

Учебное пособие 800120
.pdfИными словами, от многокритериальной задачи параметрической оптимизации в виде:
K1(X) extr. .
. . . (4.4) Ks(X) extr,
gl(X) 0, l=1,…,L,
необходимо перейти к однокритериальной задаче:
f(X) extr,
gl(X)0,l=1,…,L, (4.5) X=(x1, x2.,…,xn).
Наиболее часто на практике используются следующие методы построения целевой функции (методы векторной свертки частных критериев) : метод главного критерия, аддитивный, мультипликативный, минимаксный
ивероятностный.
Вметоде выделения главного критерия проектировщик выбирает один, наиболее важный с его точки зрения частный критерий качества, который и принимается за обобщенную целевую функцию. Требования к остальным частным критериям учитывают в виде ограничений F(Х)=Kt(X), где t – номер наиболее важного частного критерия.
Например, задана принципиальная электрическая схема логического элемента и условия работоспособности на следующие выходные параметры: y1 – коэффициент нагружения, y2 – запас помехоустойчивости, y3 – средняя
59
рассеиваемая мощность, y4задержка распространения сигнала. Необходимо рассчитать параметры пассивных элементов, то есть управляемые параметры – это сопротивления резисторов. В качестве целевой функции может быть выбран один из выходных параметров,
например, y4 ( f(X)= y4 ).
В аддитивном методе каждому из частных критериев качества ставится в соответствие весовой коэффициент характеризующий важность данного критерия с точки зрения проектировщика.
При построении целевой функции в аддитивном методе используется соотношение: если f (X) max, то
f (X) 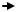 min.
min.
Каждый частный критерий включаетcя в аддитивную целевую функцию по правилу: умножается на весовой коэффициент и входит в целевую функцию со знаком плюс или минус.
Вмультипликативном методе используется
правило: если f (X) max, то 1/ f (X) min при условии, что f (X) . В отличие от аддитивного метода, частные критерии не складывают, а перемножают.
Кроме того, в мультипликативном методе не используют весовые коэффициенты. Целевая функция строится в виде дроби.
Минимаксный метод построения обобщенной целевой функции получил свое название потому, что в нем минимизируется максимальное отклонение частного критерия качества от его наилучшего, желаемого значения (технического требования, оговоренного в ТЗ). Логика минимаксного построения целевой функции заключается в том, что в каждый момент времени в качестве главного выбирается тот из частных критериев качества Ki(X), который в наибольшей степени удален от своего желаемого значения Ki*. Другими словами, минимизируется “самый
60
плохой” из частных критериев. Процесс продолжают до тех пор, пока все частные критерии не будут достаточно (с требуемой точностью) близки к своим желаемым значениям).
В случае вероятностного (статистического) метода построения обобщенной целевой функции выбирают f(X)=P(X) max, где P(X) – вероятность выполнения условий работоспособности, то есть вероятность того, что при наборе значений внутренних параметров X=(x1, x2.,…,xn ) выходные параметры объекта проектирования будут удовлетворять требованиям ТЗ. Для определения вероятности Р(Х) на практике обычно используют метод статистических испытаний (метод Монте-Карло) [ 5 ].
4.5. Методы перехода от задачи с ограничениями к
задаче |
безусловной оптимизации |
|
|||
Для |
перехода |
от |
задачи |
параметрической |
|
оптимизации |
с ограничениями |
(4.5) |
к задаче без |
||
ограничений ( к задаче безусловной оптимизации) : |
|||||
Ф(Х) extr |
|
|
|
(4.6) |
|
используется один из следующих методов: метод неопределенных множителей Лагранжа; метод штрафных функций; метод барьерных функций.
В методе неопределенных множителей Лагранжа вводятся дополнительные переменные y1,y2.,…,yL, которые называют неопределенными множителями Лагранжа. Их количество равно числу ограничений L в задаче оптимизации (4.1).
Основной проблемой при использовании метода Лагранжа является значительное увеличение размерности задачи параметрической оптимизации.
