

7.3. Процедура индексирования и хеширования
Для того чтобы детальнее разобраться с индексами, рассмотрим в качестве примера таблицу с данными об оценках и запрос на поиск студентов, сдававших тот или иной учебный предмет. При таких условиях в БД можно выбрать способ хранения данных, схематически показанный на рис. 7.1.
Он основан на двух хранимых файлах: файле с данными об успеваемости студентов USP и файле с данными об учебных предметах. Эти файлы могут размещаться в различных наборах страниц, при этом предполагается, что в файле предметов используется упорядочение по алфавитному перечню их названий.

Рис. 7.1. Индексирование файла оценок по полю PN
Возможны следующие стратегии, которые можно применить для поиска всех студентов, сдававших физику:
- найти весь файл успеваемости, найти все записи, для которых названием дисциплины является строка "Физика";
- найти файл предметов со строкой "Физика", а затем согласно указателям извлечь все соответствующие записи из файла успеваемости.
Если доля всех студентов, сдавших физику, по отношению к общему количеству студентов невелика, то вторая стратегия будет гораздо эффективнее первой. Дело в том, что СУБД известна физическая последовательность записей в файле предметов, а поиск будет прекращен после извлечения следующего за физикой в алфавитном порядке названии предмета. Кроме того, даже если придется просмотреть файл предметов полностью, для такого поиска потребуется гораздо меньше операций ввода-вывода, поскольку физический размер файла предметов меньше, чем размер файла успеваемости из-за меньшего размера записей.
В рассмотренном примере файл предметов называют индексным файлом или индексом по отношению к файлу успеваемости, или наоборот - файл успеваемости индексирован по отношению к файлу предметов. Индексный файл является хранимым файлом особого типа, в котором каждая запись состоит из двух значений: данных и указателя номера записи. При этом данные необходимы для индексного поля из индексированного файла, а указатель - для связывания с соответствующей записью индексированного файла.
Если индексирование организовано на основе ключевого поля, например, на основе поля SN файла успеваемости, то индекс называется первичным. А если индекс организован на основе другого поля, например, поля PN, то он называется вторичным.
Кроме того, индекс, организованный на основе ключевого поля или другого ключа, называется уникальным.
Основным преимуществом использования индексов является значительное ускорение процесса выборки или извлечения данных, а основным недостатком - замедление процесса обновления данных, т. к. при каждом добавлении новой записи в индексированный файл потребуется также добавить новый индекс в индексный файл. Индексы можно использовать двумя разными способами:
- для последовательного доступа к индексированному файлу, т. е. в последовательности, заданной значениями индексного поля. Например, индекс PN будет определять доступ к записям файла успеваемости согласно алфавитному перечню предметов;
- индексы могут использоваться и для прямого доступа к отдельным записям индексированного файла на основе заданного значения индексного поля, как это было сделано в приведенном примере.
Хранимый файл может иметь несколько индексов: например, хранимый файл успеваемости может иметь индекс PN и индекс OCENKA (см. рис. 7.2).
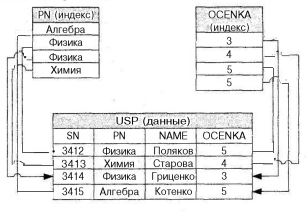
Рис. 7.2. Индексирование файла оценок по полю PN и OCENKA
Индексы могут как раздельно, так и совместно использоваться для более эффективного доступа к данным об успеваемости, например, при запросе на поиск студентов, сдавших физику на 5.
Тогда согласно индексу PN для студентов будут найдены записи с идентификационными указателями z3412 и z3414, а согласно индексу OCENKA - записи с указателями z3412 и z3415. Понятно, что на основе сравнения этих двух наборов записей условиям запроса удовлетворяет только запись с данными о студенте z3412 и только после этого в СУБД будет организован доступ к файлу успеваемости и будет извлечена данная запись.
Часто индекс создают на основе комбинации двух или более полей. Например, на рис. 7.3 показана схема индексирования файла успеваемости на основе комбинации полей PN и OCENKA. При такой организации индексов в СУБД можно выполнить запрос на поиск студентов, сдавших физику на 5 на основе однократного просмотра с помощью одного индекса, а, как было показано выше, при использовании пары индексов требуется два отдельных просмотра, тем более, что скорость выполнения запроса может сильно зависеть от последовательности выполнения отдельных просмотров по индексам.
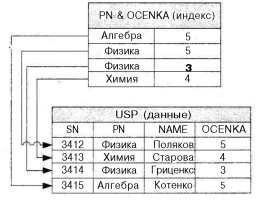
Рис. 7.3. Индексирование файла оценок по комбинации полей PN и OCENKA
Стоит обратить внимание на тот факт, что комбинированный индекс PN&OCENKA может также служить индексом по одному полю PN, т. к. все записи в комбинированном индексе расположены последовательно. Вообще говоря, индекс на основе комбинации полей может использоваться либо для отдельного индексирования по конкретному полю, либо для индексирования на простое натуральное число значения, содержащегося в хеш-поле.
Из этого ясно, что хеширование отличается от индексирования тем, что в файле может быть любое количество индексов, но только одно хеш-поле. Теоретически можно было бы для определения адреса вместо функции использовать непосредственно значение ключевого числового поля, однако практически такой способ непригоден, т. к. диапазон возможных значений ключевого поля может быть гораздо шире диапазона имеющихся адресов.
Таким образом, во избежание неэффективного использования дискового пространства следует найти такую хеш-функцию, чтобы можно было сузить диапазон до оптимальной величины с учетом возможности резервирования дополнительного пространства.
