

3.1. Взлом md5
В Інтернеті можна знайти багато програм, які обіцяють знайти рядок, для якої алгоритм MD5 видає заданий результат. Ці програми дійсно працюють. Раніше зазначалося, що відновити параметр неможливо. Як же працюють ці програми? Вони перебирають всі можливі рядки, застосовують до них алгоритм MD5, а потім порівнюють зі зразком. Якщо значення співпали, це означає, що програма знайшла необхідний рядок. Але у цих програм є маленький недолік. Припустимо, відомо, що програму доведеться перебрати усі слова довжиною в 8 символів, що складаються з маленьких і великих латинських букв. Скільки часу це займе? Скільки всього таких слів? На першому місці може стояти будь-який з 26 * 2 = 52 символів. На 2, 3, 4, 5, 6, 7 і 8 - теж 52. Значить, всього таких слів буде: 52 * 52 * 52 * 52 * 52 * 52 * 52 * 52 = 528 = 53 * 1012. А якщо використовуються не тільки латинські букви? То це ще більше. Перебір всіх варіантів на звичайному персональному комп'ютері займе дуже багато часу. В Інтернеті можна знайти сайти, які по введеному хешу видають рядок, для якої буде точно такий же хеш. Ці сайти використовують базу даних з заздалегідь прорахованим хешом. Але в базах зберігаються не всі хеши, а тільки самі використовувані. Так що рекомендується використовувати в якості пароля абсолютно випадкову послідовність символів[17].
На даний момент існують кілька видів «злому» хешів MD5 — підбору повідомлення із заданим хешем:
Перебір по словником
Brute-force
RainbowCrack
Колізія хеш-функції
При цьому методи перебору по словнику і brute-force можуть використовуватися для злому хешу інших хеш-функцій (з невеликими змінами алгоритму). На відміну від них, RainbowCrack вимагає попередньої підготовки райдужних таблиць, які створюються для заздалегідь певної хеш-функції. Пошук колізій специфічний для кожного алгоритму[18].
Коротко розглянемо ці види «злому»:
Перебір по словнику – атака на систему захисту, що використовує метод повного перебору (англ. brute-force) передбачуваних паролів, які використовуються для аутентифікації, здійснюваного шляхом послідовного перегляду всіх слів (паролів в чистому вигляді або їх зашифрованих образів) певного виду і довжини зі словника з метою подальшого злому системи і отримання доступу до секретної інформації. Даний захід, в більшості випадків, має негативний характер, що суперечить моральним і законодавчим нормам[19].
Повний перебір (або метод «грубої сили», англ. Brute force) - метод вирішення математичних задач. Відноситься до класу методів пошуку рішення вичерпання всіляких варіантів. Складність повного перебору залежить від кількості всіх можливих рішень задачі. Якщо простір рішень дуже велике, то повний перебір може не дати результатів протягом декількох років або навіть століть.
Будь-яке завдання з класу NP може бути вирішена повним перебором. При цьому, навіть якщо обчислення цільової функції від кожного конкретного можливого рішення задачі може бути здійснено за поліноміальний час, в залежності від кількості всіх можливих рішень повний перебір може зажадати експоненціального часу роботи.
У криптографії на обчислювальної складності повного перебору ґрунтується оцінка крипостійкості шифрів. Зокрема, шифр вважається крипостійким, якщо не існує методу «злому» істотно більш швидкого ніж повний перебір всіх ключів. Криптографічні атаки, засновані на методі повного перебору, є найбільш універсальними, але і найдовшими[20].
RainbowCrack - комп'ютерна програма для швидкого злому хешей. Є реалізацією техніки Філіпа Оксліна faster time-memory trade-off. Вона дозволяє створити базу предсгенерованих LanManager хешів, за допомогою якої можна майже миттєво зламати практично будь-який алфавітно-цифровий пароль. Хоча створення райдужних таблиць займає багато часу і пам'яті, наступний злом проводиться дуже швидко. Основна ідея даного методу - досягнення компромісу між часом пошуку по таблиці і займаної пам'яттю[21].
Колізією хеш-функції H називається два різних вхідних блока даних x і y таких, що H (x) = H (y).
Колізії існують для більшості хеш-функцій, але для «хороших» хеш-функцій частота їх виникнення близька до теоретичного мінімуму. У деяких окремих випадках, коли безліч різних вхідних даних звичайно, можна задати ін'єкційних хеш-функцію, за визначенням не має колізій. Однак для хеш-функцій, що приймають вхід змінної довжини і повертають хеш постійної довжини (таких як MD5), колізії зобов'язані існувати, оскільки хоча б для одного значення хеш-функції відповідне йому безліч вхідних даних (повний прообраз) буде нескінченне - і будь-які два набори даних з цієї безлічі утворюють колізію[22].
3.2. Колізії MD5
Колізія хеш-функції - це отримання однакового значення функції для різних повідомлень і ідентичного початкового буфера. На відміну від колізій, псевдоколлізії визначаються як рівні значення хешу для різних значень початкового буфера, причому самі повідомлення можуть збігатися або відрізнятися. У MD5 питання колізій не вирішується[23].
