

Задача классификации и её решение
2.1 Дискриминантный анализ
Рассмотрим процедуру проведения дискриминантного анализа в системе Statistica на примере решения задачи SonarAdstudy– имеется выборка, состоящая из 209 наблюдений и 7 переменных.

Переменные: зависимая – категории, независимая –переменная с данными. Выбираем метод – пошаговый с включением.
Заходим на вкладку «анализ» далее «многомерный разведочный анализ» выбираем дискриминантный анализ и получаем:

Итоги анализа дискриминантн. функций (Hurrdata) Шаг 3, Переменных в модели: 3; Группир.: CLASS (2 гр.) Лямбда Уилкса: ,47361 прибл. F (3,205)=75,949 p<0,0000 |
||||||
|
Уилкса |
Частная |
F-исключ |
p-уров. |
Толер. |
1-толер. |
LATHURR |
0,606831 |
0,780459 |
57,66586 |
0,000000 |
0,651478 |
0,348522 |
LONDEPR |
0,484602 |
0,977312 |
4,75896 |
0,030283 |
0,909354 |
0,090646 |
LATDEPR |
0,480086 |
0,986504 |
2,80454 |
0,095522 |
0,605744 |
0,394256 |
Из данной таблицы видно, что наибольший вклад в дискриминантый анализ вложили LATDEPR. Остальные считаются «вне модели». Общий итог представлен в матрице классификаций.
Матрица классификации (Hurrdata) Строки: наблюдаемые классы Столбцы: предсказанные классы |
|||
|
Процент |
BARO |
TROP |
BARO |
86,60714 |
97 |
15 |
TROP |
80,41237 |
19 |
78 |
Всего |
83,73206 |
116 |
93 |
По матрице классификаций можно сказать, что Общий % наблюдаемости составляет = 83%.
2.2 Классификация в нейронных сетях
Рассмотрим процедуру классификации, реализуемую с помощью нейронных сетей в системе Statistica.
Оценим ход проведения этого анализа, внедрив в совокупность «левую» переменную, не связанную с действующими данными (данные могут быть произвольны).
Выберем инструмент «Понижение размерности».
Задаем «переменные» и «входные -выходные»
Нажимаем ОК и получаем: На вкладке «Быстрый» установим метод последовательный с включением. На вкладке «генетический алгоритм» установим следующие значения : популяция =100; поколение =100; скорость мутаций = ,001; скорость скрещивания =1, На вкладке «Дополнительно»: доля =1; сглаживание=,1 ; штраф за элемент = ,001.