На практике задачи параметрической оптимизации решаются в основном итерационными (пошаговыми)
61
методами, которые называют методами поисковой оптимизации. При этом на каждом шаге поиска значение штрафной функции θk(X) уточняется (рассчитывается заново).
Метод штрафных функций часто называют методом внешней точки, потому что при проведении дальнейшей оптимизации поисковыми методами для метода штрафных функций неважно, принадлежит ли начальная точка поиска области работоспособности ХР.
В методе барьерных функций на границе области работоспособности ХР ставится непреодолимый барьер (целевая функция задачи безусловной оптимизации Ф(Х) возрастает до бесконечности на границе области ХР). Поэтому начальная точка поиска обязательно должна принадлежать области работоспособности, если при построении целевой функции задачи безусловной оптимизации был применен метод штрафных функций, или метод внутренней точки.
Главный недостаток метода барьерных функций заключается в том, что начальную точку поиска приходится выбирать внутри области работоспособности ХР, что представляет собой сложную задачу при малых размерах области ХР.
Таким образом, при небольшом количестве
управляемых |
параметров |
Х |
и ограничений |
g l(X), |
|
целесообразно |
применять |
метод |
неопределенных |
||
множителей Лагранжа, |
если |
проверка |
принадлежности |
||
начальной точки поиска области ХР не слишком трудоемкая задача, то применяем метод барьерных функций, в противном случае – метод штрафных функций, который, хотя и является более универсальным, но впоследствии, в ходе поисковой оптимизации требует большего числа итераций по сравнению с другими методами.
62
4.6. Назначение и классификация методов поисковой оптимизации
В связи со сложностью и малоизученностью объктов проектирования и критерии качества, и ограничения задачи параметрической оптимизации (4.6), как правило, слишком сложны для применения классических методов поиска экстремума. Поэтому на практике предпочтение отдается методам поисковой оптимизации. Рассмотрим основные этапы любого метода поиска.
Исходными данными в методах поиска являются требуемая точность метода и начальная точка поиска Х0 . Затем выбирается величина шага поиска h, и по некоторому
k+1
правилу происходит получение новых точек Х |
по |
k |
|
предыдущей точке Х при k=0,1,2,… Получение новых точек продолжают до тех пор, пока не будет выполнено условие прекращения поиска. Последняя точка поиска считается решением задачи оптимизации. Все точки поиска составляют траекторию поиска.
Методы поиска отличаются друг от друга процедурой выбора величины шага h ( шаг может быть одинаковым на всех итерациях метода или рассчитываться на каждой итерации), алгоритмом получения новой точки и условием прекращения поиска.
Для методов, использующих постоянную величину шага, h следует выбирать значительно меньше точности h ). Если при выбранной величине шага h не удается получить решение с требуемой точностью, то нужно уменьшить величину шага и продолжить поиск из последней точки имеющейся траектории.
В качестве условий прекращения поиска принято
63
использовать следующие:
1)все соседние точки поиска хуже, чем предыдущая;
2)Ф(Xk+1 )-Ф(X k) , то есть значения целевой
функции Ф(Х) в соседних точках (новой и предыдущей) отличаются друг от друга на величину не больше, чем требуемая точность ;
3) |
|
Ф(Х k+1) |
|
, i=1,…,n, то есть все частные |
|
|
|||
|
|
xi |
|
|
производные в новой точке поиска практически равны 0, |
||||
то есть отличаются от 0 на величину, не превышающую точности .
Алгоритм получения новой точки поиска Хk+1 по предыдущей точке Хk свой для каждого из методов поиска, но всякая новая точка поиска должна быть не хуже предыдущей: если задача оптимизации является задачей поиска минимума, то Ф(Хk+1) Ф(Хk).
Методы поисковой оптимизации принято классифицировать по порядку производной целевой функции, используемой для получения новых точек. Так, в методах поиска нулевого порядка не требуется вычисления производных, а достаточно самой функции Ф(Х). Методы поиска первого порядка используют первые частные
производные Ф(Х ) , i=1,…,n, а методы второго порядка
xi
используют матрицу вторых производных (матрицу Гессе). Чем выше порядок производных, тем более
обоснованным является выбор новой точки поиска и тем меньше число итераций метода. Но при этом трудоемкость каждой итерации из-за необходимости численного расчета производных.
