

3. Загрузка данных (loading) – запись преобразованных данных в в хранилище данных
Причины отказа в загрузке некоторых записей:
На этапе преобразования данных не удалось исправить все критические ошибки, которые блокируют загрузку записей в ХД
Некорректный порядок загрузки данных
Внутренние проблемы хранилища данных, например недостаток места в нем
Прерывание процесса загрузки или остановка его пользователем
59.Характеристика иерархической, сетевой, реляционной, объектно-ориентированной и многомерной моделей представления данных.
Модель представления данных – множество элементов (объектов, типов данных) и связей (отношений) между ними, ограничений (например, целостности, синхронизации многопользовательского доступа, авторизации) операций над типами данных и отношениями
Иерархическая модель
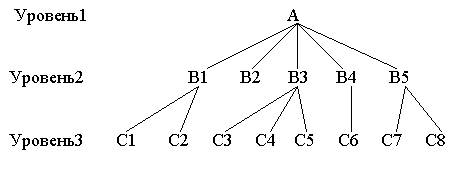 –
Иерархическая модель представляет
собой ориентированный граф (перевернутое
дерево) объектов, связанных иерархическими
отношениями Характеризуется: уровнем,
узлом и связями между узлами.(
IMS, Data Edge,
Ока)
–
Иерархическая модель представляет
собой ориентированный граф (перевернутое
дерево) объектов, связанных иерархическими
отношениями Характеризуется: уровнем,
узлом и связями между узлами.(
IMS, Data Edge,
Ока)
Достоинства иерархической модели данных
Простота понимания
Простота оценки операционных характеристик
Хорошие временные показатели выполнения операций над данными
Недостатки иерархической модели данных
Структура данных задается на этапе проектирования БД и не может быть изменена при организации доступа к данным
Громоздкость модели для обработки информации со сложными логическими связями
Отношения М : М могут быть реализованы только искусственно
Возможны избыточные данные
Удаление исходных объектов ведет к удалению порожденных объектов
Доступ к любому порожденному узлу возможен только через корневой узел
Ограниченный набор структур запроса
Сетевая модель данных - при тех же основных понятиях (уровень, узел, связь) каждый элемент может быть связан с любым другим элементом, связанных иерархическими отношениями. (db_Vista, КОМПАС)
Достоинства сетевой модели данных
В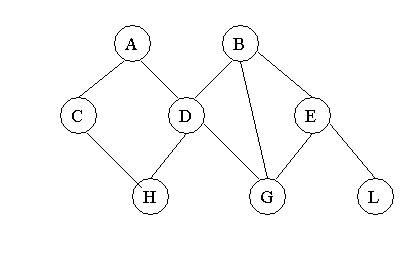 озможность
эффективной реализации по показателям
затрат памяти и оперативности
озможность
эффективной реализации по показателям
затрат памяти и оперативности
Сохранение информации при уничтожении владельца
Более богатая, чем в иерархической модели данных, структура запросов
Недостатки сетевой модели данных
Структура данных задается на этапе проектирования БД и не может быть изменена при организации доступа к данным
Жесткость схемы базы данных, построенной на ее основе
Сложность структуры (для навигации в наборах и записях прикладной программист должен детально знать логическую структуру базы данных)
Возможна потеря независимости данных при реорганизации БД
Представление в прикладной программе сложнее, чем в иерархической модели данных
Реляционная модель данных (виде таблицы).
Достоинства реляционной модели данных
Простота работы и отражение представлений пользователя
Гибкость (соединение, разделение файлов)
Простота внедрения плоских файлов
Отделение от физической реализации (независимость)
Произвольная структура запросов
Хорошее теоретическое обоснование
Недостатки реляционной модели данных
Сложность структуры, вызванная процессом нормализации
Низкая производительность из-за поиска по ключу Ограниченный набор типов данных
Недостаточное естественное представление данных
Невозможность рассмотрения данных послойно, на разных уровнях абстракции
М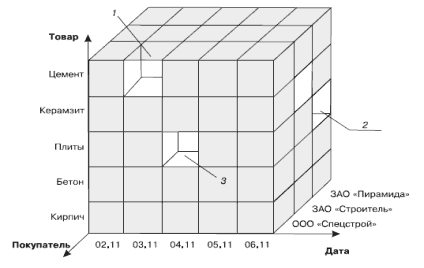 ногомерная
модель данных
ногомерная
модель данных
Многомерная модель: В основе многомерного представления данных лежит их разделение на две группы – измерения и факты. Многомерная модель данных реализуется с помощью многомерных кубов.
Измерения – это категориальные атрибуты, наименования и свойства объектов, участвующих в некотором бизнес-процессе (наименования товаров, названия фирм-поставщиков и покупателей, ФИО людей, названия городов и т. д.)
 Факты
– это данные, количественно описывающие
бизнес-процесс, непрерывные по своему
характеру, то есть они могут принимать
бесконечное множество значений (цена
товара или изделия, их количество,
сумма продаж или закупок, зарплата
сотрудников, сумма кредита,
страховое вознаграждение и т. д.)
Факты
– это данные, количественно описывающие
бизнес-процесс, непрерывные по своему
характеру, то есть они могут принимать
бесконечное множество значений (цена
товара или изделия, их количество,
сумма продаж или закупок, зарплата
сотрудников, сумма кредита,
страховое вознаграждение и т. д.)
