

Частина 4
.pdf“Курс вищої математики. Частина 4.”
3) При прагненні одного або обох аргументів до мінус нескінченність функція
розподілу прагне до нуля.
F(−∞, y) = F(x,−∞) = F(−∞,−∞) = 0;
4)Функція розподілу є неубутною функцією по кожному аргументу.
5)Ймовірність попадання випадкової крапки (X, Y) в довільний прямокутник із
сторонами, паралельними координатним осям, обчислюється за формулою:
P(a ≤ X ≤ b, c ≤ Y ≤ d) = F(b, d) − F(a, d) − F(b, c) + F(a, c)
Щільність розподілу системи двох випадкових величин.
Визначення. Щільністю сумісного розподілу |
ймовірності двовимірної |
|
випадкової величини (X, Y) називається друга змішана приватна похідна від функції |
||
розподілу. |
|
|
f (x, y) = |
∂2 F(x, y) |
|
∂x∂y |
|
|
|
|
|
Якщо відома щільність розподілу, то функція розподілу може бути легко |
||
знайдена по формулі: |
|
|
y |
x |
|
F(x, y) = ∫ ∫ f (x, y)dxdy |
|
|
−∞−∞
Двовимірна щільність розподілу ненегативна і подвійний інтеграл з нескінченними межами від двовимірної щільності рівний одиниці.
∞∫ ∞∫ f (x, y)dxdy =1
−∞−∞
По відомій щільності сумісного розподілу можна знайти щільність розподілу кожній з складових двовимірної випадкової величини.
f1 (x) = ∞∫ f (x, y)dy; |
f2 ( y) = ∞∫ f (x, y)dx |
−∞ |
−∞ |
x ∞ |
y ∞ |
F1 (x) = F(x, ∞) = ∫ ∫ f (x, y)dxdy ; |
F2 ( y) = F(∞, y) = ∫ ∫ f (x, y)dxdy ; |
−∞−∞ |
−∞−∞ |
Умовні закони розподілу.
Як було показано вище, знаючи сумісний закон розподілу можна легко знайти закони розподілу кожної випадкової величини, що входить в систему.
Проте, на практиці частіше коштує зворотне завдання – по відомих законах розподілу випадкових величин знайти їх сумісний закон розподілу.
У загальному випадку це завдання є нерозв'язним, оскільки закон розподілу випадкової величини нічого не говорить про зв'язок цієї величини з іншими випадковими величинами.
Крім того, якщо випадкові величини залежні між собою, то закон розподілу не може бути виражений через закони розподілу складових, оскільки повинен встановлювати зв'язок складовими.
Все це приводить до необхідності розгляду умовних законів розподілу.
41

“Курс вищої математики. Частина 4.”
Визначення. Розподіл однієї випадкової величини, що входить в систему, знайдене за умови, що інша випадкова величина прийняла певне значення, називається
умовним законом розподілу.
Умовний закон розподілу можна задавати як функцією розподілу так і щільністю розподілу.
Умовна щільність розподілу обчислюється по формулах:
f (x / y) = |
f (x, y) |
= |
|
f (x, y) |
f2 ( y) |
∞ |
|
||
|
|
∫ f (x, y)dx |
||
|
|
|
||
|
f (x, y) |
|
−∞ |
f (x, y) |
f ( y / x) = |
= |
|
||
f1 (x) |
∞ |
|
||
|
|
∫ f (x, y)dy |
||
|
|
|
||
−∞
Умовна щільність розподілу володіє всіма властивостями щільності розподілу однієї випадкової величини.
Умовне математичне очікування.
Визначення. Умовним математичним очікуванням дискретної випадкової величини Y при X = x (х – певне можливе значення Х) називається твір всіх можливих значень Y на їх умовну ймовірність.
m
M (Y / X = x) = ∑yi p( yi / x)
i=1
Для безперервних випадкових величин:
∞
M (Y / X = x) = ∫yf ( y / x)dy ,
−∞
де f(y/x) – умовна щільність випадкової величини Y при X=x.
Умовне математичне очікування M(Y/x)=f(x) є функцією від х і називається
функцією регресії Х на Y.
