

Протоколы рорз и imap
А теперь давайте, как мы и собирались, сравним два протокола доступа к почте: РОРЗ (Post Office Protocol v.3 — протокол почтового отделения версии 3) и IMAP (Internet Mail Access Protocol — протокол доступа к электронной почте Интернета). Оба эти протокола решают одну и ту же задачу — обеспечивают доступ пользователей к корреспонденции, хранящейся на почтовом сервере. В связи с многопользовательским характером работы почтового сервера оба протокола поддерживают аутентификацию пользователей на основе идентификаторов и паролей. Однако протоколы РОРЗ и IMAP имеют принципиальные различия, важнейшее из которых состоит в следующем. Получая доступ к почтовому серверу по протоколу РОРЗ, вы «перекачиваете» адресованные вам сообщения в память своего компьютера, при этом на сервере не остается никакого следа от считанной вами почты. Если же доступ осуществляется по протоколу IMAP, то в память вашего компьютера передаются только копии сообщений, хранящихся на почтовом сервере.
Это различие серьезно влияет на характер работы с электронной почтой. Сейчас очень распространенной является ситуация, когда человек в течение одного и того же периода времени использует несколько различных компьютеров: на постоянном месте работы, дома, в командировке. Теперь давайте представим, что произойдет с корреспонденцией пользователя Полины, если она получает доступ к почте по протоколу РОРЗ. Письма, прочитанные на работе, останутся в памяти ее рабочего компьютера. Придя домой, она уже не сможет прочитать их снова. Опросив почту дома, она получит все сообщения, которые поступили с момента последнего обращения к почтовому серверу, но из памяти сервера они исчезнут, и завтра на работе она, возможно, не обнаружит важные служебные сообщения, которые были загружены на диск ее домашнего ноутбука. Таким образом, получаемая Полиной корреспонденция будет «рассеяна» по всем компьютерам, которыми она пользовалась. Такой подход не позволяет рационально организовать почту: распределять письма по папкам, сортировать их по разным критериям, отслеживать состояние переписки, отмечать письма, на которые послан ответ, и письма, еще требующие ответа и т. д. Конечно, если пользователь всегда работает только с одним компьютером, недостатки протокола РОРЗ не являются столь критичными. Но и в этом случае проявляется еще один «дефект» этого протокола — клиент не может пропустить, не читая, ни одного письма, поступающего от сервера. То есть объемное и возможно совсем ненужное вам сообщение может надолго заблокировать вашу почту.
Протокол IMAP был разработан как ответ на эти проблемы. Предположим, что теперь Полина получает почту по протоколу IMAP. С какого компьютера она бы ни обратилась к почтовому серверу, ей будут переданы только копии запрошенных сообщений. Вся совокупность полученной корреспонденции останется в полной сохранности в памяти почтового сервера (если, конечно, не поступит специальной команды от пользователя об удалении того или иного письма). Такая схема доступа делает возможным для сервера предоставление широкого перечня услуг по рациональному ведению корреспонденции, то есть именно того, чего лишен пользователь при применении протокола РОРЗ. Важным преимуществом IMAP является также возможность предварительного чтения заголовка письма, после чего пользователь может принять решение о том, есть ли смысл получать с почтового сервера само письмо.
Веб-служба
Изобретение службы World Wide Web (WWW), или Всемирной паутины, стоит в одном ряду с изобретениями телефона, радио и телевидения. Благодаря WWW люди получили возможность доступа к нужной им информации в любое удобное для них время. Теперь проще найти интересующую вас статью в Интернете, чем в стопке журналов, хранящихся рядом в шкафу. Очень быстро исчезают многие традиционные приемы рациональной организации работы с информацией, заключающиеся, например, в хранении полезной информации в записных книжках, раскладывании вырезок из журналов и газет в картонные папки с веревочками, упорядочивании документов в каталогах путем наклеивания на них маркеров с условными кодами, помогающими быстро отыскать нужный документ и т. д. Этим приемам приходят на смену новые безбумажные технологии Интернета, среди которых важнейшей является сетевая служба WWW, или веб-служба. Заметим, что WWW не только предоставляет любому человеку возможность быстрого поиска нужных данных и доступа к ним, но и позволяет выносить на многомиллионную аудиторию пользователей
Интернета собственную информацию — мнения, художественные и публицистические произведения, результаты научной работы, объявления и т. д. Причем он может это делать без особых организационных забот и практически бесплатно.
Мы не будем долго останавливаться на описании всех возможностей этой службы, учитывая, что для большинства из нас регулярный просмотр веб-сайтов стал не просто обыденностью, а необходимым элементом жизненного уклада.