64
Эффективность поискового метода определяют по числу итераций и по количеству вычислений целевой функции Ф(Х) на каждой итерации метода.
Рассмотрим наиболее распространенные методы поиска, расположив их в порядке уменьшения числа итераций.
Для методов поиска нулевого порядка справедливо
следующее: |
в методе случайного поиска |
нельзя заранее |
предсказать |
количество вычислений Ф(Х) |
на одной |
итерации N, а в методе покоординатного спуска N 2 n, где n- количество управляемых параметров X=( x1, x2.,…,xn).
Для методов поиска первого порядка справедливы следующие оценки: в градиентном методе с постоянным шагом N=2 n; в градиентном методе с дроблением шага N=2 n + n 1, где n1 – число вычислений Ф(Х), необходимых для проверки условия дробления шага; в методе наискорейшего спуска N=2 n+n 2, где n2 – число вычислений Ф(Х), необходимых для расчета оптимальной величины шага; а в методе Давидона – Флетчера - Пауэлла ( Д Ф П ) N=2 n + n 3, где n3 – число вычислений Ф(Х), необходимых для расчета матрицы, приближающей матрицу Гессе ( для величин n1, n2, n3 справедливо соотношение n1< n2<< n3 ).
И, наконец, в методе второго порядка - методе Ньютона N=3 n2.
При получении данных оценок предполагается приближенное вычисление производных по формулам конечных разностей [ 6 ], то есть для вычисления производной первого порядка нужно два значения целевой функции Ф(Х), а для второй производной – значения функции в трех точках.
На практике широкое применение нашли метод
наискорейшего |
спуска и |
метод |
ДФП, как методы с |
оптимальным |
соотношением |
числа |
итераций и их |
трудоемкости. |
|
|
|
|
65 |
|
|
4.7. Методы поиска нулевого порядка
4.7.1. Метод случайного поиска
В методе случайного поиска исходными данными являются требуемая точность метода , начальная точка поиска
Х0=( x10, x2. 0,…,xn0) и величина шага поиска h. Поиск новых точек производится в случайном направлении, на котором и откладывается заданный шаг h , таким образом
получают пробную точку Х и проверяют, является ли пробная точка лучшей, чем предыдущая точка поиска. Для задачи поиска минимума это означает, что :
|
|
Ф(Х) Ф(Хk), k=0,1,2… |
(4.7) |
Если условие (4.7) выполнено, то пробную точку включают
в траекторию поиска ( Х k+1 = Х ) . В противном случае, пробную точку исключают из рассмотрения и производят выбор нового случайного направления из точки Х k, k=0,1,2,… .
Несмотря на простоту данного метода, его главным недостатком является тот факт, что заранее неизвестно, сколько случайных направлений потребуется для получения новой точки траектории поиска Хk+1, что делает затраты на проведение одной итерации слишком большими. Кроме того, поскольку при выборе направления поиска не используется информация о целевой функции Ф(Х), число итераций в методе случайного поиска очень велико.
В связи с этим метод случайного поиска используется для исследования малоизученных объектов проектирования и для выхода из зоны притяжения локального минимума при поиске глобального экстремума целевой функции .
66

4.7.2.Метод покоординатного спуска
Вотличие от метода случайного поиска, в методе покоординатного спуска в качестве возможных направлений поиска выбирают направления, параллельные осям координат, причем движение возможно как в сторону увеличения, так и уменьшения значения координаты.
Исходными данными в методе покоординатного
спуска являются величина шага h и начальная точка поиска Х0=( x10, x2. 0,…,xn0). Движение начинаем из точки Х0 вдоль оси x1 в сторону увеличения координаты.Получим пробную
точку X=( x1k+h, x2.k,…,xnk), k=0. Сравним значение
функции Ф(Х) с значением функции в предыдущей точке поиска Хk.