Приклад. Знайти умовне математичне очікування складової Y
X= x1=1 для дискретної двовимірної випадкової величини, заданою таблицею:
Y |
|
|
X |
|
|
|
x1=1 |
x2=3 |
|
x3=4 |
x4=8 |
y1=3 |
0,15 |
0,06 |
|
0,25 |
0,04 |
y2=6 |
0,30 |
0,10 |
|
0,03 |
0,07 |
p(x1 ) = 0,15 + 0,30 = 0,45
p( y1 / x1 ) = p(x1 , y1 ) / p(x1 ) = 0,15 / 0,45 =1/ 3; p( y2 / x1 ) = p(x1 , y2 ) / p(x1 ) = 0,30 / 0,45 = 2 / 3;
2
M (Y / X = x1 ) = ∑y j p( y j / x1 ) = y1 p( y1 / x1 ) + y2 p( y2 / x1 ) = 2 / 3 +12 / 3 = 5.
j=1
42

“Курс вищої математики. Частина 4.”
Аналогічно визначаються умовна дисперсія і умовні моменти системи випадкових величин.
Залежні і незалежні випадкові величини.
Випадкові величини називаються незалежними, якщо закон розподілу однієї з них не залежить від того яке значення приймає інша випадкова величина.
Поняття залежності випадкових величин є дуже важливим в теорії ймовірності. Умовні розподіли незалежних випадкових величин рівні їх безумовним
розподілам.
Визначимо необхідні і достатні умови незалежності випадкових величин.
Теорема. Для того, щоб випадкові величини Х і Y були незалежні, необхідно і достатньо, щоб функція розподілу системи (X, Y) була рівна твору функцій розподілу складових.
F(x, y) = F1 (x)F2 ( y)
Аналогічну теорему можна сформулювати і для щільності розподілу:
Теорема. Для того, щоб випадкові величини Х і Y були незалежні, необхідно і достатньо, щоб щільність сумісного розподілу системи (X, Y) була рівна твору щільності розподілу складових.
f (x, y) = f1 (x) f2 ( y)
Визначення. Кореляційним моментом xy випадкових величин Х і Y називається математичне очікування твору відхилень цих величин.
µxy = M{[ X − M ( X )][Y − M (Y )]}
Практично використовуються формули:
|
n |
m |
Для дискретних випадкових величин: µxy = ∑∑[xi − M (X )][ y j − M (Y )]p(xi , y j ) |
||
|
i=1 |
j=1 |
|
|
|
Для безперервних випадкових величин: µxy = ∞∫ ∞∫[x − M (X )][ y − M (Y )] f (x, y)dxdy
−∞−∞
Кореляційний момент служить для того, щоб охарактеризувати зв'язок між випадковими величинами. Якщо випадкові величини незалежні, то їх кореляційний момент рівний нулю.
Кореляційний момент має розмірність, рівну твору размерностей випадкових величин Х і Y. Цей факт є недоліком цієї числової характеристики, оскільки при різних одиницях вимірювання виходять різні кореляційні моменти, що утрудняє порівняння кореляційних моментів різних випадкових величин.
Для того, щоб усунути цей недолік застосуються інша характеристика – коефіцієнт кореляції.
Визначення. Коефіцієнтом кореляції rxy випадкових величин Х і Y
називається відношення кореляційного моменту до твору середніх квадратичних відхилень цих величин.
43

“Курс вищої математики. Частина 4.”
r |
= |
µxy |
|
|
|
σ |
σ |
|
|
||
xy |
|
y |
|||
|
|
x |
|
||
|
|
|
|
|
|
Коефіцієнт кореляції є безрозмірним величиною. Коефіцієнт кореляції незалежних випадкових величин рівний нулю.
Властивість: Абсолютна величина кореляційного моменту двох випадкових величин Х і Y не перевищує середнього геометричного їх дисперсій.
µxy ≤  Dx Dy
Dx Dy
Властивість: Абсолютна величина коефіцієнта кореляції не перевищує одиниці.
rxy ≤1
Випадкові величини називаються корельованими, якщо їх кореляційний момент відмінний від нуля, і некорельованими, якщо їх кореляційний момент рівний нулю.
Якщо випадкові величини незалежні, то вони і некорельовані, але з некоррелированности не можна зробити вивід про їх незалежність.
Якщо дві величини залежні, то вони можуть бути як корельованими, так і некорельованими.
Часто по заданій щільності розподілу системи випадкових величин можна визначити залежність або незалежність цих величин.