Веб- и HTML-страницы
Миллионы компьютеров, связанных через Интернет, хранят невообразимо огромные объемы информации, представленной в виде веб-страниц.
□ Веб-страница, или веб-документ, как правило, состоит из основного HTML-файла и некоторого количества ссылок на другие объекты разного типа: JPEG- и GIF-изображения, другие HTML-файлы, аудио- и видеофайлы.
□ HTML-файлом, HTML-страницей или гипертекстовой страницей называют файл, который содержит текст, написанный на языке HTML (HyperText Markup Language — язык разметки гипертекста).
История появления языка HTML связана с попытками программистов разработать средство, которое бы позволяло им программным путем создавать красиво сверстанные страницы для просмотра на экране. Другими словами, красивая картинка появляется на дисплее только в результате ее интерпретации специальной программой, а в исходном виде она представляет собой однообразный текст с множеством служебных пометок. Вместо применения различных приемов форматирования, таких как выделение заголовков крупным шрифтом, а важных выводов — курсивным или полужирным начертанием, создатель документа на языках этого типа просто вставляет в текст соответствующие указания о том, что данная часть текста должна быть выведена на экран в том или ином виде. Служебные пометки такого рода в исходном тексте выглядят, например, как <b> </Ь> (начать и закончить вывод текста полужирным начертанием) и называются тегами. Язык HTML не является первым языком разметки текста, его предшественники существовали задолго до появления веб-службы, например в первых версиях ОС Unix существовал язык troff (с помощью этого языка отформатированы страницы электронной документации Unix, известные как man-страницы).
В язык HTML включены разные типы тегов, команд и параметров, в том числе для вставки в текст изображений (тег <img s гс="...">). Чтобы HTML-страница выглядела так, как задумал программист, она должна быть выведена на экран специальной программой, способной интерпретировать язык HTML. Такой программой является уже упоминавшийся веб-браузер.
Существует особый тип тега, который имеет вид <а href ="..."> ...</а> и называется гиперссылкой. Гиперссылка содержит информацию о веб-странице или объекте, который может находиться как на том же компьютере, так и на других компьютерах Интернета. Отличие гиперссылки от других тегов состоит в том, что элемент, описываемый ею, не появляется автоматически на экране, вместо этого на месте тега (гиперссылки) на экран выводится некоторое условное изображение или особым образом выделенный текст — имя гиперссылки. Чтобы получить доступ к объекту, на который указывает эта гиперссылка, пользователь должен «щелкнуть» на ней, дав тем самым команду браузеру найти и вывести на экран требуемую страницу или объект. После того как новая веб-страница будет загружена, пользователь сможет перейти по следующей гиперссылке — такой «веб-серфинг» может продолжаться теоретически сколь угодно долго. Все это время веб-браузер будет находить указанные в гиперссылках страницы, интерпретировать все размещенные на них указания и выводить информацию на экран в том виде, в котором ее спроектировали разработчики этих страниц.
URL
Браузер находит веб-страницы и отдельные объекты по адресам специального формата, называемым URL (Uniform Resource Locator — унифицированный указатель ресурса). URL-адрес может выглядеть, например, так: http://www.olifer.co.uk/books/books.htm. В URL-адресе можно выделить три части:
□ Тип протокола доступа. Начальная часть URL (http://) указывает на то, какой протокол должен быть использован для доступа к данным, расположение которых определяется оставшейся частью URL. Помимо HTTP, здесь могут быть указаны и другие протоколы, такие как FTP, telnet, также позволяющие осуществлять удаленный доступ к файлам или компьютерам1.
□ DNS-имя сервера. Имя сервера, на котором хранится нужная страница. В нашем случае — это имя сайта www.olifer.co.uk.
□ Путь к объекту. Обычно это составное имя файла (объекта) относительно главного каталога веб-сервера, предлагаемого по умолчанию. В нашем случае путем к объекту является /books/books.htm. По расширению файла мы можем сделать вывод о том, что это HTML-файл.
Веб-клиент и веб-сервер
Как мы уже отмечали, сетевая веб-служба представляет собой распределенную программу, построенную в архитектуре клиент-сервер. Клиент и сервер веб-службы взаимодействуют друг с другом по протоколу HTTP.
Клиентская часть веб-службы, или веб-клиент, называемый также браузером, или агентом пользователя веб-службы, представляет собой приложение, которое устанавливается на компьютере конечного пользователя и одной из важных функций которого является поддержание графического пользовательского интерфейса.