Если Ф(Х) Ф(Хk) (мы предполагаем, что требуется решить задачу минимизации Ф(Х), то пробную точку
включают в траекторию поиска ( Х k+1 = Х ) .
В противном случае, пробную точку исключаем из рассмотрения и получаем новую пробную точку, двигаясь
вдоль |
оси x1 |
в |
сторону уменьшения координаты. |
Получим |
|
|
|
|
|
|
( x1k-h, x2. k,…,xnk ). Проверяем, |
пробную точку X |
= |
||
Ф(Х)>Ф(Хk), то продолжаем движение вдоль оси x2 в сторону
увеличения координаты. Получим пробную точку
X=( x1k, x2.k+h,…,xnk) и т.д.
67
При построении траектории поиска повторное движение по точкам, вошедшим в траекторию поиска, запрещено.
Получение новых точек в методе покоординатного спуска продолжается до тех пор, пока не будет получена точка Хk, для которой все соседние 2 n пробных точек ( по всем направлениям x1, x2.,…,xn в сторону увеличения и уменьшения значения координаты)
будут хуже, то есть Ф(Х)>Ф(Хk). Тогда поиск прекращается и в качестве точки минимума выбирается последняя точка траектории поиска Х*= Хk.
4.8. Методы поиска первого порядка
4.8. 1. Структура градиентного метода поиска
В методах поиска первого порядка в качестве направления поиска максимума целевой функции Ф(Х) выбирается вектор градиент целевой функции grad (Ф(Хk)), для поиска минимума – вектор антиградиент -grad (Ф(Хk)).
При этом используется свойство вектора градиента указывать направление наискорейшего изменения функции:
grad (Ф(Х k)) = Ф(Х k) , Ф(Х k) , |
Ф(Х k) . |
|
x1 |
x2 |
xn |
Для изучения методов поиска первого порядка важно также следующее свойство: вектор градиент grad (Ф(Хk)), направлен по нормали к линии уровня функции Ф(Х) в точке Хk
Линии уровня – это кривые, на которых функция принимает постоянное значение (Ф(Х)=соnst).
В данной главе мы рассмотрим пять модификаций градиентного метода:
68

градиентный метод с постоянным шагом, градиентный метод с дроблением шага, метод наискорейшего спуска, метод Давидона-Флетчера-Пауэлла, двухуровневый адаптивный метод.
4.8. 2. Градиентный метод с постоянным шагом В градиентном методе с постоянным шагом
исходными данными являются требуемая точность , начальная точка поиска Х0 и шаг поиска h.
Получение новых точек производится по формуле:
Хk+1= Хk – h grad Ф(Хk), k=0,1,2,… |
(4.8) |
Формула (4.8) применяется, если для функции Ф(Х) необходимо найти минимум. Если же задача параметрической оптимизации ставится как задача поиска максимума, то для получения новых точек в градиентном методе с постоянным шагом используется формула:
Хk+1= Хk + h grad Ф(Хk), k=0,1,2,… |
(4.9) |
Каждая из формул (4.8), (4.9) является векторным
соотношением, включающим n уравнений. Например, с
учетом Хk+1=( x1k+1, x2. k+1,…,xnk+1), Хk=( x1k, x2. k,…,xnk)
формула (3.8) примет вид:
x1 k+1 = x1 k - h Ф(Х k)
x1
x2 k+1 = x2 k - h Ф(Х k) x2
. |
. |
. |
(4.10)
xn k+1 = xn k - h Ф(Х k). xn
Вобщем виде (4.10) можно записать:
xik+1 = xi k - h Ф(Х k), i=1,…,n.
xi
В качестве условия прекращения поиска во всех градиентных методах используется, как правило, комбинация двух условий: Ф(Xk+1 ) - Ф(X k) или
Ф(Х k+1) для всех i=1,…,n. xi
Вградиентном методе можно несколько сократить число итераций, если научиться избегать ситуаций, когда несколько шагов поиска выполняются в одном и том же направлении.
4.8.3.Градиентный метод с дроблением шага
Вградиентном методе с дроблением шага процедура подбора величины шага на каждой итерации реализуется следующим образом.
