

8 3D Face Recognition |
353 |
of the two transforms provided a marginal improvement of around 0.3 % over Haar wavelets alone. If the evaluation was limited to neutral expressions, a reasonable verification scenario, verification rates improved to as high as 99 %. A rank-1 identification rate of 97 % was reported.
8.10.2 Local Feature-Based 3D Face Recognition
Three-dimensional face recognition algorithms that construct a global representation of the face using the full facial area are often termed holistic. Often, such methods are quite sensitive to pose, facial expressions and occlusions. For example, a small change in the pose can alter the depth maps and normal maps of a 3D face. This error will propagate to the feature vector extraction stage (where a feature vector represents a 3D face scan) and subsequently affect matching. For global representation and features to be consistent between multiple 3D face scans of the same identity, the scans must be accurately normalized with respect to pose. We have already discussed some limitations and problems associated with pose normalization in Sect. 8.5.5. Due to the difficulty of accurate localization of fiducial points, pose normalization is never perfect. Even the ICP based pose normalization to a reference 3D face cannot perfectly normalize the pose with high repeatability because dissimilar surfaces have multiple comparable local minima rather than a single, distinctively low global minimum. Another source of error in pose normalization is a consequence of the non-rigid nature of the face. Facial expressions can change the curvatures of a face and displace fiducial points leading to errors in pose correction.
In contrast to holistic approaches, a second category of face recognition algorithms extracts local features [96] from faces and matches them independently. Although local features have been discussed before for the purpose of fiducial point localization and pose correction, in this section we will focus on algorithms that use local features for 3D face matching. In case of pose correction, the local features are chosen such that they are generic to the 3D faces of all identities. However, for face matching, local features may be chosen such that they are unique to every identity.
In feature-based face recognition, the first step is to determine the locations from where to extract the local features. Extracting local features at every point would be computationally expensive. However, detecting a subset of points (i.e. keypoints) over the 3D face can significantly reduce the computation time of the subsequent feature extraction and matching phases. Uniform or arbitrary sparse sampling of the face will result in features that are not unique (or sufficiently descriptive) resulting in sub-optimal recognition performance. Ideally keypoints must be repeatedly detectable at locations on a 3D face where invariant and descriptive features can be extracted. Moreover, the keypoint identification (if required) and features should be robust to noise and pose variations.
354 |
A. Mian and N. Pears |
8.10.2.1 Keypoint Detection and Local Feature Matching
Mian et al. [65] proposed a keypoint detection and local feature extraction algorithm for 3D face recognition. Details of the technique are as follows. The point cloud is first resampled at uniform intervals of 4 mm on the x, y plane. Taking each sample point p as a center, a sphere of radius r is used to crop a local surface from the face. The value of r is chosen as a trade-off between the feature’s descriptiveness and sensitivity to global variations, such as those due to varying facial expression. Larger r will result in more descriptive features at the cost of being more sensitive to global variations and vice-versa.
This local point cloud is then translated to zero mean and a decorrelating rotation is applied using the eigenvectors of its covariance matrix, as described earlier for full face scans in Sect. 8.7.1. Equivalently, we could use SVD on the zero-mean data matrix associated with this local point cloud to determine the eigenvectors, as described in Sect. 8.7.2. The result of these operations is that the local points are aligned along their principal axes and we determine the maximum and minimum coordinate values for the first two of these axes (i.e. the two with the largest eigenvalues). This gives a measure of the spread of the local data over these two principal directions.
We compute the difference in these two principal axes spreads and denote it by δ. If the variation in surface is symmetric as in the case of a plane or a sphere, the value of δ will be close to zero. However, in the case of asymmetric variation of the surface, δ will have a value dependent on the asymmetry. The depth variation is important for the descriptiveness of the feature and the asymmetry is essential for defining a local coordinate basis for the subsequent extraction of local features.
If the value of δ is greater than a threshold t1, p qualifies as a keypoint. If t1 is set to zero, every point will qualify as a keypoint and as t1 is increased, the total number of keypoints will decrease. Only two thresholds are required for keypoint detection namely r and t1 which were empirically chosen as r1 = 20 mm and t1 = 2 mm by Mian et al. [65]. Since the data space is known (i.e. human faces), r and t1 can be chosen easily. Mian et al. [65] demonstrated that this algorithm can detect keypoints with high repeatability on the 3D faces of the same identity. Interestingly, the keypoint locations are different for different individuals providing a coarse classification between different identities right at the keypoint detection stage. This keypoint detection technique is generic and was later extended to other 3D objects as well where the scale of the feature (i.e. r ) was automatically chosen [66].
