

4.4.3. Новітні засоби Grid і Cloud для обчислення задач e–sciences
Обчислення задач e–sciences у теоретичному плані іде по шляху застосування нових комп’ютерних можливостей щодо високої швидкості дій, розподілення пам’яті між процесорами кластерів для проведення обчислень глобальних задач з великими обсягами даних та інтероперабельності [6, 13 14, 22, 23].
Індустрія обчислень базується на організації прозорих обчислень різного роду складних задач e–sciences за рахунок появи нових інфраструктур систем Grid і Cloud Computing з високо пропускним доступом до загальних on–line сховищ даних з деякого місця планети для наукових предметних областей фізики, математики, біології тощо.
Зассоби системи Grid
Одним з практичних рішень забезпечення індустрії обчислень є поява системи Grid у 2005 р. в межах Європейського проекту, як інструментарію підтримки калайдеру з інфраструктурою для глобальних обчислень суперскладних задач з області e–science, фізико-техничних ексреиіментів тощо.
Грід-обчислення (від англ. grid - решітка, мережа) - це форма розподілених обчислень, в якій «віртуальний суперкомп'ютер» представлений у вигляді кластерів з'єднаних за допомогою мережі, слабко пов’язаних гетерогенних комп'ютерів, що працюють разом для виконання величезної кількості завдань (операцій, робіт).
Термін «грід-обчислення» з'явився на початку 1990-х років, як метафора, що демонструє можливість простого доступу до обчислювальних ресурсів як і до електронної (сильної) мережі (англ. Power grid) у збірнику під редакцією Яна Фостера і Карла Кессельмана «The Grid: Blueprint for a new computing infrastructure».
Використання вільного часу процесорів і добровільного комп'ютингу стало популярним після запуску проектів обчислень GIMPS в 1996 році, distributed.net в 1997 році і SETI @ home в 1999 році. Ці перші проекти комп'ютингу використовували потужності приєднаних до мережі комп'ютерів звичайних користувачів для вирішення дослідницьких завдань, що вимагають великих обчислювальних потужностей.
Ідеї грід-системи, включаючи ідеї розподілених обчислень, об'єктно-орієнтованого програмування, використання комп'ютерних кластерів, веб-сервісів та ін.. були зібрані і об'єднані Іеном Фостером, Карлом Кессельманом і Стівом Тікі, яких часто називають батьками грід-технології.
Грід-технологія застосовується для моделювання та обробки даних в експериментах на Великому адронному колайдері.
Найбільш характерними властивостями інформаційно-обчислювальногосередовища GRID є наступні:
1. масштаби обчислювального ресурсу (обсяг пам'яті, кількість процесорів), які багаторазово перевершують ресурси окремого комп'ютера або одного обчислювального комплексу; 2. гетерогенність середовища до її складу можуть входити комп'ютери різної потужності, що працюють під управлінням різних ОС і зібрані на різній елементній базі; 3. просторовий (географічний) розподіл інформаційно-обчислювального ресурсу;
4. об'єднання ресурсів, які не можуть управлятися централізовано (у випадку, якщо вони не належать одній організації);
5. використання стандартних, відкритих, загально доступних протоколів та різних інтерфейсів;
6. Забезпечення інформаційної безпеки.
По своєму призначенні GRID прийнято ділити на обчислювальні системи (computational GRID) і системи, орієнтовані на збереження великих масивів інформації (data GRID).
На GRID можуть використовуватися прикладні завдання, а саме: складне моделювання, спільна візуалізація дуже великих наборів наукових даних,розподілена обробка з метою аналізу даних; зв'язування наукового інструментарію з віддаленими комп'ютерами та архівами даних.
Найбільш ефективним є застосування Рівс для вирішення наступних завдань: – розподілені високопродуктивні обчислення, рішення дуже великих завдань, що вимагають максимальних процесорних ресурсів, пам'яті і т.д.;
– «високо потокові» обчислення, що дозволяють організувати ефективне використання ресурсів для невеликих завдань, утилізуючи тимчасово простоючі
комп'ютерні ресурси; – проведення великих разових розрахунків;
– обчислення із залученням великих обсягів розподілених даних, наприклад, в метеорології, астрономії, фізики високих енергій;
– колективні обчислення, тобто одночасна робота декількох взаємодіючих завдань різних користувачів.
Аналіз світового досвіду побудови GRID систем показує, що вони вирішують наступні проблеми: – об'єднання різнорідних систем;
– спільне використання даних;
– динамічне виділення ресурсів;
– переносність застосувань в гетерогенному середовищі;
– забезпечення інформаційної безпеки.