Многомерный куб можно рассматривать как систему координат, осями которой являются измерения (например, Дата, Товар, Покупатель). По осям будут откладываться значения измерений
Из многомерного куба может быть составлен обычный плоский отчёт. По столбикам и строчкам отчёта будут бизнес-категории (грани куба), а в ячейках показатели. Сечение (срез) - формируется подмножество многомерного массива данных, соответствующее единственному значению одного или нескольких элементов измерений, не входящих в это подмножество. Вращение - изменение расположения измерений, представленных в отчете или на отображаемой странице. Свертка – замена одного или нескольких подчиненных значений измерений теми значениями, которым они подчинены. При этом уровень обобщения данных увеличивается. Детализация - процедура обратная свертке, уменьшает уровень обобщения данных
Преимущества многомерного подхода
Представление данных в виде многомерных кубов более наглядно, чем совокупность нормализованных таблиц реляционной модели, структуру которой представляет только администратор БД
Возможности построения аналитических запросов к системе, использующей МХД, более широки
В некоторых случаях использование многомерной модели позволяет значительно уменьшить продолжительность поиска в МХД, обеспечивая выполнение аналитических запросов практически в режиме реального времени
Недостатки использования многомерной модели 1) Для ее реализации требуется больший объем памяти. 2) Многомерная структура труднее поддается модификации.
 Системы:
Essbase, Media
Multi-matrix,
Oracle Express
Server, Cache.
Многие программные продукты позволяют
одновременно работать с многомерными
и с реляционными БД.
Системы:
Essbase, Media
Multi-matrix,
Oracle Express
Server, Cache.
Многие программные продукты позволяют
одновременно работать с многомерными
и с реляционными БД.
Объектно-ориентированная модель
Структура объектно-ориентированной модели графически представима в виде дерева, узлами которого являются объекты. Свойства объектов описываются некоторым стандартным типом или типом, конструируемым пользователем (определяется как class).
Инкапсуляция ограничивает область видимости имени свойства пределами того объекта, в котором оно определено.
Наследование, наоборот, распространяет область видимости свойства на всех потомков объекта.
Полиморфизм означает способность одного и того же программного кода работать с разнотипными данными.
Достоинства объектно-ориентированной модели данных
В сравнении с реляционной у этой модели есть возможность отображения информации о сложных взаимосвязях объектов.
Позволяет идентифицировать отдельную запись базы данных и определять функции их обработки
Недостатки объектно-ориентированной модели данных 1) Высокая понятийная сложность. 2) Неудобство обработки данных. 3) Низкая скорость выполнения запросов
60. Информация, знания, данные. Меры информации. Технологии обработки данных.
Информация — это сведения об объектах и явлениях окружающей среды, их параметрах, свойствах и состоянии, которые уменьшают имеющуюся о них степень неопределенности, неполноты знаний
Информационные процессы - это процессы передачи, хранения и переработки информации.
Свойства информации: достоверность; полнота; ценность; своевременность; понятность; доступность; краткость; и др.
Виды информации: Числовая, Текстовая, Кодовая, Графическая, Акустическая представлена звуками, Видеоинформация.
Знания – это закономерности, принципы, связи, законы предметной области, полученные в результате практической деятельности и профессионального опыта.
Типы:
эмпирическими (на основе опыта или наблюдения)
теоретическими (на основе анализа абстрактных моделей).
Данные – это отдельные факты, характеризующие объекты, процессы и явления предметной области, а также их свойства. Данные – (ГОСТ) информация, представленная в виде, пригодном для обработки автоматическими средствами при возможном участии человека. (Структурированные и неструктурированные).
М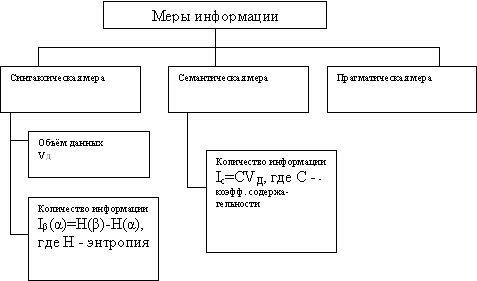 еры
информации.
еры
информации.
Синтаксическая мера информации. Эта мера количества информации оперирует с обезличенной информацией, не выражающей смыслового отношения к объекту. На синтаксическом уровне учитываются тип носителя и способ представления информации, скорость передачи и обработки, размеры кодов представления информации.
Объём данных (VД) понимается в техническом смысле этого слова как информационный объём сообщения или как объём памяти, необходимый для хранения сообщения без каких-либо изменений.
Информационный объём сообщения измеряется в битах и равен количеству двоичных цифр (“0” и “1”), которыми закодировано сообщение.
В компьютерной практике слово “бит” используется также как единица измерения объёма памяти. Ячейка памяти размером в 1 бит может находиться в двух состояниях (“включено” и “выключено”) и в неё может быть записана одна двоичная цифра (0 или 1). Понятно, что бит — слишком маленькая единица измерения информации, поэтому пользуются кратными ей величинами. Основной единицей измерения информации является байт. 1 байт равен 8 битам. В ячейку размером в 1 байт можно поместить 8 двоичных цифр, то есть в одном байте можно хранить 256 = 28 различных чисел.
