

Лаба 1-4 2-ой сем [Вариант 5] / Лаба 4
.docxМинистерство образования Республики Беларусь
Учреждение образования
БЕЛОРУССКИЙ ГОСУДАРСТВЕННЫЙ УНИВЕРСИТЕТ ИНФОРМАТИКИ И РАДИОЭЛЕКТРОНИКИ
Факультет информационных технологий и управления
Кафедра ИТАС
ОТЧЕТ
по лабораторной работе №4 (вариант 5)
“ Анализ и принятие решений на основе методов кластерного анализа ”
по дисциплине «Системный анализ и исследование операций»
|
Выполнил: |
Проверила: |
|
студент гр. XXXXXX |
Н.В.Хаджинова |
|
|
|
Минск 201X
-
Цель работы
- Изучить понятие кластерного анализа, назначение и классификацию методов кластерного анализа.
-
Ход работы
2.1 Анализируются сведения о продукции девяти предприятий (П1, П2,...,П9). Имеются следующие показатели.
|
Предприятие |
П1 |
П2 |
П3 |
П4 |
П5 |
П6 |
П7 |
П8 |
П9 |
|
Доля продукции, поставляемой на экспорт, % |
42 |
17 |
38 |
54 |
14 |
11 |
50 |
24 |
62 |
|
Доля высокотехнологичной продукции, % |
30 |
20 |
24 |
60 |
10 |
7 |
30 |
20 |
42 |
Требуется выделить группы предприятий, имеющих сходные значения показателей.
При решении задачи с использованием метода K средних выделить следующие группы: 1) предприятия с высокой долей экспортной продукции и высокотехнологичной продукции; 2) предприятия с низкой долей экспортной продукции и высокотехнологичной продукции; 3) предприятия со средними значениями обоих показателей.
2.2 Нормировка исходных данных с помощью деления на максимальное значение
Выполним нормировку, для этого делим все значения для каждого признака на максимальное значение этого признака. Например, для признака «Доля продукции, поставляемой на экспорт» максимальное значение 62. Разделим каждое значение признака на это максимальное значение. Результаты приведены в таблице 1.
Таблица 1
|
Предприятие |
П1 |
П2 |
П3 |
П4 |
П5 |
П6 |
П7 |
П8 |
П9 |
|
Доля продукции, поставляемой на экспорт |
0,677 |
0,274 |
0,613 |
0,871 |
0,226 |
0,177 |
0,806 |
0,387 |
1,00 |
|
Доля высокотехнологичной продукции |
0,5 |
0,333 |
0,4 |
1 |
0,167 |
0,117 |
0,5 |
0,333 |
0,7 |
2.3 Разделение объектов на три группы, используя метод К средних
Метод К средних предназначен для разделения объектов на заданное число кластеров.
Пусть предполагается, что предприятия можно разделить на три группы:
1) предприятия с высокой долей экспортной продукции и высокотехнологичной продукции;
2) предприятия с низкой долей экспортной продукции и высокотехнологичной продукции;
3) предприятия со средними значениями обоих показателей.
1. Номер итерации принимается равным нулю s=0.
2. Количество кластеров равно трем К=3. Выберем для каждого кластера прототип. Наиболее характерным представителем первого кластера является предприятие П4. В качестве характерного представителя второго кластера – предприятие П6, а в качестве представителя третьего кластера –предприятие П1.

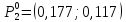
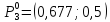
3. Переходим к следующей итерации s = 1.
4. Находим расстояния от каждого из анализируемых объектов до каждого из прототипов по следующей формуле:
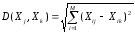
В зависимости от расстояния относим страны к соответствующему кластеру. Расстояния приведены в таблице 2.
Таблица 2.
|
Объект |
П1 |
П2 |
П3 |
П4 |
П5 |
П6 |
П7 |
П8 |
П9 |
|
|
0,536 |
0,895 |
0,653 |
0,000 |
1,054 |
1,123 |
0,504 |
0,824 |
0,327 |
|
|
0,630 |
0,237 |
0,520 |
1,123 |
0,070 |
0,000 |
0,737 |
0,302 |
1,008 |
|
|
0,000 |
0,436 |
0,119 |
0,536 |
0,561 |
0,630 |
0,129 |
0,335 |
0,380 |
|
Кластер |
3 |
2 |
3 |
1 |
2 |
2 |
3 |
2 |
1 |
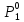
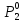
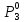
По найденным расстояниям отнесем каждый объект к кластеру, представленному ближайшим прототипом.
Таким образом, получено следующее разбиение объектов на кластеры:
к первому
– относятся объекты
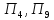 ;
;
ко
второму – объекты
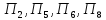 ;
;
к
третьему – объекты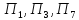 .
.
5. В каждом кластере определим новый объект-прототип. Значение каждого признака этого объекта-прототипа определим как среднее арифметическое значение этого признака для всех объектов, входящих на текущей итерации в данный кластер.
|
|
|
|
|
0,935 |
0,266 |
0,699 |
|
0,850 |
0,238 |
0,467 |
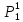