Исходными данными являются требуемая точность
, начальная точка поиска Х0 и начальная величина шага поиска h (обычно h=1). Получение новых точек производится по формуле:
Хk+1= Хk – hk grad Ф(Хk), k=0,1,2,…, |
(4.11) |
где hk – величина шага на k-ой итерации поиска, при hk должно выполняться условие:
Ф(Хk – hk grad Ф(Хk) ) Ф(Хk) - hk grad Ф(Хk) 2. (4.12)
70
69
Если величина hk такова, что неравенство (3.6) не выполнено, то производится дробление шага до тех пор, пока данное условие не будет выполнено. Дробление шага выполняется по формуле hk = hk , где 0 1.Такой подход позволяет сократить число итераций, но затраты на проведение одной итерации при этом несколько возрастают.
4.8.4. Метод наискорейшего спуска
В методе наискорейшего спуска на каждой итерации градиентного метода выбирается оптимальный шаг в направлении градиента. Исходными данными являются требуемая точность , начальная точка поиска Х0.
Получение новых точек производится по формуле:
Хk+1= Хk – hk grad Ф(Хk), k=0,1,2,… , |
(4.13) |
где hk = arg min Ф(Хk – hk grad Ф(Хk)), 0<h<
то есть выбор шага производится по результатам одномерной оптимизации по параметру h.
Основная идея метода наискорейшего спуска заключается в том, что на каждой итерации метода выбирается максимально возможная величина шага в направлении наискорейшего убывания целевой функции,
то есть в направлении вектора-антиградиента функции Ф(Х) в точке Хk .
При выборе оптимальной величины шага необходимо из множества ХМ={ Х Х= Хk–h grad Ф(Хk), h [0, ) } точек, лежащих на векторе градиенте функции Ф(Х), построенном в точке Хk выбрать ту, где функция Ф( h ) = Ф(Хk – h grad Ф(Хk)) принимает минимальное значение.
71
Таким образом, метод наискорейшего спуска нашел точку минимума целевой функции за одну итерацию ( из-за того, что линии уровня функции Ф(x1, x2)=(x1 – 1)2 + ( x2 – 2)2 окружности (x1 – 1)2 + (x2–2)2 =c onst, и вектор антиградиент из любой точки точно направлен в точку минимума – центр окружности).
На практике целевые функции гораздо более сложные, линии также имеют сложную конфигурацию, но в любом случае справедливо следующее: из всех градиентных методов в методе наискорейшего спуска наименьшее число итераций, но некоторую проблему представляет поиск оптимального шага численными методами, так как в реальных задачах, возникающих при проектировании РЭС применение классических методов нахождения экстремума практически невозможно. Численные методы однопараметрической (одномерной) оптимизации содержатся в разделе 4.10 данного пособия.
4.8. 5. Двухуровневый адаптивный метод
Для задач оптимизации в условиях неопределенности (оптимизация стохастических объектов), в которых один или несколько управляемых параметров являются случайными величинами, используется двухуровневый адаптивный метод поисковой оптимизации, являющийся модификацией градиентного метода.
Исходными данными являются требуемая точность, начальная точка поиска Х0 и начальная величина шага поиска h (обычно h=1 ). Получение новых точек производится по формуле:
Хk+1= Хk – hk+1 grad Ф(Хk), k=0,1,2,…, |
(4.14) |
72
где шаг hk+1 может быть рассчитан по одной из двух формул: hk+1 = hk+ k+1 k, или hk+1 = hkexp(k+1 k). В
качестве понижающего коэффициента выбирают обычноk=1/k, где k- номер итерации поискового метода.
Смысл применения коэффициента k заключается в том, что на каждой итерации производится некоторая корректировка величины шага, при этом чем больше номер итерации метода поиска, тем ближе очередная точка поиска к точке экстремума и тем аккуратнее (меньше) должна быть корректировка шага с тем, чтобы не допустить удаления от точки экстремума.