Семантическая мера информации - Для измерения смыслового содержания информации, т.е. ее количества на семантическом уровне, наибольшее признание получила тезаурусная мера, которая связывает семантические свойства информации со способностью пользователя принимать поступившее сообщение. Для этого используется понятие тезаурус пользователя.
Тезаурус — это совокупность сведений, которыми располагает пользователь или система.
Прагматическая мера информации - Эта мера определяет полезность информации (ценность) для достижения пользователем поставленной цепи. Эта мера также величина относительная, обусловленная особенностями использования этой информации в той или иной системе.
Мера информации |
Единицы измерения |
Примеры (для компьютерной области) |
Синтаксическая: шенноновский подход компьютерный подход |
Степень уменьшения неопределенности Единицы представления информации |
Вероятность события Бит, байт. Кбайт и та |
Семантическая |
Тезаурус Экономические показатели
|
Пакет прикладных программ, персональный компьютер, компьютерные сети и т.д. Рентабельность, производительность, коэффициент амортизации и тд. |
Прагматическая |
Ценность использования |
Емкость памяти, производительность компьютера, скорость передачи данных и т.д. Денежное выражение Время обработки информации и принятия решений |
Технологии
обработки данных.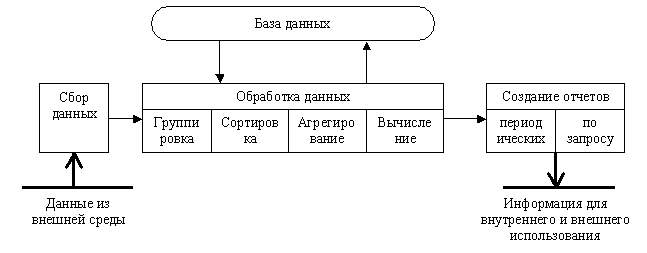
Информационная технология обработки данных предназначена для решения хорошо структурированных задач, по которым имеются необходимые входные данные и известны алгоритмы и другие стандартные процедуры их обработки. Эта технология применяется на уровне операционной (исполнительской) деятельности персонала невысокой квалификации в целях автоматизации некоторых рутинных постоянно повторяющихся операций управленческого труда.
На уровне операционной деятельности решаются следующие задачи:
- обработка данных об операциях, производимых фирмой;
- создание периодических контрольных отчетов о состоянии дел в фирме;
- получение ответов на всевозможные запросы.
Существует несколько особенностей, связанных с обработкой данных:
- выполнение необходимых фирме задач по обработке данных.
- решение только хорошо структурированных задач, для которых можно разработать алгоритм;
- выполнение стандартных процедур обработки;
- выполнение основного объема работ в автоматическом режиме с минимальным участием человека;
- использование детализированных данных. Записи о деятельности фирмы имеют детальный характер, допускающий проведение ревизий;
- акцент на хронологию событий;
- требование минимальной помощи в решении проблем со стороны специалистов других уровней.
Основные компоненты:Сбор данных. Обработка данных.
Для создания из поступающих данных информации, отражающей деятельность фирмы, используются следующие типовые операции:
- классификация или группировка. Первичные данные обычно имеют вид кодов, состоящих из одного или нескольких символов.
- сортировка,
- вычисления, включающие арифметические и логические операции.
- агрегирование,
Хранение данных. Многие данные на уровне операционной деятельности необходимо сохранять для последующего использования. Для их хранения создаются базы данных.
Создание отчетов (документов).
61. Структурный и объектно-ориентированный подходы в программировании.
Структурное программирование — методология разработки программного обеспечения, в основе которой лежит представление программы в виде иерархической структуры блоков в соответствии с данной методологией. (pascal).
Любая программа представляет собой структуру, построенную из трёх типов базовых конструкций:
последовательное исполнение — однократное выполнение операций в том порядке, в котором они записаны в тексте программы;
ветвление — однократное выполнение одной из двух или более операций, в зависимости от выполнения некоторого заданного условия;
цикл — многократное исполнение одной и той же операции до тех пор, пока выполняется некоторое заданное условие (условие продолжения цикла).
Распространены две методики (стратегии) разработки программ:
Программирование «сверху вниз», или нисходящее программирование – это методика разработки программ, при которой разработка начинается с определения целей решения проблемы, после чего идет последовательная детализация, заканчивающаяся детальной программой.
Сначала выделяется несколько подпрограмм, решающих самые глобальные задачи (например, инициализация данных, главная часть и завершение), потом каждый из этих модулей детализируется на более низком уровне, разбиваясь в свою очередь на небольшое число других подпрограмм, и так происходит до тех пор, пока вся задача не окажется реализованной.
В данном случае программа конструируется иерархически - сверху вниз: от главной программы к подпрограммам самого нижнего уровня, причем на каждом уровне используются только простые последовательности инструкций, циклы и условные разветвления.
Такой подход удобен тем, что позволяет человеку постоянно мыслить на предметном уровне, не опускаясь до конкретных операторов и переменных. Кроме того, появляется возможность некоторые подпрограммы не реализовывать сразу, а временно откладывать, пока не будут закончены другие части. Например, если имеется необходимость вычисления сложной математической функции, то выделяется отдельная подпрограмма такого вычисления, но реализуется она временно одним оператором, который просто присваивает заранее выбранное значение. Когда все приложение будет написано и отлажено, тогда можно приступить к реализации этой функции
Программирование «снизу вверх», или восходящее программирование – это методика разработки программ, начинающаяся с разработки подпрограмм (процедур, функций), в то время когда проработка общей схемы не закончилась.