In PCA-based alignment, there is an inherent two-fold ambiguity. This is resolved by assuming that the faces are roughly upright and the patch is rotated by the smaller of the possible angles to align it with its principal axis. A smooth surface is fitted to the points that have been mapped into a local frame, using the approximation given in [27] for robustness to noise and outliers. The surface is sampled on a uniform 20 × 20 xy lattice. To avoid boundary effects, a larger region is initially cropped using r2 > r for surface fitting using a larger lattice and then only the central 20 × 20 samples covering the r region are used as a feature vector of dimension 400. Note that this feature is essentially a depth map of the local surface defined

8 3D Face Recognition |
355 |
Fig. 8.13 Illustration of a keypoint on a 3D face and its corresponding texture. Figure courtesy of [65]
in the local coordinate basis with the location of the keypoint p as origin and the principal axes as the direction vectors. Figure 8.13 shows a keypoint and its local corresponding feature.
A constant threshold t1 usually results in a different number of keypoints on each 3D face scan. Therefore, an upper limit of 200 is imposed on the total number of local features to prevent bias in the recognition results. To reduce the dimensionality of the features, they are projected to a PCA subspace defined by their most significant eigenvectors. Mian et al. [65] showed that 11 dimensions are sufficient to conserve 99 % of the variance of the features. Thus each face scan is represented by 200 features of dimension 11 each. Local features from the gallery and probe faces are projected to the same 11 dimensional subspace and whitened so that the variation along each dimension is equal. The features are then normalized to unit vectors and the angle between them is used as a matching metric.
For a probe feature, the gallery face feature that forms the minimum angle with it is considered to be its match. Only one-to-one matches are allowed i.e. if a gallery feature matches more than one probe feature, only the one with the minimum angle is considered. Thus gallery faces generally have a different number of matches with a probe face.
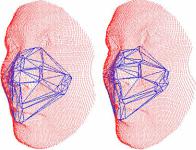
The matched keypoints of the probe face are meshed using Delaunay triangulation and its edges are used to construct a similar 3D mesh from the corresponding keypoints of the gallery face. If the matches are spatially consistent, the two meshes will be similar (see Fig. 8.14). The similarity between the two meshes is given by:
|
= nε |
nε |
| |
− |
| |
|
|
|
γ |
1 |
|
εpi |
|
εgi |
, |
(8.42) |
|
|
|
|
||||||
i
where εpi and εgi are the lengths of the corresponding edges of the probe and gallery meshes, respectively. The value nε is the number of edges. Note that γ is invariant to pose.
A fourth similarity measure between the faces is calculated as the mean Euclidean distance d between the corresponding vertices (keypoints) of the meshes after least squared minimization. The four similarity measures namely the average
356 |
A. Mian and N. Pears |
Fig. 8.14 Graph of feature points matched between two faces. Figure courtesy of [65]
angle between the matching features, the number of matches, γ and d are normalized on a scale of 0 to 1 and combined using a confidence weighted sum rule:
s |
= |
θ |
¯ + |
κ |
m(1 − m) + κγ γ + κd d, |
(8.43) |
|
κ |
θ |
|
|
where κx is the confidence in individual similarity metric defined as a ratio between the best and second best matches of the probe face with the gallery. The gallery face with the minimum value of s is declared as the identity of the probe. The algorithm achieved 96.1 % rank-1 identification rate and 98.6 % verification rate at 0.1 % FAR on the complete FRGC v2 data set. Restricting the evaluation to neutral expression face scans resulted in a verification rate of 99.4 %.
8.10.2.2 Other Local Feature-Based Methods
Another example of local feature based 3D face recognition is that of Chua et al. [21] who extracted point signatures [20] of the rigid parts of the face for expression robust 3D face recognition. A point signature is a one dimensional invariant signature describing the local surface around a point. The signature is extracted by centering a sphere of fixed radius at that point. The intersection of the sphere with the objects surface gives a 3D curve whose orientation can be normalized using its normal and a reference direction. The 3D curve is projected perpendicularly to a plane, fitted to the curve, forming a 2D curve. This projection gives a signed distance profile called the point signature. The starting point of the signature is defined by a vector from the point to where the 3D curve gives the largest positive profile distance. Chua et al. [21] do not provide a detailed experimental analysis of the point signatures for 3D face recognition.
Local features have also been combined with global features to achieve better performance. Xu et al. [90] combined local shape variations with global geometric features to perform 3D face recognition. Finally, Al-Osaimi et al. [4] also combined local and global geometric cues for 3D face recognition. The local features represented local similarities between faces while the global features provided geometric consistency of the spatial organization of the local features.