

Див. Також
№2
Стандарт Plug and Play.
Во второй половине 1995 года компания Microsoft выпустила в пользование законченную версию новой операционной системы Windows95 (рабочее название Chicago). Новые технологии этой системы позволили устранить многие недостатки имевшихся в то время РС и операционных систем и в частности - трудность аппаратной модернизации. Добавление акустической карты, дисковода CD ROM или даже модема ко вчерашнему РС может быть кошмарным процессом даже для знатоков РС или специалистов. Руководства обсуждают установку переключателей, IRQ, DMA и адреса устройств, как будто это бытовые термины. Что еще хуже, так это то, что нужно установить драйверы устройств, требующихся для DOS и WINDOWS. Новая технология Chicago - Plug and Play - позволяет программному обеспечению автоматически устанавливать конфигурацию аппаратных средств, когда вы ставите (или снимаете) адаптер в стационарный или портативный компьютер. К сожалению, вам может потребоваться новая Plug and Play - совместимая материнская плата (или, по крайней мере, новый чип BIOS) и новый набор Plug and Play-адаптеров для того, чтобы полностью использовать преимущества автоконфигурации. Plug and Play - это стандарт компьютерной индустрии для автоматизации процесса добавления новых возможностей к вашему компьютеру или изменения адаптеров PCMCIA в вашем портативном компьютере. Технология Plug and Play возникла в связи с историческими проблемами, связанными с установками звуковых карт на компьютеры, работавших под управлением DOS или Windows3. 1+; поддержка этой технологии гораздо важнее для тех, кто использует средства мультимедиа или играет в компьютерные игры, чем для любой другой категории пользователей. Компьютеры, поддерживающие технологию Plug and Play и оборудованные Plug and Play-адаптерами, не требуют файлов config. sys и autoexec. bat. Каждый раз, когда вы запускаете Chicago, операционная система проверяет, какие адаптеры и периферийное оборудование, такое как принтеры, видеоадаптеры, инсталлированы на вашем компьютере. Далее она присваивает каждой карте свои собственные параметры: прерывания (IRQ), канал прямого доступа к памяти (DMA) и адреса портов. Наконец, стартовый процесс загружает только те драйверы, которые поддерживают установленные аппаратные средства. Если вы имеете портативный компьютер с одним или более слотов PCMCIA, то технология Plug and Play предоставляет процесс, называемые горячей заменой. Если вы заменили сетевую карту PCMCIA на модем PCMCIA, то раздел Plug and Play операционной системы заметит эту замену, выгрузит драйвер сети и установит драйвер модема. Конечно, Chicago поддерживает адаптеры и другие унаследованные драйверы, которые не являются Plug and Play. Если такие устройства, как акустические карты с присоединенными дисководами CD ROM, требуют драйверы DOS и резидентные приложения DOS (terminate-and-resident - TSR) (например, mscdex. exe для CD ROM), то вам необходима соответствующая запись в config. w40 и autoexec. w40, заменителях config. sys и autoexec. bat. Когда вы устанавливаете Chicago, приложение Setup (установка) автоматически создаст эти записи. Если вы используете утилиты сжатия данных, такие как Stacker3. x, то Chicago добавляет необходимые записи в config. w40, и проблем с обработкой сжатых томов на диске возникать не должно.
Вероятно, наиболее важный вклад Chicago в мир компьютерных звуков и музыки поддержка технологий Plug and Play при установке карт аудиоадаптеров (звуковых карт). Если вам когда-либо удавалось успешно установить в компьютер обычный аудио адаптер, особенно если этот компьютер присоединен к сети и на нем установлены другие специализированные адаптеры, вы заслуживаете диплома квалифицированного техника: нахождение незанятых IRQ и портов ввода-вывода так, чтобы ваша звуковая карта не отключила какое-либо другое устройство, требует незаурядных дедуктивных способностей. Однако, для использования звуковых карт стандарта Plug and Play тоже есть препятствия: необходимо иметь новый компьютер (или хотя бы материнскую плату) с BIOS, ориентированной на Plug and Play (Plug and Play BIOS); кроме того, к моменту начала выпуска Windows95 можно было найти небольшое количество карт аудиоадаптеров, полностью совместимых со стандартом Plug and Play. Компания Creative Labs начала выпуск серии Sound Blaster, отвечающей Plug and Play и не имеющей никаких перемычек к моменту официального выпуска Windows95. Однако немногие из других изготовителей звуковых карт начали выпуск продукции, поддерживающей технологию Plug and Play, к этому моменту. Выпущенная в то время компанией Media Vision серия плат Pro Audio Spectrum (PAS) почти отвечает стандарту Plug and Play. По словам менеджера аудио- и видеопроизводства этой компании Глена Готтлиба (Glen Gottlieb) разрабатывая эти платы, фирма стремилась избавиться от перемычек, используемых большинством других звуковых плат для выбора IRQ и базовых адресов ввода-вывода. Изделия Media Vision PAS используют специальное программное обеспечение для установки IRQ и адресов ввода-вывода и запоминают эти установки во встроенной памяти. (На платах PAS с адаптером SCSI имеются только две перемычки; они используются для установки адреса SCSI, значение которого изредка бывает необходимо изменить. ) В Chicago имеются драйверы для всей гаммы продукции Media Vision, начиная с первой 8-разрядной платы Thunder Board и кончая современными платами PAS, которые могут обеспечивать дополнительно объемный (3-D) звук и табличный midi-синтез звука. Хотя эти карты с технической точки зрения не полностью совместимы с Plug and Play, тем не менее, они работают как полностью совместимые. Chicago идентифицирует наличие платы PAS и автоматически загружает соответствующий драйвер, а он, в свою очередь, производит нужные установки в карте так, чтобы она не конфликтовала с другими. Если бы вы хотели иметь хорошую звуковую карту, пригодную для использования в Windows95 в 1995 году, то лучший выбор - одна из плат Media Vision. В настоящее же время компьютерный рынок изобилует звуковыми картами различных фирм, поддерживающими Plug and Play.
Plug and Play обходится без переключателей и программ конфигурирования; вставляйте Plug and Play-адаптер, и Plug and Play-совместимый компьютер заработает с первого раза. Как только вы дважды щелкните по значку New Device (Новое устройство) в Control Panel (Панели управления), появиться окно New Device Installation Wizard (Мастера установки новых устройств). Для инсталлирования Plug and Play-устройства рекомендуется сначала выключить компьютер, а затем вставить соответствующую карту. Когда вы вновь запустите компьютер и если Chicago не сможет воспользоваться для этой карты ни одним из своих встроенных драйверов, то попросит вставить дискету изготовителя в дисковод А. Вам даже не надо читать руководство.
Стандарт Plug and Play является совместной разработкой Intel Corporation и Microsoft Corporation. Другие лидеры компьютерной индустрии, такие как Phoenix Technologies Limited, Compaq Computer Corporation, NEC Technologies, Toshiba Computer System Division также внесли свой вклад в разработку восьми спецификаций, которые составляют стандарт Plug and Play.
Chicago - первая операционная система, полностью поддерживающая стандарт Plug and Play, но в MS-DOS 5+, Windows3. 1+ и Windows NT 3. 5 вы также можете воспользоваться ограниченными возможностями Plug and Play.
По определению Microsoft, компьютерная система, удовлетворяющая стандарту Plug and Play, на которую можно ставить знак "Designed for Microsoft Windows95" должна иметь следующие три компонента:
Версия BIOS Plug and Play 1. 0а. Plug and Play BIOS содержит основные инструкции для определения устройств, необходимых для загрузки компьютера во время POST-процесса. Стандартный минимум устройств - это дисплей, клавиатура и диск для загрузки операционной системы, в данном случае жесткий диск для загрузки Chicago.
Операционная система Plug and Play. Chicago является первой операционной системой Plug and Play, но некоторая поддержка Plug and Play может быть получена в MS-DOS 5+ и Windows3. 1+. Возможно, Microsoft добавит Plug and Play в будущую версию Windows NT.
Аппаратные средства Plug and Play - это множество устройств компьютера, которые автоконфигурируемы операционной системой Plug and Play. Аппаратные средства Plug and Play обычно состоят из адаптеров или эквивалентных схем на материнской плате компьютера; однако принтеры, внешние модемы и другие устройства, связанные с последовательными (COM) и параллельными (LPT) портами компьютера, так же могут поддерживаться Plug and Play. Адаптеры PCI и MCA отвечают требованиям к аппаратным средствам Plug and Play. Адаптеры ISA и EISA требуют модификации для автоконфигурирования Plug and Play.
В начале 1995 года каждому производителю PC были предложены продукты, удовлетворяющие стандарту Plug and Play и имеющие знак "Designed for Microsoft Windows95". Простая замена чипа BIOS на материнской плате одним из тех, которые удовлетворяют Plug and Play спецификации 1. 0а, не делает собранный компьютер Plug and Play-совместимыми. Адаптеры, жесткие диски и CD ROM, как и другие компоненты системы, также должны подчиняться соответствующей спецификации Plug and Play. Ниже приводится восемь спецификаций, которые включают в себя стандарт Plug and Play.
Спецификация BIOS Plug and Play 1. 0а, разработанная Compaq, Phoenix Technologies и Intel. Это основной документ, определяющий, как работает Plug and Play.
Спецификация ISA Plug and Play 1. 0а, разработанная Microsoft и Intel. Цель спецификации ISA Plug and Play - определить, как не Plug and Play и Plug and Play-совместимыми карты могут сосуществовать на шине ISA и работать согласовано.
Спецификация SCSI Plug and Play 1. 0, разработанная Adaptec, AT&T Global Information Solution, Digital Equipment Corporation, Future Domain, Maxtor и Microsoft. SCSI 1. 0 спецификация определяет хост-адаптер SCSI. Дополнительная спецификация SCAM (SCSI Configured AutoMatically) определяет средства, при помощи которых отдельные устройства SCSI, такие как жесткие диски, поддерживают средства автоконфигурации, аналогичные Plug and Play.
Спецификация IDE Plug and Play.
Спецификация LPТ Plug and Play 1. 0, разработанная Microsoft, определяет метод, по которому устройства, связанные с параллельным портом идентифицируют себя в Plug and Play BIOS. Принтеры, модемы, сетевые адаптеры и параллельные порты адаптеров SCSI принадлежат к устройствам, определяемым Plug and Play спецификацией LPT. Если вы подсоедините Hewlett Packard LaserJet 4M к параллельному порту вашего компьютера, то Chicago найдет драйвер для принтера и автоматически его загрузит.
Спецификация COM Plug and Play 0. 94, разработанная Microsoft и Hayes Microcomputer Products, определяет как устройства, подключенные к последовательным портам, такие как мыши, модемы, принтеры и источники бесперебойного питания, идентифицируют себя. Обычно Chicago определяет тип установленных мыши и модема даже без идентификации Plug and Play. Спецификация АРМ Plug and Play 1. 1, разработанная Microsoft и Intel, обрабатывает АРМ (advanced power management - система управления питанием) для портативных компьютеров и энергетически критичных стационарных компьютеров. Спецификация интерфейса драйверов устройств Plug and Play для Microsoft Windows и MS-DOS 1. 0с, разработанная Microsoft, дает ограниченную поддержку Plug and Play для присваивания I/O, IRQ, DMA и областей памяти под DOS и Windows3. 1+.
В дополнение к спецификациям предыдущего списка спецификация ATAPI определяет процесс идентификации для Plug and Play совместимых CD-ROM, которые присоединяются к расширенному интерфейсу IDE, удовлетворяющего стандарту Plug and Play. Спецификация ESCD (Extended System Configuration Data) 1. 0 разработана для предоставления дополнительной информации об адаптерах ISA и EISA в Plug and Play BIOS.
Наиболее важным элементом системы Plug and Play компьютера является системный Plug and Play BIOS. Спецификация BIOS Plug and Play 1. 0а добавляет следующие три новых главных компонента к обычному BIOS:
Управление ресурсами обрабатывает основные системные ресурсы: память прямого доступа (DMA), запросы прерываний (IRQ), ввод/вывод (I/O) и адреса памяти. Эти системные ресурсы разделяются различными устройствами, что и приводит к конфликтам. Диспетчер ресурсов Plug and Play BIOS отвечает за конфигурирование загрузочных устройств на материнской плате, а также любых устройств Plug and Play.
Управление конфигурацией во время выполнения является новым для РС. Plug and Play BIOS включает в себя возможность реконфигурации устройств после загрузки операционной системы. Это средство особенно важно для портативных компьютеров с устройствами PCMCIA, которые можно заменять, не выключая компьютер. Ранее операционная система рассматривала все устройства, отмеченные BIOS, как статические; это требовало перезагрузки портативного компьютера после замены устройства PCMCIA.
Управление событием определяет во время работы компьютера, когда устройство удалено или добавлено к системе. Plug and Play BIOS 1. 0а предоставляет управление событием только для устройства PCMCIA портативных компьютеров, так как горячая замена адаптеров стационарных компьютеров не является безопасной. Управление событием связано с управление во время выполнения для реконфигурирования системы.
Phoenix Technologies, один из соавторов спецификации BIOS Plug and Play 1. 0, является независимым поставщиком системного программного обеспечения РС, BIOS ROM, BIOS утилит. По словам Альберта Сарье (Albert Sarie), главного менеджера по рынку высоких технологий Phoenix Technologies, Phoenix имеет 65% неохваченного рынка этих системных продуктов для РС. (Compaq и IBM разработали свой собственный BIOS). Сарье говорит, что все клиенты Phoenix Technologies планируют Plug and Play BIOS в своих линиях компьютеров. Единственные компьютеры, которые, в конечном счете, не могут воплотить технологию Plug and Play, - это сверхмощные системы, используемые в качестве сетевых файл-серверов и серверов приложений.