Разом з коефіцієнтом кореляції ступінь залежності випадкових величин можна охарактеризувати і інший величиною, яка називається коефіцієнтом коваріації. Коефіцієнт коваріації визначається формулою:
k( X ,Y ) = M (XY ) − M (X ) M (Y )
Приклад. Задана щільність розподілу системи випадкових величин Х і Y.
|
f (x, y) = |
1 |
|
|
|
|
|
|
||
|
π2 (x2 + y 2 + x2 y 2 +1) |
|
|
|
|
|
||||
З'ясувати чи є незалежними випадкові величини Х і Y. |
|
|
|
|
|
|||||
Для вирішення цього завдання перетворимо щільність розподілу: |
|
|||||||||
1 |
1 |
|
|
1 |
|
|
1 |
|||
f (x, y) = |
|
= |
|
|
= |
|
|
|
||
π2 (1 + x2 + y 2 (1 + x2 )) |
π2 (1 + x2 )(1 + y 2 ) |
π(1 + x2 ) |
|
π(1 + y 2 ) |
||||||
Таким чином, щільність розподілу вдалося представити у вигляді твору двох функцій, одна з яких залежить тільки від х, а інша – тільки від у. Тобто випадкові величини Х і Y незалежні. Зрозуміло, вони також будуть і некорельовані.
Лінійна регресія.
Розглянемо двовимірну випадкову величину (X, Y), де X і Y – залежні випадкові величини.
Представимо приблизно одну випадкову величину як функцію інший. Точна відповідність неможлива. Вважатимемо, що ця функція лінійна.
Y g(X ) = αX +β
Для визначення цієї функції залишається тільки знайти постійні величини α і β.
44

“Курс вищої математики. Частина 4.”
Визначення. Функція g(X) називається якнайкращим наближенням
випадкової величини Y в сенсі методу найменших квадратів, якщо математичне очікування
M[Y − g( X )]2 приймає найменше можливе значення. Також функція g(x) називається
среднеквадратической регресією Y на X.
Теорема. Лінійна середня квадратична регресія Y на Х обчислюється за формулою:
|
|
|
|
|
g( X ) = my + r |
σy |
(X − mx ) |
|||||
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
σx |
||||
у цій формулі mx=M(X), my=M(Y), |
σx |
= D(X ), σy = D(Y ), r = µxy /(σx σy ) − |
||||||||||
коефіцієнт кореляції величин Х і Y. |
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
||||
Величина |
β = r |
σy |
|
називається коефіцієнтом регресії Y на Х. |
||||||||
σx |
||||||||||||
Пряма, рівняння |
|
|
|
|
|
|
|
|
|
|||
якої |
|
|
|
|
|
|
|
|
||||
|
|
|
|
|
y − my |
= r |
σy |
(x − mx ) , |
|
|||
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
σx |
|
||||
називається прямий сренеквадратической регресії Y на Х. |
||||||||||||
Величина σ2y (1 − r 2 ) називається залишковою дисперсією випадкової величини
Y щодо випадкової величини Х. Ета величина характеризує величину помилки, що утворюється при заміні випадкової величини Y лінійною функцією g(X)=αХ + β.
Видно, що якщо r=1±, то залишкова дисперсія рівна нулю, і, отже, помилка рівна нулю і випадкова величина Y точно представляється лінійною функцією від випадкової величини Х.
Пряма середньоквадратичної регресії Х на Y визначається аналогічно по формулі:
x − mx = r σσx ( y − my )
y
Прямі середньоквадратичної регресії перетинаються в крапці (тх, ту), яку називають центром сумісного розподілу випадкових величин Х і Y.
Лінійна кореляція.
Якщо дві випадкові величини Х і Y мають у відношенні один одного лінійні функції регресії, то говорять, що величини Х і Y зв'язані лінійною кореляційною залежністю.
Теорема. Якщо двовимірна випадкова величина (X, Y) розподілена нормально, то Х і Y зв'язані лінійною кореляційною залежністю.
Закон великих чисел.
Нерівність Чебишева.
(Чебишев Пафнутій Львович (1821 – 1824) – російський математик)
45
“Курс вищої математики. Частина 4.”
На практиці складно сказати яке конкретне значення прийме випадкова величина, проте, при дії великого числа різних чинників поведінка великого числа випадкових величин практично втрачає випадковий характер і стає закономірним.
