

УДК 004.93
ОСОБЕННОСТИ ПОСТРОЕНИЯ НЕЙРОСЕТЕВЫХ АЛГОРИТМОВ В ЗАДАЧАХ РАСПОЗНАВАНИЯ ОБРАЗОВ
Чобан А. Г.
студент группы КЗИ-161 Омского государственного технического университета, г. Омск
Стадников Д.Г.
студент группы КЗИ-161 Омского государственного технического университета, г. Омск
.
СибАДИИниватов Д.П
студент группы БИТ-151 Омского государственного технического университета, г. Омск
Сулавко А.Е.
канд. техн. наук, доцент кафедры «Комплексная защита информации» Омского государственного технического университета, г. Омск
Аннотац я. В статье оп саны и о о щены существующие алгоритмы, применяемые для интеллектуального анал за данных с применением искусственных нейронных сетей (ИНС). Рассматр ваются класс ческ е архитектуры, алгоритмы обучения, а также способы и возможности х пр менен я в задачах распознавания образов.
Ключевые слова: нейросетевые алгоритмы, распознавание образов.
Введение
Искусственные нейронные сети (ИНС) рассматривают как математические конструкции, вдохновленные исследованиями человеческого мозга, фундаментальные идеи построения которых были заимствованы из нейро иологии. На практике же искусственные нейронные сети имеют мало общего с механизмами ра оты человеческого мозга, так как принципы их работы сильно упрощены. Несмотря на это ИНС позволяют решать широкий круг задач достаточно трудных для выполнения классическими алгоритмами. К таким задачам относятся: сегментация и классификация объектов на изображениях, обработка естественного языка, распознавания речи, сжатие данных, прогнозирование вероятности возникновения событий, улучшение качества машинного перевода, прогнозирование событий, порождение новых осмысленных изображений (пейзажей, изображений людей и животных), создание искусственного интеллекта для игры в настольные и видеоигры, машинный синтез речи, неотличимой от человеческой и многое другое.
Общие черты нейронных сетей
Несмотря на разнообразие задач, с решением которых нейронные сети справляются лучше других алгоритмов, невозможно подобрать универсальную сеть, которая справлялась бы одинаково хорошо со всеми задачами. хотя на сегодняшний день известно большое количество различных архитектур ИНС, в основе структуры каждой из них лежит математическая модель нейрона (структурной клетки нервной системы человека).
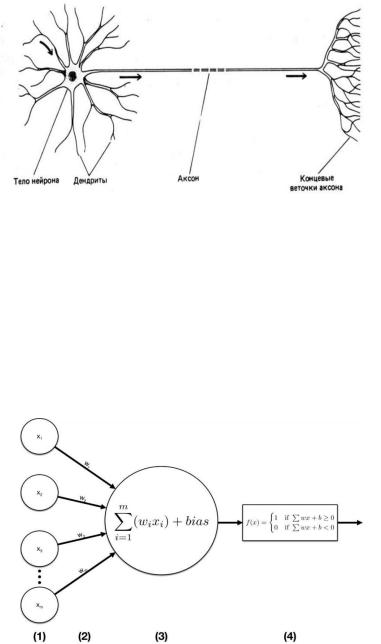
Биологический нейрон (рис. 1) состоит из множества коротких отростков - дендритов, по которым электрические сигналы поступают в нейрон, и одного длинного отростка - аксона, по которому электрические сигналы передаются другим нейронам. Связи между дендритами и аксонами называются синапсами и имеют сложную структуру. Они устроены таким образом, что один и тот же электрический сигнал возбуждает различные нейроны с разной силой.
127
СибАДИнелинейные зависимости в данных разделять линейно неразделимые классы. Чтобы сделать модель нелинейной, необходимо на выходе персептрона ввести нелинейную функцию активации.