Величина k определяет знак такой корректировки
( при k>0 шаг |
увеличивается, а при k<0 уменьшается): |
|
|
k=sign{(grad Ф(Хk),grad Ф(Х))}, |
|
то есть k – это знак скалярного произведения векторов |
|
|
|
градиентов целевой функции в точках Хk и Х, где |
|
|
|
Х=Хk – hkgrad Ф(Хk) пробная точка, а hk- это шаг , который был использован для получения точки Хk на предыдущей итерации метода (рис. 3.6).
Знак скалярного произведения двух векторов позволяет оценить величину угла между данными векторами ( обозначим этот угол ).
Если 9, то скалярное произведение должно быть положительным, в противном случае – отрицательным.
С учетом вышеизложенного нетрудно понять принцип
корректировки |
величины шага |
в двухуровневом |
адаптивном методе. |
|
|
Если угол |
между антиградиентами (острый |
|
|
73 |
|
угол), |
то направление поиска из точки Хk выбрано |
правильно, и величину шага надо увеличить. |
|
|
Если же угол между антиградиентами (тупой |
угол), |
то направление поиска из точки Хk удаляет нас от |
точки минимума Х*, и шаг нужно уменьшить .
Метод носит название двухуровневого, так как на каждой итерации поиска анализируются не одна, а две точки и строятся два вектора антиградиента.
Это, конечно, увеличивает затраты на проведение одной итерации, но позволяет проводить адаптацию (настройку) величины шагаhk+1 на поведение случайных факторов.
4. 9. Методы поиска второго порядка
Несмотря на простоту реализации метод наискорейшего спуска не рекомендуется в качестве “серьезной” оптимизационной процедуры для решения задачи безусловной оптимизации функции многих переменных, так как для практического применения он работает слишком медленно.
Причиной этого является тот факт, что свойство наискорейшего спуска является локальным свойством, поэтому необходимо частое изменение направления поиска, что может привести к неэффективной вычислительной процедуре.
Более точный и эффективный метод решения задачи параметрической оптимизации (4.6) можно получить, используя вторые производные целевой функции (методы второго порядка). Они базируются на аппроксимации (то есть приближенной замене) функции Ф(Х) функцией (Х),
(Х)=Ф(Х0)+(Х-Х0) тgradФ(Х0)+1 G(X0) (Х-Х0), |
(4.15) |
2
74
где G(X0)- матрица Гессе ( гессиан, матрица вторых производных), вычисленная в точке Х0:
|
2Ф(Х ) |
2Ф(Х ) . . . |
2Ф(Х ) |
|
|
|
x12 |
|
x1 x2 |
x1 xn |
|
G(X) = 2Ф(Х ) |
2Ф(Х ) . . . |
2Ф(Х ) |
|
||
|
x2 x1 |
x2 2 |
x2 xn |
|
|
|
2Ф(Х ) |
2Ф(Х ) . . . |
2Ф(Х ) |
|
|
|
xn x1 |
xn x2 |
xn2 |
. |
|
Формула (4.15) представляет собой первые три члена разложения функции Ф(Х) в ряд Тейлора в окрестности точки Х0, поэтому при аппроксимации
функции Ф(Х) функцией (Х) возникает ошибка не более чем Х-Х0 3.
С учетом (4.15) в методе Ньютона исходными данными являются требуемая точность , начальная точка поиска Х0 и получение новых точек производится по формуле:
Хk+1= Хk – G-1(Хk) grad Ф(Хk), k=0,1,2,…, |
(4.16) |
где G-1(Хk) – матрица, обратная к матрице Гессе, вычисленная в точке поиска Хk ( G(Хk) G-1(Хk) = I,
1 0 … 0
I = 0 1 … 0 - единичная матрица).
…
0 0 … 1
75
Главным недостатком метода Ньютона являются затраты на вычисление обратного гессиана G-1(Хk) на каждой итерации метода.
В методе Давидона – Флетчера - Пауэлла (ДФП) преодолены недостатки как метода наискорейшего спуска, так и метода Ньютона .