– застосування відкритих стандартів.
Поняття GRID, GRID-структура, GRID-система є синоніми.
Прикладами ресурсів є обчислювальні ресурси, системи зберігання, каталоги, мережеві ресурси. Вони можуть бути розділені на фізичні і логічні. До фізичних відносяться: оперативна пам'ять, пам'ять на довготривалих носіях, кількість і продуктивність процесорів і т.д. Прикладами логічних ресурсів є розподілена файлова система, комп'ютерний кластер, розподілений пул комп'ютерів, системи проведення деяких обчислень тощо.
Формальний опис форматів повідомлень і наборів правил для обміну повідомлень виконується мережевими протоколами – протоколи нижнього (Ethernet та ін.), середнього (IP, TCP та ін.) та високого(FTP, HTTP та ін.) рівня.
Інтерфейс прикладних програм (API) представляє собою набір функцій (сервісів) специфічної функціональності, що дозволяють ПС здійснювати доступ до ресурсів через обслуговуючу ОС. Розподілене обчислювальне середовище має володіти набором сервісів, які забезпечують контрольоване виконання прикладних програм авторизованих користувачів. Специфіка сервісів GRID визначається характером самого обчислювального середовища: GRID, з динамічним утворенням. З плином часу можуть бути змінені як кількість об'єднаних обчислювальних вузлів, так і їхні якісні характеристики (зміна обчислювального навантаження одного вузла тощо).
При побудові деякої розподіленої системи необхідно забезпечити і ідентифікацію унікальним номером виконуваних програми, за яким проводиться контроль його унікальності засобами спеціального сервісу GRID та авторизація користувача з пріоритетом користувача, необхідним для нормальної роботи служби розподілу обчислювальних ресурсів між прикладними програмами;
GRID забезпечує такі сервіси:
– пошук необхідного програмі ресурсу виконує спеціальний сервіс, який визначає розмір доступного в даний момент часу обчислювального ресурсу, контроль поточного стану системи за описом різнорідних ресурсів, які є у поточний момент часу в складі GRID;
– розміщення на ньому прикладної програми;
– виконання розподілених алгоритмів та паралельних програм;
– доступ до віддалених даних.
– роботу розподілених баз даних
– розподіл ресурсов між різними прикладними програмами;
– виявлення неполадок та забезпечення працездатності включених в обчислювальний процес вузлів;
– забезпечення роботи GRID-системи та змінювання кількості та характеру її сервісів в залежності від призначення варіанту даного обчислювального середовища.
В архітектурі GRID є рівень фабрики (Fabric), який надає необхідні ресурси, спільний доступ до яких забезпечується через протоколи GRID, а також рівень Connectivity, що визначає базові комунікаційні та ідентифікаційні протоколи, необхідні для проведення специфічних для GRID операцій (транзакцій); рівень Resource, базовані на комунікаційному і авторизованому протоколі; рівень Collective для групування протоколів і сервісів, не пов'язаних з будь-яким конкретним ресурсом, а більш глобальними ресурсами за природою для забезпечення колективної взаємодії ресурсів; рівень Application включає в себе за стосунки користувачів, щодо функціонування в середовищі GRID.
Підсистема Etics в Європейскому проекті Grid містить репозиторій програм і даних, виконує збирання готових КПВ, програм, модулів, систем черех конфігураційні файли для виконання по ним обчислень. Нами в ІТК помплексі узято з Etics Grid стандартну мову WSDL для специфікації КПВ з метою подальшого їх подання у глобальному репозиторії Grid.
Для функціонування розподілених прикладних систем нами розроблено загальну модель обчислень, як розвиток моделі взаємодії програм для забезпечення інтероперабельності різнорідних програм і використання необхідних віртуальних даних з оn-line Grid і Cloud. Для обчислень таких задач застосовуються знов розроблені або готові програмні і системні ресурси виду: системи сховищ даних; фонди reuses з багатьох доменів; нові загальні «тули» (конвертори, генератори, трансформатори, верифікатори тощо); глобальні протоколи взаємодії програм у середовищі гетерогенних платформ, географічно розташованих у віддалених адміністративних доменах тощо.
Процес розроблення домену включає багаторівневий аналіз ПрО для встановлення єдиної термінології, вживаної розробниками сімейства і його членів (рис.3) та визначення компонентів, що реалізують завдання домену [ 12, 29, 30].