Такая методика является менее предпочтительной по сравнению с нисходящим программированием так как часто приводит к нежелательным результатам, переделкам и увеличению времени разработки.
Очень важная характеристика подпрограмм – это возможность их повторного использования. С интегрированными системами программирования поставляются большие библиотеки стандартных подпрограмм, которые позволяют значительно повысить производительность труда за счет использования чужой работы по созданию часто применяемых подпрограмм.
Подпрограммы бывают двух видов – процедуры и функции. Отличаются они тем, что процедура просто выполняет группу операторов, а функция вдобавок вычисляет некоторое значение и передает его обратно в главную программу (возвращает значение). Это значение имеет определенный тип.
Перечислим некоторые достоинства структурного программирования:
Структурное программирование позволяет значительно сократить число вариантов построения программы по одной и той же спецификации, что значительно снижает сложность программы и, что ещё важнее, облегчает понимание её другими разработчиками.
В структурированных программах логически связанные операторы находятся визуально ближе, а слабо связанные — дальше, что позволяет обходиться без блок-схем и других графических форм изображения алгоритмов (по сути, сама программа является собственной блок-схемой).
Сильно упрощается процесс тестирования и отладки структурированных программ.
Объектно-ориентированное прораммирование — парадигма программирования, в которой основными концепциями являются понятия объектов и классов. В случае языков с прототипированием вместо классов используются объекты-прототипы. (c++, Delphi).
Абстрагирование — это способ выделить набор значимых характеристик объекта, исключая из рассмотрения незначимые. Соответственно, абстракция — это набор всех таких характеристик.
Инкапсуляция — это свойство системы, позволяющее объединить данные и методы, работающие с ними, в классе и скрыть детали реализации от пользователя.
Наследование — это свойство системы, позволяющее описать новый класс на основе уже существующего с частично или полностью заимствующейся функциональностью. Класс, от которого производится наследование, называется базовым, родительским или суперклассом. Новый класс — потомком, наследником или производным классом.
Полиморфизм — это свойство системы использовать объекты с одинаковым интерфейсом без информации о типе и внутренней структуре объекта.
Класс является описываемой на языке терминологии (пространства имён) исходного кода моделью ещё не существующей сущности (объекта). Фактически он описывает устройство объекта, являясь своего рода чертежом. Говорят, что объект — это экземпляр класса. При этом в некоторых исполняющих системах класс также может представляться некоторым объектом при выполнении программы посредством динамической идентификации типа данных. Обычно классы разрабатывают таким образом, чтобы их объекты соответствовали объектам предметной области.
Объект - Сущность в адресном пространстве вычислительной системы, появляющаяся при создании экземпляра класса или копирования прототипа (например, после запуска результатов компиляции и связывания исходного кода на выполнение).
В центре ООП находится понятие объекта. Объект — это сущность, которой можно посылать сообщения, и которая может на них реагировать, используя свои данные. Данные объекта скрыты от остальной программы. Сокрытие данных называется инкапсуляцией.
Наличие инкапсуляции достаточно для объектности языка программирования, но ещё не означает его объектной ориентированности — для этого требуется наличие наследования.
Но даже наличие инкапсуляции и наследования не делает язык программирования в полной мере объектным с точки зрения ООП. Основные преимущества ООП проявляются только в том случае, когда в языке программирования реализован полиморфизм; то есть возможность объектов с одинаковой спецификацией иметь различную реализацию.
Достоинства:
Классы позволяют проводить конструирование из полезных компонент, обладающих простыми инструментами, что дает возможность абстрагироваться от деталей реализации.
Данные и операции вместе образуют определенную сущность и они не «размазываются» по всей программе, как это нередко бывает в случае процедурного программирования.
Локализация кода и данных улучшает удобство сопровождения программного обеспечения.
Инкапсуляция информации защищает критичные данные от несанкционированного доступа.
Обработка разнородных структур данных.. Новые виды могут быть добавлены в любой момент.
Изменение поведения во время выполнения.
Реализация родовых компонент
Доведение полуфабрикатов. Их можно сохранять в библиотеке в виде полуфабрикатов.
Расширение каркаса.
62. Современные инструментальные средства (среды), обеспечивающие реализацию методологии объектно-ориентированного программирования (классификация, основные особенности).
Объектно-ориентированное прораммирование (в дальнейшем ООП) — парадигма программирования, в которой основными концепциями являются понятия объектов и классов. В случае языков с прототипированием вместо классов используются объекты-прототипы.
J ava
— объектно-ориентированный язык
программирования, разработанный
компанией Sun Microsystems (в последующем
приобретённой компанией Oracle).
ava
— объектно-ориентированный язык
программирования, разработанный
компанией Sun Microsystems (в последующем
приобретённой компанией Oracle).
