

Множественная регрессия
Обобщением линейной регрессионной модели с двумя переменными является многомерная регрессионная модель (или модель множественной регрессии). Пустьnраз измерены значения факторов x1 , x2 , ..., xk и соответствующие значения переменной y; предполагается, что
yi = o + 1xi1 + ... + kxik+ i , i= 1, ..., n, (12)
(второй индекс у х относится к номеру фактора, а первый - к номеру наблюдения); предполагается также, что
Mi=
0,
M =
2,
=
2,
M(ij) = 0, i j, (12a)
т.е. i- некоррелированные случайные величины . Соотношения (12) удобно записывать в матричной форме:
Y = X+ , (13)
где Y = (y1, ..., yk)T - вектор-столбец значений зависимой переменной, Т - символ транспонирования, = (0, 1, ..., k)T- вектор-столбец (размерности k) неизвестных коэффициентов регрессии, = (1 , ..., n)T - вектор случайных отклонений,

-матрица n (k + 1); в i - й строке (1, xi1, ...,xik) находятся значения независимых переменных в i-м наблюдении первая переменная - константа, равная 1.
Оценка
коэффициентов регрессии.
Построим оценку
 для вектора
так, чтобы вектор оценок
для вектора
так, чтобы вектор оценок
 = Х
= Х зависимой переменной минимально (в
смысле квадрата нормы разности) отличался
от вектораY
заданных значений:
зависимой переменной минимально (в
смысле квадрата нормы разности) отличался
от вектораY
заданных значений:

 по
по
 .
.
Решением является (если ранг матрицы Х равен k +1) оценка
 =
(XTX)-1XTY
(14)
=
(XTX)-1XTY
(14)
Нетрудно проверить, что она несмещенная. Ковариационная (дисперсионная) матрица равна
D = (
= ( )
(
)
( )T
= 2
(XTX)1
= 2Z
, (15)
)T
= 2
(XTX)1
= 2Z
, (15)
где обозначено Z = (XTX)1.
Справедлива
теорема Гаусса - Маркова. В условиях (12а) оценка (14) является наилучшей (в смысле минимума дисперсии) оценкой в классе линейных несмещенных оценок.
Оценка дисперсии 2 ошибок. Обозначим
e
= Y = YХ
= YХ =[IX
(XTX)1XT]
Y = BY
(16)
=[IX
(XTX)1XT]
Y = BY
(16)
вектор
остатков (или невязок); B
= IX
(XTX)1XT
- матрица; можно проверить, что B2
= B.
Для остаточной суммы квадратов
 справедливо соотношение
справедливо соотношение
M = M
= M (n
- k -1)2
,
(n
- k -1)2
,
откуда следует, что несмещенной оценкой для 2 является
s2=
 .
(17)
.
(17)
Если предположить, что iв (12) нормально распределены, то справедливы следующие свойства оценок:
1)
(n
- k
- 1)
 имеет распределение хи квадрат
имеет распределение хи квадрат сn-k-1
степенями свободы;
сn-k-1
степенями свободы;
оценки
 иs2независимы.
иs2независимы.
Как и в случае простой регрессии, справедливо соотношение:
 или
или
Tss =Ess +Rss , (18)
в векторном виде:
 ,
,
где
 = (
= ( .
Поделив обе части на полную вариацию
игреков
.
Поделив обе части на полную вариацию
игреков
Tss=
 ,
получим коэффициент детерминации
,
получим коэффициент детерминации
R2
=
 (19)
(19)
Коэффициент
R2
показывает качество подгонки регрессионной
модели к наблюдённым значениям yi.
Если R2
= 0,
то регрессия Y
на x1
, ..., xk
не улучшает качество предсказания yi
по сравнению с тривиальным предсказанием
 .
Другой крайний случайR2
= 1
означает точную подгонку: все ei
= 0, т.е. все точки наблюдений лежат на
регрессионной плоскости. Однако, значение
R2
возрастает с ростом числа переменных
(регрессоров) в регрессии, что не означает
улучшения качества предсказания, и
потому вводится скорректированный
(adjusted)
коэффициент детерминации
.
Другой крайний случайR2
= 1
означает точную подгонку: все ei
= 0, т.е. все точки наблюдений лежат на
регрессионной плоскости. Однако, значение
R2
возрастает с ростом числа переменных
(регрессоров) в регрессии, что не означает
улучшения качества предсказания, и
потому вводится скорректированный
(adjusted)
коэффициент детерминации
 (20)
(20)
Его использование более корректно для сравнения регрессий при изменении числа переменных (регрессоров).
Доверительные
интервалы для коэффициентов регрессии.
Стандартной
ошибкой оценки
 является величина
является величина , оценка для которой
, оценка для которой
sj
=
 ,
j
=
0, 1, ..., k,
(21)
,
j
=
0, 1, ..., k,
(21)
где zjj- диагональный элемент матрицы Z. Если ошибки i распределены нормально, то, в силу свойств 1) и 2), приведенных выше, статистика
 (22)
(22)
распределена по закону Стьюдента с (n - k - 1) степенями свободы, и потому неравенство
 tpsj,
(23)
tpsj,
(23)
где tp - квантиль уровня (1 + PД) / 2 этого распределения, задает доверительный интервал для j с уровнем доверия РД.
Проверка гипотезы о нулевых значениях коэффициентов регрессии. Для проверки гипотезы Н0об отсутствии какой бы то ни было линейной связи между y и совокупностью факторов, Н0: 1 = 2= ... = k = 0, т.е. об одновременном равенстве нулю всех коэффициентов, кроме коэффициента 0при константе, используется статистика
F
=
 =
= =
= , (24)
, (24)
распределенная, если Н0верна, по закону Фишера с k и n - k - 1 степенями свободы. Н0отклоняется, если
F>F(k, n - k - 1), (25)
где F- квантиль уровня 1 - .
Отбор
наиболее существенных объясняющих
переменных. Различные
регрессии (с различным набором переменных)
можно сравнивать по скорректированному
коэффициенту детерминации (20): принять
тот вариант регрессии, для которого
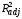 максимален (подробнее см. в примере).
максимален (подробнее см. в примере).
Пример [5]. Исследуется зависимость урожайности y зерновых культур ( ц/га ) от ряда факторов (переменных) сельскохозяйственного производства, а именно,
х1 - число тракторов на 100 га;
х2 - число зерноуборочных комбайнов на 100 га;
х3 - число орудий поверхностной обработки почвы на 100 га;
х4- количество удобрений, расходуемых на гектар (т/га);
х5 - количество химических средств защиты растений, расходуемых на гектар (ц/га).
Исходные данные для 20 районов области приведены в табл. 2.