Нажимаем ОК:
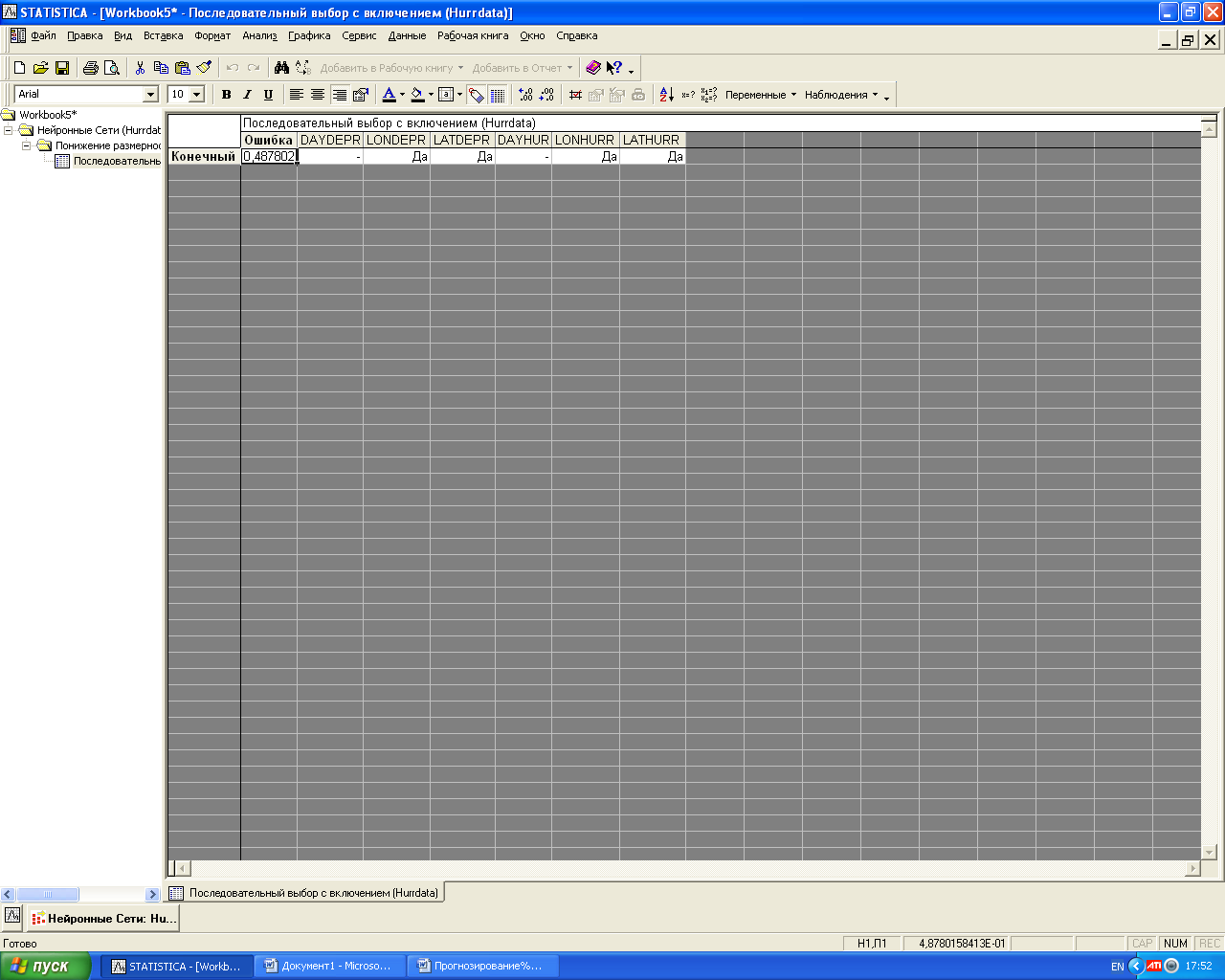
Согласно результатам наблюдения к модели нельзя относить DAYDEPR, DAYHUR их значения равны = 0. Ошибка =0,487802.
Теперь давайте посмотрим метод последовательный с исключением и посмотрим что получится:

Из таблицы мы видим, что наблюдения DAYDPR, DAYHUR, LONHURR в модель могут не включиться, так как их значения стремятся к 0. Ошибка в данном случае = 0,492675.
После исключения «лишних» переменных проведём непосредственно классификацию. Соответственно тип задачи «Классификация».
Из 15 лучших моделей лучшими обладают в нашем случае модели РБФ:


Используя инструмент «Конструктор сетей», можно внести необходимые корректировки в сеть. Результаты представлены ниже:
Классификация (13-15 ) (Hurrdata) |
||||||
|
CLASS.BARO.13 |
CLASS.TROP.13 |
CLASS.BARO.14 |
CLASS.TROP.14 |
CLASS.BARO.15 |
CLASS.TROP.15 |
Всего |
112,0000 |
97,00000 |
112,0000 |
97,00000 |
112,0000 |
97,00000 |
Правильно |
99,0000 |
86,00000 |
100,0000 |
87,00000 |
99,0000 |
86,00000 |
Ошибочно |
13,0000 |
11,00000 |
12,0000 |
10,00000 |
13,0000 |
11,00000 |
Неизвестно |
0,0000 |
0,00000 |
0,0000 |
0,00000 |
0,0000 |
0,00000 |
% правильных |
88,3929 |
88,65979 |
89,2857 |
89,69072 |
88,3929 |
88,65979 |
% ошибочных |
11,6071 |
11,34021 |
10,7143 |
10,30928 |
11,6071 |
11,34021 |
% неизвестно |
0,0000 |
0,00000 |
0,0000 |
0,00000 |
0,0000 |
0,00000 |
Из данной задачи можно сказать, что применение сетей в нашей задачи имеет большую продуктивность более 80% нежели при проведении дискриминантного анализа.