Р сунок 1 – Биологический нейрон
Модель скусственного нейрона (персептрона) (рис 2) была предложена Фрэнком Розенблатом [8,9] представляет собой линейную модель классификации. Где в роли дендритов выступают входы персептрона. В роли синапсов – весовые коэффициенты w, соответствующ е каждому входу. В качестве входных данных может выступать вектор
вещественных ч сел x = (x1, x2, …, xn), и для каждого входа тренировочное множество содержит метку выхода y = {-1, 1}. Таким образом, подбирая весовые коэффициенты, так чтобы каждому входу x з тренировочного множества, соответствовал правильный y,
персептрон решает задачу |
нарной классификации. И задача состоит в том, чтобы |
научиться расставлять метки у ранее не виденных объектов. |
|
|
Рисунок 2 – Персептрон |
Классическая модель линейного персептрона не может использоваться в современных сетях, так как для различных задач регрессии и классификации необходимо искать
Функции активации
Одним из основных и первостепенных аспектов в проектировании искусственных нейронных сетей является выбор функции активации f. Основная задача функции активации - это нормализация данных, т.е. представление входных данных в необходимом диапазоне. В настоящее время существует достаточно большое число различных функций активации, например, сигмоидальная функция (далее сигмоид), гиперболический тангенс, функция Хевисайда, ReLU и многие другие.
Исторически сложилось, что сигмоид является одной из классических и наиболее распространенных функций активации. Сигмоид является монотонно возрастающей,
128

ограниченной и дифференцируемой S-образной функцией, которая стремится к нулю при х→ −∞ и к единице при х→ ∞. Задается сигмоид следующей формулой:
1 ( ) = 1+
Другой, похожей по своим свойствам на сигмоид, функцией является гиперболический тангенс:
СибАДИ |
|||
( ) = tanh( ) = |
|
. |
|
В сравнен с с гмо дом гиперболический тангенс |
быстрее приближается к своим |
||
пределам, а также стрем тся к −1 при х→ −∞ и к 1 при х→ ∞. Наиболее целесообразно использовать данную функц ю в тех случаях, когда есть необходимость получать на выходе значения разных знаков т.к. с гмоид имеет строго положительный выход.
уществует на более простой вид функции активации – функция Хевисайда, она же
ступенчатая функц |
я: |
0, < 0. |
|
|
|
|
( ) = |
|
|
Данная функц |
я |
спользовалась в ранних архитектурах1, ≥ 0 |
искусственных нейронных сетей. |
|
Выход нейрона |
у такой функции принимает всего два значения: 0, если вход меньше |
|||
определенного порога 1, если ольше. Недостатком данной функции является то, что она не может разделять линейно неразделимые классы, поэтому подходит лишь для решения NP- полных задач.
Наиболее современной и широко используемой функцией активации является ReLU (Rectified linear units), а также её модификации: LReLU(Leaky ReLU) [4], PReLU(Parametric ReLU) [5], ELU (Exponential Linear Unit) [7]. ReLU является кусочно-линейной функцией
активации: |
) = |
0, |
< 0. |
|
( |
|
|||
Нейроны, использующие ReLU в |
качестве, |
≥функции0 |
активации, являются более |
|
эффективными, чем основанные на логистическом сигмоиде и гиперболическом тангенсе. Так, например, сети на ReLU-нейронах при одних и тех же вычислительных ресурсах системы обучаются гораздо быстрее могут быть гораздо больше, чем сети, использующие сигмоид или гиперболический тангенс, поскольку производная данной функции равна либо 0, либо 1 в зависимости от знака входа, что существенно ускоряет процесс обучения. Стоит отметить то, что ReLU нашла своё применение еще в начале 1980-ых годов в работах Кунихико Фокусимы [2, 3].
Существуют и другие варианты функций активации, которые находят свое применение в различных областях и исследованиях. В таблице 1 представлены некоторые из них.
