

3.7.4. Взаимоисключения
В многозадачных однопроцессорных системах процессы чередуются, обеспечивая эффективное выполнение программ. В многопроцессорных системах возможно не только чередование, но и перекрытие процессов.
Способы взаимодействия процессов (потоков) можно классифицировать по степени осведомленности одного процесса о существовании другого.
1. Процессы не осведомлены о наличии друг друга (например, процессы разных заданий одного или различных пользователей). Это независимые процессы, не предназначенные для совместной работы. Хотя эти процессы и не работают совместно, ОС должна решать вопросы конкурентного использования ресурсов. Например, два независимых приложения могут затребовать доступ к одному и тому же диску или принтеру. ОС должна регулировать такие обращения.
2. Процессы косвенно осведомлены о наличии друг друга (например, процессы одного задания). Эти процессы не обязательно должны быть осведомлены о наличии друг друга с точностью до идентификатора процесса, однако они разделяют доступ к некоторому объекту, например буферу ввода-вывода, к файлу или БД. Такие процессы демонстрируют сотрудничество при разделении общего объекта.
3. Процессы непосредственно осведомлены о наличии друг друга (например, процессы, работающие последовательно или поочередно в рамках одного задания). Такие процессы способны общаться один с другим с использованием идентификаторов процессов и изначально созданы для совместной работы. Эти процессы также демонстрируют сотрудничество при работе.
Совместное использование общего ресурса различными задачами (или процессами) при отсутствии согласованности может привести к ошибкам функционирования. Эту задачу решают путем взаимоисключения, т.е. путем предоставления каждому процессу монопольного исключительного права доступа к разделяемым данным.
Взаимоисключение необходимо только в том случае, когда процессы обращаются к общим данным.
Если они выполняют операции, не приводящие к конфликтным ситуациям, они должны работать параллельно.
Когда процесс производит обращение к разделяемым данным, то говорят, что он находится на критическом участке. Таким образом, решение проблемы взаимоисключения в том, что если один процесс находится на своем критическом участке, необходимо исключить вхождение другого процесса на свой критический участок. Выполнение другого процесса продолжается, но без входа в критический участок (рис. 11). Если же это невозможно, процесс должен ожидать освобождения критических данных. Это одна из ключевых проблем параллельного программирования. Она решается программно, а в особо ответственных случаях аппаратно.
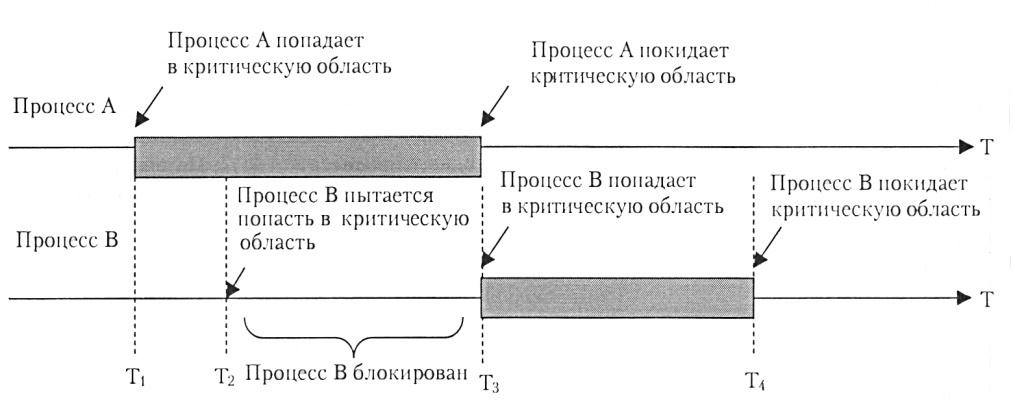
Рис. 11. Поведение процессов в критической области
Требования к критическому участку:
– в любой момент времени только один процесс может находиться внутри критического участка;
– ни один процесс не может оставаться внутри критического участка бесконечно долго;
– ни один процесс не должен ждать бесконечно долго входа в критический участок.
Для двух процессов задача решается алгоритмом Деккера. В этом алгоритме две задачи конкурируют за использование общего критического участка. Доступ к критическому участку предоставляется задачам попеременно. Данный алгоритм был усовершенствован Петерсоном.
shared int ready[2] = {0, 0};
shared int turn;
while (some condition)&&
{
ready [i] = 1;
turn =1- i;
while (ready [1-i]&& turn == 1-i);
critical section ready [i] = 0;
remainder section
}
При исполнении пролога критической секции процесс Pi заявляет о своей готовности исполнить критический участок и одновременно предлагает другому процессу приступить к его выполнению. Если оба процесса подошли к прологу практически одновременно, то они оба объявят о своей готовности и предложат выполняться друг другу. При этом одно из предложений всегда последует после другого. Тем самым работу в критическом участке продолжит процесс, которому было сделано последнее предложение.
Для трех или более процессов разработан так называемый «алгоритм булочной» (bakery algorithm). Основная его идея выглядит так. Каждый вновь прибывающий клиент (он же процесс) получает «талончик» на обслуживание с номером. Клиент с наименьшим номером на «талончике» обслуживается следующим. К сожалению, из-за специфики операции вычисления следующего номера алгоритм булочной не гарантирует, что у всех процессов будут «талончики» с разными номерами. В случае равенства номеров на «талончиках» у двух или более клиентов первым обслуживается клиент с меньшим значением имени (имена можно сравнивать в лексикографическом порядке).
Разделяемые структуры данных для алгоритма – это два массива:
shared enum {false, true} choosing[n];
shared int number[n];
Изначально элементы этих массивов инициируются значениями false и 0 соответственно. Введем следующие обозначения:
(a,b) < (c,d), если а < с или если а == с и b < d
max(a0, al,…,an) - это число k такое, что k >= ai для всех i = 0, ...,n.
Структура процесса Pi для алгоритма булочной приведена ниже
while (some condition):
{
choosing[i] = true;
number[i] = max (number[0],number[n-1]) + 1;
choosing[i] = false;
for(j = 0; j<n; j++)
{
while (choosing[i]);
while (number[j] != 0 && (number[j],j) < (number[i],i));
}
critical section
number[i ] = 0;
remainder section
}