – вероятность доступа нарушителя k-й категории к j-му КНПИ в l-й зоне i-го компонента при условии доступа нарушителя в зону;
P(и)ijl вероятность наличия защищаемой информации j-м КНПИ в l-й зоне i-го компонента в момент доступа туда нарушителя.
Тогда вероятность несанкционированного получения информации нарушителем k-й категории по j-му КНПИ в l-й зоне i-го структурного компонента системы можно определить следующим образом:
![]() . (3.1)
. (3.1)
Вероятность несанкционированного получения информации в одном компоненте системы одним злоумышленником одной категории по одному КНПИ, назовем базовым показателем уязвимости информации (с точки зрения несанкционированного получения). С учетом (3.1) выражение для базового показателя будет иметь следующий вид:
![]() . (3.2)
. (3.2)
Рассчитанные таким образом базовые показатели уязвимости имеют ограниченное практическое значение. Для решения задач, связанных с разработкой и эксплуатацией систем защиты информации, необходимы значения показателей уязвимости, обобщенные по какому-либо одному индексу (i, j, k) или по их комбинации. Рассмотрим возможные подходы к определению таких частично обобщенных показателей.
Пусть {K*} – интересующее нас подмножество из полного множества потенциально возможных нарушителей. Тогда вероятность нарушения защищенности информации указанным подмножеством нарушителей по j-му фактору в i-м компоненте системы определится выражением:
![]() . (3.3)
. (3.3)
Аналогично, если {J*} есть подмножество представляющих интерес КНПИ, то уязвимость информации в i-м компоненте по данному подмножеству факторов относительно k-го нарушителя определится выражением:
![]() . (3.4)
. (3.4)
Наконец, если {I*} есть подмножество интересующих нас структурных компонентов системы, то уязвимость информации в них по j-му КНПИ относительно k-го нарушителя
![]() . (3.5)
. (3.5)
Каждое из приведенных выше выражений позволяет производить обобщение по одному какому-либо параметру. Если интересуют подмножества {I*}, {J*} и {K*} одновременно, то
![]() . (3.6)
. (3.6)
Общий показатель уязвимости определяется при таком подходе выражением:
![]() . (3.7)
. (3.7)
На практике наибольший интерес представляют экстремальные показатели уязвимости, характеризующие наиболее неблагополучные условия защищенности информации: самый уязвимый структурный компонент систем (i’), самый опасный КНПИ (j’), самая опасная категория нарушителей (k’).
Аналогичным образом может быть проведена оценка уязвимости информации и в других случаях, в частности при нарушении целостности.
Рассмотрим далее методы расчета показателей уязвимости информации с учетом интервала времени, на котором оценивается уязвимость. При этом следует учитывать, что чем больше интервал времени, тем больше возможностей у нарушителей для злоумышленных действий и тем больше вероятность изменения состояния системы и условий обработки информации.
Можно определить такие временные интервалы (не сводимые к точке), на которых процессы, связанные с нарушением защищенности информации, являлись бы однородными. Малый интервал, в свою очередь, может быть разделен на очень малые интервалы, уязвимость информации на каждом из которых определяется независимо от других:
![]() . (3.8)
. (3.8)
где
![]() –
показатель уязвимости в точке (на очень
малом интервале), Рμ – показатель
уязвимости на малом интервале, t
– переменный индекс очень малых
интервалов, на которые поделен малый
интервал; п – общее число очень
малых интервалов.
–
показатель уязвимости в точке (на очень
малом интервале), Рμ – показатель
уязвимости на малом интервале, t
– переменный индекс очень малых
интервалов, на которые поделен малый
интервал; п – общее число очень
малых интервалов.
При этом в силу однородности происходящих процессов уязвимость информации на каждом из выделенных очень малых интервалов будет определяться по одной и той же зависимости.
Нетрудно увидеть, что рассмотренный подход можно распространить и на другие интервалы, а именно: большой интервал представить некоторой последовательностью малых, очень большой –последовательностью больших, бесконечно большой – последовательностью очень больших.
2.3. Динамическая модель оценки потенциальных угроз
Рис.