129

Таблица 1- Функции активации
|
Название функции |
|
Формула f (x) |
|
||||||||
|
Логистический сигмоид |
|
( ) |
|
|
1 |
|
|
|
|
|
|
|
Гиперболический тангенс |
|
= 1+ |
|
|
−1 |
|
|
||||
|
|
|
|
|
|
|
|
|||||
|
Функция Хевисайда |
( ) = tanh( ) = |
+1 |
|
|
|||||||
|
|
|
|
|||||||||
|
СибА |
|
|
|
0, |
|
|
< 0 |
|
|
||
|
ДИ |
|
||||||||||
|
ReLU |
( |
) |
= |
1, |
|
|
≥ 0 |
|
|||
|
|
( |
) = |
, |
|
|
< 0 |
|
|
|||
|
LReLU, PReLU |
, |
|
|
< 0 |
|
|
|||||
|
, |
|
|
≥ 0 |
|
|||||||
|
ELU |
( |
) = |
, |
|
|
≥ 0 |
|
||||
|
|
( ) = |
( |
|
− 1, |
< 0 |
|
|||||
|
SoftPlus |
( ) = |
, |
|
|
|
|
≥ 0 |
|
|||
|
SoftSign |
1 |
(1+ |
) |
|
|
||||||
|
|
|
|
1+ | | |
|
|
|
|
|
|||
Обучен е нейронной сети
Обучен е скусственной нейронной сети сводится к подбору коэффициентов синапсов. От этого шага во многом зависит эффективность ИНС и качество выполнения поставленных для неё задач. Существует несколько видов обучения: обучение с учителем (supervised learning), обучение без учителя (unsupervised learning) и обучение с частичным привлечением учителя (semi-supervised learning). В зависимости от того, для каких целей проектируется ИНС, используется тот или иной метод.
При обучении с учителем ИНС обучается на так называемом тренировочном наборе (выборке) данных. Выборка состоит из полностью размеченных данных - это означает то, что в соответствии каждому примеру выборки соответствует правильный ответ, который ИНС должна получить на выходе. Данный метод обычно делиться на две задачи: классификации и регрессии. В задаче классификации качество алгоритма зависит от того, насколько точно он сможет отнести новые данные соответствующим классам. Например, Зо Зо Тун и С. А. Филист в работе [1] классифицируют кардиоциклы кардиосигналов с помощью ИНС на основе радиальных базисных функций, при этом точность спроектированной ими ИНС достигает 99%. В задачи регрессии входит предсказание значения переменной некоторой функции, которая может принимать бесконечное количество различных значений. Например, сделать прогноз погоды на основе показаний анемометра датчика давления, а также других параметров.
Однако, часто возникают проблемы, связанные с недостатком большого количества достоверных данных для обучения и тестирования ИНС. В таких случаях применяется метод обучения без учителя. Данный метод также решает ряд задач, к которому можно отнести кластеризацию, снижение размерности и оценку плотности. Задача кластеризации основывается на обучении ИНС таким образом, чтобы она разбила заранее неизвестные, ей данные так, чтобы точки одного класса были как можно ближе друг другу и как можно дальше от точек остальных классов. Другая нередко встречающаяся задача обучения без учителя - снижение размерности, возникает в тех случаях, когда данные большой размерности необходимо “сжать” так, чтобы полученное представление данных, имея меньшую размерность, достаточно полно отражало исходные. Задача оценки плотности является наиболее общей из всех, представленных ранее. Например, необходимо оценить
130
распределение p (x) данных нам точек {x1 ..., xn} и, возможно, каких-то априорных представлений о том, откуда они взялись.
Существует также метод обучения ИНС с частичным привлечением учителя. Поскольку часто возникает ситуация, когда возможность получить большое количество размеченных данных отсутствует, а неразмеченные данные найти очень легко. Так, например, вручную разметить достаточно большое количество сканов компьютерной томографии весьма трудоемкая и дорогостоящая задача, а неразмеченных сканов можно собрать сколь угодно много.
