

Глава 1.Файловые системы и базы данных
С данными людям приходилось иметь дело с самого начала развития человеческого общества. На заре человечества данные сохранялись в виде наскальных рисунков, затем появились пиктограммы и клинопись. С изобретением алфавита сохранение данных упростилось, и с тех пор технология обмена информацией постоянно совершенствуется.
Независимо от того, какие методы использовались в прошлом или используются в наши дни, основная идея информационных технологий остается неизменной: сохранение, получение и отображение данных остаются основными функциями любой системы. Идея состоит в том, чтобы сохранять данные так, чтобы ими могли воспользоваться другие люди. Сегодня все сводится к работе с информацией, и к этому все будет сводиться в будущем.
Какую бы сферу человеческой деятельности вы не затронули: торговлю, медицину, образование, промышленность, сферу развлечений или управления, – везде главенствующую роль в организационных процессах играют средства накопления, обработки и передачи данных. Сегодня уже невозможно представить торговое предприятие без информационной системы учета операций, банк – без централизованной базы данных, мгновенный доступ к которой может получить любое отделение в любой точке страны.
Для обеспечения эффективного хранения данных, а это означает быстрый поиск, обновление данных, защиту от ошибочных вводов, обеспечение конфиденциальности информации и многое другое, необходима соответствующая их организация. Для быстрого поиска необходимо упорядочение хранимых данных, поддержание связей между ними, контроль на непротиворечивость, обеспечение однократного ввода или изменения при многократном последующем использовании.
Ключевую роль при этом играют методы поддержания логических связей между данными. Именно эти методы рассматриваются в моделях данных, разработанных в рамках развития концепции баз данных, пришедшей на смену файловым системам, в которых преимущественно рассматривались вопросы доступа к данным.
Термин база данных относится к совместно используемому набору логически связанных данных (и описанию этих данных), предназначенному для удовлетворения информационных потребностей организации. В случае баз данных на внешнем носителе хранятся данные совместно с их описанием, в то время как в файлах хранятся просто двоичные данные, логическое описание которых содержится в соответствующих программах в неявном виде.
База данных это единое, большое хранилище данных, которое однократно определяется, а затем используется одновременно многими пользователями представителями разных подразделений. Вместо разрозненных файлов с избыточными данными здесь все данные собраны вместе с минимальной долей избыточности. База данных уже не принадлежит какому-либо единственному отделу, а является общим корпоративным ресурсом.
|
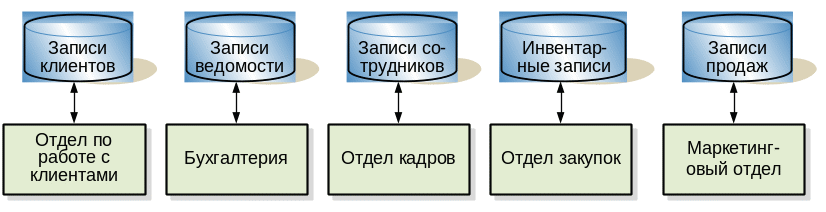
Рис. 1.1. Файловая информационная система |
1.2.История систем управления данными
Исторически базы данных развивались как способ интеграции систем хранения данных. С развитием компьютерных технологий для них находилось все больше применений в управлении информацией и начали создаваться информационные системы для автоматизации деятельности бухгалтерий, отделов кадров, отделов закупок и т. д. Каждая такая информационная система имела свой собственный набор данных (см. Рис. 1.1. ). Сначала эти данные хранились в последовательных файлах, затем появились файлы, основанные на индексировании.
Хотя с появлением индексированных файлов эффективность работы систем существенно повысилась, но набор отдельных информационных систем в пределах одной организации все же является неэффективной тратой ресурсов по сравнению возможностями интегрированной системы базы данных. Например, если в каждом подразделении предприятия использовалась своя файловая система, то большая часть информации, хранимой в организации, дублировалась в этих хранилищах. В результате, например, при смене места жительства сотрудника приходилось корректировать файлы во всех подразделениях, где содержалась информация об адресах сотрудников.