Предварительный просмотр.
Предварительно визуально оценим имеющиеся данные, построив несколько диаграмм рассеяния:


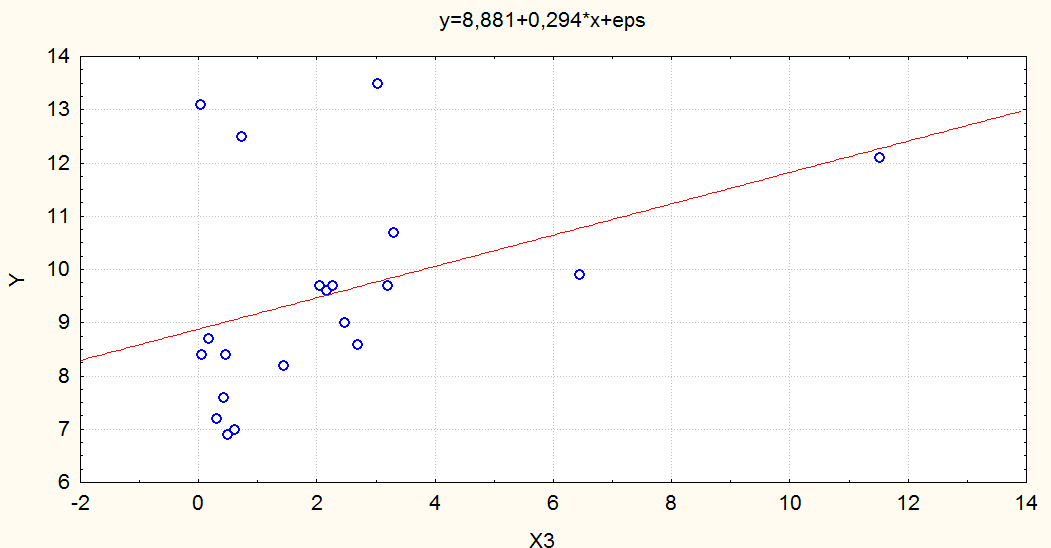


Наблюдаем диаграммы рассеяния с подобранной прямой парной регрессии, параметры которой отражены в заголовке. Иногда такой просмотр позволяет увидеть основную зависимость. В нашем примере этого нет.
В окне Mult. Regr.Resultsимеем основные результаты: коэффициент детерминации (19) R2 = 0.517; для проверки гипотезы Н0об отсутствии какой бы то ни было линейной связи между переменной y и совокупностью факторов определена статистика (24) F = 3.00; это значение соответствует уровню значимости р = 0.048 (эквивалент (25) согласно распределению F (5,14) Фишера с df = 5 и 14 степенями свободы. поскольку значение р весьма мало, гипотеза Н0 отклоняется.

Оценка
 (x)
неизвестной функции регрессии f
(x)
в данном случае:
(x)
неизвестной функции регрессии f
(x)
в данном случае:
 (x)
= 3.51
0.06 x1
+ 15.5x2
+ 0.11x3
+ 4.47 x4
2.93x5
(26)
(x)
= 3.51
0.06 x1
+ 15.5x2
+ 0.11x3
+ 4.47 x4
2.93x5
(26)
В столбце St. Err. ofBуказаны стандартные ошибки sjоценок коэффициентов (по (21)); видно, что стандартные ошибки в оценке всех коэффициентов, кроме 4, превышают значения самих коэффициентов, что говорит о статистической ненадежности последних. В столбце t(14) -значение статистики Стьюдента (22) для проверки гипотезы о нулевом значении соответствующих коэффициентов; в столбце p-level -уровень значимости отклонения этой гипотезы; достаточно малым (0.01) этот уровень является только для коэффициента при x4. Только переменная x4- количество удобрений, подтвердила свое право на включение в модель. В то же время проверка гипотезы об отсутствии какой бы то ни было линейной связи между y и (х1 , ..., х5) с помощью статистики (24) (об этом сказано выше)
F = 3.00 ,p = 0.048 ,
говорит о том, что следует продолжить изучение линейной связи между y и (х1 , ..., х5), анализируя как их содержательный смысл, так и матрицу парных корреляций:

Из матрицы видно, что х1 , х2 и х3(оснащенность техникой) сильно коррелированы (парные коэффициенты корреляции 0.854, 0.882 и 0.978), т.е. имеет место дублирование информации, и потому, по-видимому, есть возможность перехода от исходного числа признаков (переменных) к меньшему.