Через этот интерфейс пользователь получает доступ к широкому набору услуг, главной из которых, конечно, является «веб-серфинг», включающий поиск и просмотр страниц, навигацию между уже просмотренными страницами, переход по закладкам и хранение истории посещений. Помимо средств просмотра и навигации, веб-браузер предоставляет пользователю возможность манипулирования страницами: сохранение их в файле на диске своего компьютера, вывод на печать, передача по электронной почте, контекстный поиск в пределах страницы, изменение кодировки и формата текста, а также множество других функций, связанных с представлением информации на экране и конфигурированием самого браузера.
К числу наиболее популярных сейчас браузеров можно отнести Internet Explorer компании Microsoft, Firefox компании Mozilla и последнее предложение компании Google — Chrome. Веб-браузер — это не единственный вид клиента, который может обращаться к веб-серверу. Эту роль могут исполнять любые программы и устройства, поддерживающие протокол HTTP, а также многие модели мобильных телефонов — для доступа в этом случае применяется специальный протокол WAP (Wireless Application Protocol — протокол беспроводных приложений).
Значительную часть своих функций браузер выполняет в тесной кооперации с веб-сервером. Как уже было сказано, клиент и сервер веб-службы связываются через сеть по протоколу HTTP. Это означает, что в клиентской части веб-службы присутствует клиентская часть HTTP, а в серверной — серверная часть HTTP.
Веб-сервер — это программа, хранящая объекты локально в каталогах компьютера, на котором она запущена, и обеспечивающая доступ к этим объектам по URL-адресам. Наиболее популярными веб-серверами сейчас являются Apache и Microsoft Internet Information Server.
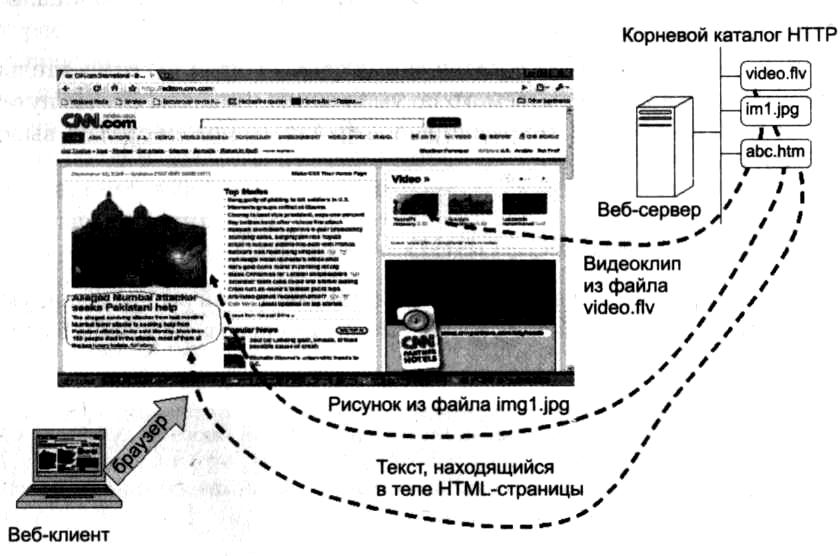
Рис. 23.4. Отображение веб-страницы
Как и любой другой сервер, веб-сервер должен быть постоянно в активном состоянии, прослушивая ТСР-порт 80, который является назначенным портом протокола HTTP. Как только сервер получает запрос от клиента, он устанавливает TCP-соединение и получает от клиента имя объекта, например, в виде /books/books.htm, после чего находит в своем каталоге этот файл, а также другие связанные с ним объекты и отсылает по ТСР-соединению клиенту. Получив объекты от сервера, веб-браузер отображает их на экране (рис. 23.4). После отправки всех объектов страницы клиенту сервер разрывает с ним ТСР-соединение. В дополнительные функции сервера входят также аутентификация клиента и проверка прав доступа данного клиента к данной странице.
Для повышения производительности некоторые веб-серверы прибегают к кэшированию наиболее часто используемых в последнее время страниц в своей памяти. Когда приходит запрос на какую-либо страницу, сервер, прежде чем считывать ее с диска, проверяет, не находится ли она в буферах более «быстрой» оперативной памяти. Кэширование страниц осуществляется и на стороне клиента, а также на промежуточных серверах (прокси-серверах). Кроме того, эффективность обмена данными с клиентом иногда повышают путем компрессии (сжатия) передаваемых страниц. Объем передаваемой информации уменьшают также за счет того, что клиенту передается не весь документ, а только та часть, которая была изменена. Все эти приемы повышения производительности веб-службы реализуются средствами протокола HTTP