У 1996 році Ганс Доббертін знайшов псевдоколлізіі в MD5, використовуючи певні ініціалізованні вектори, відмінні від стандартних. Виявилося, що можна для відомого повідомлення побудувати друге, таке, що воно буде мати такий же хеш, як і вихідне. C точки зору математики це означає: MD5 (IV, L1) = MD5 (IV, L2), де IV - початкове значення буфера, а L1 і L2 - різні повідомлення. Наприклад, якщо взяти початкове значення буфера:
A = 0x12AC2375
В = 0x3B341042
C = 0x5F62B97C
D = 0x4BA763E
і задати вхідний повідомлення
AA1DDABE |
D97ABFF5 |
BBF0E1C1 |
32774244 |
1006363E |
7218209D |
E01C136D |
9DA64D0E |
98A1FB19 |
1FAE44B0 |
236BB992 |
6B7A779B |
1326ED65 |
D93E0972 |
D458C868 |
6B72746A |
то, додаючи число 29 до певного 32-розрядного слова в блоковому буфері, можна отримати друге повідомлення з таким же хешем[24].
Тоді MD5 (IV, L1) = MD5 (IV, L2) = BF90E670752AF92B9CE4E3E1B12CF8DE.
У 2004 році китайські дослідники Ван Сяоюн (Wang Xiaoyun), Фен Денг (Feng Dengguo), Лай Сюецзя (Lai Xuejia) і Юй Хунбо (Yu Hongbo) оголосили про виявлену ними уразливості в алгоритмі, що дозволяє за невеликий час (1 година на кластері IBM p690) знаходити колізії.
У 2005 році Ван Сяоюн і Юй Хунбо з університету Шаньдун в Китаї опублікували алгоритм, який може знайти дві різні послідовності в 128 байт, які дають однаковий MD5-хеш[25].
Кожен з цих блоків дає MD5-хеш, рівний 79054025255fb1a26e4bc422aef54eb4.
У 2006 році чеський дослідник Властіміл Клима опублікував алгоритм, що дозволяє знаходити колізії на звичайному комп'ютері з будь-яким початковим вектором (A, B, C, D) за допомогою методу, названого їм «туннелирование».
Алгоритм MD5 використовує ітераційний метод Меркле-Дамгарда, тому стає можливим побудова колізій з однаковим, заздалегідь обраним префіксом. Аналогічно, колізії виходять при додаванні однакового суфікса до двох різних префіксам, які мають однаковий хеш. У 2009 році було показано, що для будь-яких двох заздалегідь обраних префіксів можна знайти спеціальні суфікси, з якими повідомлення будуть мати однакове значення хешу. Складність такої атаки становить всього 239 операцій підрахунку хешу[26].
Метод Ван Сяоюн і Юй Хунбо
Метод Ван Сяоюн і Юй Хунбо використовує той факт, що MD5 побудований на ітераційному методі Меркле-Дамгарда. Поданий на вхід файл спочатку доповнюється, так щоб його довжина була кратна 64 байтам, після цього він ділиться на блоки по 64 байта кожен M0, M1 ,…, Mn-1.Далі обчислюється послідовність 16-байтних станів s0 ,…, sn за правилом sf+1 = ƒ(sj,Mi), де ƒ - деяка фіксована функція. Початковий стан s0 називається ініціалізовним вектором[27].
Метод дозволяє для заданого ініціалізованого вектора знайти дві пари М,М’ и N,N’, такі що ƒ(ƒ(s,M),M’)= ƒ(ƒ(s,N),N’). Важливо відзначити, що цей метод працює для будь-якого ініціалізованого вектора, а не тільки для вектора використовуваного за стандартом.
Ця атака
є різновидом диференціальної атаки,
яка, на відміну від інших атак цього
типу, використовує цілочисельне
віднімання, а не XOR в якості запобіжної
різниці. При пошуку колізій використовується
метод модифікації повідомлень: спочатку
вибирається довільне повідомлення M0,
далі воно модифікується за деякими
правилами, сформульованим у розділі,
після чого обчислюється диференціал
хеш-функції, причому
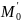 =М0+dM0
з ймовірністю 2-37.
До М0
і
застосовується функція стиснення для
перевірки умов колізії; далі вибирається
довільне M1,
модифікується, обчислюється новий
диференціал, рівний нулю з ймовірністю
2-30,
а рівність нулю диференціала хеш-функції
як раз означає наявність колізії.
Виявилося, що знайшовши одну пару М0
і
,
можна змінювати лише два останніх слова
в М0,тоді
для знаходження нової пари М1
і
=М0+dM0
з ймовірністю 2-37.
До М0
і
застосовується функція стиснення для
перевірки умов колізії; далі вибирається
довільне M1,
модифікується, обчислюється новий
диференціал, рівний нулю з ймовірністю
2-30,
а рівність нулю диференціала хеш-функції
як раз означає наявність колізії.
Виявилося, що знайшовши одну пару М0
і
,
можна змінювати лише два останніх слова
в М0,тоді
для знаходження нової пари М1
і
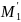 потрібно всього близько 239
операцій хеширования.
потрібно всього близько 239
операцій хеширования.
Застосування цієї атаки до MD4 дозволяє знайти колізію менше ніж за секунду. Вона також може бути застосована до інших хеш-функцій, таких як RIPEMD і HAVAL[28].