Цей факт дуже важливий на практиці, оскільки дозволяє передбачати результат досвіду при дії великого числа випадкових чинників.
Проте, це можливо тільки при виконанні деяких умов, які визначаються законом великих чисел. До законів великих чисел відносяться теореми Чебишева (найбільш загальний випадок) і теорема Бернуллі (простий випадок), які будуть розглянуті далі.
Розглянемо дискретну випадкову величину Х (хоча все сказане нижче буде справедливе і для безперервних випадкових величин), задану таблицею розподілу:
X |
x1 |
x2 |
. |
xn |
p |
p1 |
p2 |
. |
pn |
Потрібно визначити ймовірність того, що відхилення значення випадкової величини від її математичного очікування буде не більше, ніж задане число ε.
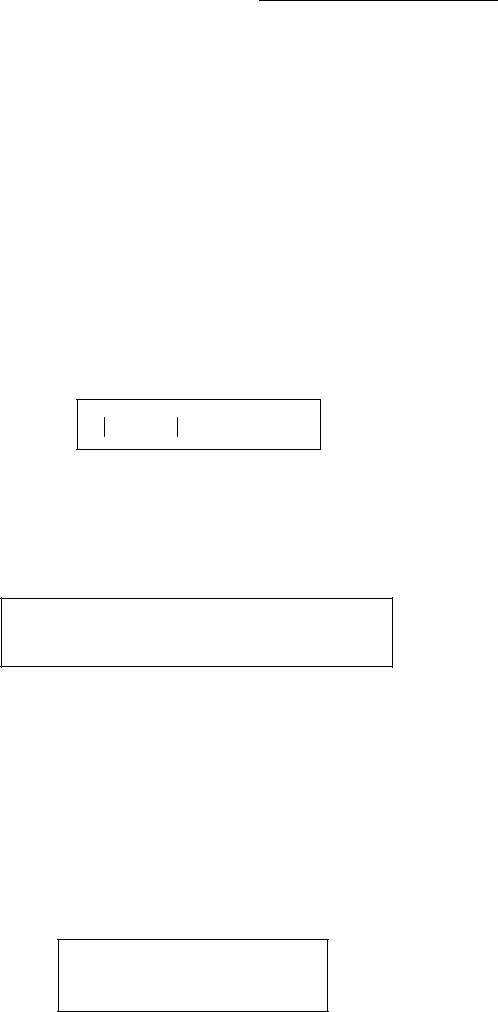
Теорема. (Нерівність Чебишева) Ймовірність того, що відхилення випадкової величини Х від її математичного очікування по абсолютній величині менше
позитивного числа, не менше ніж 1 − D(X ) / ε2 .
P( X − M (X ) < ε) ≥1 − D(X ) / ε2
Доведення цієї теореми приводити не будемо, воно є в
Теорема Чебишева.
Теорема. Якщо Х1, Х2 ., Хnпопарно незалежні випадкові величини, причому дисперсії їх рівномірно обмежені (не перевищую постійного числа З), то, як би мало не було позитивне число, ймовірність нерівності
X |
1 |
+ X |
2 |
+... + X |
n |
− |
M ( X |
1 |
) + M (X |
2 |
) +... + M (X |
n |
) |
< ε |
||
|
|
|
|
|
|
|
|
|
||||||||
|
|
|
|
n |
|
|
|
|
n |
|
|
|
||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
буде скільки завгодно близька до одиниці, якщо число випадкових величин достатньо велике.
Тобто можна записати:
|
|
|
|
X |
1 |
+ X |
2 |
+... + X |
n |
|
M (X |
1 |
) + M (X |
2 |
) +... + M (X |
n |
) |
|
|
|
|
|
|
|
|
|
|||||||||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
lim P |
|
|
|
|
|
|
|
|
− |
|
|
|
|
|
|
|
|
|
< ε |
=1 |
|
|
|
|
|
n |
|
|
|
|
n |
|
|
|
|||||||||
n→∞ |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
ЛЕКЦІЯ 6.
