

5. Численная реализация
Прежде всего отметим, что численная реализация решения (26) основана на решении основных задач линейной алгебры. Существуют несколько библиотек, в которых собраны необходимые подпрограммы: LAPACK, IMSL, NAG и так далее. Math Kernel Library (MKL) представляет собой пакет, который специально оптимизирован для процессоров Intel (существуют версии MKL для Windows и для Linux систем). Отличное преимущество получают от использования поддержки многоядерных и многопроцессорных систем и автоматического распараллеливания. Это способно значительно увеличить скорость вычислений. Существует вектор реализаций элементарной операции (например, квадратный корень из элемента массива) в параллельном режиме. Специальные математические пакеты программ такие, как Matlab, Maple, Mathematica используют MKL, играя роль библиотечной оболочки.
Перспективный путь для ускорения кода – применение графических процессоров общего назначения (GPUs). Технология CUDA является вычислительным двигателем в графических процессорах NVIDIA. Она дает доступ к набору команд вычислительных элементов видеокарты. Стандартные процедуры LAPACK могут быть ускорены CUDA. Вместо того, чтобы перепрограммировать процедуры LAPACK, желательно применять специальные CUDA-библиотеки. Кроме того, MATLAB 2010b поддерживает nVIDIA CUDA-совместимые процессоры и для использования GPU-вычислительных возможностей не требует знаний и опыта в CUDA.
Значительное ускорение и экономия памяти могут быть достигнуты при работе с разреженными матрицами. Основная идея заключается в следующем: при работе с матрицей, содержащей много нулевых элементов, имеет смысл хранить только ненулевые элементы и дополнительную информацию, которая может быть использована для восстановления индексов ненулевых или нулевых элементов. Существует несколько форматов для хранения разреженных матриц: формат сжатия разреженных строк (CSR), формат сжатия разреженных столбцов (CSC) и координированный формат. Выбор формата зависит от типа операции, например, CSC формат удобно использовать в случаях, когда элементы разреженной матрицы расположены в каждом столбце. Использование разреженных матриц может быть эффективным для вычисления мнимой части (49) и модифицированной функции источника.
6. Результаты и обсуждение
Были проанализированы влияния различных аппаратно-программных средств для эффективной реализации решения (26) с ликвидацией мнимой части на основе MSH на примере кода MDOM и MVDOM. Сравнение времени выполнения для различных режимов компиляции и вычисления представлены в таблице 1 для двух тестов (тест 1: N=101, K=500, M=32; тест 2: N=101, K=1000, M=32). Тесты проводились на системе Ubuntu 10.04, Intel Core 2 Duo 3 ГГц 2 Гб ОЗУ, Intel Fortran Compiler 11.1 c MKL 10.2. Использовались два компилятора gfortran и ifort, использовалась технология оптимизации при работе с разреженными матрицами.
Обратим
внимание, что MKL
использует все доступные ядра
вычислительной системы (в данном случае
– 2 ядра) и предоставляет результат в
половину времени. Технология разреженных
матриц, примененная при вычислении
мнимой части, значительно уменьшила
время выполнения. В связи с разреженностью
матриц, двумерные массивы сводятся к
одномерным. Таким образом, время
выполнения пропорционально K
вместо
 .
.
Мы увеличили ускорение примерно на 20% за счет умножения матриц на nVIDIA GeForce 480 GTX GPU. Вычисления на графических процессорах дают преимущества только для массивов большой размерности, в противном случае более предпочтительными являются вычисления на центральном процессоре. Инструменты профайлера показывают, что вычисление собственных векторов и значений занимают половину времени выполнения. К сожалению, подпрограммы для этих задач не реализована в инструментах Matlab для графических процессоров. Размеры матриц значительно сокращены в связи с тем, что для ликвидации мнимого решения использовался МСГ. На практике N меньше 300. Однако вычисление поляризационного спектра длины волны также может быть реализовано средствами CUDA технологии. Возможно использовать преимущества CUDA для более чем одной длины волны.
Таблица 1. Сравнение времени вычисления для двух тестов
|
Особенности |
Время выполнения на I тесте, сек |
Время выполнения на II тесте, сек |
|
gfortran+LAPACK |
240 |
530 |
|
gfortran+LAPACK + оптимизация |
230 |
505 |
|
ifort+LAPACK |
210 |
490 |
|
ifort+MKL |
115 |
250 |
|
ifort+MKL+ оптимизация |
105 |
230 |
|
ifort+MKL+ оптимизация+учет свойств разреженности |
33 |
44 |
|
Matlab 2010b |
27 |
45 |
|
Matlab 2010b + CUDA |
22 |
33 |
Рассмотрим теперь эффективность различных методов ликвидации мнимой части численным сравнением вычисления углового распределения излучений для той же задачи разными кодами: DISCORT и MDOM в скалярном случае, и PSTAR и MVDOM – в векторном. Стоит отметить, что скорость расчетов DISCORT может быть значительно увеличена с помощью алгоритмов разреженных матриц в подпрограмме ZEROIT, которая зануляет данную матрицу. В этом случае скорость для достаточно гладких фазовых функций (r<0.9) MDOM и DISORT того же порядка. Для фазовой функции Хеньи-Гринштейна r=0.98, метод ликвидации мнимой части оказался лучше. На рисунке 1 представлено численное сравнение, отражающее расчеты для средней анизотропии рассеяния, а на втором – сильная анизотропия.

Рисунок 1. Сравнение MDOM и DISORT в случае средней анизотропии

Рисунок 2. Сравнение MDOM и DISORT в случае сильной анизотропии
Обратим внимание, что даже средняя степень анизотропии рассеяния обязательно требует использования TMS метода. Выделение особенностей решения на основе МСГ работает независимо от степени анизотропии. Время работы в первом случае примерно
то
же
 сек, но сильно отличается во втором
случае: MDOM
сек, но сильно отличается во втором
случае: MDOM
 сек, а DISORT
сек, а DISORT
 сек.
сек.
Совершенно
аналогичные результаты были получены
в векторном случае. Мы сравнили PSTAR
и MVDOM
в случаях фазовых матриц для нормального
логарифмического распределения с
параметрами
 ;
и геометрии схемы наблюдения с
;
и геометрии схемы наблюдения с
 .
На рисунке 3 показано сравнение расчетов
углового распределения поляризации,
передающейся плите, а на рисунке 4
приводится сравнение отраженного
излучения.
.
На рисунке 3 показано сравнение расчетов
углового распределения поляризации,
передающейся плите, а на рисунке 4
приводится сравнение отраженного
излучения.

Рисунок 3. Поляризация передающегося излучения
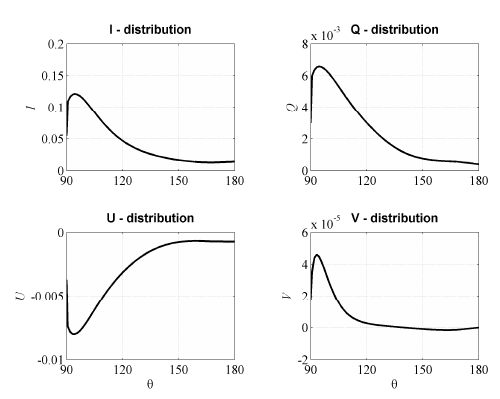
Рисунок 4. Поляризация отраженного излучения
Для получения наилучших результатов мы использовали следующие параметры:N=71, K=171, M=20 в коде MVDOM и 30 потоков в коде Pstar.Сравнение результатов показало идеальное совпадение на уровне машинной точности компьютера, но время вычислений составило 11 секунд для MVDOM и боле 180 секунд для PSTAR.