

6.3 Кластерні процедури класифікації
Формування однорідних одиниць сукупності у багатовимірному просторі важко уявити без такого методу аналізу як кластерний. Це пов’язано з тим, що за його допомогою можна побудувати науково обґрунтовані класифікації об’єктів з одночасним врахуванням всіх групувальних ознак. Особливої уваги кластерний аналіз заслуговує ще й тоді, коли є потреба дослідити певне явище в регіональному розрізі, тобто згрупувати регіони за заданими ознаками.
Кластерному аналізу свої праці присвятили чимало вчених, найбільш відомими серед них можна н1азвати Сокала Р., Сніта П., Дюрана Б., Оделла П., Айвазяна С. А., Мхітаряна В. С., Плюту В., Жамбю, Болла Г., Холла Д., Мак-Куїна Дж., Тамашевича В., Сошникову Л., Єріну А. М., Манделя І.
Сьогодні існує чимало прикладних програм для швидкої та неклопіткої побудови кластерної моделі, зокрема, прикладний пакет «Statistica» та його модуль «Cluster analysis».
Слово «кластер» походить від англійського «cluster», що в перекладі означає гроно, скупчення, пучок.
У 1939 р. Р. Тріоном було запропоновано вжити термін «кластерний аналіз».
В основу кластерного аналізу Р. Сокалом та Дж. Снітом покладено так званий політетичний підхід. На противагу монотетичному підходу, його сутність полягає в тому, що одночасно враховуються всі групувальні ознаки під розбиття сукупності на групи.
Кластерний аналіз являє собою спосіб групування багатовимірних об’єктів. В основу кластерного аналізу покладено представлення результатів спостереження за допомогою точок відповідного геометричного простору та подальшого виділення груп у вигляді «згустків» цих точок.
Основні завдання кластерного аналізу можна звести до:
виділення однорідних груп із початкових багатовимірних даних таким чином, щоб об’єкти, які належать одній групі, були схожі між собою, а ті, що відносяться до різних груп – відмінні;
побудови науково обґрунтованих класифікацій;
виявлення внутрішнього зв’язку серед одиниць сукупності;
скорочення інформації через виявлення діагностичних ознак, тобто ознак, які мають найсуттєвіші особливості серед чисельних початкових ознак.