Хмарні обчислення
Іншим напрямом сучасного обчислення задач глобального типу є Cloud Computing – хмарні обчислення, які підтримуються новими системними засобами (рис. 6), які підтримуються системами Google Apps, IBM-VSphere та системами Microsoft – WCloud, Azure, Amazon, Mech, WАpps, SkyDriven (Http://lenta.ru/articles/2010). Функції деяких систем розглядаються нижче. Google Apps забезпечує обчислення бізнесу в режимі он-лайн за допомогою Інтернет-браузеру до великих об'ємів даних на серверах Google, виконує веб-застосування з сховищами даних через інтерфейс API.в мовах Java і Python за допомогою стандартних протоколів [ 5, 6].
Рис
Рис.6. Віртуальне середовище для організації обчислень задач |
Amazon Machine Image (AMI) підтримує застосування|застосування|, бібліотеки за|та| інструментами збері-гання AMI і|та| образів|зображень| в сховищі, вибір ОС для запуску і|та| контролю декількох AMI з використанням Веб-сервісу, інструментів управління т платою за надані для вживання ресурси, такі як час за кількість переданих даних. Azure (Windows Cloud, 2008) для створення розподілених «хмарних» веб-застосувань і інтернет-сервісів з використанням технології .Net. Amazon Web Services — це інфраструктура Web Services для надання таких послуг: зберігання даних (файловий хостінг, розподілені сховища даних), аренда віртуальних серверів, |
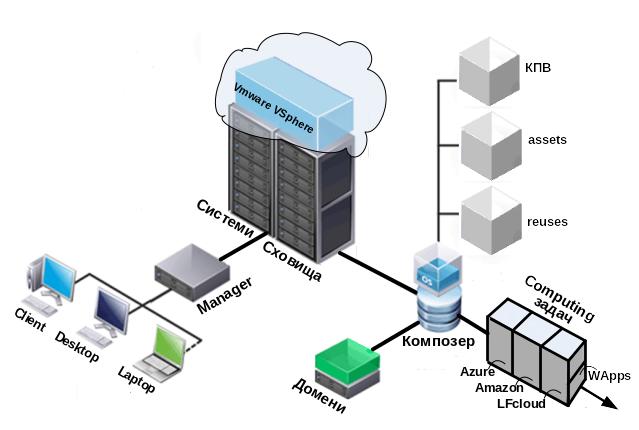
надання обчислювальних потужностей тощо. При чому, час обчислення 12 центів, гігабайт даних на сервері – 15 центів, кожні 10 тисяч транзакцій – 10 центів.
Ці системи зорієнтовані на збереження даних, доступ до глобальних сховищ даних on–line, синхронізацію даних великих розмірів і викладання їх на віддалені сервери тощо. Тут головна проблема організації обчислень потребує визначення нових методів, таких як координація, кооперація та взаємодія різних сервісів і інших готових ресурсів через конфігураційний файл для виконання обчислень відповідних задач. Накопичення готових ресурсів у різних глобальних сховищах для доступу до них різних наукових користувачів потребує розвитку індустріальних методів і моделей з урахуванням особливостей і специфіки наукових задач. Ця індустрія теж базується на готових звичайних компонентах (артефактах, reuses, assets і даних) багаторазового використання, що знаходяться у різних бібліотеках, репозиторіях та нових «хмарних» сховищах Інтернету.
Головним методом індустрії наукових продуктів буде удосконалений метод зборки наукових різнорідних ресурсів, що належить до напрямів e–science в структури ПП, після виготовлення вони подаються на різні глобальні сервери для їх застосування.
Для хмарних обчислень основним припущенням є нерівномірність запиту ресурсів з боку клієнта. Для згладжування цієї нерівномірності в плані надання сервісу між реальним залізом і middleware розміщується ще один шар — віртуальний сервер, який виконує застосування шляхом віртуализації і балансування навантаженням засобами програмного забезпечення, так і засобами розподілу віртуальних серверів по реальних платформах і комп’ютерах.
Основна ідея Cloud Сomputing полягає у тому, що клієнт не повинен створювати свій обчислюючий центр і навчати персонал інсталяції прикладних програм і обслуговуванню системи. Ця технологія має деякі схожі риси з технологіями Grid, Utility computing і service computing (см. рис.4.5).

Існує 15 обчислювальних технологій в cloud computing. Це такі
Технологія зберігання даних – надання за запитом потрібного дискового простору для конкретного застосування. Цей ресурс може розташовуватися віддалено.
Технологія Баз даних – це надання віддаленого доступу до банків і баз даних. Для користувача це виглядає так, як якщо б база даних була розміщена локально.