3.1. Стоимостные зависимости защиты
информации: 1 – ожидаемая полная
стоимость; 2 – стоимость защиты; 3 –
стоимость ущерба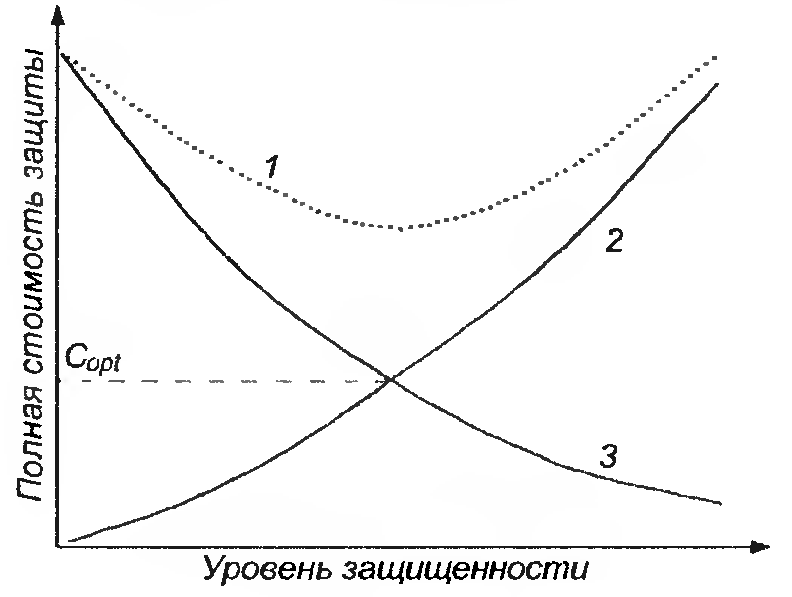
Вопрос оценки ущерба представляет на сегодняшний день наиболее сложную задачу, практически не поддающуюся формализации и решаемую только с использованием методов экспертных оценок. Исходной посылкой при разработке этих моделей может явиться очевидное предположение, что полная ожидаемая стоимость защиты информации может быть выражена суммой расходов на защиту и потерь от ее нарушения. При этом подходе оптимальным решением было бы выделение на защиту информации средств в размере Copt (см. рис. 3.1), поскольку именно при этом обеспечивается минимизация общей стоимости защиты информации.
Поскольку, как видно из рис 3.1, при оптимальном решении целесообразный уровень затрат на защиту равен уровню ожидаемых потерь при нарушении защищенности, то для оценки суммарных затрат, достаточно определить только уровень потерь.
Допустим, что
проявление угрозы рассматриваемого
типа характеризуется случайной переменной
![]() с распределением вероятностей f(λ).
Заметим, что функция распределения
f(λ) должна
определяться на основе обработки данных
о фактах реального проявления угроз
этого типа, которая проводится экспертом
с обязательной оценкой достоверности
используемой информации.
с распределением вероятностей f(λ).
Заметим, что функция распределения
f(λ) должна
определяться на основе обработки данных
о фактах реального проявления угроз
этого типа, которая проводится экспертом
с обязательной оценкой достоверности
используемой информации.
Если рассматривать
проявление данной угрозы в течение
определенного периода времени, то числу
этих проявлений
![]() будет соответствовать распределение
вероятностей f(r/λ),
которое может быть выражено функцией
распределения Пуассона:
будет соответствовать распределение
вероятностей f(r/λ),
которое может быть выражено функцией
распределения Пуассона:
![]() , (3.9)
, (3.9)
где t – период времени, на котором определены значения r.
По ряду значений r1, r2, …, rn функция f(λ), может быть выражена гамма-распределением
![]() ,
,
где а и b параметры распределения, определяемые по рекуррентным зависимостям:
![]() ,
,
где r1, r2, …, rn – число проявлений рассматриваемой угрозы в периоды наблюдения t1, t2, …, tn.
Безусловное распределение вероятностей проявления угроз за период времени t может быть представлено в виде:
![]() , (3.10)
, (3.10)
Тогда результирующее распределение имеет вид:
![]() , (3.11)
, (3.11)
Количество
проявлений угроз при этом характеризуется
математическим ожиданием
![]() и дисперсией
и дисперсией
![]() .
.
Таким образом, мы описали вероятности проявления угроз. Для того, чтобы оценить ущерб от проявления угроз, рассмотрим для начала средние оценки ущерба, для которых может быть принята нормальная функция распределения с параметрами т и D:
![]() ,
,
где fn(...) и fg(...) - функции нормального и гамма-распределений вероятностей соответственно; п' и χ' – параметры нормального и гамма распределений.
Если в заданный период времени имеет место r проявлений рассматриваемой угрозы, которые приводят к ущербу х1, х2, ..., хr соответственно, то параметры распределения вероятностей ожидаемых потерь корректируются следующим образом:
![]() ,
,
где
![]() ,
,
![]() ,
,
![]() .
.
Выделим неопределенные параметры m и D из функции распределения вероятностей для стоимости проявления угрозы данного типа. Тем самым будет получено прогнозируемое распределение для ущерба от возможного проявления рассматриваемой угрозы:
![]() ,
,
где fS(…) – член семейства распределения Стьюдента.
Ожидаемое изменение значения определяется параметрами:
![]()
Ожидаемые полные
затраты в условиях проявления
рассматриваемой угрозы
![]() определяются по формуле:
определяются по формуле:
![]() .
.
Поскольку полные затраты в условиях проявления угроз являются случайными величинами (из-за случайного характера наносимого ущерба), то для их оценки необходимо знание соответствующей функции распределения вероятностей.
Таким образом, если бы существовали систематизированные статистические данные о проявлениях угроз и их последствиях, то рассмотренную модель, можно было бы использовать для решения достаточно широкого круга задач защиты информации. Более того, эта модель позволяет не только находить нужные решения, но и оценивать их точность, что, как подчеркивалось выше, имеет принципиальное значение. К сожалению, в силу ряда объективных и субъективных причин такая статистика в настоящее время практически отсутствует, что делает особо актуальной организацию непрерывного и регулярного сбора и обработки данных о проявлениях угроз, охватывающих возможно большее число реальных ситуаций.