Нехай є множина I = (I1, I2,….,In), яку характеризує n об’єктів, а також множина ознак С = (С1,С2,…,Сm)Т, які притаманні кожному об’єкту з множини I. Тоді результатом вимірювання і-ї ознаки Ij об’єкта буде xij, і=1,2,…m; j=1,2,…n. Підсумовуючи сказане, маємо: для множини об’єктів I є множина векторів X= (X1, X2,…,Xm), які характеризують множину I. Слід зазначити, що множину Х можна відобразити у вигляді n точок у m- вимірному просторі (Еm).
У матричному вигляді можна записати так.
На
основі матриці початкових даних розміром
n![]() m:
m:
Х =
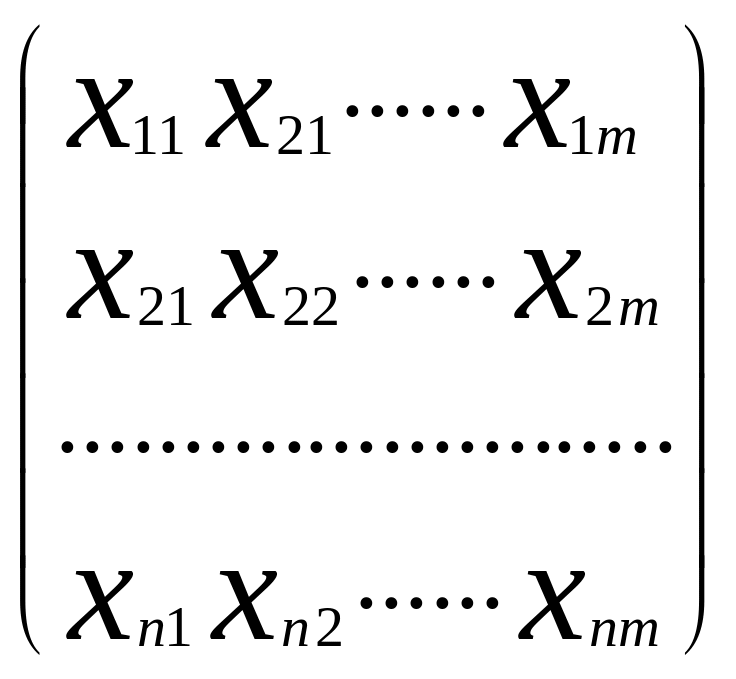 = (Х1, Х2,…Хm),
= (Х1, Х2,…Хm),
де
![]() -
значення і-ї
ознаки для j-ї
одиниці сукупності;
-
значення і-ї
ознаки для j-ї
одиниці сукупності;
і = 1,2,……m;
j = 1,2,……n;
m – кількість ознак;
n – кількість одиниць сукупності
потрібно розрахувати нормовані значення ознак та побудувати матрицю нормованих значень Z розміром n m:
Z
=
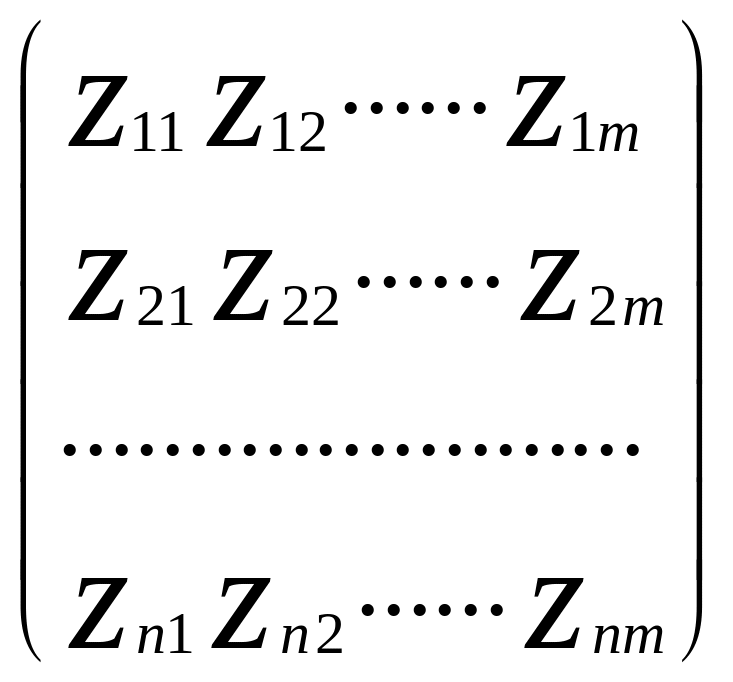
![]() =
(Z1,
Z2,…Zm)
=
(Z1,
Z2,…Zm)
Ця дія обумовлена тим, що коли ознаки мають різні одиниці виміру, виникає необхідність нормування ознак, в результаті чого вони стануть безрозмірними величинами. В результаті введення так званої умовної одиниці виміру буде змога порівнювати об’єкти.
Під час проведення кластерного аналізу виникають труднощі, пов’язані з вибором способу нормування та визначення відстані між об’єктами, яка має неоднозначний характер.
Найбільш вживаними способами нормування прийнято вважати наступні:
 ;
;
 ;
;
 ;
;
 ;
;
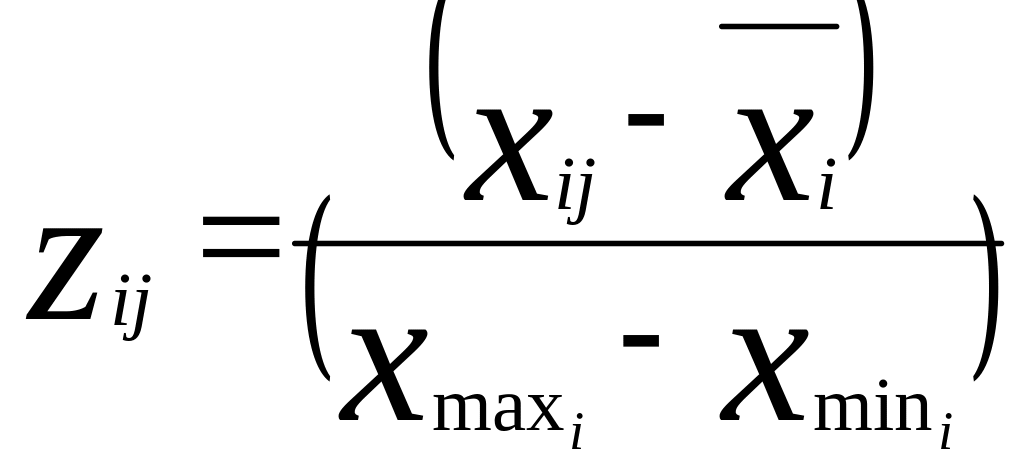 ,
,
де
![]() – нормоване
значення і-ї
ознаки для j-ї
одиниці сукупності;
– нормоване
значення і-ї
ознаки для j-ї
одиниці сукупності;
і = 1,2,……m;
j = 1,2,……n;
m – кількість ознак;
n – кількість одиниць сукупності;
![]() -
значення
і-ї
ознаки для j-ї
одиниці сукупності;
-
значення
і-ї
ознаки для j-ї
одиниці сукупності;
![]() -
середній рівень і-ї
ознаки;
-
середній рівень і-ї
ознаки;
![]() -
середньоквадратичне відхилення і-ї
ознаки;
-
середньоквадратичне відхилення і-ї
ознаки;