Архитектуры нейронных сетей
Классическ е арх тектуры.
Полносвязные нейронные сети являются логическим продолжением идеи персептрона Розенблата, х часто называют многослойными персептронами. Термин «полносвязная» означает, что каждый нейрон n-го слоя связан с каждым нейроном (n+1) слоя.
Математически операц я прямого |
распространения |
данных |
для |
одного нейрона |
||||
описывается следующ м о разом: |
yi = f(wi×x), где wi – вектор весов нейрона, x – вектор |
|||||||
входных данных, f – функц я активации нейрона. Тогда вычисления нейронов одного слоя |
||||||||
можно представ ть матр чным произведением: |
|
|
|
|
||||
= ( × ) = |
( |
|
) |
, где = |
= |
|
. |
|
( |
) |
|
|
|||||
Сверточные нейронные сети (СНС) (рис. 3) – класс архитектур, основной задачей которых изначально была обработка изо ражений. В этой области СНС смогли добиться больших результатов вследствие того, что они устроены наподобие зрительной коры головного мозга. Данное качество спосо ствует умению концентрироваться на определённой области и выделять необходимые осо енности. Сейчас же применение данной архитектуры выходит за рамки анализа изображений. В свёрточной сети выходы промежуточных слоев образуют между собой матрицу или набор матриц, основными использующимися в свёрточных нейронных сетях слоями являются свёрточные, полносвязные пулинговые. В случае, если в слое происходит r свёрток, вход имеет размерность w*h, ядро размерности соответствует
, то размерность выхода будет определяться следующей формулой:
( − +1) ( − +1).
Также в некоторых случаях использования свёрточного слоя бывает с добавлением сдвига
(s) отличного от единицы, при этом подразумевается, что применение операции будет осуществлено подряд не для каждого пикселя. В таком случае размерность выхода при всех
аналогичных предыдущих значениях будет выглядеть следующим образом: |
|
СибАДИ |
|
|
+1 ( +1). |
131
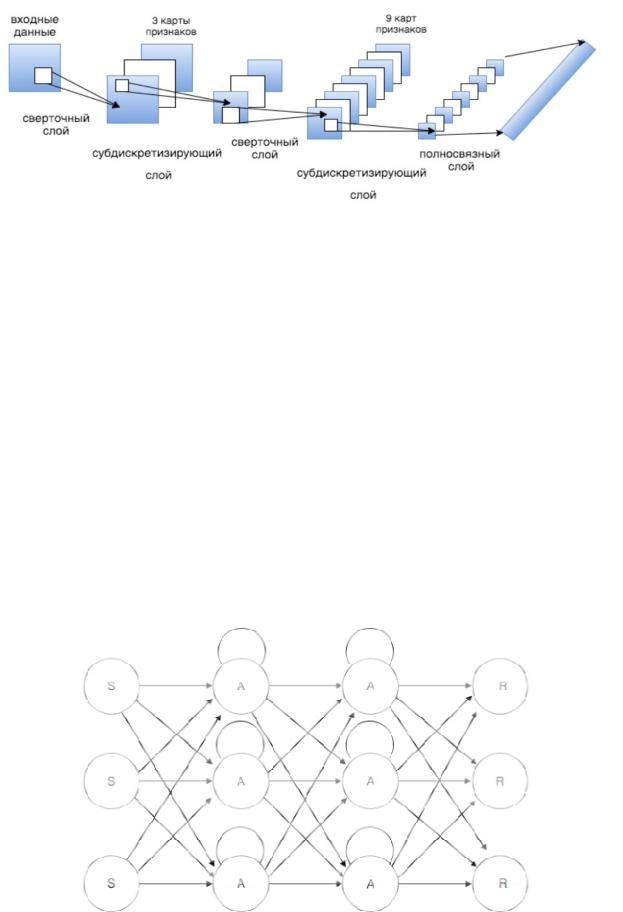
СибАДИРекуррентной нейронной сетью (РНС) называют такую модель сетей, в которой нейроны могут иметь связь не только друг к другу, но и к самим себе, то есть к предыдущему значению нейрона. В данной структуре значение каждого элемента вычисляется не только посредством других, но и может ыть зависимо от предыдущего своего веса. Таким образом, образуются некие циклы в сетевой топологии. Данное очень важное свойство помогает в решении задачи использования контекста при обработке текстовых последовательностей, так как другие топологии не могут учитывать значения предыдущих элементов при синтаксическом разборе. Это свойство идеально подходит для анализа текста, перевода, распознавания речи, прогнозирования кадров на основе предыдущих, прогнозировании пикселя на основе окружающий его пикселей т.д.