Для решения этой проблемы на первых этапах развития технологии информационных систем для хранения данных создавались файлы коллективного доступа, разрабатываемые в едином центре. Но у файлов коллективного доступа имелись серьезные недостатки. Структура записей в файлах и наборы отношений, реализуемые в прикладных программах, были «жесткими», и их изменение означало перестройку отношений в прикладных программах.
Структуры данных, используемые при решении задачи комплексной автоматизации, как правило, связаны между собой сложными взаимосвязями. При отсутствии поддержки отношений между данными в файловой системе связи между данными приходилось реализовывать в прикладных программах. Этот дополнительный код, предназначенный для управления данными, практически повторялся от одной системы к другой и составлял существенную часть прикладных программ.
|
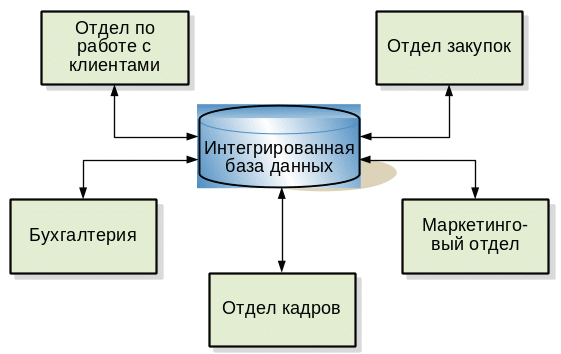
Рис. 1.1. Информационная система с базой данных |
История систем управления данными во внешней памяти началась с появлением магнитных дисков. Первым попытку расширить возможности работы с дисками путем создания СУБД предпринял еще в 1961 г. Чарльз Бахман. Тогда он работал в фирме General Electric, а потому разработка велась на машине этой компании, а созданная им «интегрированная система хранения» могла работать только на этой машине.
Дальнейшее развитие этой идеи предпринял Джон Куллиан. Он был предпринимателем и ему первому пришла в голову оригинальная для того времени идея: продавать ПО для компьютеров. Он не стремился разрабатывать свои программы «с нуля»; наряду с собственными разработками он покупал отдельные программы сторонних организаций, производящих программную продукцию, дорабатывал их соответствующим образом и продавал готовые, более сложные изделия на рынке.
На этом поприще он оказался чрезвычайно успешным, но вскоре столкнулся с тем, что для интеграции приобретенных и разрабатываемых продуктов нужна единая система управления данными. На основании анализа альтернативных решений выбор пал на «интегрированную систему хранения» Бахмана, и это было исключительно верным решением. Система Бахмана, названная Куллианом СУБД, отлично работала на мейнфреймах IBM и совместимых с ними машинах.
Система, созданная на основе «интегрированной системы хранения» Бахмана, была совсем простой: вся СУБД упаковывалась в один файл, а таблицы, содержащие сведения о размещении данных, создавались вручную. Но в этой системе был использован революционный подход: доступ к данным осуществлялся не непосредственно, как в файловой системе, а через описание данных. Здесь необходимо отметить, что описание файлов, используемое файловой системой касается только способов доступа, а в СУБД Бахмана были использованы описание самих данных, т. е. описание их структуры и взаимосвязей между ними.
Описание данных Бахмана было представлено в виде иерархической системы «указателей», помогающих осуществить доступ к конкретной ячейке памяти. Эта незамысловатая работа оказала колоссальное влияние на развитие ПО, за что Бахман получил Тьюринговскую премию, а это аналог Нобелевской в области ВТ.
СУБД Бахмана строились с использованием иерархических и сетевых моделей и были названы им навигационными, поскольку для перемещения по записям использовались «указатели» или «пути», что отличает их от реляционных СУБД, где используются принципы логического программирования.
К появлению современных реляционных СУБД привела другая революционная идея, предложенная Коддом. Он в 1970 г. опубликовал статью, содержащую описание простой модели данных, согласно которой база данных составляется из таблиц. Таблицы эти особенные, и их особенность заключается в том, что в них не должно быть одинаковых строк. Поэтому эти таблицы были названы реляциями, а сама модель реляционной.
