

6.2. Повышение производительности с помощью оптимизации
Проблема оптимизации структуры БД связана с проектированием концептуальной логической схемы данных, однако грамотно построенная БД позволяет повысить производительность всей системы. Другая сторона этой проблемы связана с тем, что некоторые СУБД для нормального функционирования требуют оптимизации.
Многие современные СУБД обладают встроенными системами автоматической оптимизации: в частности, это выражается в том, что конечному пользователю уже не нужно задумываться над оптимальным выражением запросов - в этом случае сама СУБД построит запрос наилучшим образом.
Говоря про оптимизацию запросов в реляционных СУБД, обычно имеют в виду такой способ обработки запросов, когда по начальному представлению запроса, путем его преобразования, вырабатывается некий план его выполнения, наиболее приемлемый при существующих в БД управляющих структурах. Соответствующие преобразования начального представления запроса выполняются специальным компонентом СУБД - оптимизатором, и оптимальность производимого им плана запроса носит условный характер: план оптимален в соответствии с критериями, заложенными в оптимизатор. Можно представить, что обработка поступившего в систему запроса состоит из фаз, изображенных на рис.6.7.
На первом этапе запрос, заданный на языке запросов, подвергается лексическому и синтаксическому анализу. При этом вырабатывается его внутреннее представление, отражающее структуру запроса и содержащее информацию, которая характеризует объекты БД, упомянутые в запросе (отношения, атрибуты и константы). Информация о хранимых в БД объектах выбирается из соответствующих каталогов. Внутреннее представление запроса используется и преобразуется на следующих стадиях обработки запроса, так как форма внутреннего представления должна быть достаточно удобной для последующих оптимизационных преобразований.
На втором этапе запрос во внутреннем представлении подвергается логической оптимизации. Могут применяться различные преобразования, "улучшающие" начальное представление запроса. Среди преобразований могут быть эквивалентные, после проведения которых получается внутреннее представление, семантически эквивалентные начальному, например, приведение запроса к некоторой канонической форме. Преобразования могут быть и семантическими: получаемое представление не является семантически эквивалентным начальному, но гарантируется, что результат выполнения преобразованного запроса совпадает с результатом запроса в начальной форме при соблюдении ограничений целостности, существующих в БД. После выполнения второго этапа обработки запроса его внутреннее представление становится более эффективным, чем начальное.
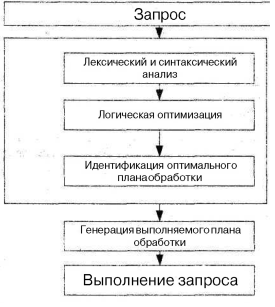
Рис.6.7. Структура обработки запроса в СУБД
Третий этап обработки запроса состоит в том, что реализуется выбор альтернативных процедурных планов выполнения данного запроса в соответствии с его внутреннем представлением на основе информации, которой располагает оптимизатор. При этом для каждого плана оценивается предполагаемая продолжительность и скорость выполнения запроса на основе статистической информации о состоянии БД. Из полученных альтернативных планов выбирается наиболее выгодный, и его внутреннее представление теперь соответствует обрабатываемому запросу.
На четвертом этапе по внутреннему представлению наиболее оптимального плана выполнения запроса формируется выполняемое представление плана. Выполняемое представление плана может быть, например, программой в машинных кодах, или быть машинно-независимым. Однако, стоит заметить, что четвертый этап обработки запроса уже не связана с оптимизацией.
На последнем этапе обработки запроса происходит его реальное выполнение. Это либо выполнение соответствующей подпрограммы, либо вызов интерпретатора с передачей ему для интерпретации выработанного оптимального плана.
В традиционном подходе к организации оптимизаторов запросов на этапе логической оптимизации производятся эквивалентные преобразования внутреннего представления запроса, которые "улучшают" начальное внутреннее представление в соответствии со стратегиями оптимизатора. Характер "улучшений" связан со спецификой общей организации оптимизатора, в частности, с особенностями процедуры поиска возможных процедурных планов запросов, выполняемой на третьем этапе обработки запроса. Именно по этой причине трудно привести полную характеристику и классификацию методов логической оптимизации, поэтому ограничимся несколькими примерами.
Очевидный класс логических преобразований запроса составляют преобразования предикатов, входящих в условие выборки, к каноническому представлению. Имеются в виду предикаты, содержащие операции сравнения простых значений. Такой предикат имеет вид
арифметическое_выражение1 OPERATOR
арифметическое_выражение2
где OPERATOR - некая операция сравнения;
арифметическое_выражение1 и арифметиче-ское_выражение2 - выражения, содержащие имена атрибутов отношений и константы.
Канонические представления могут быть различными для предикатов разных типов. Если предикат включает только одно имя атрибута, то его каноническое представление может, например, иметь вид
имя_атрибута OPERATOR константа
Эта форма предиката очень полезна при выполнении следующего этапа оптимизации.
Если предикат включает два имени атрибутов разных отношений, то его каноническое представление имеет вид
имя_атрибута OPERATOR арифметическое_выражение
где арифметическое_выражение - включает только константы и имя второго атрибута.
И, наконец, для рассматриваемых предикатов более общего вида имеет смысл приведение предиката к каноническому представлению вида
арифметическое_выражение OPERATOR константное_ арифметическое выражение
Здесь выражения в правой и левой части также должны быть приведены к каноническому представлению, например, в выражениях должны быть полностью раскрыты скобки. В дальнейшем можно произвести поиск общих арифметических выражений в разных предикатах запроса. Это оправдано, поскольку при выполнении запроса вычисление арифметических выражений будет производиться при выборке каждого очередного кортежа, т.е. потенциально большое число раз. Кроме того, при приведении предикатов к каноническому представлению желательно вычислять константные выражения и избавляться от логических отрицаний.