Если в вашем компьютере отсутствует чип BIOS ROM, который отвечает требованиям спецификации BIOS Plug and Play 1. 0а, то вы, возможно, не получите удовольствия от Plug and Play. Исключения возможны, если:
Ваш компьютер имеет флеш BIOS, который вы можете модернизировать с дискеты поставщика компьютера или материнской платы. Флеш BIOS является чипом NVRAM, который сохраняет инструкции BIOS при выключении питания.
Поставщик вашего компьютера предлагает набор для модернизации BIOS Plug and Play 1. 0а. В этом случае вы просто вынимаете существующий BIOS и ставите замену.
Если ваш поставщик ничего из этого не предлагает, то для получения выгоды от использования технологии Plug and Play вам необходимо заменить материнскую плату.
Когда вы включаете компьютер, соответствующий стандарту Plug and Play, то выполняются следующие 5 шагов:
Системный BIOS идентифицирует устройство на материнской плате (включая тип шины), а также внешние устройства, такие как диски, клавиатуру, видеодисплей и другие адаптеры.
Системный BIOS определяет требования ресурсов каждого устройства (IRQ, DMA, I/O и адреса памяти). Некоторые устройства не требуют всех этих четырех ресурсов. На этом шаге системный BIOS определяет, какие из устройств имеют фиксированные значения ресурсов, а какие являются устройствами Plug and Play, чьи значения ресурсов могут быть реконфигурированы.
Операционная система Chicago предоставляет ресурсы, остающиеся после размещения фиксированных ресурсов, каждому устройству Plug and Play. Если имеется несколько различных устройств, то может потребоваться много итераций процесса размещения ресурсов для исключения всех ресурсных конфликтов путем изменения ресурсных присваиваний устройства Plug and Play.
Chicago создает конечную системную конфигурацию и сохраняет данные размещения ресурсов для этой конфигурации в регистре (Registry).
Chicago отыскивает каталог CHICAGO\SYSTEMS\ для того, чтобы найти требуемые для устройства драйверы. Если драйвер устройства не найден, то появляется диалоговое окно с требованием поставить дискету изготовителя с драйвером в дисковод А. Chicago загружает драйвер в память и затем заканчивает начальные операции.
Ниже на рисунке показаны описанные выше шаги в виде простой блок-схемы. Хотя с виду процесс кажется несложным, но требует довольно много низкоуровневого кода BIOS и высокоуровневого программного кода для обеспечения технологии Plug and Play.
№3
RS-232 — интерфейс передачи информации между двумя устройствами на расстоянии до 15 метров. Информация передается по проводам цифровым сигналом с двумя уровнями напряжения. Логическому "0" соответствует положительное напряжение (от +5 до +15 В для передатчика), а логической "1" отрицательное (от -5 до -15 В для передатчика). Асинхронная передача данных осуществляется с фиксированной скоростью при самосинхронизации фронтом стартового бита.
Назначение
Интерфейс RS-232-C был разработан для простого применения, однозначно определяемого по его названию: «Интерфейс между терминальным оборудованием и связным оборудованием с обменом по последовательному двоичному коду».
Чаще всего используется в промышленном и узкоспециальном оборудовании, встраиваемых устройствах. Присутствует на несколько устаревших стационарных персональных компьютерах, в современных чаще всего доступен через дополнительный контроллер/преобразователь (как правило, RS-232 не ставят на портативных компьютерах - на ноутбуках, нетбуках, КПК и т. п.).
[править]
Принцип работы
По структуре это обычный асинхронный последовательный протокол, то есть передающая сторона по очереди выдает в линию 0 и 1, а принимающая отслеживает их и запоминает.
Данные передаются пакетами по одному байту (обычно 8 бит).
Вначале передаётся стартовый бит, противоположной полярности состоянию незанятой (idle) линии, после чего передаётся непосредственно кадр полезной информации, от 5 до 8 бит.
Увидев стартовый бит, приемник выжидает интервал T1 и считывает первый бит, потом через интервалы T2 считывает остальные информационные биты. Последний бит — стоповый бит (состояние незанятой линии), говорящий о том, что передача завершена. Возможно 1, 1,5 или 2 стоповых бита.
В конце байта, перед стоп битом, может передаваться бит чётности (parity bit) для контроля качества передачи. Он позволяет выявить ошибку в нечетное число бит (используется, так как наиболее вероятна ошибка в 1 бит).
[править]
Соединители
Основная статья: Сигналы последовательных портов
Устройства для связи по последовательному каналу соединяются кабелями с 9-ю или 25-ю контактными разъёмами типа D-sub. Обычно они обозначаются DE-9 (или некорректно: DB-9), DB-25, CANNON 9, CANNON 25.
Первоначально в RS-232 использовались DB-25, но, поскольку многие приложения использовали лишь часть предусмотренных стандартом контактов, стало возможно применять для этих целей 9-штырьковые разъёмы DE-9 (D-subminiature), которые рекомендованы стандартом RS-574.
Номера основного передающего и принимающего данные контакта для разъемов DE-9 и DB-25 разные! Для DE-9 контакт 2 - вход приемника, контакт 3 - выход передатчика. Для DB-25 наоборот, контакт 2 - выход передатчика, контакт 3 - вход приемника.
[править]
Стандарт
Ассоциация электронной промышленности (EIA) развивает стандарты по передаче данных. Стандарты EIA имеют префикс «RS». «RS» означает рекомендуемый стандарт, но сейчас стандарты просто обозначаются как «EIA» стандарты. RS-232 был введён в 1962 году. Стандарт развивался, и в 1969 г.. представлена третья редакция (RS-232C). Четвёртая редакция была в 1987 (RS-232D, известная также под EIA-232D). RS-232 идентичен стандартам МККТТ (CCITT) V.24/V.28, X.20bis/X.21bis и ISO IS2110. Самой последней модификацией является модификация «Е», принятая в июле 1991 г. как стандарт EIA/TIA-232E. В данном варианте нет никаких технических изменений, которые могли бы привести к проблемам совместимости с предыдущими вариантами этого стандарта.
[править]
Ограничения
На практике, в зависимости от качества применяемого кабеля, требуемое расстояние передачи данных в 15 метров может не достигаться, составляя, к примеру, порядка 1,5 м на скорости 115200 бод для неэкранированного плоского или круглого кабеля. Для преодоления этого ограничения, а также возможного получения гальванической развязки между узлами, можно применить преобразователи RS-232—RS-422 (с сохранением полной программной совместимости) или RS-232—RS-485 (с определёнными программными ограничениями). При этом расстояние может быть увеличено до 1 км на скорости 9600 бод и использовании кабеля типа «витая пара» категории 3.
БІЛЕТ № 26
№1
В функцiональному та структурному вiдношеннi операцiйний пристрiй подiляється на двi частини: операцiйний та керуючий автомати. Операцiйний автомат ОА служить для збереження слiв iнформацiї, виконання набору мiкрооперацiй i обчислення значень логiчних умов, тобто операцiйний автомат є структурою, органiзованою для виконання дiй над iнформацiєю. Мiкрооперацiї, що реалiзуються операцiйним автоматом, iнiцiюються множиною керуючих сигналiв Y=[y(1),...,y(m)], з кожним iз них ототожнюється визначена мiкрооперацiя. Значення логiчних умов, якi обчислюються в операцiйному автоматi, вiдображаються множиною освiдомлюючих сигналiв X=[x(1),...,x(l)], кожний з яких ототожнюється з визначеною логiчною умовою. Керуючий автомат КА генерує послiдовнiсть керуючих сигналiв, визначену мiкропрограмою, яка вiдповiдає значенням логiчних умов. Іншими словами, керуючий автомат задає порядок виконання дiй в операцiйному автоматi, що зрозумiло з алгоритму виконання операцiй. Найменування операцiї, яку необхiдно виконати в пристрої, визначається кодом g операцiї. По вiдношенню до керуючого автомату сигнали g(1),...,g(h), за допомогою яких кодується найменування операцiї, i освiдомлюючi сигнали x(1),...,x(l), що формуються в операцiйному автоматi, грають однакову роль: вони впливають на порядок утворення робочих сигналiвY. Тому сигнали g(1),...,g(h) i x(1),...,x(l) вiдносяться до одного класу - класу освiдомлюючих сигналiв, що iдуть на вхiд управляючого автомату.
Таким чином, будь-який операцiйний пристрiй - процессор, канал вводу-виводу, пристрiй управлiння зовнiшнiм пристроєм - є композицiєю операцiйного та керуючого автоматiв. Операцiйний автомат, реалiзовуючи дiї над словами iнформацiї, є виконавчою частиною пристрою, роботою якого управляє керуючий автомат, генеруючий необхiднi послiдовностi управляючих сигналiв.
На даному етапi розгляду питання операцiйний та керуючий автомати можуть бути визначенi своїми функцiями - списком дiй, що ним виконується, виходячи iз яких в подальшому буде визначена структура автоматiв.
Функцiя операцiйного автомату визначається слiдуючою єднiстю вiдомостей:
Множиною вхiдних слiв d={d(1),...,d(H)}, що вводиться в автомат в якостi операндiв.
Множиною вихiдних слiв R={r(1),...,r(Q)}, що представляє результати операцiй.
Множиною мiкрооперацiй Y={y(m)}, m=1,...,M, реалiзуючих перетворення S={f(m)}(S) над словами iнформацiї, де f(m) - шукана функцiя.
Таким чином, функцiя операцiйного автомату задана, якщо визначенi множини D,R,S,Y,X. Час не є аргументом функцiї операцiйного автомату. Функцiя встановлює список дiй - мiкрооперацiй i логiчних умов,- якi може виконувати автомат, але нiяк не визначає порядок слiдування цих дiй у часi. Iнакше кажучи, функцiя операцiйного автомату характеризує засоби, якi можуть бути використанi для обчислень, але не сам обчислювальний процес. Порядок виконання дiй у часi визначається у формi функцiй управляючого автомату.
1.2.2 Структурна схема операційного автомату
В загальному випадку операційний пристрій будується по схемі.
Операційний автомат ОА розділяється на три частини: пам'ять S; комбінаційну схему Ф, яка реалізує мікрооперації; комбінаційну схему ψ, яка обчислює значення логічних умов. Пам’ять S забезпечує збереження слів s1,…sN, які представляють значення операндів D, проміжкові значення і кінцеві результати R. Для виконання мікрооперацій Y={ ym} служить комбінаційна схема Ф. Керуючі сигнали Y, що формуються управляючим автоматом УА, ініціюють виконання необхідних мікрооперацій. Так, якщо надходять сигнали ym1 і ym2, то схема Ф виконує дві мікрооперації що зводиться до обчислення значень і присвоєння їх словам . Для обчислення значень логічних умов служить комбінаційна схема ψ, що реалізує систему булевих функцій , значення яких представляються інформаційними сигналами X={xl}.
№2
Компонентний склад ОС визначається набором функцій, для виконання яких вона призначена. Усі її програми можна поділити на дві групи: керуюча програма та системні обробляючі програми.
Керуюча програма – обов’язковий компонент будь-якої ОС. Її функції – планування проходження безперервного потоку завдань, управління розподілом ресурсів, реалізація прийнятих методів організації даних, управління операціями вводу-виводу, організація мультипрограмної роботи, управління працездатністю системи після збоїв та інші.
Керуюча програма скуладається з ряду компонентів, серед яких слід виділити чотири основних:
управління статичними ресурсами (управління завданнями);
управління динамічними ресурсами (управління задачами);
управліня данними;
управління поновленням.
Управління статичними ресурсами (управління завданнями) виконує попереднє планування потоку завдань для виконання і статичний розподіл ресурсів між завданнями, що одночасно виконуються у процесі підготовки до виконання. До таких ресурсів відносяться розподіл пам’яті (основної, віртуальної, зовнішньої), доступні для використання завданням прострої, які припускають тільки монопольне використання, набори даних та інші. Такі ресурси закріплюються за завданням або його частиною з моменту його ініціалізації до моменту завершення та використовуються у монопольному режимі.
Управління динамцічними ресурсами (управління задачами) виконує динамічний розподіл ресурсів системи між декількома задачами, які вирішуються одночасно, у мультипрограмному режимі. Ці функції виконують програми супервізора, які входять до ядра ОС, що постійно знаходиться у оперативній пам’яті.
Управління даними забезпечує всі операції вводу-виводу (обміну між оперативною пам’яттю та периферійними пристроями) на фізичному та логічному рінях. Воно містить у собі ряд служб, які забезпечують виконання таких функцій, як управління каталогом, управління розподілом пам’яті прямого доступу, обробку помилок вводу-виводу та таке інше. Вони реалізують різні структури даних та можливість доступу до них.
Управління поновленням реєструє машинні збої та відмови, і поновлює працездатність системи після збоїв, якщо це можливо.
Системні обробляючи програми виконуються під управлінням керуючої програми, так саме, як і будь-яка обробляюча програма. Це значить, що вона у повному обсязі може користуватися послугами керуючої програми і не може самостійно виконувати системні функції. Так, наприклад, обробляюча програма не може самостійно виконувати власний ввод-вивід. Операції вводу-виводу обробляюча програма реалізує за допомогою запитів до керуючої програми, яка їх безпосередньо виконує. Централізоване виконання системних функцій керуючою програмою дозволяє виконувати їх більш ефективно та забезпечує високий рівень послуг для користувача.
До системних обробляючих програм відносяться програми, які входять у склад ОС: асемблери, транслятори, редактори зв’язків, програми обслуговування та інші.
Розподіл адресного простору
Не слід думати, що терміни "адресний простір" і "оперативна пам'ять" еквівалентні. Адресний простір - це просто набір адрес, які уміє формувати процесор; зовсім не обов'язково всі ці адреси відповідають реально існуючим елементам пам'яті. Залежно від модифікації персонального комп'ютера і складу його периферійного устаткування, розподіл адресного простору може декілька розрізнятися. Проте, розміщення основних компонентів системи задоволене строго уніфіковано. Типова схема використання адресного простору комп'ютера приведена на мал. 1.5. Значення адрес на цьому малюнку, як і всюди далі в книзі, дані в шістнадцятиричній системі числення.