Р сунок 3 – Пример архитектуры СНН
Автокод ровщ ком называется нейронная сеть прямого распространения, которая предназначена для восстановления на выходе входного сигнала. Автокодировщики состоят из двух частей: энкодера f декодера g и конструируются таким способом, чтобы точно скопировать входной с гнал выдать его на выходе было невозможно. Энкодер переводит
входной с гнал в своё внутреннее представление h |
|
, а декодер восстанавливает |
||
данный сигнал |
|
. Задачей же всей этой системы является изменять функции f и g |
||
|
|
|
( = |
( )) |
таким образом, чтобы выуч ть тождественную функцию: |
|
|||
|
( = |
( )) |
|
|
|
|
= ( ( )). |
|
|
Рисунок 4 – Архитектура РНС
132
Заключение
В ходе своей истории человек не случайно прибегнул к использованию искусственных нейронных сетей – развитие технологий и процессорных мощностей дали возможность реализовать различные идеи человечества, накопленные в ходе десятков и сотен лет с помощью создания устройства, способного обучаться по принципу живого существа. уществующее многообразие архитектур объясняется необходимостью применения искусственного интеллекта к непохожим друг на друга задачам. И с течением времени размах этих решаемых задач и их качество посредством ИНС будет только увеличиваться.
СибАДИ |
|
Благодарности |
|
Работа выполнена при ф нансовой поддержке РФФИ (грант № 18-37-00399). |
|
|
Библиографический список |
1. |
Зо Зо Тун, С.А. Ф л ст, Искусственная нейронная сеть на основе радиальных |
базисных функц й для класс ф кации кардиоциклов электрокардиосигналов. / Зо Зо Тун, |
|
. . Филист //Извест я ЮФУ. Технические науки. – 2010. –№8. – 80-85 с. |
|
2. |
Fukushima K. Neural Network Model for a Mechanism of Pattern Recognition Unaffected |
by Shift in Position – Neocognitron // Transactions of the IECE, 1979, vol. J62-A (10). P. 658–665. |
|
3. |
Fukushima K. Neocognitron: A Self-Organizing Neural Network for a Mechanism of |
Pattern Recognition Unaffected by Shift in Position // Biological Cybernetics, 1980, vol. 36, no. 4.
– P. 193–202.
4. Maas A.L., Hannun A.Y., Ng A.Y. Rectifier Nonlinearities Improve Neural Network Acoustic Models // Proc. 29th ICML, 2013, vol. 30, no. 1.
5. Deep Residual Learning for Image Recognition / K. He et al. // Proc. 2016 CVPR, 2016. – P. 770–778.
6. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification / K. He et al. // Proc. ICCV 2015, 2015. — P. 1026–1034.
7. Clevert D., Unterthiner T., Hochreiter S. Fast and Accurate Deep Network Learning by Exponential Linear Units (ELUs) // arXiv, 2015. http://arxiv.org/abs/1511.07289.
8. Rosenblatt F. The Perceptron: A Probabilistic Model for Information Storage and Organization in the Brain // Psychological Review, 1958, vol. 65, no. 6. — P. 386–408.
9. Rosenblatt F. Principles of Neurodynamics, Spartan, New York, 1962.
133