Достоинством данного метода является то, что он не требует вычисления обратного гессиана, а в качестве направления поиска в методе ДФП выбирается направление -Нk gradФ(Хk), где Нk - положительно определенная симметричная матрица, которая заново рассчитывается на каждой итерации (шаге метода поиска) и приближает обратный гессиан G-1(Хk) (Нk G-1(Хk) с увеличением k).
Кроме того, метод ДФП при его применении для поиска экстремума функции n переменных сходится (то есть дает решение) не более чем за n итераций.
Вычислительная процедура метода ДФП включает следующие шаги. Исходными данными являются требуемая точность , начальная точка поиска Х0 и начальная матрица Н0 (обычно единичная матрица, Н0 = I ).
1.На k-ой итерации метода известны точка поиска Хk
иматрица Нk (k=0,1,…).
2.Обозначим направление поиска
|
dk = -Нk gradФ(Хk). |
Находим |
оптимальную величину шага k в |
направлении dk с помощью методов одномерной оптимизации (так же, как в методе наискорейшего спуска выбиралась величина в направлении ветора антиградиента)
З. Обозначим vk= k dk и получим новую точку поиска Хk+1=Xk + vk.
76

4. Проверяем выполнение условия прекращения поиска .
Если vk или gradФ (Хk+1) , то решение найдено Х*= Хk+1. В противном случае продолжаем вычисления.
5Обозначим uk = gradФ(Хk+1)- gradФ(Хk) и матрицу Нk+1 рассчитаем по формуле:
Hk+1= Hk + Ak + Bk, |
(4.17) |
|
где Ak = vk. vkT / (vkT uk), |
Bk = - Hk uk. ukT. Hk / (ukT Hk uk). |
|
Ak и Вk это вспомогательные матрицы размера n х n (vkT
соответствует вектору-строке, vk означает вектор-столбец, результатом умножения n-мерной строки на n-мерный столбец является скалярная величина (число), а умножение столбца на строку дает матрицу размера nxn).
6. Увеличиваем номер итерации на единицу и переходим к пункту 2 данного алгоритма.
Метод ДФП – это мощная оптимизационная процедура, эффективная при оптимизации большинства функций. Для одномерной оптимизации величины шага в методе ДФП используют методы интерполяции.
4.10. Методы оптимизации функции одной переменной
4.10.1. Метод квадратичной интерполяции
Метод квадратичной интерполяции (метод Пауэлла) заключается в приближенной замене целевой функции
одной переменной f() квадратичной функцией2 С. Для вычисления коэффициентов А, В, С квадратичной функции необходимо знать значения
77
аппроксимируемой функции f() в трех точках 1, 2, 3:
|
f |
|
|
|
2 |
С=f |
, |
f =f( |
) |
|
|
|
|
|
|
1 |
1 |
1 |
|
1 |
1 |
|
|
2f2 |
|
22 2 С=f2 |
, |
f2=f(2) |
(4.18) |
||||||
3f3 |
|
32 3 С=f3 |
, |
f3=f(3). |
|
||||||
В точке минимума * квадратичной функции/ *=0 и // *>0, поэтому *= -В/ (2А) при А>0. Решив
систему уравнений (3.12) и подставив выражения величин А, В, и С в формулу для *, получим
1 (22- 32)f1 + (32- 12)f2 + (12- 22)f3*=
2 ( 2- 3) f1 + ( 3- 1) f2 ( 1- 2) f3 .
Рассмотрим основные шаги метода Пауэлла.
1.Исходными данными являются требуемая точность
и величина h.
2.Точку 1 задаем произвольно и, по возможности,
ближе к точке минимума * , 2= 1+h , а чтобы выбрать третью точку 3 сравним f(1) и f(2) (рис.3.8). Если f(1)< f(2), то 3=1-h, в противном случае 3=1+2 h, вычисляем f(3),
3.По формуле (3.13) находим *1.
4.Проверим, можно ли точку * считать точкой
минимума с точностью , то есть f(*k+1)-f(*k) , k=0,1, ... На первой итерации считаем, что *0 = 1. Если условие прекращения поиска выполнено, то задача решена и *= *k+1.
78