Часто буває, що випадкові величини мають одне і те ж математичне очікування. В цьому випадку теорема Чебишева декілька спрощується:
46

“Курс вищої математики. Частина 4.”
|
|
|
|
X |
1 |
+ X |
2 |
+... + X |
n |
|
|
|
|
|
|
|
|
||||||||||
|
|
|
|
|
|
|
− m |
|
|
=1 |
|||
|
|
|
|
|
|
|
|||||||
lim P |
|
|
|
|
|
|
n |
|
|
< ε |
|||
n→∞ |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||
Дріб, що входить в записаний вище вираз є не що інше як середнє арифметичне можливих значень випадкової величини.
Теорема стверджує, що хоча кожне окреме значення випадкової величини може достатньо сильно відрізнятися від свого математичного очікування, але середнє арифметичне цих значень необмежено наближатиметься до середнього арифметичного математичних очікувань.
Відхиляючись від математичного очікування як в позитивну так і в негативну сторону, від свого математичного очікування, в середньому арифметичному відхилення взаємно скорочуються.
Таким чином, величина середнього арифметичного значень випадкової величини вже втрачає характер випадковості.
Теорема Бернуллі.
Хай проводиться п незалежних випробувань, в кожному з яких ймовірність появи події А рівно р.
Можливо визначити приблизно відносну частоту появи події А.
Теорема. Якщо в кожному з п незалежних випробувань ймовірність р появи події А постійно, то скільки завгодно близька до одиниці ймовірність того, що відхилення відносної частоти від ймовірності р по абсолютній величині буде скільки завгодно малим, якщо число випробувань р достатньо велике.
lim P( m / n − p < ε) =1
n→∞
Тут т – число появ події А. Із всього сказаного вище не витікає, що із збільшенням число випробувань відносна частота неухильно прагне до ймовірності р,
тобто lim |
m |
= p . У теоремі мається на увазі lim |
m |
= p тільки ймовірність наближення |
|
|
|||
n→∞ n |
n→∞ n |
|
||
відносної частоти до ймовірності появи події А в кожному випробуванні.
У випадку, якщо ймовірність появи події А в кожному досвіді різні, то справедлива наступна теорема, відома як теорема Пуассона.
Теорема. Якщо проводиться п незалежних дослідів і ймовірність появи події А в кожному досвіді рівна рi, то при збільшенні п частота події А сходиться по ймовірності до середнього арифметичного ймовірності рi.
Граничні теореми.
Як вже мовилося, при достатньо великій кількості випробувань, поставлених в однакових умовах, характеристики випадкових подій і випадкових величин стають майже невипадковими. Це дозволяє використовувати результати спостережень випадкових подій для прогнозу результату того або іншого досвіду.
Граничні теореми теорії ймовірності встановлюють відповідність між теоретичними і експериментальними характеристиками випадкових величин при великій кількості випробувань.
У розглянутому вище законі великих чисел нічого не мовилося про закон розподілу випадкових величин.
47

“Курс вищої математики. Частина 4.”
Поставимо завдання знаходження граничного закону розподілу суми
n
Yn = ∑X i
i=1
коли число доданків п необмежено зростає. Цю задачу вирішує, яка була сформульована вище.
Залежно від умов розподілу випадкових величин Xi, створюючих суму, можливі різні формулювання центральної граничної теореми.
Допустимо, що випадкові величини Xi взаємно незалежні і однаково розподілені.
Теорема. Якщо випадкові величини Xi взаємно незалежні і мають один і той же закон розподілу з математичним очікуванням т і дисперсією 2, причому існує третий абсолютный момент ν3, то при необмеженому збільшенні числа випробувань п закон
n
розподілу суми Yn = ∑X i необмежено наближається до нормального.
i=1
При доведенні цієї теореми Ляпуновим використовувалися так звані
характеристичні функції. |
|
Визначення. Характеристичною функцією |
випадкової величини Х |
називається функція |
|
g(t) = M (eitX ) |
|
ця функція є математичним очікуванням деякої комплексної випадкової величиниU = eitX , функцією, що є, від випадкової величини Х. При вирішенні багатьох завдань зручніше користуватися характеристичними функціями, а не законами розподілу.
Знаючи закон розподілу, можна знайти характеристичну функцію по формулі (для безперервних випадкових величин):
g(t) = ∞∫eitx f (x)dx
−∞
Як видимий, дана формула є не що інше, як преобразование Фурье для функції щільності розподілу. Очевидно, що за допомогою зворотного перетворення Фурье можна по характеристичній функції знайти закон розподілу.
Введення характеристичних функцій дозволяє спростити операції з числовими характеристиками випадкових величин.