Но основное достоинство реляционных моделей данных заключалось не в их простоте, хотя и это имело большое значение, а в том, что в них были применены принципы нечисловой или ассоциативной обработки данных. В соответствии с этими принципами данные связываются в соответствии с их внутренними логическими взаимоотношениями, а не физическими указателями, как это делалось в иерархической и сетевой моделях. В основе этих принципов лежит ассоциативный, а не адресный поиск, и взаимосвязи между элементами данных устанавливаются в соответствии со значениями их атрибутов, а не путем искусственного соединения с помощью указателей.
При числовой обработке данных содержание данных практически не используется. Допустим, что мы хотим вычислить сумму элементов массива. При этом достаточно указать адрес начального элемента массива, а затем накапливать сумму элементов в некотором регистре, индексируя соответствующим образом адреса. В ходе этого вычисления нас не интересуют текущие значения суммируемых переменных, мы просто должны проверять некоторые переменные, влияющие на ход выполнения программы (например, достигнут или нет конец массива).
При ассоциативной обработке нас в первую очередь интересуют сведения об объектах и их свойствах. При этом мы можем запросить сведения о студенте, указав его фамилию, имя или номер зачетной книжки, или узнать имена всех преподавателей моложе 40 лет, чей оклад выше 300 000 руб.
Для пояснения принципов ассоциативной обработки данных приведем следующий простой пример. Допустим, у нас имеются сведения о студентах и группах, в которых они обучаются, представленные в таблице ГРУППЫ с полями Код, Наименование, и в таблице СТУДЕНТЫ с полями Номер зачетной книжки, Фамилия, Имя, Отчество, Код_группы. По этим данным, используя принципы ассоциативной обработки, а именно сравнивая значения полей Код таблицы ГРУППЫ и Код_группы таблицы СТУДЕНТЫ, мы можем определить в какой группе учится каждый студент, сколько студентов учится в каждой группе, вывести список студентов каждой группы и т. д. Как видно из приведенного примера, при ассоциативной обработке решение задач сводится к сопоставлению или ассоциации значений признаков обрабатываемых данных, т. е. используется содержание данных, а не адрес.
Таким образом, пользователи смогут комбинировать данные из разных источников, если логическая информация, необходимая для такого комбинирования, присутствует в исходных данных. Это открыло новые возможности для информационных систем, поскольку запросы к базе данных теперь не были ограничены физическими указателями и для их реализации уже не приходилось писать программы.
В последующем между Бахманом и Коддом велась активная полемика. Бахман всячески пытался доказывать преимущества навигационных баз данных, но был вынужден уступить перед математической строгостью реляционного подхода и возможностями языка запросов SQL. В модели данных Бахмана содержалась минимальная информация о данных и эта модель, названная навигационной, имела процедурный характер, в то время как реляционная модель содержит обширную декларативную информацию о содержащихся в памяти данных.
Для сравнения навигационного и реляционного (ассоциативного) подходов реализации СУБД можно использовать классический пример, в котором для описания пункта назначения применяются различные способы.
При использовании навигационного подхода путь до объекта можно указать так: «Едете по шоссе 25 км, поворачиваете направо и продолжаете движение до третьего населенного пункта. Нам нужен 3-й дом с левой стороны».
Ассоциативный подход, используемый в рамках реляционной СУБД, позволяет просто указать: «Желтый дом в населенном пункте N».
Навигационный подход используется тогда, когда таксист новичок плохо ориентируется на местности, т. е. у него нет сведений о географии местности, и ему нужно подробно описать, как доехать до места назначения.
СУБД, в которой реализована реляционная модель, можно сравнить с опытным таксистом, хорошо ориентирующимся в местности, которому достаточно назвать признаки искомого объекта, а путь к этому объекту он определит сам на основе имеющейся у него информации. Простота доступа к данным в реляционной модели объясняется тем, что СУБД обладает описанием наличных данных и может сама отыскать требуемую информацию без приведения подробной информации относительно пути доступа.
Хотя реляционная модель одержала решительную победу над навигационной, и реляционные базы данных занимают доминирующее положение на рынке, сегодня правота Кодда уже не столь безусловна. С появлением языка XML началась реставрация навигационного подхода. Но это уже тема для другой дисциплины, хотя в нашем курсе лекций мы вкратце рассмотрим основы XML-технологии, так как их роль в современных системах обработки данных чрезвычайно велика, и совместное использование концепции баз данных и XML-технологии позволяет создавать эффективные информационные системы.