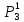
6. Сравним прототипы полученные на данной и на предыдущей итерации, т.к. прототипы не совпадают, переходим к шагу 3.
3. Переходим к следующей итерации s=2
4. Находим расстояния от каждого из анализируемых объектов до каждого из прототипов.
Эти расстояния приведены в таблице 3
Таблица 3
|
Объект |
П1 |
П2 |
П3 |
П4 |
П5 |
П6 |
П7 |
П8 |
П9 |
|
|
0,435 |
0,839 |
0,554 |
0,163 |
0,985 |
1,055 |
0,373 |
0,753 |
0,163 |
|
|
0,488 |
0,096 |
0,383 |
0,973 |
0,082 |
0,150 |
0,601 |
0,154 |
0,867 |
|
|
0,040 |
0,445 |
0,109 |
0,560 |
0,560 |
0,628 |
0,113 |
0,339 |
0,381 |
|
Кластер |
3 |
2 |
3 |
1 |
2 |
2 |
3 |
2 |
1 |

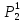
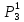
По найденным расстояниям отнесем каждый объект к кластеру, представленному ближайшим прототипом.
Таким
образом, получено следующее разбиение
объектов на кластеры: к первому кластеру
относятся
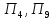 ,
ко второму – объекты
,
ко второму – объекты
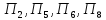 ,
к третьему – объекты
,
к третьему – объекты
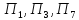 .
.
5. В каждом кластере определим новый объект-прототип. Значение каждого признака этого объекта-прототипа определим как среднее арифметическое значение этого признака для всех объектов, входящих на текущей итерации в данный кластер.
|
|
|
|
|
0,935 |
0,266 |
0,699 |
|
0,850 |
0,238 |
0,467 |
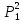
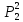