Язык Java зародился как часть проекта создания передового программного обеспечения (ПО) для различных бытовых приборов. Реализация проекта была начата на языке С++, но вскоре возник ряд проблем, наилучшим средством борьбы с которыми было изменение самого инструмента - языка программирования. Стало очевидным, что необходим платформо-независимый язык программирования, позволяющий создавать программы, которые не приходилось бы компилировать отдельно для каждой архитектуры и можно было бы использовать на различных процессорах под различными операционными системами. Язык Java потребовался для создания интерактивных продуктов для сети Internet. Фактически, большинство архитектурных решений, принятых при создании Java, было продиктовано желанием предоставить синтаксис, сходный с Си и Cи++. В Java используются практически идентичные соглашения для объявления переменных, передачи параметров, операторов и для управления потоком выполнением кода. В Java добавлены все хорошие черты C++.
Три ключевых элемента объединились в технологии языка Java:
- Java предоставляет для широкого использования свои апплеты (applets) — небольшие, надежные, динамичные, не зависящие от платформы активные сетевые приложения, встраиваемые в страницы Web. Апплеты Java могут настраиваться и распространяться потребителям с такой же легкостью, как любые документы HTML.
- Java высвобождает мощь объектно-ориентированной разработки приложений, сочетая простой и знакомый синтаксис с надежной и удобной в работе средой разработки. Это позволяет широкому кругу программистов быстро создавать новые программы и новые апплеты.
- Java предоставляет программисту богатый набор классов объектов для ясного абстрагирования многих системных функций, используемых при работе с окнами, сетью и для ввода-вывода. Ключевая черта этих классов заключается в том, что они обеспечивают создание независимых от используемой платформы абстракций для широкого спектра системных интерфейсов.
Python — высокоуровневый язык программирования общего назначения с акцентом на производительность разработчика и читаемость кода. Синтаксис ядра Python минималистичен. В то же время стандартная библиотека включает большой объём полезных функций.
Python поддерживает несколько парадигм программирования, в том числе структурное, объектно-ориентированное, функциональное, императивное и аспектно-ориентированное. Основные архитектурные черты — динамическая типизация, автоматическое управление памятью, полная интроспекция, механизм обработки исключений, поддержка многопоточных вычислений и удобные высокоуровневые структуры данных. Код в Питоне организовывается в функции и классы, которые могут объединяться в модули (которые в свою очередь могут быть объединены в пакеты).
Python — активно развивающийся язык программирования, новые версии (с добавлением/изменением языковых свойств) выходят примерно раз в два с половиной года. Вследствие этого и некоторых других причин на Python отсутствуют ANSI, ISO или другие официальные стандарты, их роль выполняет CPython.
C++ — компилируемый статически типизированный язык программирования общего назначения.
Поддерживает такие парадигмы программирования как процедурное программирование, модульность, раздельная компиляция, обработка исключений, абстракция данных, типы (объекты), виртуальные функции, объектно-ориентированное программирование, обобщенное программирование, контейнеры и алгоритмы, сочетает свойства как высокоуровневых, так и низкоуровневых языков. В сравнении с его предшественником — языком C, — наибольшее внимание уделено поддержке объектно-ориентированного и обобщённого программирования.
Являясь одним из самых популярных языков программирования,[3][4] C++ широко используется для разработки программного обеспечения. Область его применения включает создание операционных систем, разнообразных прикладных программ, драйверов устройств, приложений для встраиваемых систем, высокопроизводительных серверов, а также развлекательных приложений (например, видеоигры). Существует несколько реализаций языка C++ — как бесплатных, так и коммерческих.
Получить универсальный язык со статическими типами данных, эффективностью и переносимостью языка C.
Непосредственно и всесторонне поддерживать множество стилей программирования, в том числе процедурное программирование, абстракцию данных, объектно-ориентированное программирование и обобщённое программирование.
Дать программисту свободу выбора, даже если это даст ему возможность выбирать неправильно.
Максимально сохранить совместимость с C, тем самым делая возможным лёгкий переход от программирования на C.
Избежать разночтений между C и C++: любая конструкция, допустимая в обоих языках, должна в каждом из них обозначать одно и то же и приводить к одному и тому же поведению программы.
Избегать особенностей, которые зависят от платформы или не являются универсальными.
Никакое языковое средство не должно приводить к снижению производительности программ, не использующих его.
Не требовать слишком усложнённой среды программирования.
Язык C++ появился в начале 80-х годов. Созданный Бьерном Страуструпом с первоначальной целью избавить себя и своих друзей от программирования на ассемблере, Си или различных других языках высокого уровня.
По мнению автора языка, различие между идеологией Си и C++ заключается примерно в следующем: программа на Си отражает “способ мышления” процессора, а C++ - способ мышления программиста. Отвечая требованиям современного программирования, C++ делает акцент на разработке новых типов данных наиболее полно соответствующих концепциям выбранной области знаний и задачам приложения. Класс является ключевым понятием C++. Описание класса содержит описание данных, требующихся для представления объектов этого типа и набор операций для работы с подобными объектами.
В отличие от традиционных структур Си и Паскаля, членами класса являются не только данные, но и функции. Функции – члены класса имеют привилегированный доступ к данным внутри объектов этого класса и обеспечивают интерфейс между этими объектами и остальной программой. При дальнейшей работе совершенно не обязательно помнить о внутренней структуре класса и механизме работы встроенных функций. В этом смысле класс подобен электрическому прибору – мало кто знает о его устройстве, но все знают, как им пользоваться.