Технологія інформації передбачає віддалений доступ до даних через інтерфейс типу API. Це можуть бути біржові дані, кредитна інформація, перевірка адрес іідентифікацій.
Технологія процесу (це може бути зокрема бізнес-процес) може відноситися до провайдерів програм, інфраструктури і платформи. Ця технологія належить до провай- дерів платформ, програм та інфраструктури.
Технологія застосування еквівалентна SaaS (Software as-a-Service) і являє собою будь-яку програму, наприклад, Salesforce SFA. Зазвичай мається на увазі робота через WEB-інтерфейс.
Технологія платформи – це комплексна послуга, що включає в себе розробку застосувань, інтерфейсів, баз даних, програм тестування, тощо.
Технологія інтеграції включає в себе програми, управління інформаційними потоками, прикладний дизайн і все, що присутнє в традиційній EAI-технології (Enterprise Application-Integration).
Технологія безпеки – це надання через Інтернет послуг безпеки. Хоча структура безпеки зазвичай будується локально, деякі послуги реалізуються віддалено, наприклад, ідентифікація та сертифікація, генерація, зберігання та передача ключів доступу. Зазвичай це атрибут архітектури.
Технологія управління – це сервіс віддаленого управління іншими cloud-сервісами, сюди входить віртуалізація, управління доступом, реалізація певних політик (наприклад, безпеки).
Технологія тестування – це надання можливості локального або віддаленого тестування різних видів сервісів, включаючи WEB-сервери.
Технологія інфраструктури – це фактично інформаційний центр в якості сервісу. Користувач отримує доступ до певного серверу (або серверів), його ОС і за стосунків.
Таким чином, Cloud computing – це парадигма розподіленого широкомаштабного комп’ютенгу, де набір абстрактних віртуалізованих, динамічно маштабованих, дистанційно керуючих машин, приладів пам’яті, платформ і сервісів надаються по запиту віддаленого користувача через Інтернет.

Рис.4.6. Види технологічних сервісів в Cloud computing
Індустрія даних.
Відповідно до закордоних коментарієвієв (http://lenta.ru/articles/2010/12/webservice) ринок сервісів для збереження даних онлайн через п’ять років стануть більш прозрачним, буде вбудований в продукти Microsofts з можливістю синхронізації даних за допомогою Windows Live Mech і передачі даних на віддаленні сервери. Cервіси SkyDriven і Mech можуть взаємодіяти зі хмарою в цілях вибору необхідного сервісу. Хмарне сховище є базисом при роботі сервісів. Користувачі зможуть мати різні обсяги даних з сховищ, а також створювати резервні копії даних. Поряд з таким механізмом доступу до хмарних даних зявляються нові безпроволочні технології типу WiMAX подібно безпроволочному Інтернету. Значні можливості дають веб-технології щодо збереження та доступу даних (Amazon, Flash, HTMLS, тощо).
Сервіс даних он-лайн сховищвключає:
– величезну кількість накопичених даних з новим видом доступу до них засобами Amazon, Flash, HTML5) з деякого місця планети,
– синхронізацію даних засобами Windows Live Mech, SkyDriven тощо,
– передачу даних на віддаленні сервери і резервування різних копій даних Office WebApps,
– використання нових веб- технологій (Flash, Silverlight, Amazon),
– композер завдань, робота з| БД (Windows Azure, MS SQL, Services, Live Services),
– бібліотеки примітивів з перетворення типів даних GDT<=>FDT із бібліотек.
В межах доступа до глобальних даних винікає проблема трансформації загальних типів даних, що пропонує стандарт ISO/IEC 11404 –2007, до фундаментальних типів даних, що з моменту появи МП сформувались для усіх мов. Проблема пере творння типів даних може бути вирішена через розроблення спеціальних примитівних функцій.
Бібліотека примітивів для перетворення типів даних GDT (примітивних, агрегатних і генерованих) до FDT типів даних (простих, структурних і складних) МП реалізується в проекті ІТК ІПС, як механізм трансформації не релевантних даних, що передаються між різномовними компонентами, підсистемами і проектами. Бібліотека складних типів даних GDT (контракт, портфель тощо) використовується для генерації простих типів даних FDT і накопичення у базі даних.
Бібліотеки функцій перебудови форматів нерелевантних даних інтерфейсних посередників (stub, skeleton), що передають їх на інші платформи взаємодіючим компонентам і зворотно практично є у всіх сучасних системах програмування..Ця бібліотека містить функції перетворення даних з оn-line сховищ з можливістю, які забезпечують їх віртуалізацію і синхронізацію [5].