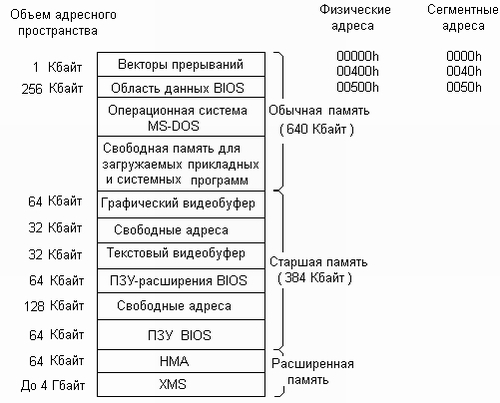
Мал. 1.5. Типовий розподіл адресного простору.
Перші 640 Кбайт адресного простору з адресами від 00000h до 9FFFF11 (і, відповідно, з сегментними адресами від 0000h до 9fffh) відводяться під основну оперативну пам'ять, яку ще називають стандартною (conventional). Початковий кілобайт оперативної пам'яті зайнятий векторами переривань, які забезпечують роботу системи переривань комп'ютера, і включає 256 векторів по 4 байти кожен. Услід за векторами переривань розташовується так звана область даних BIOS, яка займає всього 256 байт, починаючи з сегментної адреси 40h. Сама BIOS (від Basic In-out System, базова система введення-виводу) є частиною операційної системи, що зберігається в постійному пристрої, що запам'ятовує. Це пристрій (ПЗП BIOS), що запам'ятовує, розташовується на системній платі комп'ютера і є, таким чином, прикладом вбудованого, або "зашитого" програмного забезпечення. У функції BIOS входить тестування комп'ютера при його включенні, завантаження в оперативну пам'ять власне операційної системи MS-DOS, що зберігається на магнітних дисках, а також управління штатною апаратурою комп'ютера - клавіатурою, екраном, дисками і іншим. В області даних BIOS зберігаються різноманітні дані, використовувані програмами BIOS в своїй роботі. Так, тут розміщуються:
вхідний буфер клавіатури, куди поступають коди клавіш, що натискаються користувачем;
адреси відеоадаптера, а також послідовних і паралельних портів;
дані, що характеризують поточний стан відеосистеми (форма курсора і його поточне положення на екрані, відеорежим, використовувана відеосторінка і інш.);
осередки для відліку поточного часу і так далі
Область даних BIOS заповнюється інформацією в процесі початкового завантаження комп'ютера, а потім динамічно модифікується системою в міру необхідності. Багато прикладних програм, особливо, написано на мові асемблера, звертаються до цієї області з метою читання або модифікації тих, що містяться в них даних. З деякими осередками області даних BIOS ми зіткнемося при розгляді прикладів конкретних програм. В області пам'яті, починаючи з адреси 500h, розташовується власне операційна система MS-DOS, яка зазвичай займає декілька десятків Кбайт. Програми MS-DOS, як і інші системні складові (вектори переривань, область даних BIOS) записуються в пам'ять автоматично в процесі початкового завантаження комп'ютера. Вся пам'ять, що залишилася, до межі 640 Кбайт вільна для завантаження будь-яких системних або прикладних програм. Як правило, на початку сеансу в пам'ять завантажують резидентні програми (русифікатор, антивірусні програми). За наявності резидентних програм об'єм вільної пам'яті зменшується. Що залишилися 384 Кбайт адресного простору між межами 640 Кбайт і 1 Мбайт, звані старшою, або верхньою (upper) пам'яттю, спочатку були призначені для розміщення постійних пристроїв, що запам'ятовують (ПЗП). Практично під ПЗП зайнята тільки невелика частина адрес, а останні використовуються в інших цілях. Частина адресного простору старшої пам'яті відводиться для адресації до графічного і текстового відеобуферів графічного адаптера. Графічний адаптер є окремою мікросхемою або навіть окремою платою, до складу якої входить власний пристрій, що запам'ятовує (відеопам'ять). Це пристрій, що запам'ятовує, не має ніякого відношення до оперативної пам'яті комп'ютера, проте, його схеми управління налаштовані на діапазони адрес A0000h...AFFFFh і B8000h...BFFFFh, що входять в загальний з пам'яттю адресний простір процесора. Тому будь-яка програма може звернутися по цих адресах і, наприклад, записати дані у відеобуфер, що приведе до появи на екрані деякого зображення. Белі відеосистема знаходиться в текстовому режимі, а запис здійснюється по адресах текстового відеобуфера, на екрані з'являться зображення тих або інших символів (букв, цифр, різних знаків). Якщо ж перевести відеосистему в графічний режим, і записувати дані в графічний відеобуфер, то на екрані з'являться окремі крапки або лінії. Можна також прочитати поточний вміст осередків відеобуфера. В самому кінці адресного простору, в області адрес F0000h...FFFFFh, розташовується ПЗП BIOS - постійний пристрій, що запам'ятовує, про який вже мовилося вище. Частина адресного простору, починаючи з адреси C0000h, відводиться ще під один ПЗП - так званий ПЗП розширень BIOS для обслуговування графічних адаптерів і дисків. До складу комп'ютера, разом із стандартною пам'яттю (640 Кбайт), входить ще розширена (extended) пам'ять, максимальний об'єм якої може доходити до 4 Гбайт. Ця пам'ять розташовується за межами першого мегабайта адресного простору і починається з адреси 100000h. Реально на машині може бути встановлений не повний об'єм розширеної пам'яті, а лише декілька десятків Мбайт або навіть менше. Оскільки функціонування розширеної пам'яті підкоряється "специфікації розширеної пам'яті" (Extended Memory Specification, скорочено XMS), то і саму пам'ять часто називають XMS-памятью. Як вже наголошувалося вище, доступ до розширеної пам'яті здійснюється в захищеному режимі, тому для MS-DOS, що працює тільки в реальному режимі, розширена пам'ять недоступна. Проте в сучасні версії MS-DOS включається драйвер HIMEM.SYS, що підтримує розширену пам'ять, тобто що дозволяє її використовувати, хоча і обмеженим чином. Конкретно в розширеній пам'яті можна розмістити електронні диски (за допомогою драйвера RAMDRIVE.SYS) або дискові кеш-буфери (за допомогою драйвера SMARTDRV.SYS). Перші 64 Кбайт розширеної пам'яті, точніше, 64 Кбайт - 16 байт з адресами від l00000h до l0ffefh, носять спеціальну назву область старшої пам'яті (High Memoryarea, HMA). Ця область чудова тим, що хоча вона знаходиться за межами першого мегабайта, до неї можна звернутися в реальному режимі роботи мікропроцесора, якщо визначити сегмент, що починається в самому кінці мегабайтного адресного простору, з сегментної адреси Ffffh, і вирішити використання адресної лінії А20. Перші 16 байт цього сегменту зайняті ПЗП, область же із зсувами 0010h. ..FFFFh можна в принципі використовувати під програми і дані. MS-DOS дозволяє завантажувати в НМЛ (директивою файлу CONFIG.SYS Dos= high) значну частину самій себе, внаслідок чого зайнята системою область стандартної пам'яті істотно зменшується. Старшу пам'ять обслуговує той же драйвер HIMEM.SYS, тому завантаження DOS в НМЛ можливе, тільки якщо встановлений драйвер HIMEM.SYS. Як видно з приведеного вище малюнка, частина адресного простору верхньої пам'яті, не зайнята розширеннями BIOS і відеобуферами, виявляється вільною. Ці вільні ділянки можна використовувати для адресації до розширеної пам'яті (звичайно, не до всієї, а лише до тієї її частині, об'єм якої збігається із загальним об'ємом вільних адрес старшої пам'яті). Відображення розширеної пам'яті на вільні адреси старшої пам'яті виконує драйвер Emm386.EXE, а самі ділянки старшої пам'яті, "заповнені" розширеною, називаються блоками верхньої пам'яті (Upper Memory B10cks, UMB). MS-DOS дозволяє завантажувати в UMB встановлювані драйвери пристроїв, а також резидентні програми. Завантаження системних програм в UMB звільняє від них стандартну пам'ять, збільшуючи її транзитну область. Завантаження в UMB драйверів здійснюється директивою файлу CONFIG.SYS DEVICEHIGH (замість директиви DEVICE), а завантаження резидентних програм - командою DOS 10adhigh. На оптимально конфігурованому комп'ютері системними компонентами зайняті лише близько 20...25 Кбайт основної пам'яті, а решта всієї пам'яті в об'ємі близько 620 Кбайт може використовуватися для завантаження прикладних програм.
№3
хDSL (англ. digital subscriber line, цифровая абонентская линия) — семейство технологий, позволяющих значительно повысить пропускную способность абонентской линии телефонной сети общего пользования путём использования эффективных линейных кодов и адаптивных методов коррекции искажений линии на основе современных достижений микроэлектроники и методов цифровой обработки сигнала.
Технологии хDSL появились в середине 90-х годов как альтернатива цифровому абонентскому окончанию ISDN.
В аббревиатуре xDSL символ «х» используется для обозначения первого символа в названии конкретной технологии, а DSL обозначает цифровую абонентскую линию DSL (англ. Digital Subscriber Line — цифровая абонентская линия; также есть другой вариант названия — Digital Subscriber Loop — цифровой абонентский шлейф). Технологии хDSL позволяют передавать данные со скоростями, значительно превышающими те скорости, которые доступны даже самым лучшим аналоговым и цифровым модемам. Эти технологии поддерживают передачу голоса, высокоскоростную передачу данных и видеосигналов, создавая при этом значительные преимущества как для абонентов, так и для провайдеров. Многие технологии хDSL позволяют совмещать высокоскоростную передачу данных и передачу голоса по одной и той же медной паре. Существующие типы технологий хDSL различаются в основном по используемой форме модуляции и скорости передачи данных.
Службы xDSL разрабатывались для достижения определенных целей: они должны работать на существующих телефонных линиях, они не должны мешать работе различной аппаратуры абонента, такой как телефонный аппарат, факс и т. д., скорость работы должна быть выше теоретического предела в 56Кбит/сек., и наконец, они должны обеспечивать постоянное подключение. Широкое распространение технологий хDSL должно сопровождаться некоторой перестройкой работы поставщиков услуг Интернета и поставщиков услуг телефонных сетей, так как их оборудование теперь должно работать совместно. Возможен также вариант, когда альтернативный оператор связи берёт оптом в аренду большое количество абонентских окончаний у традиционного местного оператора или же арендует некоторое количество модемов в DSLAM.
К основным типам xDSL относятся ADSL, HDSL, IDSL, MSDSL, PDSL, RADSL, SDSL, SHDSL, UADSL, VDSL. Все эти технологии обеспечивают высокоскоростной цифровой доступ по абонентской телефонной линии. Некоторые технологии xDSL являются оригинальными разработками, другие представляют собой просто теоретические модели, в то время как третьи уже стали широко используемыми стандартами. Основным различием данных технологий являются методы модуляции, используемые для кодирования данных.
Методы кодирования
Технологии xDSL поддерживают несколько вариантов кодирования информации:
2B1Q: Two-binary, one-quaternary, используется для IDSL и HDSL
CAP: Carrierless Amplitude Phase Modulation - используется для HDSL
DMT: Discrete multitone modulation, наиболее распространенный метод, известен также как OFDM (Orthogonal frequency-division multiplexing)
Достижения технологий xDSL во многом определяются достижениями техники кодирования, которая за счет применения процессоров DSP (Цифровой сигнальный процессор) смогла повысить скорость передачи данных при одновременном увеличении расстояния между модемом и оборудованием DSLAM.
Преимущества xDSL перед ISDN
Широкое применение доступа через xDSL имеет ряд преимуществ по сравнению с технологией ISDN. Пользователь получает интегрированное обслуживание двух сетей – телефонной и компьютерной. Но для пользователя наличие двух сетей оказывается незаметным, для него только ясно, что он может одновременно пользоваться обычным телефоном и подключенным к Интернету компьютером. Скорость же компьютерного доступа при этом превосходит возможности интерфейса PRI сети ISDN при существенно более низкой стоимости, определяемой низкой стоимостью инфраструктуры.
БІЛЕТ № 27
№1
Детермiнованi методи доступу
Метод вставляння регiстра. Цей метод застосовується в кiльцевих мережах. Принцип його роботи полягає в тому, що коли деяка станцiя має iнформацiю, яку треба вiдправити, вона вмiщує її у зсувовий регiстр. Цей регiстр може бути послiдовно ввімкнений у канал. Тодi данi з одного кiнця будуть надходити до регiстра i, рухаючись через нього, виходити з протилежного кiнця регiстра. Регiстр пiдмикається послiдовно до решти кiльця, якщо створиться придатний для цього промiжок мiж iншими пакетами, що циркулюють кiльцем. Регiстр лишається ввімкненим у кiльце, i усi пакети рухаються через нього. Коли пакет, який був спершу переданий цим пристроєм, повертається до нього i повнiстю завантажується до регiстра, регiстр вiдмикається вiд кiльця. Принцип роботи регiстра досить простий, проте практично реалiзувати цей метод складно. Адже потiк даних, що рухаються кiльцем, не можна зупиняти, i потрiбна адекватна та висока швидкiсть, з якою регiстр вмикається в кiльце i вимикається з нього, тобто потрiбний високий рiвень синхронiзацiї. Станцiя, яка є приймачем пакета, має прочитати данi та виставити прапорець — сигнал, що данi прийнято. Реальніший варiант вставляння регiстра грунтується на тому, що використовуються два регiстри: один для передавання, другий — для приймання. Якщо станцiя має пакет даних, призначений для передавання, вона розмiщує цей пакет у передавальний регiстр Т. Тiльки-но з’являється придатний промiжок мiж двома пакетами, що проходять кiльцем один за одним, перемикач пiдмикає передавальний регiстр i його вмiст передається в кiльце. Оскiльки потiк даних, що йде вiд попереднього пристрою, не можна зупинити, то вони заносяться у зсувовий приймальний регiстр R. Тiльки-но зсувовий передавальний регiстр Т буде порожнiм, перемикач перекидається на приймальний регiстр R, а сам пристрiй чекає повернення щойно переданого пакета. Можливо, цей пакет повернеться i буде розмiщений у зсувовий приймальний регiстр R, який пiсля цього вимикається з кiльця.