Следующий класс логических преобразований связан с приведением к каноническому виду логического выражения, задающего условие выборки запроса. Как правило, используются либо дизъюнктивная, либо конъюнктивная нормальные формы. Выбор канонической формы зависит от общей организации оптимизатора.
При приведении логического условия к каноническому представлению производят поиск общих предикатов и упрощают логическое выражение за счет, например, выявления конъюнкции взаимно противоречащих предикатов. Такие упрощения могут оказаться существенными для дальнейшей обработки запроса, что ускоряет его выполнение.
Необходимо обратить внимание и на тот факт, что в традиционных оптимизаторах распространены логические преобразования, связанные с изменением порядка выполнения реляционных операций. Хотя немногие реляционные системы имеют языки запросов, основанные в чистом виде на реляционной алгебре, правила преобразований алгебраических выражений могут быть полезны и в других случаях. Довольно часто реляционная алгебра используется в качестве основы внутреннего представления запроса, как более универсальное и простое средство. Кроме того, преобразование запроса на SQL к алгебраическому представлению сокращает пространство поиска планов выполнения запроса с гарантией того, что оптимальные планы не будут потеряны.
При этом могут возникнуть проблемы, связанные с приведением запросов с вложенными запросами. Основным отличием языка SQL от языка реляционной алгебры является возможность использовать в логическом условии выборки предикаты, содержащие вложенные подзапросы. Глубина вложенности не ограничивается языком, т.е. может быть произвольной.
В этом случае стремятся к такому преобразованию запроса, содержащего предикаты с вложенными подзапросами, которое сделает структуру подзапроса более явной, предоставив тем самым в дальнейшем оптимизатору возможность выбрать наиболее быстрый способ выполнения запроса.
Поэтому в общем случае каноническим представлением запроса на n отношениях называется запрос, содержащий n-1 предикат соединения и не содержащий предикатов со вложенными подзапросами. Для пояснения этого предлагаем следующий пример, основанный на отношениях, приведенных на рис.6.1:
ВЫБРАТЬ SPO.OCENKA ИЗ SPO ДЛЯ SPO.SN(ВЫБРАТЬ SPP.PN ИЗ SPP ДЛЯ SPP.PN="Физика")
преобразуется в эквивалент
ВЫБРАТЬ SPO.OCENKA ИЗ SPO, SPP ДЛЯ SPO.SN = SPP.PN И SPP.PN="Физика"
Важность таких преобразований обосновывается тем, что оптимизатор получает возможность выбора из большего числа способов выполнения запросов и способы их выполнения более эффективны. При использовании в оптимизаторе запросов подобного подхода не обязательно производить формальные преобразования запросов - оптимизатор должен в большей степени использовать семантику обрабатываемого запроса, а каким образом она будет распознаваться - это вопрос самой СУБД.
Рассмотренные преобразования запросов основывались на семантике языка запросов, но в них не использовалась семантика БД, к которой адресуется запрос. Любое преобразование может быть произведено независимо от того, какая конкретная БД используется. На самом же деле, при каждой истинно реляционной БД хранится и некоторая семантическая информация, например, определяющая целостность данных, что было рассмотрено выше.
Семантическая оптимизация запросов основана на наличии в БД семантической информации, которую не обязательно использовать при обработке запроса, но использование которой может привести к его оптимальному выполнению. Если семантическая оптимизация имеет дело только со знаниями, представленными в виде ограничений целостности БД, то при семантической оптимизации производятся преобразования внутренних представлений запроса, и при каждом преобразовании используется некоторый набор ограничений целостности. Поясним это примером.
Напомним уже рассмотренное выше ограничение целостности для отношения SP, приведенного на рис. 4.1, которое сформулировано как:
СОЗДАТЬ ОГРАНИЧЕНИЕ ЦЕЛОСТНОСТИ RULE ДЛЯ ВСЕХ SP(SP.OCENKA>0 И SP.OCENKA<6)
Если, например, в отношении SP определены эти ограничения целостности и обрабатывается запрос с условием выборки
PN=2101, то есть ВЫБРАТЬ SP.OCENKA ИЗ SP ДЛЯ SP.PN=2101
то в ходе семантической оптимизации будут получены внутренние представления, эквивалентные запросам с условиями, и запрос примет вид:
ВЫБРАТЬ SP.OCENKA ИЗ SP ДЛЯ SP.PN=2101 И (SP.OCENKA>0 И SP.OCENKA<6)
Полученное новое выражение запроса подвергается полной дальнейшей обработке, включая логическую оптимизацию и выбор оптимального плана выполнения; из полученных планов выбирается наиболее дешевый, который и становится реальным планом выполнения исходного запроса. Следует иметь в виду, что после преобразования запроса в соответствии с некоторым правилом к полученному представлению может оказаться применимым другое правило, т. е. возможно появление циклов преобразований. Проблема построения полного набора семантически эквивалентных представлений запроса на основе заданного набора правил в общем случае является весьма сложной. Точное решение этой проблемы может потребовать вычислительных затрат, соизмеримых с затратами на выполнение запроса по наиболее оптимальному плану. Поэтому часто необходимо применение эвристических алгоритмов, сокращающих пространство поиска, т.е. задающих условие прекращения генерации новых представлений.
Таким образом, одной из сторон повышения производительности БД есть оптимизация запросов, выполняемая самой СУБД путем их декомпозиции и преобразования во внутреннее представление в несколько этапов с оценкой скорости выполнения.