Язык С++ является средством объектного программирования, новейшей методики проектирования и реализации программ, которая в текущем десятилетии, скорее всего, заменит традиционное процедурное программирование. Главной целью создателя языка доктора Бьерна Страустрапа было оснащение языка С++ конструкциями, позволяющими увеличить производительность труда программистов и облегчить процесс овладения большими программными продуктами.
Абстракция, реализация, наследование и полиморфизм являются необходимыми свойствами которыми обладает язык С++, благодаря чему он не только универсален, как и язык Си, но и является объектным языком.
63. Языки программирования. Процедурный и непроцедурный подходы. Типовые конструкции и их реализация.
Язык программирования — формальная знаковая система, предназначенная для записи компьютерных программ. Язык программирования определяет набор лексических, синтаксических и семантических правил, задающих внешний вид программы и действия, которые выполнит исполнитель (компьютер) под её управлением.
Процедурный язык программирования (Basic, ФОРТРАН) - Выполнение программы сводится к последовательному выполнению операторов с целью преобразования исходного состояния памяти, то есть значений исходных данных, в заключительное, то есть в результаты. Таким образом, с точки зрения программиста имеются программа и память, причем первая последовательно обновляет содержимое последней.
Процедурный язык программирования предоставляет возможность программисту определять каждый шаг в процессе решения задачи. Особенность таких языков программирования состоит в том, что задачи разбиваются на шаги и решаются шаг за шагом. Используя процедурный язык, программист определяет языковые конструкции для выполнения последовательности алгоритмических шагов.
Процедурное (императивное) программирование является отражением архитектуры традиционных ЭВМ, которая была предложена фон Нейманом в 40-х гг. Теоретической моделью процедурного программирования служит алгоритмическая система под названием «машина Тьюринга».
Программа на процедурном языке программирования состоит из последовательности операторов (инструкций), задающих те или иные действия. Основным является оператор присваивания, служащий для изменения содержимого областей памяти. Вообще концепция памяти как хранилища значений, содержимое которого может обновляться операторами программы, является фундаментальной в императивном программировании.
Выполнение программы сводится к последовательному выполнению операторов с целью преобразования исходного состояния памяти (т.е. значений переменных) в заключительное. Таким образом, с точки зрения программиста имеется программа и память, причем первая последовательно обновляет содержимое последней.
Процедурные языки характеризуются:
значительной сложностью;
отсутствием строгой математической основы;
необходимостью явного управления памятью, в частности необходимостью описания переменных;
малой пригодностью для символьных вычислений;
высокой эффективностью реализации на традиционных ЭВМ.
Из-за наличия побочных эффектов (т.е. взаимного влияния различных программных модулей через общую память) программы на таких языках трудно читаемы, плохо модифицируемы и трудно проверяемы, а следовательно, ненадежны. По этой же причине они предполагают лишь последовательное выполнение.
Символьные вычисления состоят в преобразовании динамических структур данных, т.е. структурированных объектов, конфигурация которых меняется во времени (в отличие от числовых вычислений, предполагающих обработку данных статической структуры). К символьным вычислениям относятся задачи искусственного интеллекта, сортировки, трансляции, интерпретации, управления базами данных, символической алгебры и др. Символьные вычисления имеют ряд особенностей:
последовательность исполняемых инструкций сильно зависит от данных;
как правило, не требуется векторных и матричных операций;
наиболее частыми операциями являются вызовы процедур, агрегирование и декомпозиция структур данных, поиск по дереву и т. д.;
основной управляющей конструкцией служит рекурсия на структурах данных, таких, как деревья, списки, множества.
Одним из важнейших классификационных признаков процедурных языков является их уровень. Уровень языка программирования определяется семантической (смысловой) емкостью его конструкций и его ориентацией на программиста-человека Язык программирования (частично) ликвидирует семантический разрыв между методами решения задач человеком и машиной. Чем более язык ориентирован на программиста, тем выше его уровень. Распределение основных реализованных на ПЭВМ императивных языков по уровням приведено на рис. 4.4. Ряд языков программирования на нем не представлен. Среди них FORTH, который трудно классифицировать по уровню, а также PL/1, Cobol, RPG, Logo, Snobol и GPSS, в настоящее время не пользующиеся большой популярностью.
Непроцедурные языки составляют группу языков, описывающих организацию данных, обрабатываемых по фиксированным алгоритмам (табличные языки и генераторы отчётов), и языков связи с операционными системами. Позволяя чётко описывать как задачу, так и необходимые для её решения действия, таблицы решений дают возможность в наглядной форме определить, какие условия должны выполняться, прежде чем переходить к какому-либо действию. Табличные методы легко осваиваются специалистами любых профессий. Программы, составленные на табличном языке, удобно описывают сложные ситуации, возникающие при системном анализе.
Непроцедурное (декларативное) программирование появилось в начале 70-х годов 20 века, К непроцедурному программированию относятся функциональные и логические языки.
В функциональных языках программа описывает вычисление некоторой функции. Обычно эта функция задается как композиция других, более простых, те в свою очередь делятся на еще более простые задачи и т.д. Один из основных элементов функциональных языков – рекурсия. Оператора присваивания и циклов в классических функциональных языках нет.