У наведених схемах пакет здiйснює повний цикл кiльцем, перш нiж його буде виведено з нього. Розглянемо iнше розв’язання. У запропонованiй схемi пакет вилучається з кiльця станцiєю, для якої вiн призначений. У
попереднiй схемi це здiйснити важко, бо там передавальна станцiя має
регiстр, що послiдовно вставлений у кiльце, i для його відімкнення
необхiдно, щоб надiсланий пакет повернувся назад. А в останнiй системi використовуються три регiстри (передавальний, приймальний та буферний), два перемикачi (припустимо, A та B) та один генератор, який утворює «холостi» символи, що не несуть жодної iнформацiї. Система працює так. У кiльце вмикається послiдовно буферний регiстр iз затримкою. Цей регiстр має рухомий вказiвник. На початку робочого циклу буферний
регiстр порожнiй, а вказiвник перебуває у крайньому лiвому положеннi (на нульовiй позначці). Данi, що циркулюють кiльцем, обминають буферний регiстр. Коли станцiя має пакет даних для передавання, вона завантажує цей пакет у передавальний регiстр. При появi промiжку мiж пакетами, що проходять кiльцем, перемикач В перекидається на передавальний регiстр, пiсля чого його вмiст передається кiльцем. У цей момент данi, що з’являються на входi, заносяться у буферний регiстр iз затримкою (зсувовий регiстр), а вказiвник проходить до позначки кiнця даних. Коли данi складаються з «холостих» символiв, що не несуть жодної iнформацiї, то вони в буферному регiстрi не зберiгаються, а вказiвник знову змiщується до нульової позначки. Якщо передавальний регiстр порожнiй, перемикач перекидається на буферний регiстр iз затримкою, а вказiвник припиняє
перемiщення. Станцiя, якiй призначено iнформацiю, розпiзнає пакет за заголовком та перекидає перемикач A на приймальний регiстр. Данi, що
надiйшли до входу, зчитуються в цей регiстр, а наприкiнцi пакета перемикач A знову пiдмикається до входу буферного регiстра iз затримкою. Доки пакет зчитується у приймальний регiстр, кiльце продовжує працювати за рахунок буферного регiстра iз затримкою або генератора «холостих»
символiв, який продовжує їх надсилати. Поки покажчик у буферному
регiстрi перебуває на нульовiй позначці, через перемикач B проходять «холостi» символи генератора. Коли повернувся пакет, який станцiя передала ранiше, це означає, що пакет з якоїсь причини не був прочитаний станцiєю-приймачем. Якщо пакет вилучено з кiльця, це означає: станцiя, для якої його було призначено, зчитала його у приймальний регiстр. Для обробки пакетiв, в яких при передаваннi можуть виникнути помилки, потрiбнi додатковi, вищі рiвнi протоколiв. Цей метод було використано у ранньому варiантi ЛОМ Cambrige Ring.
Метод тактованого доступу. Метод використовується в кiльцевiй топологiї. Робота кiльця з тактованим доступом не потребує використання зсувових регiстрiв та високошвидкiсних перемикачiв у повторювачах і станцiях, якi пiдімкнено до кiльця. Один чи кiлька контейнерних пакетiв або тактiв безперервно курсують кiльцем. Їх кiлькiсть нiколи не змiнюється i визначається довжиною такту, загальною довжиною кiльця та процедурою початкового запуску кiльця. Якщо кiльце дуже коротке, то використовуванi такти мають бути також короткими, а їх кiлькiсть не може бути великою, оскільки доведеться вставляти в кiльце буфер iз затримкою. Це пояснюється тим, що початок такту може повернутися до передавача ранiше, нiж той закінчить передавання кiнця даного пакета. З цiєї причини у багатьох практичних реалiзацiях розглянутого методу застосовується лише один короткий такт та буфер iз затримкою. У момент запуску кiльця один з повторювачiв або одна зi станцiй формує такт i вiдправляє його кiльцем. Коли вiн повернеться до передавача, це означатиме, що кiльце замкнене i можна розпочинати роботу. Структура такту:
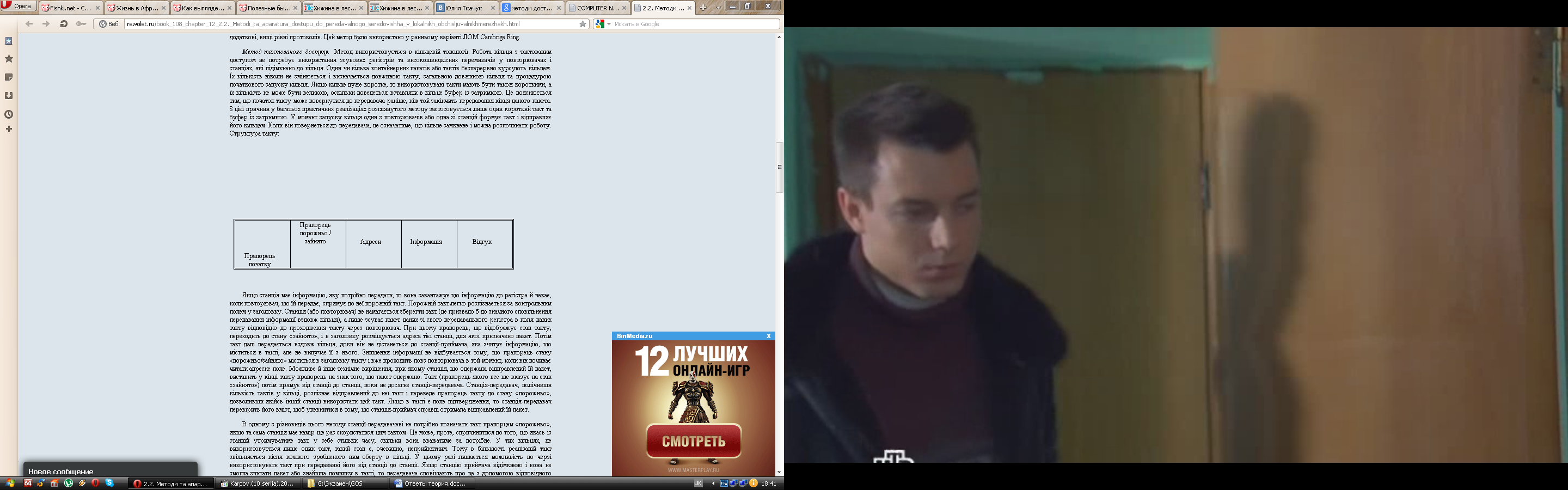
Якщо станцiя має iнформацiю, яку потрібно передати, то вона завантажує цю iнформацiю до регiстра й чекає, коли повторювач, що їй передає, спрямує до неї порожнiй такт. Порожнiй такт легко розпiзнається за контрольним полем у заголовку. Станцiя (або повторювач) не намагається зберегти такт (це призвело б до значного сповiльнення передавання iнформацiї вздовж кiльця), а лише зсуває пакет даних зi свого передавального регiстра в поля даних такту вiдповiдно до проходження такту через повторювач. При цьому прапорець, що вiдображує стан такту, переходить до стану «зайнято», i в заголовку розмiщується адреса тiєї станцiї, для якої призначено пакет. Потiм такт далі передається вздовж кiльця, доки вiн не дiстанеться до станцiї-приймача, яка зчитує iнформацiю, що мiститься в тактi, але не вилучає її з нього. Знищення iнформацiї не вiдбувається тому, що прапорець стану «порожньо/зайнято» міститься в заголовку такту i вже проходить повз повторювача в той момент, коли вiн починає читати адресне поле. Можливе й iнше технiчне вирiшення, при якому станцiя, що одержала вiдправлений їй пакет, виставить у кiнцi такту прапорець на знак того, що пакет одержано. Такт (прапорець якого все ще вказує на стан «зайнято») потiм прямує вiд станцiї до станцiї, поки не досягне станцiї-передавача. Станцiя-передавач, полічивши кiлькiсть тактiв у кiльцi, розпiзнає вiдправлений до неї такт i переведе прапорець такту до стану «порожньо», дозволивши якiйсь iншiй станцiї використати цей такт. Якщо в тактi є поле пiдтвердження, то станцiя-передавач перевiрить його вмiст, щоб упевнитися в тому, що станцiя-приймач справді отримала вiдправлений їй пакет.
В одному з рiзновидiв цього методу станцiї-передавачеві не потрiбно позначати такт прапорцем «порожньо», якщо та сама станцiя має намір ще раз скористатися цим тактом. Це може, проте, спричинитися до того, що якась iз станцiй утримуватиме такт у себе стiльки часу, скiльки вона вважатиме за потрібне. У тих кiльцях, де використовується лише один такт, такий стан є, очевидно, неприйнятним. Тому в бiльшостi реалiзацiй такт звiльняється пiсля кожного зробленого ним оберту в кiльцi. У цьому разі лишається можливiсть по черзi використовувати такт при передаваннi його вiд станцiї до станцiї. Якщо станцiю приймача вiдімкнено i вона не змогла зчитати пакет або знайшла помилку в тактi, то передавача сповiщають про це з допомогою вiдповiдного прапорця в полi пiдтвердження. Тодi передавач зможе ще раз передати той самий пакет, помiстивши його в наступному вiльному тактi. Отже, незважаючи на явнi втрати часу через те, що заповнений такт змушений виконувати повний оберт, вiн використовується як для передавання даних на прямому шляху до приймача, так i для пiдтвердження доставки при зворотному русi. Якщо використовуваний такт не був звiльнений станцiєю-передавачем (наприклад, через збiй на цiй станцiї пiсля передавання), то такт iз мiткою «зайнято» циркулюватиме кiльцем. На практицi однiй зi станцiй надається право звiльняти такти, що проходять повз неї у незмiнному станi бiльш як один раз. Це завдання покладається на спецiальну станцiю, яка також вiдповiдає за запуск мережі в роботу та стежить за помилками. Цей метод використований у комерцiйнiй мережi Cambrige Ring.
Передавання маркера кiльцем. При застосуваннi методу тактованого доступу керування кiльцем воно стає неявно пов’язаним з порожнiм тактом. Альтернативним вирiшенням є доступ з передаванням маркера. Маркер то є специфiчна комбiнацiя бiтiв, що передається вiд станцiї до станцiї у певнiй послiдовностi. Якщо у станцiї є данi, які пiдлягають передаванню, вона змушена чекати, доки попередня станцiя надiшле їй маркер. Коли станцiя отримує маркер, вона на деякий час вилучає його з кiльця та розмiщує одразу ж за пакетом даних, який зберiгається у зсувовому регiстрi для передавання. Потiм передавальний зсувовий регiстр послiдовно пiдмикається до кiльця i його вмiст (разом iз маркером наприкiнцi пакета) передається кiльцем. Далi регiстр вилучається з кiльця, а станцiя чекає на повернення вiдправленого нею пакета. Перший же пакет, отриманий приймальною стороною, має бути за нормальних умов цим пакетом. Тому перший же отриманий пакет зчитується у приймальний регiстр для аналiзу. Пiсля цього вiдновлюється звичайний ланцюг кiльця, що нагадує метод вставляння регiстра. Станцiя переходить до стану очікування наступного маркера, якщо в неї лишилася iнформацiя, яку необхiдно передати. Отже, потiк iнформацiї, що надходить до деякої станцiї, завжди починається з пакета, який вiдправлено даною станцiєю. Кожний передавач вiдповiдає за вилучення своїх пакетiв з кiльця. Кожний пакет, що передається, завжди стає останнiм у послiдовностi пакетiв, що передують маркеру. У цiй схемi не доводиться вiдводити вхiдний потiк у буферний регiстр iз затримкою при потребі передати якийсь пакет. Станцiя-приймач звичайно працює аналогiчно повторювачу при тактованому доступi. Вона читає пакет в мiру його проходження та може виставити прапорець пiдтвердження наприкiнцi пакета, не змiнюючи при цьому самого пакета. Основнi складностi в кiльцi з курсуючим маркером виникають, якщо маркер губиться або передавач не вилучає свого пакета. Перша ситуацiя може виникнути в тому разі, коли маркер, вилучений якоюсь станцiєю, що передає iнформацiю, потiм не вiдроджується через апаратний збiй або маркер, пошкоджений при передаваннi, не можна розпiзнати. Пакет може лишитися невилученим тому, що виникла помилка у станцiї-передавачi, а потiк iнформацiї, яка надходить, не був вiдведений у приймальний буфер. З обома ситуацiями допомагає успішно впоратися спецiальний слiдкуючий пристрій, який розпiзнає вiдсутнiсть маркера в кiнцi потоку даних або факт циркулювання якогось пакета кiльцем. У першому випадку генерується новий маркер, у другому — знищується пакет.