У разі нормального розподілу характеристична функція має вигляд: g(t) = e−t 2 / 2
Сформулюємо деякі властивості характеристичних функцій:
1) Якщо випадкові величини Х і Y зв'язані співвідношенням
Y = aX
де а – невипадковий множник, то
g y (t) = g x (at)
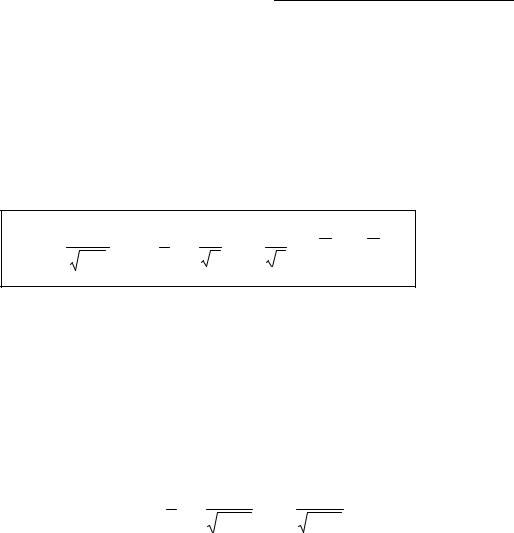
2) Характеристична функція суми незалежних випадкових величин рівна твору характеристичних функцій доданків.
48
“Курс вищої математики. Частина 4.”
Випадкові величини Xi, розглянуті в центральній граничній теоремі, можуть володіти довільними розподілами ймовірності.
Якщо всі ці випадкові величини однаково розподілені, дискретні і приймають тільки два можливі значення 0 або 1, то виходить простий випадок центральної граничної теореми, відомий як теорема Муавра, – Лапласа.
Теорема. (Теорема Муавра – Лапласа) Якщо проводиться п незалежних дослідів, в кожному з яких подія А з'являється з ймовірністю р, то для будь-якого інтервалу (α, β) справедливе співвідношення:
|
|
Y − np |
|
|
|
1 |
|
|
β |
|
α |
|
|
|
|
|
|
|
|
||||||||
P |
α < |
npq |
< β |
|
= |
2 |
Φ |
|
−Φ |
2 |
|
= Φ(β) − Φ(α) |
|
|
|
|
|
|
|
|
2 |
|
|
|
|||
де Y – число появ події А в п дослідах, q = 1 – p, Ф(х) –, - нормированная функция Лапласа .
Теорема Муавра – Лапласа описує поведінку биноминального распределения при великих значеннях п.
Дана теорема дозволяє істотно спростити обчислення за формулою біномінального розподілу.
Розрахунок ймовірності попадання значення випадкової величини в заданий
інтервал P(α < Y < β) = ∑Cnk pk qn−k |
|
при |
великих |
значеннях п украй скрутний. |
||||
α<k <β |
|
|
|
|
|
|
|
|
Набагато простіше скористатися формулою: |
|
|
|
|
||||
P(α < Y < β) = |
1 |
|
|
β− np |
|
|
α − np |
|
2 |
Φ |
|
|
−Φ |
|
|||
|
|
|
|
2npq |
|
|
2npq |
|
|
|
|
|
|
|
|
|
|
Теорема Муавра – Лапласа дуже широко застосовується при вирішенні практичних завдань.
Приклад. Ймовірність настання події А в кожному випробуванні рівна 0,3. Використовуючи нерівність Чебишева, оцінити ймовірність того, що в 10000 випробуваннях відхилення відносної частоти появи події А від його ймовірності не перевершить по абсолютній величині 0,01.
Відповідно до нерівності ймовірність Чебишева того, що відхилення випадкової величини від її математичного очікування буде менше деякого числаε, обмежена
відповідно до нерівності P( |
|
X − mx |
|
< ε) ≥1 − |
Dx |
. |
|
|
|
||||||
|
|||||||
|
|
|
|
|
ε2 |
||
|
|
|
|
|
|||
Треба визначити математичне очікування і дисперсію числа появи події А при одному досвіді. Для події А випадкова величина може приймати одне з двох значень: 1- події з'явилася, 0- події не з'явилася. При цьому ймовірність значення 1 рівна ймовірності р=0,3, а ймовірність значення 0- рівна ймовірності ненастання події А
q=1 – p =0,7.