В логических языках программа вообще не описывает действий. Она задает данные и соотношения между ними. После этого системе можно задавать вопросы. Машина перебирает известные и заданные в программе данные и находит ответ на вопрос. Порядок перебора не описывается в программе, а неявно задается самим языком. Классическим языком логического программирования считается Пролог. Программа на Прологе содержит, набор предикатов–утверждений, которые образуют проблемно–ориентированную базу данных и правила, имеющие вид условий.
Функциональное программирование (LISP) — раздел дискретной математики и парадигма программирования, в которой процесс вычисления трактуется как вычисление значений функций в математическом понимании последних (в отличие от функций как подпрограмм в процедурном программировании).
Противопоставляется парадигме императивного программирования, которая описывает процесс вычислений как последовательное изменение состояний (в значении, подобном таковому в теории автоматов). При необходимости, в функциональном программировании вся совокупность последовательных состояний вычислительного процесса представляется явным образом, например как список.
Функциональное программирование предполагает обходиться вычислением результатов функций от исходных данных и результатов других функций, и не предполагает явного хранения состояния программы. Соответственно, не предполагает оно и изменяемость этого состояния (в отличие от императивного, где одной из базовых концепций является переменная, хранящая своё значение и позволяющая менять его по мере выполнения алгоритма).
На практике отличие математической функции от понятия «функции» в императивном программировании заключается в том, что императивные функции могут опираться не только на аргументы, но и на состояние внешних по отношению к функции переменных, а также иметь побочные эффекты и менять состояние внешних переменных. Таким образом, в императивном программировании при вызове одной и той же функции с одинаковыми параметрами, но на разных этапах выполнения алгоритма, можно получить разные данные на выходе из-за влияния на функцию состояния переменных. А в функциональном языке при вызове функции с одними и теми же аргументами мы всегда получим одинаковый результат: выходные данные зависят только от входных. Это позволяет средам выполнения программ на функциональных языках кешировать результаты функций и вызывать их в порядке, не определяемом алгоритмом.
Логическое программирование (Planner) — парадигма программирования, основанная на автоматическом доказательстве теорем, а также раздел дискретной математики, изучающий принципы логического вывода информации на основе заданных фактов и правил вывода. Логическое программирование основано на теории и аппарате математической логики с использованием математических принципов резолюций.
64. Основные стили программирования. Преимущества объектной модели.
Под стилем программирования понимается внутренне согласованная совокупность базовых конструкций программ и способов их композиции, обладающая общими фундаментальными особенностями, как логическими, так и алгоритмическими. Стиль включает также совокупность базовых концепций, связанных с этими программами. Стиль программирования реализуется через методологии программирования,
заключающиеся в совокупности соглашений о том, какие базовые концепции языков программирования и какие их сочетания считаются приемлемыми или неприемлемыми для данного стиля. Методология включает в себя, в частности, модель вычислителя для данного стиля.
Парадигма программирования — это система идей и понятий, определяющих стиль написания компьютерных программ, а также образ мышления программиста.
Императивное программирование — это парадигма программирования, которая, в отличие от декларативного программирования, описывает процесс вычисления в виде инструкций, изменяющих состояние программы. Императивная программа очень похожа на приказы, выражаемые повелительным наклонением в естественных языках, то есть это последовательность команд, которые должен выполнить компьютер. Императивные языки программирования противопоставляются функциональным и логическим языкам программирования. Функциональные языки, например, Haskell, не представляют собой последовательность инструкций и не имеют глобального состояния. Логические языки программирования, такие как Prolog, обычно определяют что надо вычислить, а не как это надо делать.
Структурное программирование — методология разработки программного обеспечения, в основе которой лежит представление программы в виде иерархической структуры блоков в соответствии с данной методологией. (pascal).
Программирование «сверху вниз», или нисходящее программирование – это методика разработки программ, при которой разработка начинается с определения целей решения проблемы, после чего идет последовательная детализация, заканчивающаяся детальной программой.
Программирование «снизу вверх», или восходящее программирование – это методика разработки программ, начинающаяся с разработки подпрограмм (процедур, функций), в то время когда проработка общей схемы не закончилась.
Функциональное программирование (LISP) — раздел дискретной математики и парадигма программирования, в которой процесс вычисления трактуется как вычисление значений функций в математическом понимании последних (в отличие от функций как подпрограмм в процедурном программировании).
Противопоставляется парадигме императивного программирования, которая описывает процесс вычислений как последовательное изменение состояний (в значении, подобном таковому в теории автоматов). При необходимости, в функциональном программировании вся совокупность последовательных состояний вычислительного процесса представляется явным образом, например как список.
Функциональное программирование предполагает обходиться вычислением результатов функций от исходных данных и результатов других функций, и не предполагает явного хранения состояния программы.
Логическое программирование (Planner) — парадигма программирования, основанная на автоматическом доказательстве теорем, а также раздел дискретной математики, изучающий принципы логического вывода информации на основе заданных фактов и правил вывода. Логическое программирование основано на теории и аппарате математической логики с использованием математических принципов резолюций.
Объектно-ориентированное прораммирование — парадигма программирования, в которой основными концепциями являются понятия объектов и классов. В случае языков с прототипированием вместо классов используются объекты-прототипы. (c++, Delphi).
В центре ООП находится понятие объекта. Объект — это сущность, которой можно посылать сообщения, и которая может на них реагировать, используя свои данные. Данные объекта скрыты от остальной программы. Сокрытие данных называется инкапсуляцией.