За вiдсутностi спецiальної станцiї, що стежить за роботою кiльця, проблему загублення маркера легко вирiшити, дозволивши якiйсь станцiї або повторювачу виробити новий маркер, якщо протягом деякого довiльного промiжку часу ця станцiя не прийняла такий маркер. Можливе дублювання маркера, якщо якiсь двi станцiї генерують новi маркери одночасно. Проте цього можна уникнути, коли кожна зі станцiй, що генерують маркер, завжди розмiщує перед ним контрольний пакет та стежить за тим, аби вiн повернувся першим. Кожний пакет, який з’являється на виходi, перевiряється та скидається, якщо вiн вiдрiзняється вiд переданого пакета. Якщо двi станцiї роблять це одночасно, то вони знищують маркери та пакети один одного. Пiсля довiльного промiжку часу в деякій точцi кiльця знову генерується маркер. Якщо кожна зі станцiй, яка вже передала пакет, завжди знищує першi пакети, що надiйшли до неї з кiльця, поки не дiйде до свого пакета, то проблему невилучених пакетiв буде вирiшено. Метод передавання маркера дуже ефективний, і до того ж не потрібний такий складний слiдкуючий пристрій, як для тактованого доступу. Але для реалізацiї перемикання регiстрiв та керування маркером вiн потребує значно складніших повторювачiв і програмного забезпечення для кожної зі станцiй. Метод передавання маркера застосовано в комерцiйнiй мережi RingNet.
Передавання маркера в шинi. Сутність методу полягає в тому, що шиною вiд одного пристрою до iншого передається маркер, тобто спецiальний пакет з легко розпiзнаваною послiдовнiстю бiтiв.
Кадр типу маркер має такий вигляд:
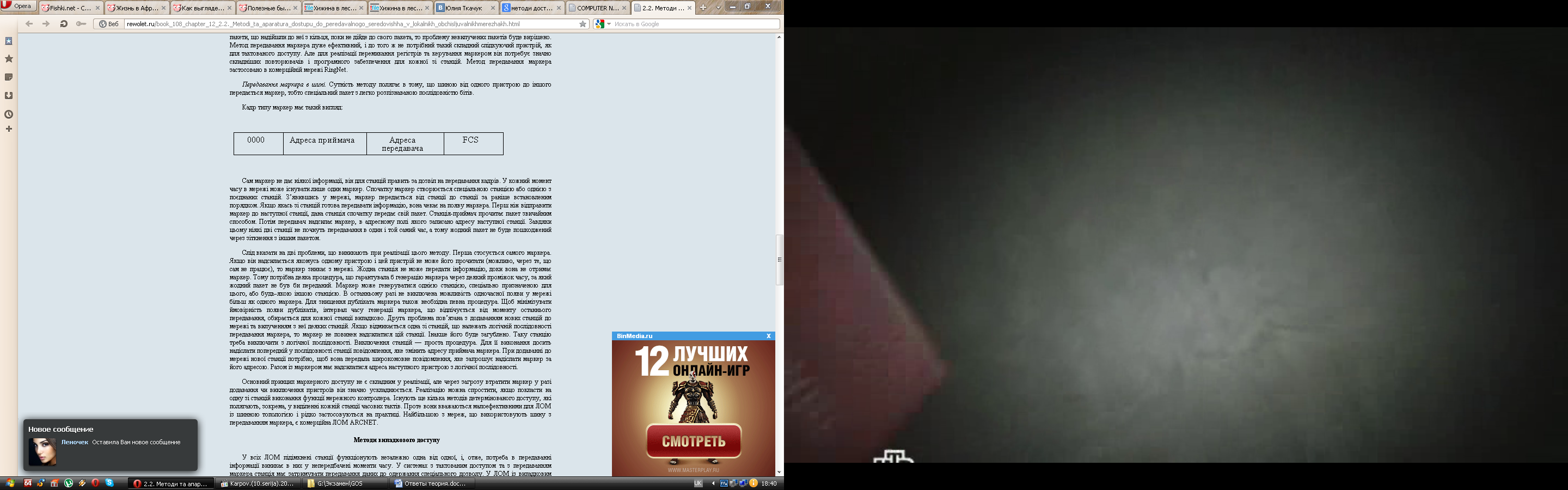
Сам маркер не дає нiякої iнформацiї, вiн для станцiй править за дозвiл на передавання кадрiв. У кожний момент часу в мережi може iснувати лише один маркер. Спочатку маркер створюється спецiальною станцiєю або однiєю з поєднаних станцiй. З’явившись у мережi, маркер передається вiд станцiї до станцiї за ранiше встановленим порядком. Якщо якась зі станцiй готова передавати iнформацiю, вона чекає на появу маркера. Перш нiж вiдправити маркер до наступної станцiї, дана станцiя спочатку передає свiй пакет. Станцiя-приймач прочитає пакет звичайним способом. Потiм передавач надсилає маркер, в адресному полi якого записано адресу наступної станцiї. Завдяки цьому нiякi двi станцiї не почнуть передавання в один i той самий час, а тому жодний пакет не буде пошкоджений через зiткнення з iншим пакетом.
Слiд вказати на двi проблеми, що виникають при реалiзацiї цього методу. Перша стосується самого маркера. Якщо вiн надсилається якомусь одному пристрою і цей пристрiй не може його прочитати (можливо, через те, що сам не працює), то маркер зникає з мережі. Жодна станцiя не може передати iнформацiю, доки вона не отримає маркер. Тому потрібна деяка процедура, що гарантувала б генерацiю маркера через деякий промiжок часу, за який жодний пакет не був би переданий. Маркер може генеруватися однiєю станцiєю, спецiально призначеною для цього, або будь-якою іншою станцiєю. В останньому разі не виключена можливiсть одночасної появи у мережi бiльш як одного маркера. Для знищення дублiката маркера також необхiдна певна процедура. Щоб мiнiмiзувати ймовiрнiсть появи дублiкатiв, iнтервал часу генерацiї маркера, що вiдлічується вiд моменту останнього передавання, обирається для кожної станцiї випадково. Друга проблема пов’язана з додаванням нових станцiй до мережі та вилученням з неї деяких станцiй. Якщо вiдмикається одна зi станцiй, що належать логiчнiй послiдовностi передавання маркера, то маркер не повинен надсилатися цiй станцiї. Iнакше його буде загублено. Таку станцiю треба виключити з логiчної послiдовностi. Виключення станцiй — проста процедура. Для її виконання досить надiслати попереднiй у послiдовностi станцiї повiдомлення, яке змiнить адресу приймача маркера. При додаваннi до мережі нової станцiї потрiбно, щоб вона передала широкомовне повiдомлення, яке запрошує надiслати маркер за його адресою. Разом iз маркером має надсилатися адреса наступного пристрою з логiчної послiдовностi.
Основний принцип маркерного доступу не є складним у реалiзацiї, але через загрозу втратити маркер у разі додавання чи виключення пристроїв вiн значно ускладнюється. Реалiзацiю можна спростити, якщо покласти на одну зі станцiй виконання функцiї мережного контролера. Існують ще кiлька методiв детермiнованого доступу, якi полягають, зокрема, у видiленнi кожнiй станцiї часових тактiв. Проте вони вважаються малоефективними для ЛОМ iз шинною топологiєю i рiдко застосовуються на практицi. Найбільшою з мереж, що використовують шину з передаванням маркера, є комерцiйна ЛОМ ARCNET.
№2
Hyper-threading (англ. Hyper-threading — гіпер-нитевість, офіційна назва Hyper-Threading Technology (HTT)) — торгова марка компанії Intel для реалізації технології «одночасної багатонитевості» (англ. Simultaneous multithreading) на мікроархітектурі Pentium 4.
Розширена форма супер-нитевості (англ. Super-threading), що вперше з'явилася у процесорах Intel Xeon і пізніше додана в процесори Pentium 4. Ця технологія збільшує продуктивність процесора при певних робочих навантаженнях шляхом надання «корисної роботи» (англ. useful work) виконавчим блокам (англ. execution units), які без цієї функції не будуть використовуватись (наприклад, у випадках кеш-промаху). Процесори Pentium 4 з увімкненим Hyper-threading операційна система визначає як два різних процесора замість одного.
Основні переваги Hyper-threading представлені як: покращена підтримка багатонитевого коду, що дозволяє запускати ниті одночасно; поліпшена реакція і час відгуку; збільшена кількість користувачів, що може підтримувати сервер.
Компанія Intel стверджує що перша реалізація призвела до 5-відсоткового збільшення площі кристала але натомість дозволяла збільшити продуктивність на 15 — 30%.
Intel стверджує, що надбавка до швидкості становить 30% в порівнянні з ідентичними процесорами Pentium 4 без технології «Simultaneous multithreading». Однак надбавка до продуктивності змінюється від застосунку до застосунка: деякі програми взагалі дещо сповільнюються при включеній технології Hyper-threading. Це, в першу чергу, пов'язано з «системою повторення» процесорів Pentium 4, що займає необхідні обчислювальні ресурси, від чого і починають «голодувати» інші ниті.
Сучасний стан
Технологія Hyper-threading не була успадкована в сімействі процесорів Intel Core.
Intel в листопаді 2008 випустив процесор Core i7 (кодова назва Nehalem), в якому технологія hyper-threading була відроджена. Nehalem містить 4 ядра і ефективно маштабується до 8 нитей в пікових режимах.[2]
Черговим процесором, де інкарнувалася технологія hyper-threading, став Intel Atom, який використовується для енергоефективних мобільних пристроїв і дешевих настільних комп'ютерів.
Також Hyper-Threading підримують процесори з ядром Sandy Bridge: Core i3, Core i5, Core i7.
Как задействовать в приложении мощь новой технологии
Технология Hyper-Threading (поддержка логических процессоров физическим процессором) повышает эффективность процессора, позволяя выполнять два потока инструкций параллельно. Эта возможность появилась в сравнительно новых процессорах Intel Pentium 4; она позволяет увеличить производительность некоторых приложений на 20-30%, в отдельных случаях до 40%.
К сожалению, производительность остальных приложений не повышается, а иногда и уменьшается (мне попадались приложения, производительность которых снижалась на 20%), особенно если нарушаются рекомендации, такие как обсуждаемые в этой статье. Более того, вместе с преимуществами, получаемыми на однопроцессорных компьютерах с поддержкой Hyper-Threading, проявляют себя и некоторые ошибки в приложениях, которые ранее могли возникать только в многопроцессорных системах.
В этой статье я исследую технологию Hyper-Threading и продемонстрирую, как дополнить свой код поддержкой параллелизма, способной помочь увеличить производительность на компьютерах с Hyper-Threading. Я расскажу о тонкостях оптимизации для Hyper-Threading и покажу несколько полезных примеров. Мои примеры написаны на C#, но основные принципы применимы как к управляемым, так и к неуправляемым приложениям.
Важность Hyper-Threading
Технология Hyper-Threading доступна на сравнительно новых процессорах Pentium 4, обычно с тактовой частотой от 2,4 ГГц, а также на всех процессорах Xeon от 2,2 ГГц.
До появления Hyper-Threading процессор Pentium 4 мог исполнять лишь один поток инструкций одновременно. Процессор поддерживал единственный указатель команд (instruction pointer, IP), и вся многозадачность на однопроцессорных компьютерах базировалась на способности операционной системы распределять процессорное время между потоками. Hyper-Threading позволяет Pentium 4 выполнять два потока инструкций одновременно; процессор поддерживает два указателя команд и состояний машины (machine states) и незаметно для пользовательского кода переключается между ними.
Для выполнения машинной инструкции программы нужен один или более слотов исполнения (execution slots). Слот исполнения соответствует внутреннему ресурсу процессора, например блоку вычислений с плавающей точкой (floating point unit, FPU), и отражает способность процессора выполнить какую-либо операцию, скажем, вычисление значения с плавающей точкой.
Процессор Pentium 4 всегда знает, какие слоты исполнения доступны. Такая функциональность, как Out-Of-Order Execution (когда процессор пытается выполнять инструкции в порядке, отличном от того, в котором они появляются в потоке инструкций), повышает производительность, так как это позволяет обеспечить работой больше слотов исполнения, а не ждать, пока какой-то слот освободится. В результате того, что процессор получил свободу переключения между двумя потоками, можно задействовать еще больше слотов исполнения. Пока один поток инструкций ожидает доступа к блокированному участку оперативной памяти или занятому слоту исполнения, процессор может обрабатывать команды из второго потока инструкций.
В процессорах с поддержкой Hyper-Threading два потока инструкций выполняются одновременно. Точнее, процессор выполняет несколько команд из первого потока, потом несколько команд из второго и т. д. Переключение между ними определяется алгоритмом, который пытается оптимизировать нагрузку между слотами исполнения и свести к минимуму возможность простоев; этот алгоритм также стремится равномерно распределять ресурсы между потоками инструкций. Контекст выполнения (например значения регистров) хранится в потоке инструкций. В итоге один процессор с поддержкой Hyper-Threading эмулирует два физических процессора, каждый из которых на самом деле является логическим.
Hyper-Threading позволяет лучше использовать ресурсы процессора, а следовательно, увеличивает производительность. Обратная сторона вопроса заключается в том, что на самом деле ресурсы процессора разделяются и, когда оба потока инструкций запрашивают один и тот же общий ресурс, производительность может падать.
Помимо общих ресурсов вроде FPU, модуля арифметической логики (ALU), разделяется и пространство внутри кэша процессора (оно делится на кэши уровней 1 и 2, также называемые L1 и L2), где кэшируются недавно использовавшиеся области оперативной памяти. Совместное использование пространства кэша может и повышать, и снижать производительность, но об этом я расскажу позже.В процессорах с поддержкой Hyper-Threading два потока инструкций выполняются одновременно. Точнее, процессор выполняет несколько команд из первого потока, потом несколько команд из второго и т. д.
