

7.4. Сжатие данных
В качестве примера рассмотрим несколько записей со следующими данными:
Студент
Студентка
Студенческий
Предположим, что длина поля составляет 15 символов и справа от данных в несжатом виде содержится соответствующее количество пробелов. Один из способов применения сжатия на основе различий - это удаление повторяющихся символов в начале каждой записи с указанием их количества, т. е. переднее сжатие. В результате будет получено (числа соответствуют количеству повторяющихся символов в начале имени, пробелы справа до полной длины поля -15 символов - не показаны):
0 - Студент
7 - ка
6 - ческий
При необходимости можно осуществить дополнительное сжатие, удаляя пробелы с указанием их количества, т. е. выполнить так называемое заднее сжатие. Иногда еще допускается удаление с правого конца каждого значения всех повторяющихся символов в двух ближайших соседних значениях.
Другим способом уменьшения объема занимаемого данными места является иерархическое сжатие. Предположим, что в хранимом файле задана некоторая физическая последовательность согласно выбранному полю, различные значения которого располагаются в нескольких последовательных записях этого файла.
Например, в хранимом файле успеваемости благодаря кластеризации, выполненной согласно полю PN с названиями предметов, отдельно содержатся все записи о студентах, сдавших тот или иной предмет. В таком случае набор всех записей с данными о студентах, сдавших тот или иной предмет, может быть успешно сжат в одну хранимую иерархическую запись, при этом название предмета будет упомянуто только один раз, а вслед за ним будут расположены данные о студентах (см. рис. 7.3).
Хранимая иерархическая запись состоит из двух частей: постоянной, в нашем примере это поля с названиями предметов, и переменной - записи с информацией о студентах. Такой набор значений переменного количества внутри одной записи обычно называется группой повторения. Таким образом, можно сказать что иерархическая запись, представленная на рис. 7.5, состоит из значения поля предметов, и группы повторения с информацией о студентах, состоящей из полей с номерами студенческих билетов, фамилий студентов и оценок по предмету.
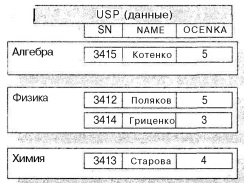
Рис. 7.5. Внутрифайловое иерархическое сжатие файла с данными об успеваемости
Иерархическое сжатие такого типа применяют и для индекса, в котором несколько последовательно расположенных значений содержат одни и те же повторяющиеся значения данных, но различные значения указателей.
Аналогичным образом можно применять иерархическое сжатие на основе межфайловой кластеризации. Например, записи с данными о студентах как бы объединяются с данными о всех оценках по всем предметам для данного студента.
В заключение отметим, что структуру на основе цепочки указателей, вообще говоря, можно рассматривать как межфайловое сжатие, которое не требует межфайловой кластеризации, т. к. указатели позволяют логически достичь эффекта кластеризации.
Кодирование Хафмана - это еще одна технология кодирования символов, которая может быть весьма эффективной для сжатия различных символов, встречающихся с разной частотой. Основная идея этого метода заключается в кодировании отдельных символов битовыми строками различной длины, причем наиболее часто встречающиеся символы кодируются строками наименьшей длины. Кроме того, код любого символа длиной n не должен совпадать с первыми n символами кода какого-либо другого символа.
Предположим, что некоторые данные записаны с помощью символов А, Б, В, Г, Д, тогда с учетом относительной частоты, с которой они встречаются, их коды приведены в таблице.
Коды символов
Символ |
Частота, % |
Код |
А |
35 |
1 |
В |
30 |
01 |
Г |
20 |
001 |
Д |
10 |
0001 |
Б |
5 |
00001 |
Символ А встречается чаще остальных, и потому имеет самый короткий код, состоящий из одного бита. Все остальные коды должны быть длиннее, однако нельзя использовать код на основе одного нуля, так как он будет совпадать с начальной частью других, более длинных кодов. Оценочно можно сказать, что в среднем общая длина закодированного текста на 40% меньше, чем при отсутствии кодирования.
Таким образом, рассмотрены важнейшие современные структуры хранения данных, описана общая схема функционирования программного обеспечения, предназначенного для доступа к данным, а также распределение выполнения этих задач между СУБД, диспетчером файлов и диспетчером дисков. Основной целью изложения было разъяснение общих идей и принципов без описания отдельных подробностей их реализации в разных практически используемых системах и структурах хранения.