

1.4.2.Субд в составе информационной системы
Отделение логической структуры от физической в рамках файловой системы, а затем обеспечение независимости программ от данных в рамках концепции баз данных, привело к появлению нескольких уровней представления информации. В соответствии с этим информационные системы, реализованные на основе баз данных, также рассматриваются как сложное многоуровневое программное обеспечение.
1. На самом верхнем уровне прикладная программа формулирует свои запросы на языке SQL, используя термины логической схемы базы данных, и направляет на вход СУБД.
2. Интерфейсная составляющая СУБД проводит синтаксический и семантический анализ запроса с использованием метаданных и определяет унифицированную процедуру, отвечающую за выполнение запроса.
3. Унифицированная процедура СУБД, в соответствии с атрибутами, заданными в запросе, выполняет запрос на уровне физической схемы в памяти машины.
Общую организацию системы, содержащую в своем составе СУБД, можно описать с помощью схемы, приведенной на Рис. 1.1.
До сих пор мы не вычленяли СУБД из состава информационной системы, рассматривая ее как неотъемлемую часть общей структуры, создаваемую вместе со всей системой. Данной архитектуре информационной системы свойственны два дефекта:
|
Рис. 1.1. СУБД в составе информационной системы |

во-первых, очевидно, что СУБД должна поддерживать достаточно развитую функциональность. Повторять эту функциональность в каждой информационной системе неразумно;
во-вторых, набор файлов можно назвать базой данных только при наличии метаданных, следовательно, метаданные принадлежат только данной информационной системе. Применительно к нашей информационной системе, в этом случае файлы СЛУЖАЩИЕ и ОТДЕЛЫ можно использовать только через нашу систему регистрации служащих.
1.4.3.Выделение субд в качестве отдельного компонента информационной системы
Предположим, что предприятию нужна еще и информационная система для бухгалтерского учета. Очевидно, что для ее работы также потребуются данные о служащих и отделах. При показанной выше организации системы возможны два варианта выполнения задачи, ни один из которых не является удовлетворительным.
1. Внедрить бухгалтерскую систему в состав системы регистрации служащих. Но, как правило, бухгалтерские системы покупаются в виде готовых и отдельных продуктов, не приспособленных к подобному «внедрению».
2. Скопировать метаданные системы регистрации служащих в бухгалтерскую систему. Но метаданные (как и данные) не обязательно являются статичными. Структура базы данных может со временем изменяться, могут исчезать одни правила целостности и появляться другие. Поэтому в данном варианте возникает проблема согласования копий метаданных, поддерживаемых независимыми информационными системами.
Так мы приходим к организации информационной системы, показанной на Рис. 1.1. . Здесь мы видим три информационные системы, которые через одну СУБД работают с двумя разными базами данных, причем первая и вторая системы работают с общей базой данных. Это возможно, поскольку метаданные каждой базы данных содержатся в самих базах данных, и достаточно лишь указать СУБД, с какой базой данных желает работать данное приложение.
Поскольку СУБД функционирует отдельно от приложений, и ее работа с базами данных регулируется метаданными, совместное использование одной базы данных двумя информационными системами не вызовет потери согласованности данных, и доступ к данным будет должным образом синхронизироваться.
|
Рис. 1.1. Отдельная СУБД и база данных с метаданными |
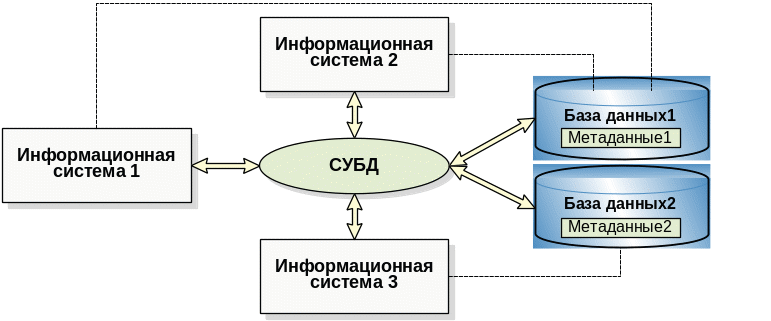
Заметим, что схема, приведенная на Рис. 1.1. , вплотную приближает нас к наиболее распространенной в последние десятилетия архитектуре «клиент-сервер». СУБД в этой архитектуре играет роль «сервера», обсуживающего нескольких «клиентов» – прикладных информационных систем.
Таким образом, выделение СУБД в самостоятельный компонент информационной системы решает множество проблем, которые затруднительно или вообще невозможно решить при использовании СУБД, встроенных в информационные системы.