6. Сравним прототипы полученные на данной и на предыдущей итерации, прототипы совпадают. Это означает, что получено окончательное разбиение объектов на кластеры.
Таким образом, получено следующее разбиение объектов на кластеры:
к первому
– относятся объекты
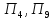 ;
;
ко
второму – объекты
 ;
;
к
третьему – объекты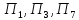 .
.
2.4 Разделение объектов на группы, используя метод максимина
Метод предназначен для разделения объектов на кластеры, причем количество кластеров заранее неизвестно, оно определяется автоматически в процессе разбиения объектов.
1. Пусть первый объект принимается в качестве прототипа первого кластера: Р1= П1=(0,677; 0,500). Количество кластеров принимается равным единице.
2. Определим расстояние от прототипа Р1 до всех остальных объектов. Эти расстояния приведены в табл.2.3.
Таблица 4
|
Объект |
П1 |
П2 |
П3 |
П4 |
П5 |
П6 |
П7 |
П8 |
П9 |
|
P1 |
0,000 |
0,436 |
0,119 |
0,536 |
0,561 |
0,630 |
0,129 |
0,335 |
0,380 |
Из таблицы видно, что наиболее удаленным от прототипа Р1 является объект П6 . Он становиться прототипом второго кластера:
Р2= П6=(0,177; 0,117).
3. Определим пороговое расстояние Т=D(Р1 ,Р2)/2=0,315.
4. Находим расстояние от каждого из анализируемых объектов до каждого прототипа. По найденным расстояниям выполним отнесение каждого объекта к кластеру, представленному ближайшим прототипом. Расстояния и результаты разбиения объектов на кластеры приведены в таблице 5
Таблица 5
|
Объект |
П1 |
П2 |
П3 |
П4 |
П5 |
П6 |
П7 |
П8 |
П9 |
|
P1 |
0,000 |
0,436 |
0,119 |
0,536 |
0,561 |
0,630 |
0,129 |
0,335 |
0,380 |
|
P2 |
0,630 |
0,237 |
0,520 |
1,123 |
0,070 |
0,000 |
0,737 |
0,302 |
1,008 |
|
Кластер |
1 |
2 |
1 |
1 |
2 |
2 |
1 |
2 |
1 |
5. В каждом кластере определим объект, наиболее удаленный от прототипа своего кластера. В первом кластере таким объектом является П4, во втором – П8.
6. Расстояния между наиболее удаленными объектами и прототипами сравниваются с пороговым расстоянием. Расстояние между П4 и П1 равно 0,536, оно превышает пороговое расстояние (0,315). Таким образом, он становится прототипом нового кластера (Р3), и количество кластеров увеличивается на единицу (К=3). Во втором кластере наиболее удаленным объектом является П8. Расстояние между ним и прототипом равно 0,302 , что меньше порогового, т.е. они имеют сходные значения признаков.
7. Находим новое пороговое расстояние. Оно определяется как половина среднего арифметического всех расстояний между прототипами.
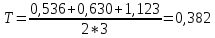
8. Возвращаемся к шагу 4.
4. Находим расстояние от каждого из анализируемых объектов до каждого прототипа. По найденным расстояниям выполним отнесение каждого объекта к кластеру, представленному ближайшим прототипом. Расстояния и результаты разбиения объектов на кластеры приведены в таблице 6.
Таблица 6
|
Объект |
П1 |
П2 |
П3 |
П4 |
П5 |
П6 |
П7 |
П8 |
П9 |
|
P1 |
0,000 |
0,436 |
0,119 |
0,536 |
0,561 |
0,630 |
0,129 |
0,335 |
0,380 |
|
P2 |
0,630 |
0,237 |
0,520 |
1,123 |
0,070 |
0,000 |
0,737 |
0,302 |
1,008 |
|
P3 |
0,536 |
0,895 |
0,653 |
0,000 |
1,054 |
1,123 |
0,504 |
0,824 |
0,327 |
|
Кластер |
1 |
2 |
1 |
3 |
2 |
2 |
1 |
2 |
3 |
5. В каждом кластере определим объект, наиболее удаленный от прототипа своего кластера. В первом кластере таким объектом является П7, во втором – П8, а в третьем – П9.
6. Расстояния между наиболее удаленными объектами и прототипами сравниваются с пороговым расстоянием. Ни одно расстояние не превышает пороговое. Таким образом, можно считать, что во всех кластерах объекты достаточно близки к своим прототипам, т.е. они имеют сходные значения признаков.
Таким
образом, результаты разделения предприятий
на кластеры оказались следующими: к
первому кластеру относятся предприятия
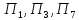 ;
ко второму кластеру –
;
ко второму кластеру –
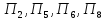 ;
к третьему –
;
к третьему –
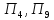 .
Проанализировав показатели предприятий,
мы видим интереснейший момент. Разбиение
на кластеры у нас получилось точно такое
же как и в методе трех средних. А значит
интерпретация полученного разбиения
такова: 1-ый кластер - предприятия со
средними значениями обоих показателей;
2-ой кластер - предприятия с низкой долей
экспортной продукции и высокотехнологичной
продукции; 3-ий кластер - предприятия с
высокой долей экспортной продукции и
высокотехнологичной продукции.
.
Проанализировав показатели предприятий,
мы видим интереснейший момент. Разбиение
на кластеры у нас получилось точно такое
же как и в методе трех средних. А значит
интерпретация полученного разбиения
такова: 1-ый кластер - предприятия со
средними значениями обоих показателей;
2-ой кластер - предприятия с низкой долей
экспортной продукции и высокотехнологичной
продукции; 3-ий кластер - предприятия с
высокой долей экспортной продукции и
высокотехнологичной продукции.
-
Вывод
Выполнив лабораторную работу, познакомился с методами кластерного анализа. Изучил на практике методы К средних и максимина.
Результаты разделения предприятий на три группы методом К средних оказались следующими:
1) предприятия с
высокой долей экспортной продукции и
высокотехнологичной продукции –
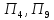 ;
;
2) предприятия
с низкой долей экспортной продукции и
высокотехнологичной продукции –
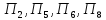 ;
;
3) предприятия
со средними значениями обоих показателей
–
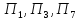 .
.
Результаты разделения предприятий на кластеры методом максимина оказались аналогичными.