Если второго потока инструкций нет, тогда все пространство кэша и другие ресурсы передаются первому потоку. Поскольку многопоточный режим выполнения инструкций приводит к некоторым издержкам, процессор использует его, только если инструкции запланированы к выполнению на обоих логических процессорах. Кроме того, компьютер с одним процессором, но с включенной поддержкой Hyper-Threading использует многопроцессорную версию ядра операционной системы, которое обеспечивает более качественную синхронизацию, но за счет небольшой потери производительности.
В идеальном случае каждый поток инструкций выполняется почти так же быстро, как и на процессоре, обрабатывающем только один поток. Но в действительности ситуация, в которой два потока инструкций могли бы выполняться без частого обращения к разделяемым ресурсам, наблюдается весьма редко. В результате каждый поток выполняется несколько медленнее, чем в идеале. Однако, если работа приложения разделяется на две части в соответствии с рекомендациями, Hyper-Threading может все равно повысить общую производительность этого приложения.
Hyper-Threading в Windows
В последних версиях Windows каждый поток инструкций представляется как логический процессор, поэтому операционная система планирует выполнение потоков на каждом логическом процессоре. Это означает, что на компьютере с одним физическим процессором, но двумя логическими, два потока будут работать одновременно — каждый на своем логическом процессоре. Пользователь увидит на таком компьютере два логических процессора, и, когда будут выполняться два потока, они будут выполняться на обоих логических процессорах одновременно.
В Windows NT и более поздних версиях Windows планировщик поддерживает Hyper-Threading. Когда несколько потоков выполняются параллельно, им выделяется процессорное время на обоих логических процессорах, а не просто кванты времени, как в случае единственного процессора без поддержки Hyper-Threading. Это может заметно повысить производительность и «отзывчивость» систем с поддержкой Hyper-Threading.
Планирование потоков в двухпроцессорной системе с поддержкой Hyper-Threading сложнее; операционная система сначала планирует потоки для физических процессоров, затем для логических, поддерживаемых этими физическими процессорами. То есть при наличии всего двух потоков каждый из них закрепляется за своим физическим, а не логическим процессором. Далее я буду рассматривать лишь однопроцессорные системы с поддержкой Hyper-Threading.
Клиентские и серверные приложения
Ключ к оптимизации приложений для Hyper-Threading — добиться того, чтобы оба логических процессора делали что-нибудь полезное. Я расскажу, как для большей производительности оптимизировать разделение труда между потоками.
Обсуждаемый здесь материал относится как к клиентским, так и к серверным приложениям. На серверах иногда больший смысл имеет прямолинейное разделение труда. Так, если вы разрабатываете ASP.NET-приложение или Web-сервис, ежесекундно обрабатывающий массу запросов, то здесь эффективна традиционная многопоточная архитектура, гарантирующая одновременное выполнение множества потоков. По этой причине существующие серверные приложения показывают большее увеличение производительности при включении Hyper-Threading.
Приложения, которым нужен быстрый ввод-вывод (сетевой или дисковый), выигрывают при распределении операций между несколькими потоками при использовании асинхронной модели. Для клиентских или серверных приложений, где каждый запрос требует интенсивной процессорной обработки, дополнительные преимущества могут быть достигнуты путем распределения работы между несколькими потоками (такой способ почти ничего не дает или даже вредит на однопроцессорных компьютерах без Hyper-Threading из-за слишком частого переключения контекстов). Клиентские приложения, в которых работа передается потоку, отделенному от UI-потока (такой вариант почти всегда оправдывает себя даже просто по соображениям удобства в использовании), на компьютерах с поддержкой Hyper-Threading реагируют на команды пользователя заметно быстрее.
Как задействовать преимущества Hyper-Threading
Hyper-Threading повышает производительность и «отзывчивость» многопоточных приложений. Я расскажу о нескольких подходах, которые позволят максимально повысить производительность. У каждого подхода свои недостатки, поэтому для оценки измеряйте показатели производительности.
Хорошая отправная точка — замерить производительность вашего кода на процессоре с поддержкой Hyper-Threading и без нее (тестировать можно на одном компьютере, если его BIOS позволяет выключать Hyper-Threading). Дополнительный эффект от программирования с учетом Hyper-Threading заключается в том, что это позволит повысить производительность вашего приложения и при выполнении на двухпроцессорной машине. Я поясню, какие подходы специфичны для Hyper-Threading и не будут работать на компьютерах с двумя и более процессорами. Однако приложения, хорошо масштабируемые в многопроцессорных системах, всегда будут чувствовать себя хорошо и в среде с Hyper-Threading.
Прежде всего стоит обратить внимание на операции, интенсивно использующие процессор. Это блоки кода, отвечающие за рендеринг и вывод графики, кодирование и декодирование музыки или видео, сжатие или шифрование данных, а также выполняющие много циклов. Чтобы выявить такие операции, можно начать с профилирования приложения.
Здесь полезен такой инструмент, как диспетчер задач (TaskMgr.exe), показанный на рис. 1. На вкладке Performance (Быстродействие) отображаются графики использования логических процессоров. Убедитесь, что диспетчер задач настроен на вывод отдельного графика для каждого процессора (View | Select Colums | CPU Usage).
Аналогичная информация доступна через счетчик производительности «Processor: % Processor Time» либо для всех процессоров вместе или отдельно для каждого логического процессора. Получить эту информацию удобнее всего через PerfMon.exe (оснастка Performance).
Иногда измерение только загруженности процессора не позволяет определить все операции, интенсивно использующие процессор, так как можно пропустить короткие всплески активности процессора, но такие всплески поможет выявить средство профилирования. В частности, для идентификации функций, сильно нагружающих процессор, удобно средство профилирования в CLR, а также другие средства профилирования, например VTune или поставляемые с Visual Studio 2005 Team System.
Важно отметить, что измерение загруженности процессора через Task Manager или Perfmon может вводить в заблуждение. Операция, нагружающая процессор лишь из одного потока, будет давать загрузку процессора только на 50%. Но, поскольку логические процессоры тесно взаимосвязаны, крайне маловероятно, что полная нагрузка обоих процессоров приведет к удвоению производительности.
В остальной части статьи я исхожу из того, что два потока (T1 и T2) выполняются на двух логических процессорах (LC1 и LC2) на одном физическом процессоре.
№3
Швидкий розвиток нових технологій програмування безпосередньо пов’язаний з бурхливим розвитком науково-технічного прогресу і комп’ютерної техніки зокрема. Щоб розібратись в деяких існуючих технологіях програмування, звернімось всього на декілька десятиліть назад і спробуємо визначити основні етапи розвитку програмування як науки.
Програми для перших обчислювальних машин створювались, як правило, в машинних кодах або на асемблері і були схожі на витвір мистецтва, бо повинні були поміститись у мініатюрному за сучасними поняттями об’ємі пам’яті. Пошуки помилки в програмі можна було, мабуть, порівняти з муками Тантала. Програмісти були схожі на “вищу касту” серед нормальних людей, бо вони єдині були здатні на спілкування з обчислювальною технікою. Цей етап програмування називають “стихійним програмуванням”. Створення нових алгоритмічних мов програмування, таких як FORTRAN та ALGOL, дещо покращило, але не змінило в корені ситуацію. Революційний винахід засобів, що підтримували можливість використання підпрограм, привів до підвищення складності програм. Були створені цілі бібліотеки службових та розрахункових програм, які можна було використовувати в різних програмних системах. Дані в програмах зберігались, як правило, в глобальних областях, які спільно використовувались різними підпрограмами. В 60-х роках минулого вже століття вибухнув так званий кризис програмування. Вираженням його стали програмні проекти, які встигали морально застаріти ще на рівні розробки, і перевищували всі можливі терміни в часі та вартості. Бідою більшості програмних проектів ставали численні помилки, пошуки та виправлення яких займали до 90% часу, відведеного на розробку. Багато з них так і не були завершені. Причиною такого положення речей стала відсутність ретельно продуманих технологій або методів програмування.
Глибокий та ретельний аналіз причин даного кризису привів до створення робочої групи з методології програмування при Міжнародній федерації по обробці інформації. До її складу увійшло багато відомих програмістів, наприклад, Н. Вірт, П. Наур, Ч.Хоар, У. Дал, Е. Дейкстра. Їх спільні зусилля привели до оформлення нової технології (інколи кажуть – парадігми) програмування – структурного програмування [3, 4, 9, 12, 15]. Завдяки принципам структурного програмування вдалося подолати фактор складності та зрозуміти причини невдач програмних проектів великого масштабу. Ці принципи детально будуть розглянуті нижче, тут лише зазначимо, що вони спрямовані на створення програмних проектів з прозорою логікою функціонування. Цього вдається досягти завдяки правильному структуруванню проекту в цілому і кожного його модуля зокрема.
Сучасні технології програмування базуються на принципах об’єктно-орієнтованого програмування, завдяки якому складні програмні проекти реалізуються у вигляді сукупності об’єктів певної ієрархії. Їх взаємодія встановлюється шляхом передачі повідомлень між об’єктами. На підтримку нової технології програмування були створені нові мови, наприклад C++, Java, Modula. Організація програм на засадах інкапсуляції, успадкування, поліморфізму дозволила значно підвищити рівень програмних проектів.
Перспективи подальшого розвитку програмування вбачаються у так званому компонентному підході [8].
2. Життєвий цикл програмного забезпечення
Процес створення та використання програмної системи включає декілька стадій: від початкової ідеї до остаточного морального застаріння. Цей процес називається життєвим циклом програмного забезпечення [6, 8, 11]. Він складається з наступних 6 етапів.
1. Специфікація вимог:
а) підготовка повного і чіткого визначення задачі;
б) представлення документів з вимогами до задачі користувачам і аналітикам для погодження (ухвалення).
2. Аналіз:
а) вивчення задачі, визначення специфікацій (тобто структури вхідних та вихідних даних);
б) оцінка альтернативних методів розв’язання (алгоритмів);
в) вибір оптимального метода (алгоритма).
3. Проектування:
а) визначення структури програмної системи та її проектування;
б) розбиття програмної системи на окремі компоненти та їх проектування з визначенням ключових елементів структури даних.
4. Реалізація:
а) створення алгоритмів і кодів окремих модулів вибраною мовою програмування;
б) створення вихідного текста програми;
в) налагодження вихідного текста.
5. Тестування і верифікація:
а) тестування вихідного текста;
б) участь користувачів і спеціальних колективів (тестерів) у всіх перевірках системи.
6. Експлуатація і супроводження:
а) використання готової програмної системи;
б) оцінка її ефективності;
в) усунення знайдених в процесі експлуатації помилок;
г) внесення необхідних змін для підтримки актуальності програмної системи;
д) перевірка коректності внесених змін (вони не повинні негативно впливати на функціонування системи).
Життєвий цикл програмного забезпечення є ітеративним, тобто допускає багатократне повторення своїх етапів. В ході розробки (етап 3) можуть виникнути проблеми, які будуть вимагати змін вимог до системи (етап 1); під час реалізації (етап 4) може виникнути необхідність переглянути результати, отримані під час розробки (на етапі 3); під час тестування (етап 5) можуть бути виявлені помилки і так далі.
Розглянемо детальніше деякі аспекти програмування згідно хронології життєвого циклу програмного продукту.
БІЛЕТ № 28
№1
Нехай А
- ділене, В
- дільник і С
- частка. Найпростіше ділення виконується
в прямому коді. У разі представлення
чисел
 ,
,
 і
і
 у формі з фіксованою комою, воно
реалізується у два етапи. На першому
етапі визначається знак частки
у формі з фіксованою комою, воно
реалізується у два етапи. На першому
етапі визначається знак частки
 шляхом додавання за модулем два цифр
знакових розрядів діленого
шляхом додавання за модулем два цифр
знакових розрядів діленого
 і дільника
і дільника
 (див. табл. 3.1). На другому етапі здійснюється
ділення модулів початкових чисел
(див. табл. 3.1). На другому етапі здійснюється
ділення модулів початкових чисел
 і
і
 ,
округлення модуля частки, після чого
до нього дописується знак, що визначений
на першому етапі.
,
округлення модуля частки, після чого
до нього дописується знак, що визначений
на першому етапі.
На відміну від
множення чисел з фіксованою комою, в
процесі якого принципово неможливе
переповнення розрядної сітки, ділення
дробових чисел може призвести до
переповнення розрядної сітки і, отже,
до неправильного результату. Тому для
уникнення такої ситуації має виконуватись
умова:
 .
.
Відомо два основних метода ділення чисел, а саме: ділення з відновленням та без відновлення остач.
Алгоритм ділення модулів чисел з відновленням остач полягає у виконанні таких дій.
П. 1. Подвоїти модуль
діленого
 .
.
П. 2. Відняти від
подвоєного модуля діленого модуль
дільника. Одержана різниця
 є першою остачею.
є першою остачею.
П. 3. Проаналізувати
знак остачі R.
Якщо
 ,
то черговому розряду частки присвоїти
цифру 1 і перейти до п. 5; якщо ж R
< 0, то
черговому розряду частки присвоїти
цифру 0.
,
то черговому розряду частки присвоїти
цифру 1 і перейти до п. 5; якщо ж R
< 0, то
черговому розряду частки присвоїти
цифру 0.
П. 4. Відновити
остачу, додавши модуль дільника
 .
.
П. 5. Подвоїти остачу.
П. 6. Визначити чергову остачу, віднявши від попередньої остачі модуль дільника. Перейти до п. 3.
П. 3 - п. 6 виконувати до одержання всіх необхідних цифр частки.
За своїм характером операція ділення відноситься до операцій, що дають не завжди точний результат, тому ознакою закінчення операції ділення може бути досягнення заданої точності. Якщо в процесі ділення одержується остача R = 0, то операція зупиняється й у решту розрядів частки записується нуль. Звичайно формальною ознакою кінця операції ділення є одержання такої самої кількості розрядів у частці, яку мають операнди.
Подвоєння діленого та остачі практично виконується шляхом зсуву коду вліво на один розряд.