Недостаток хеширования заключается в том, что физическая последовательность записей внутри хранимого файла почти всегда отличается от последовательности ключевого поля, а также любой другой логически заданной последовательности, а между последовательно размещенными записями могут быть промежутки неопределенной протяженности. Практически всегда физическая последовательность записей в хранимом хешированием файле принципиально иная по сравнению с заданной в нем логической последовательностью.
Другим недостатком хеширования является возможность возникновения ситуаций, когда две или более различных записей имеют одинаковые адреса, поэтому иногда возникает необходимость функцию исправлять. Если на одной странице располагается несколько записей, то для исправления можно воспользоваться методом прямого перебора. Суть метода заключается в следующем: предположим, что на пустой странице s размещается n записей. Тогда, при размещении записей и возникновении первых n совпадений по некоторому хеш-адресу s, все такие записи будут размещены на этой странице и найдены при необходимости с помощью прямого перебора. Однако при размещении следующей n+1 записи и возникновении очередного совпадения, запись придется разместить на дополнительной странице переполнения, для чего понадобится дополнительная дисковая операция ввода-вывода.
Необходимо иметь в виду, что с увеличением размера хранимого файла количество совпадений адресов увеличивается, что приводит к значительному увеличению среднего времени доступа - ведь все больше времени придется тратить на поиск информации в наборах конфликтующих записей. Можно устранить, если реорганизовать файл, т.е. загрузить данный файл, используя новую хеш-функцию, что решается при помощи расширяемого хеширования.
При использовании расширяемого хеширования необходимо, чтобы все значения хеш-поля были уникальны, а это может быть реализовано только в том случае, если хеш-поле является ключевым. Основные принципы работы метода расширяемого хеширования следующие:
- если в качестве хеш-функции используется функция f, а значение ключевого поля для некоторой записи z равно р, то в качестве результата хеширования значения ключевого поля будет получено значение псевдоключа для записи z в виде f(р). Здесь псевдоключ используется не в качестве адреса записи, а лишь как косвенный указатель на место их хранения;
- хранимый файл имеет связанный с ним каталог, который также сохраняется на диске. Он состоит из заголовка, содержащего значение g, которое называется глубиной каталога, а также 28 указателей на страницы с несколькими записями данных на каждой.
Таким образом, с помощью каталога глубиной g можно организовать доступ к файлу, содержащему несколько различных страниц с данными.
Если рассматривать первые g бит псевдоключа как целое беззнаковое двоичное число b, то i-й указатель в каталоге будет относиться к странице, содержащей все записи, для которых величина b равна. Для того чтобы найти запись со значением ключевого поля, равным р, следует с помощью хеш-функции вычислить значение псевдоключа, а затем по первым g бит псевдоключа определить численное значение i-1 и найти в каталоге соответствующий ему i-й указатель на страницу, содержащую искомую запись, что реализуется за два доступа к диску.
Здесь был описан лишь один из вариантов хеширования, однако существует множество других способов реализации этой основной идеи.
Для выполнения запросов можно применять другой, не менее эффективный, способ хранения данных с использованием цепочек указателей. При этом, в отличие от индексирования, оба файла могут находиться в одном наборе файлов, причем файл, аналогичный индексному, в данном случае принято называть родительским, а файл с основными данными соответственно дочерним.
Рассмотрим такую структуру (ее часто называют родительско-дочерней) на примере уже рассмотренного выше файла, содержащего данные об успеваемости студентов. Тогда структура будет состоять из файлов успеваемости и учебных предметов, при этом родительский файл будет содержать одну хранимую запись для каждого предмета, предоставляя при необходимости название предмета в качестве заголовка цепочки или кольца указателей, связывающих вместе все дочерние записи об успеваемости студентов по этому предмету (см. рис. 7.4).
Стоит обратить внимание на то, что поле с названиями предметов PN отсутствует в файле успеваемости, т. к. СУБД для поиска студентов в зависимости от сданного предмета будет искать строку с названием предмета в родительском файле, а затем извлекается вся связанная с данной строкой цепочка указателей.

Рис. 7.4. Родительско-дочерняя структура для файла с данными об успеваемости
Основным преимуществом родительско-дочерней структуры является значительно более простое выполнение операций вставки или удаления записей по сравнению с индексной структурой.
Кроме того, родительско-дочерняя структура занимает меньше места на диске, чем соответствующая индексная структура, поскольку в ней не повторяется информация в родительском файле. Однако такая структура имеет и некоторые недостатки. Например, для данного предмета единственным путем доступа к n-му студенту является цепочка с последовательным перебором всех предыдущих записей студентов, а если для этих записей не выполнена кластеризация, то для каждого доступа к данным может потребоваться отдельная операция поиска и время доступа к записи может оказаться очень большим.
С другой стороны, такая структура может быть оптимальной для выполнения запроса на поиск студентов, сдавших тот или иной предмет.