

4.5.Многотабличные запросы
До сих пор мы рассматривали однотабличные запросы, однако на практике довольно часто приходится иметь дело с многотабличными запросами. Например, предположим, что требуется выполнить запрос, реализующий вывод списка служащих и офисов, в которых они работают (таблицы SLUZHASCHIE и OFFISY) или вывод списка заказов, выполненных за заданный период, включая следующую информацию: наименование заказанного товара, стоимость заказа и имя клиента (таблицы ZAKAZY, CLIENTY и TOVARY).
Для ответа на эти вопросы SQL обеспечивает возможность выполнения многотабличных запросов, объединяющих данные из нескольких таблиц.
4.5.1.Алгоритм выполнения многотабличного запроса
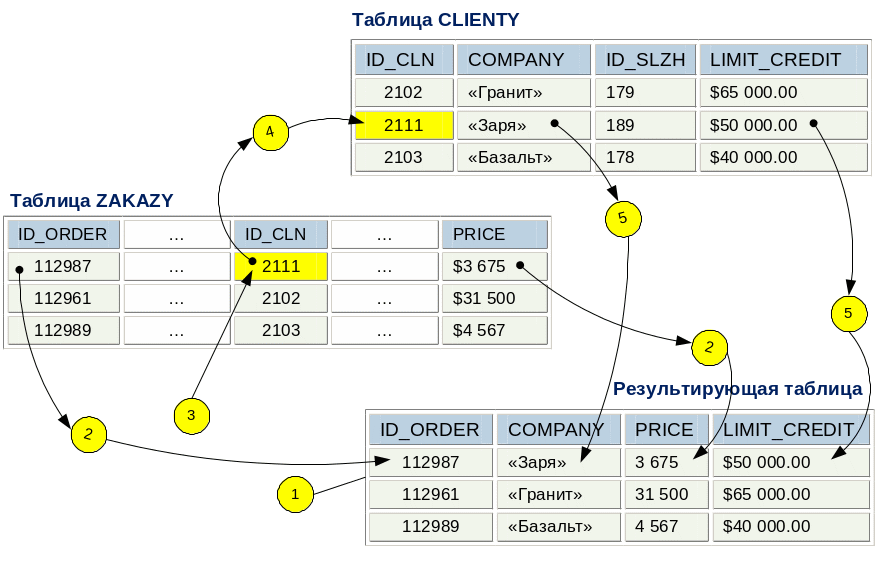
Рассмотрим порядок выполнения многотабличного запроса на примере запроса, объединяющего данные из двух различных таблиц (см. Рис. 1.1. ). Допустим, что требуется вывести список всех заказов, включая номер и стоимость заказа, фамилию и имя клиента. Перечисленные данные содержатся в следующих таблицах:
Номер (ID_ORDER) и Стоимость (PRICE) заказа содержатся в таблице ZAKAZY;
Имя клиента (COMPANY) и лимит кредита (LIMIT_CREDIT) содержатся в таблице CLIENTY .
Рассмотрим умозрительный порядок выполнения данного заказа.
Сначала построим результирующую таблицу, содержащую четыре перечисленные выше колонки (ID_ORDER, COMPANY, PRICE, LIMIT_CREDIT).
Найдите в таблице ZAKAZY Номер и Стоимость первого заказа (первой записи) и перепишите полученные значения в поля ID_ORDER и PRICE результирующей таблицы.
Запомните Номер клиента (ID_CLN) для первой записи таблицы ZAKAZY.
Перейдите к таблице CLIENTY и в столбце ID_CLN найдите значение, соответствующее запомненному значению поля ID_CLN для первой записи таблицы ZAKAZY.
Отыщите Имя клиента и Лимит кредита для найденной записи таблицы CLIENTY и перепишите их в поля COMPANY и LIMIT_CREDIT результирующей таблицы.
Таким образом, мы создали одну строку результирующей таблицы. Далее повторите шаги 2 5 до тех пор, пока не будут перечислены все заказы.
В данном алгоритме можно зафиксировать два важных момента:
каждая строка результирующей таблицы формируется из пары строк: одна строка находится в таблице ZAKAZY, а другая в таблице CLIENTY .
любая пара строк определяется по совпадению значений ключевых полей.
4.5.2.Внутреннее объединение таблиц
Описанный выше процесс формирования пар строк для записи в результирующую таблицу называется объединением таблиц.
|
Рис. 1.1. Алгоритм выполнения многотабличного запроса |
Объединение таблиц по равенству
Объединение на основе точного совпадения значений двух и более столбцов называется объединением по равенству. Объединения могут быть сформированы и на других видах сравнения значений столбцов (например, «больше» или «меньше»).
В реляционной базе данных информация между таблицами формируются путем сопоставления значений соответствующих столбцов. Таким образом, объединения являются мощным средством выявления отношений, существующих между данными. По этой причине оператор SELECT для многотабличного запроса должен содержать условие отбора, определяющее взаимосвязь между столбцами таблиц.
Приведем пример многотабличного запроса для описанного выше алгоритма: вывести список всех заказов, включающий номер и стоимость заказа, наименование компании-клиента и лимит кредита клиента.
SELECT ID_ORDER, COMPANY, PRICE, CREDIT_LIMIT
FROM ZAKAZY, CLIENTY
WHERE ZAKAZY.ID_CLN = CLIENTY.ID_CLN
Обратите внимание на то, что в приведенном запросе нет указаний о том, как должен выполняться запрос. В запросе ничего не сказано, с какой таблицы начинать выполнение процесса выборки, какую запись таблицы рассматривать первой, а какую второй. В запросе указывается лишь то, каким должен быть результат выполнения запроса: из каких таблиц и значения каких полей должны содержаться в результирующей таблице. Порядок выполнения запроса определяет СУБД. Этим и отличается язык SQL от алгоритмических языков типа C++ и Pascal.
Приведенный пример многотабличного запроса похож на однотабличные запросы за исключением следующих различий:
Предложение FROM содержит две таблицы, а не одну.
В предложении WHERE сравниваются связанные столбцы разных таблиц.