Приклад 3.16. Поділити число А = - 0, 10100 на число В = 0, 11011, використовуючи метод ділення з відновленням остач.
Розв'язання.
Для даних чисел маємо:
=1;
= 0, 10100;
=0;
= 0, 11011. Визначаємо знак частки:
 =1
=1 0=1.
Віднімання будемо виконувати як додавання
доповняльних кодів, тому
0=1.
Віднімання будемо виконувати як додавання
доповняльних кодів, тому
 =
1,00101.
=
1,00101.
Усі дії, що виконуються в процесі ділення, наведені в табл. 3.18.
Відповідь: С= - 0, 10111.
З наведеного прикладу випливає, що цифри частки є інверсними значеннями знакових розрядів чергових остач. Треба також відзначити, що результат подвоєння іноді може бути > 1. Однак таке переповнення розрядної сітки усувається на наступному кроці алгоритму, оскільки після подвоєння завжди виконується віднімання.
Основні недоліки розглянутого методу ділення такі:
аритмічність процесу ділення, яка обумовлена нерегулярністю виконання відновлення остачі, що призводить до ускладнення блоку керування діленням;
відносно мала швидкість ділення, оскільки в середньому для половини кроків потрібно виконувати додаткове додавання, що забезпечує відновлення остач.
Для ритмізації процесу ділення можна виконувати фіктивну дію у тих випадках, коли відновлення остачі не потрібне, що призведе до збільшення часу виконання операції. Разом з тим, операцію можна спростити, якщо відмовитись від відновлення остач.
Таблиця 3.18 - Приклад ділення з відновленням остач

Алгоритм ділення модулів чисел без відновлення остач зводиться до виконання таких дій.
П. 1. Подвоїти модуль діленого .
П. 2. Відняти від подвоєного модуля діленого модуль дільника. Одержана різниця є першою остачею.
П. 3. Проаналізувати знак остачі R. Якщо , то черговому розряду частки присвоїти цифру 1; якщо ж R < 0, то черговому розряду частки присвоїти цифру 0.
П. 4. Подвоїти остачу.
П. 5. Визначити чергову остачу, віднявши від попередньої остачі модуль дільника якщо і додавши до попередньої остачі модуль дільника якщо R < 0. Перейти до п. 3.
П. 3 - п. 5 виконувати до одержання всіх необхідних цифр частки.
Приклад 3.17. Поділити число А = - 0, 10100 на число В = 0, 11011, використовуючи метод ділення без відновлення остач.
Розв'язання. Для даних чисел маємо: =1; = 0, 10100; =0; = 0, 11011. Визначаємо знак частки: =1 0=1. Віднімання будемо виконувати як додавання доповняльних кодів, тому = 1,00101.
Усі дії, що виконуються в процесі ділення, наведені в табл. 3.19.
Відповідь: С= - 0, 10111.
В наведених алгоритмах пункт "Подвоєння остачі" можна замінити пунктом "Зменшити в два рази модуль дільника". В машині це буде відповідати зсуву дільника, а не остачі. Наявність двох варіантів зсуву для двох алгоритмів ділення приводить до чотирьох основних алгоритмів машинного ділення:
ділення з відновленням остач і зі зсувом дільника;
ділення з відновленням остач та з їх зсувом;
ділення без відновлення остач і зсувом дільника;
ділення без відновлення остач та з їх зсувом.
Алгоритми ділення з відновленням остач не знаходять практичного застосування в машинах у силу наведених вище причин, тому на рис. 3.8, а і б приведені тільки структурні схеми пристроїв для ділення без відновлення остач.
Для реалізації варіанта а необхідні 2n-розрядний регістр дільника (РгВ) з колами зсуву вправо, 2n-розрядний нагромаджувальний суматор (НСМ), (п+1)-розрядний регістр частки (РгС) з колами зсуву вліво, суматор за модулем два (М2), блок інвертування цифр (БІЦ) і блок керування (БК).
Таблиця 3.19 - Приклад ділення без відновлення остач

Перед початком ділення в нагромаджувальний суматор НСМ записується ділене. За допомогою М2 визначається цифра знакового розряду частки, що записується в знаковий розряд регістра РгС. Передавання модуля дільника в НСМ для додавання або віднімання забезпечується блоком керування, що аналізує цифру знакового розряду НСМ. Ця знакова цифра остачі, проходячи через блок БІЦ, інвертується і подається в молодший розряд регістра частки, де вона зсувається вже як цифра частки.
Для реалізації варіанта б необхідні: (п + 1)-розрядний регістр дільника; (п + 1)-розрядний регістр частки з колами зсуву вліво і (n + 1)-розрядний суматор з колами зсуву вліво. Решта блоків така сама, як для варіанта а.

а)

б)
Рис. 3.8. Варіанти пристроїв для ділення без відновлення остач:
а - зі зсувом дільника; б - зі зсувом остач
Аналіз обох схем
показує, що апаратні витрати на реалізацію
варіанта б
менше, ніж варіанта а.
Проте у варіанті б
неможливо сумістити додавання і зсув,
оскільки додавання в НСМ можна тільки
після закінчення зсуву коду остачі в
нагромаджувальному суматорі. В варіанті
а
кожну цифру дільника з відповідного
розряду регістра РгВ можна одночасно
передавати за двома адресами: в сусідній
правий розряд цього регістра (зсув) і у
відповідний розряд НСМ, тобто починати
виконувати додавання модуля дільника
(або його доповнення) до остачі. Виходячи
з цього, час ділення за алгоритмом без
відновлення остач і зі зсувом дільника
дорівнює
 ,
тоді як зі зсувом остач -
,
тоді як зі зсувом остач -
 .
.
№2
Цифро-аналоговый преобразователь (ЦАП) — устройство для преобразования цифрового (обычно двоичного) кода в аналоговый сигнал (ток, напряжение или заряд). Цифро-аналоговые преобразователи являются интерфейсом между дискретным цифровым миром и аналоговыми сигналами.
Аналого-цифровой преобразователь (АЦП) производит обратную операцию.
Звуковой ЦАП обычно получает на вход цифровой сигнал в импульсно-кодовой модуляции (англ. PCM, pulse-code modulation). Задача преобразования различных сжатых форматов в PCM выполняется соответствующими кодеками.
Применение
ЦАП применяется всегда, когда надо преобразовать сигнал из цифрового представления в аналоговое, например, в проигрывателях компакт-дисков (Audio CD).
Типы ЦАП
Наиболее общие типы электронных ЦАП:
Широтно-импульсный модулятор — простейший тип ЦАП. Стабильный источник тока или напряжения периодически включается на время, пропорциональное преобразуемому цифровому коду, далее полученная импульсная последовательность фильтруется аналоговым фильтром нижних частот. Такой способ часто используется для управления скоростью электромоторов, а также становится популярным в Hi-Fi-аудиотехнике;
ЦАП передискретизации, такие как дельта-сигма-ЦАП, основаны на изменяемой плотности импульсов. Передискретизация позволяет использовать ЦАП с меньшей разрядностью для достижения большей разрядности итогового преобразования; часто дельта-сигма ЦАП строится на основе простейшего однобитного ЦАП, который является практически линейным. На ЦАП малой разрядности поступает импульсный сигнал с модулированной плотностью импульсов (c постоянной длительностью импульса, но с изменяемой скважностью), создаваемый с использованием отрицательной обратной связи. Отрицательная обратная связь выступает в роли фильтра верхних частот для шума квантования.
Большинство ЦАП большой разрядности (более 16 бит) построены на этом принципе вследствие его высокой линейности и низкой стоимости. Быстродействие дельта-сигма ЦАП достигает сотни тысяч отсчетов в секунду, разрядность — до 24 бит. Для генерации сигнала с модулированной плотностью импульсов может быть использован простой дельта-сигма модулятор первого порядка или более высокого порядка как MASH (англ. Multi stage noise SHaping). С увеличением частоты передискретизации смягчаются требования, предъявляемые к выходному фильтру низких частот и улучшается подавление шума квантования;
ЦАП взвешивающего типа, в котором каждому биту преобразуемого двоичного кода соответствует резистор или источник тока, подключенный на общую точку суммирования. Сила тока источника (проводимость резистора) пропорциональна весу бита, которому он соответствует. Таким образом, все ненулевые биты кода суммируются с весом. Взвешивающий метод один из самых быстрых, но ему свойственна низкая точность из-за необходимости наличия набора множества различных прецизионных источников или резисторов и непостоянного импеданса. По этой причине взвешивающие ЦАП имеют разрядность не более восьми бит;
ЦАП лестничного типа (цепная R-2R-схема). В R-2R-ЦАП значения создаются в специальной схеме, состоящей из резисторов с сопротивлениями R и 2R, называемой матрицей постоянного импеданса, которая имеет два вида включения: прямое — матрица токов и инверсное — матрица напряжений. Применение одинаковых резисторов позволяет существенно улучшить точность по сравнению с обычным взвешивающим ЦАП, так как сравнительно просто изготовить набор прецизионных элементов с одинаковыми параметрами. ЦАП типа R-2R позволяют отодвинуть ограничения по разрядности. С лазерной подгонкой резисторов на одной подложке достигается точность 20-22 бита. Основное время на преобразование тратится в операционном усилителе, поэтому он должен иметь максимальное быстродействие. Быстродействие ЦАП единицы микросекунд и ниже (то есть наносекунды);
Характеристики
ЦАП находятся в начале аналогового тракта любой системы, поэтому параметры ЦАП во многом определяют параметры всей системы в целом. Далее перечислены наиболее важные характеристики ЦАП.
Разрядность — количество различных уровней выходного сигнала, которые ЦАП может воспроизвести. Обычно задается в битах; количество бит есть логарифм по основанию 2 от количества уровней. Например, однобитный ЦАП способен воспроизвести два () уровня, а восьмибитный — 256 () уровней. Разрядность тесно связана с эффективной разрядностью (англ. ENOB, Effective Number of Bits), которая показывает реальное разрешение, достижимое на данном ЦАП.
Максимальная частота дискретизации — максимальная частота, на которой ЦАП может работать, выдавая на выходе корректный результат. В соответствии с теоремой Найквиста — Шеннона (известной также как теорема Котельникова), для корректного воспроизведения аналогового сигнала из цифровой формы необходимо, чтобы частота дискретизации была не менее, чем удвоенная максимальная частота в спектре сигнала. Например, для воспроизведения всего слышимого человеком звукового диапазона частот, спектр которого простирается до 20 кГц, необходимо, чтобы звуковой сигнал был дискретизован с частотой не менее 40 кГц. Стандарт Audio CD устанавливает частоту дискретизации звукового сигнала 44,1 кГц; для воспроизведения данного сигнала понадобится ЦАП, способный работать на этой частоте. В дешевых компьютерных звуковых картах частота дискретизации составляет 48 кГц. Сигналы, дискретизованные на других частотах, подвергаются передискретизации до 48 кГц, что частично ухудшает качество сигнала.
Монотонность — свойство ЦАП увеличивать аналоговый выходной сигнал при увеличении входного кода.
THD+N (суммарные гармонические искажения + шум) — мера искажений и шума вносимых в сигнал ЦАПом. Выражается в процентах мощности гармоник и шума в выходном сигнале. Важный параметр при малосигнальных применениях ЦАП.
Динамический диапазон — соотношение наибольшего и наименьшего сигналов, которые может воспроизвести ЦАП, выражается в децибелах. Данный параметр связан с разрядностью и шумовым порогом.
Статические характеристики:
DNL (дифференциальная нелинейность) — характеризует, насколько приращение аналогового сигнала, полученное при увеличении кода на 1 младший значащий разряд (МЗР), отличается от правильного значения;
INL (интегральная нелинейность) — характеризует, насколько передаточная характеристика ЦАП отличается от идеальной. Идеальная характеристика строго линейна; INL показывает, насколько напряжение на выходе ЦАП при заданном коде отстоит от линейной характеристики; выражается в МЗР;
усиление;
смещение.
Частотные характеристики:
SNDR (отношение сигнал/шум+искажения) — характеризует в децибелах отношение мощности выходного сигнала к суммарной мощности шума и гармонических искажений;
HDi (коэффициент i-й гармоники) — характеризует отношение i-й гармоники к основной гармонике;
THD (коэффициент гармонических искажений) — отношение суммарной мощности всех гармоник (кроме первой) к мощности первой гармоники.
№3
Операционная система Linux поддерживает те возможности, которые имеются в других реализациях семейства UNIX, а также те, которых нет больше нигде. Ниже будет дан краткий обзор основных возможностей системы Linux.