За визначенням математичного очікування маємо: mx = 0 q +1 p = p = 0,3
Дисперсія: Dx = (0 − p)2 q + (1 − p)2 p = pq = 0,3 0,7 = 0,21
49
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
“Курс вищої математики. Частина 4.” |
||
|
|
У разі п незалежних випробувань отримуємо mx = np; Dx = npq; Ці формули |
|||||||||||||||||
вже згадувалися выше. |
|
|
|
|
|
|
|||||||||||||
|
|
У нашому випадку отримуємо: mx = 3000; |
|
Dx = 2100; |
|||||||||||||||
|
|
Ймовірність відхилення відносної частоти появи події А в п випробуваннях від |
|||||||||||||||||
ймовірності на величину, що не перевищує ε=0,01 рівна: |
|||||||||||||||||||
|
|
|
|
|
m |
|
|
|
|
|
|
|
|
|
|
|
|
||
|
|
|
|
|
|
|
|
|
|
|
|||||||||
|
|
P |
|
|
|
− p |
< ε = P( |
m − np |
< nε) = P( |
m − m |
x |
< nε) = P( |
m −3000 |
<100) |
|||||
|
|
|
|||||||||||||||||
|
|
|
|
|
n |
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|||
|
|
|
|
|
|
|
|
|
|
|
|||||||||
|
|
Вираз отриманий в результаті цих простих перетворень є не що інше, як |
|||||||||||||||||
ймовірність |
відхилення числа т появи події |
А |
від математичного очікування на |
||||||||||||||||
величину не більшу, ніж δ=100. |
|
|
|
|
|
|
|||||||||||||
|
Dx |
Відповідно до нерівності Чебишева ця ймовірність буде не менша, ніж величина |
|||||||||||||||||
1 − |
=1 − |
|
|
|
|
2100 |
|
=1 −0,21 = 0,79. |
|
|
|
|
|
|
|||||
δ2 |
10000 |
|
|
|
|
|
|
|
|||||||||||
|
|
|
|
|
|
|
|
|
|
|
|
|
|||||||
Приклад. Скільки слід перевірити деталей, щоб з ймовірністю, не меншою 0,96, можна було чекати, що абсолютна величина відхилення відносної частоти придатних деталей від ймовірності деталі бути придатною, рівною 0,98, не перевищить 0,02.
Умова завдання фактично означає, що виконується нерівність:
|
|
|
n |
|
|
|
|
|
|||||
P |
|
|
|
−0,98 |
|
≤ 0,02 ≥ 0,96 |
|
||||||
|
|
|
m |
|
|
|
|
|
|
|
|
|
|
|
|
Тут п- число придатних деталей, т- число перевірених деталей. Для застосування нерівності Чебишева перетворимо отриманий вираз:
P( |
|
n −0,98m |
|
≤ 0,02m) ≥1 − |
Dx |
≥ 0,96 |
|
|
|||||
|
|
(0,02m)2 |
||||
|
|
|
|
|
|
Після домножения виразу, що стоїть в дужках, на т отримуємо ймовірність відхилення по модулю кількості придатних деталей від свого математичного очікування, отже, можна застосувати нерівність Чебишева, тобто ця ймовірність
повинна бути не менше, ніж величина1 − |
Dx |
, а по умові завдання ще і не менше, |
|||
(0,02m)2 |
|||||
ніж 0,96. |
|
|
Dx |
|
|
Таким чином, отримуємо нерівність 0,96 ≤1 − |
. Як вже мовилося в |
||||
(0,02m)2 |
|||||
попередньому завданні, дисперсія може бути знайдена по формулі Dx = mpq . Разом, отримуємо:
m ≥ |
0,98 0,02 |
; |
m ≥1225 |
|
0,04 0,0004 |
||||
|
|
|
Тобто для виконання необхідних умов необхідно не менше 1225 деталей.
Приклад. Добова потреба електроенергії в населеному пункті є випадковою величиною, математичне очікування якої рівне 3000 кВт/час, а дисперсія складає 2500. Оцінити ймовірність того, що в найближчу добу витрата електроенергії в цьому населеному пункті буде від 2500 до 3500 кВт/час.
Потрібно знайти ймовірність попадання випадкової величини в заданий інтервал:
P(2500 ≤ X ≤ 3500) = ?
50