Характерные особенности Linux
Одновременное выполнение нескольких программ
Работа нескольких пользователей на одной машине
Документированность Linux
Отличие Linux от других ОС со свободной лицензией
Характерные особенности Linux
Характерными особенностями Linux как операционной системы являются:
многозадачность: одновременно выполняется множество программ;
многопользовательский режим: большое число пользователей одновременно работают на одной и той же машине;
защищенный режим процессора (386 protected mode);
защита памяти процесса; сбой программы не может вызвать зависания системы;
экономная загрузка: Linux считывает с диска только те части программы, которые действительно используются для выполнения;
разделение страниц по записи между экземплярами выполняемой программы. Это значит, что процессы-экземпляры программы могут использовать при выполнении одну и ту же память. Когда такой процесс пытается произвести запись в память, то 4-x килобайтная страница, в которую идет запись, копируется на свободное место. Это свойство увеличивает быстродействие и экономит память;
виртуальная память со страничной организацией (т.е. на диск из памяти вытесняется не весь неактивный процесс, а только требуемая страница); виртуальная память в самостоятельных разделах диска и/или файлах файловой системы; объем виртуальной памяти до 2 Гбайт; изменение размера виртуальной памяти во время выполнения программ;
общая память программ и дискового кэша: вся свободная память используется для буферизации обмена с диском;
динамические загружаемые разделяемые библиотеки;
дамп программы для пост-мортем анализа: позволяет анализировать отладчиком не только выполняющуюся, но и завершившуюся аварийно программу;
совместимость со стандартами System V и BSD на уровне исходных текстов;
наличие исходного текста всех программ, включая тексты ядра, драйверов, средств разработки и приложений. Эти тексты свободно распространяются. В настоящее время некоторыми фирмами для Linux поставляется ряд коммерческих программ без исходных текстов, но все, что было свободным так и остается свободным;
управление заданиями в стандарте POSIX;
эмуляция сопроцессора в ядре, поэтому приложение может не заботиться об эмуляции сопроцессора. Конечно, если сопроцессор в наличии, то он и используется;
поддержка национальных алфавитов и соглашений, в т.ч. для русского языка; возможность добавлять новые;
множественные виртуальные консоли: на одном дисплее несколько одновременных независимых сеансов работы, переключаемых с клавиатуры;
поддержка ряда распространенных файловых систем (MINIX, Xenix, файловые системы System V); наличие собственной передовой файловой системы объемом до 4 Терабайт и с именами файлов до 255 знаков;
прозрачный доступ к разделам DOS (или OS/2 FAT): раздел DOS выглядит как часть файловой системы Linux; поддержка VFAT;
специальная файловая система UMSDOS, которая позволяет устанавливать Linux в файловую систему DOS;
поддержка всех стандартных форматов CD ROM;
поддержка сети TCP/IP, включая ftp, telnet, NFS и т.д.
Одновременное выполнение нескольких программ
Так называемая виртуальная мультиконсоль дает возможность на одном дисплее организовать работу нескольких консолей. На первой консоли запускается процесс трансляции. Комбинацией клавиш Alt-F2 следует переход на вторую консоль. Трансляция продолжается, но при этом первая консоль на экране дисплея заменяется новой картинкой второй консоли, в которой запускается, например, редактор текста. Комбинацией Alt-F3 следует переход на третью консоль, в которой запускается отладчик и т.д. Обычно в системе 6 консолей, но можно установить до 64-х. В любой момент времени можно переключиться на любую консоль.
На отдельной консоли может работать как текстовая, так и графическая программа.
На одной из свободных консолей можно запустить оконную графическую систему X Window System. Открываете окно на экране и играете в DOOM (можно через сеть с партнером). В других окнах: база данных, почта, редактор, трансляция и т.д.
Таким образом, одновременно работает много консолей, а на одной из консолей еще и много окон X Window System.
Кроме того, в системе одновременно работают фоновые процессы, которые не выдают информации на дисплей, но делают свою работу, например, передают данные по модему, печатают на принтере, передают почту по сети и т.д. Фоновый процесс может инициировать как пользователь, так и сама ОС в соответствии со сложившимися условиями (есть почта для отправки, данные для печати, наступило время связи по модему и т.п.).
Linux обеспечивает физическое распараллеливание вычислений на многопроцессорных машинах (до 32 процессоров), но это не имеет прямого отношения к одновременному выполнению нескольких программ. Операционная система позволяет одновременно выполнять несколько задач на одном процессоре, сотни раз в секунду переключая процессор с задачи на задачу.
БІЛЕТ № 29
№1
В принципі можна працювати взагалі без використання протоколів маршрутизації. Це так звана статична маршрутизація. В цьому випадку таблиця маршрутів будується з допомогою команди ifconfing. Ці команди виписують рядки які відповідають за розсилку повідомлень в локальній мережі і команди route яка використовується для внесення змін вручну.
Існує так звана мінімальна маршрутизація, яка виникає тоді коли локальна мережа не має виходу в Інтернет і не складається з під мереж. В цьому випадку достатньо виконати команди ifconfig для інтерфейсів LO і Ethernet і все буде працювати. Наприклад:
…/usr/paul>ifconfig lo inet 127.0.01
…/usr/paul>ifconfig ed1 inet 144.226.43.1 netmask 255.255.255.0
В таблиці маршрутів з’являться тільки ці два рядки, але оскільки мережа обмежена, пакет не треба відправляти в інші мережі, то модуль ARP буде справлятись з доставкою пакетів по мережі. Якщо ж мережа підключена до Internet, то в таблиці маршрутів треба ввести як мінімум ще один рядок – адресу шлюзу. Робиться це командою route, яка має такий формат:
route
.
В полі
вказується команда роботи з таблицею маршрутів
(add, delete, gem:добавити,вилучити,отримати інформацію про маршрут).
В полі
вказується адреса відправки пакета.
В полі
вказується ІР-адреса через яку треба відправити пакети які призначені хосту або мережі з попереднього поля.
Поле
визначає відстань в кількості шлюзів які пройде даний пакет, якщо ви відправите за даним маршрутом.
Наприклад: route add default 144.206.160.32 це призначення шлюзу по замовчуванню.
Всі пакети, адреси яких не були знайдені в локальній мережі відправляються на мережний інтерфейс з цією адресою і метрика по зімовчуванню приймається =1. таким чином вказується, що це адреса шлюзу.
В полі прапорців звіту отриманого командою netstat, можна зустріти такі прапорці:
U-маршрут активний і може використовуватись для маршрутизації пакетів
H- маршрут використовується для відправки пакетів визначеному в маршруті хосту.
G- пакет напрвляється на шлюз, який веде до адресата.
D- означає, що цей маршрут був добавлений в таблицю з тої причини, що з одного із шлюзів прийшов ICMP-пакет, який показує на адресу шлюзу, який був відсутній в таблиці. І тоді в таблиці маршрутів в полі Flag буде комбінація UGD. Це означає, що маршрут активний (U), пакети направляються на шлюз (G), (D)- цей маршрут отриманий в результаті повідомлення ICMP для перенаправлення пакетів, тобто такого маршруту спочатку в таблиці небуло.
Якщо локальна мережа підключається до провайдера, то все зводиться до отримання адреси з мережі провайдера для зовнішнього інтерфейсу, тобто інтерфейсу який буде звязувати локальну мережу з адресою шлюзу провайдера та адресою своєї мережі (підмережі).
Якщо провайдер небуде міняти структуру своєї мережі, то все буде працювати роками, але якщо є поділ на мережі і підмережі і ще й за неієрархічним принципом, то задача значно ускладнюється. Тому зявилася динамічна маршрутизація у вигляді протокола RIP.
№2
П'єзоелектричні
динаміки служать для генерації звуків.
Вони мають максимальну вхідну напругу
50 В і номінальний струм 10 мА. На рисунку
1 зображена схема, що використовує буфер
КМОН/ТТЛ для
керування таким динаміком. Схема пристрою
керування на транзисторі ZTX300
наведена на
рисунку 2. Щоб отримати звук, необхідно
подати на вхід послідовність імпульсів.
Рисунок 1 – Схема керування п’єзоелектричним динаміком на базі буфера ТТЛ/КМОН
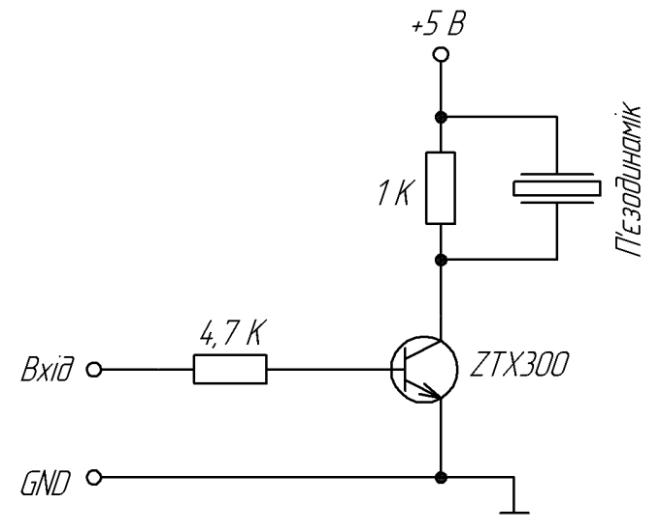
Рисунок 2 – Схема керування п’єзоелектричним динаміком на транзисторі
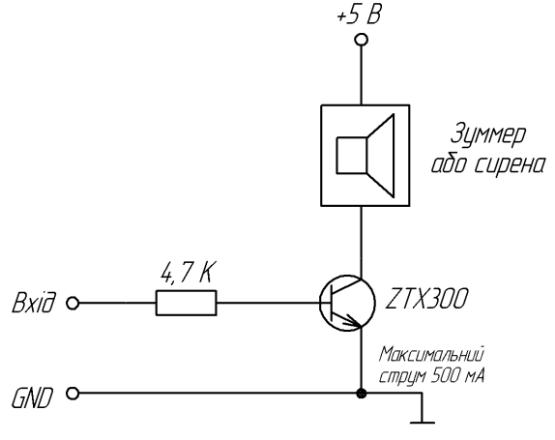
Рисунок 3 – Схема керування зумером або сиреною
Напівпровідникові зумери – це автономні динаміки, здатні генерувати тон, частотою близько 450 Гц. На рисунку 3 наведена схема керування на транзисторі ZTX300. Для генерації звуку на базу ZTX300 необхідно подати високий рівень напруги. При керуванні сиренами можна використовувати такі ж схеми.
Ультразвукові перетворювачі призначені для генерації ультразвуку. Зазвичай вони застосовуються в пристроях дистанційного керування, вимірювання і передачі даних, наприклад в ультразвуковому вимірювачі відстаней і детекторах руху об'єкта. На рисунку 4 зображена схема, яка генерує сигнал частотою 38,4 кГц.
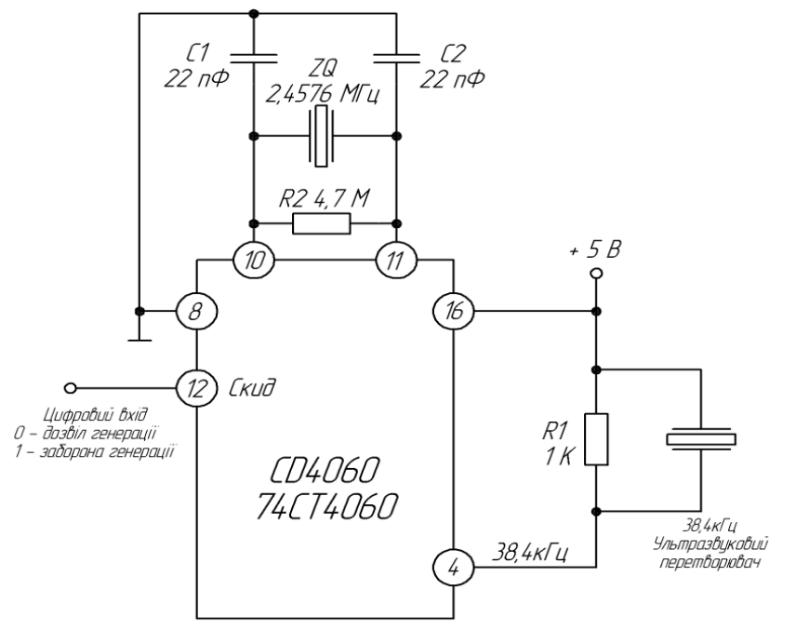
Рисунок 4– Схема генератора ультразвуку
№3
На рис.4.3,а наведена схема підсилювача постійного струму на одному транзисторі. Для таких підсилювачів характерне двополярне живлення, тобто використання двох джерел живлення з напругами +Ек і -Ее відносно землі.

Рис.4.3. Варіанти підсилювальних каскадів із двополярним (а) та однополярним (б) живленням
У принципі можна використовувати й однополярне живлення (рис.4.3,б). Проте в такому варіанті можуть виникати серйозні труднощі. По-перше, потрібне спеціальне джерело зміщення Еб. По-друге, джерело сигналу не має заземленої точки, що виключає використання більшості типових джерел сигналу і різко підвищує рівень паразитних наводок (завад) на вході підсилювача. Якщо поміняти місцями джерела сигналу і зміщення, то високий рівень завад залишається, а реалізувати схемним шляхом неза-
землене джерело зміщення практично неможливо.
Нехай вхідний сигнал Vвх=0. Тоді в схемі протікають постійні скла-
дові струмів, зумовлені джерелами Ек і Ее. Режим відсутності сигналу прийнятоназивати режимом спокою підсилювача.
При наявності вхідного сигналу до постійних складових додаються змінні складові, пропорційні значенню Vвх. В робочому режимі повні значення напруг і струмів можна записати у вигляді: V=V+V; I=I+I. Тут верхній індекс "0" присвоєно постійним складовим, а змінні складові позначені як прирости.

Обійшовши вхідний контур схеми (рис.4.4), отри-маємо рівняння:
ІбRб+V*+IeRe-Ee=0 (4.13).
Рис.4.4.
Еквівалентна схема каскаду для постійних
складових
Іе=(Ее-V*)[(Re+(1-)Rб)]. (4.14)
Потенціал колектора має вигляд
Vк=Ек-ІкRк, (4.15)
де Ік=Іе.
Значення Іе і Vк задаються заздалегідь. Їхня сукупність визначає, як кажуть, робочу точку транзистора в режимі спокою. Напругу живлення Ек також задано; тоді з виразу (4.16) однозначно отримаємо необхідне спів-відношення Rк.
Щодо значень Ее і Rе, то обидві вони повинні бути достатньо великими з тим, щоб змінення параметрів і V* не здійснювали помітного впливу на струм Іе. Можна сказати, що вибір значень Ее і Rе визначається бажаною стабільністю робочої точки транзистора при зміненнях температури й інших чинників.
Опір Rе вибирають за умови
Re>>(1-)Rб. (4.16)
Наприклад, якщо Rб=2кОм і =0,99 (тобто =100), то опір Re повинен бути не менше 200 Ом.