Наличие инкапсуляции достаточно для объектности языка программирования, но ещё не означает его объектной ориентированности — для этого требуется наличие наследования.
Но даже наличие инкапсуляции и наследования не делает язык программирования в полной мере объектным с точки зрения ООП. Основные преимущества ООП проявляются только в том случае, когда в языке программирования реализован полиморфизм; то есть возможность объектов с одинаковой спецификацией иметь различную реализацию.
Достоинства:
Классы позволяют проводить конструирование из полезных компонент, обладающих простыми инструментами, что дает возможность абстрагироваться от деталей реализации.
Данные и операции вместе образуют определенную сущность и они не «размазываются» по всей программе, как это нередко бывает в случае процедурного программирования.
Локализация кода и данных улучшает удобство сопровождения программного обеспечения.
Инкапсуляция информации защищает критичные данные от несанкционированного доступа.
Обработка разнородных структур данных.. Новые виды могут быть добавлены в любой момент.
Изменение поведения во время выполнения.
Реализация родовых компонент
Доведение полуфабрикатов. Их можно сохранять в библиотеке в виде полуфабрикатов.
Расширение каркаса.
65. Элементы объектно-ориентированного программирования: абстрагирование, инкапсуляция, модульность, иерархия, типизация.
Объектно-ориентированное — парадигма программирования, в которой основными концепциями являются понятия объектов и классов.
Абстрагирование — это способ выделить набор значимых характеристик объекта, исключая из рассмотрения незначимые. Соответственно, абстракция — это набор всех таких характеристик.
Абстракция — в объектно-ориентированном программировании это придание объекту характеристик, которые четко определяют его концептуальные границы, отличая от всех других объектов.
Инкапсуляция — это свойство системы, позволяющее объединить данные и методы, работающие с ними, в классе и скрыть детали реализации от пользователя. Инкапсуляция — свойство языка программирования, позволяющее пользователю не задумываться о сложности реализации используемого программного компонента (то, что у него внутри), а взаимодействовать с ним посредством предоставляемого интерфейса (публичных членов — методов, данных etc.)
Полиморфизм означает способность одного и того же программного кода работать с разнотипными данными. Другими словами, он означает допустимость в объектах разных типов иметь методы (процедуры или функции) с одинаковыми именами. Во время выполнения объектной программы одни и те же методы оперируют с разными объектами в зависимости от типа аргумента.
Модульность — принцип, согласно которому программное разделяется на отдельные именованные сущности, называемые модулями. Модульность часто является средством упрощения задачи проектирования ПС и распределения процесса разработки ПС между группами разработчиков. При разбиении ПС на модули для каждого модуля указывается реализуемая им функциональность, а также связи с другими модулями.
Роль модулей могут играть классы.
Класс – это способ группирования объектов, имеющих одинаковые наборы атрибутов и линии поведения, в шаблон. Объекты определенного класса называются экземплярами этого класса.
Иерархия классов означает классификацию объектных типов, рассматривая объекты как реализацию классов и связывая различные классы отношениями наподобие «наследует», «расширяет», «является его абстракцией», «определение интерфейса».
Объект – любая сущность реального мира. Объекты характеризуются свойствами, определяющими их состояние, и методами, определяющими их поседение. Объекты взаимодействуют друг с другом путем передачи сообщений.
Линии поведения – это методы, или операции, которые объект может реализовать.
Сообщения – это действие одного объекта, запускающее определенное поведение другого объекта.
Отношения описывают то, как объекты ассоциированы друг с другом.
76. Цель и место тестирования программного средства. Классификация форм тестирования.
Тести́рование програ́ммного обеспе́чения — процесс исследования программного обеспечения (ПО) с целью получения информации о качестве продукта.
Обнаружение всех ошибок невозможно.
Таким образом, целью тестирования является не тотальное обнаружение всех ошибок (это принципиально невозможно), а выявление наибольшего количества наиболее критичных ошибок. Если исправление их задерживается, то пользователи программного продукта должны быть предупреждены о наличии такого рода ошибок и рекомендуемых путях обхода.
Основными критериями завершенности тестирования является отсутствие критичных ошибок, каждая из которых может сделать абсолютно невозможной реализацию декларированной в системе прикладной функциональности (решение принимается по результатам функционального тестирования). Кроме того, при принятии решения учитывается общее количество зарегистрированных, но неисправленных ошибок. Компания-разработчик обычно заранее выбирает по каждому программному продукту общее количество ошибок (лимит), с которым уже нельзя выпускать программный продукт.
Количественная оценка завершенности процесса тестирования и готовности программного продукта для эксплуатации может быть получена при помощи моделей надежности программного обеспечения. Самый простой способ представления информации для принятия решения — графический: по одной оси откладывается время от начала процесса тестирования, по другой — количество обнаруженных ошибок в программном средстве. По графику (знаку производной) определяется необходимость продолжения тестирования. Существует множество методов, которые помогают принять решение в выпуске программного обеспечения, однако самое, веское слово остается за специалистом, осуществляющим тестирование программного обеспечения, так как на основе количества и характера найденных проблем он может судить о том, удовлетворит данный продукт потребности и ожидания пользователя или нет.
Существует несколько признаков, по которым принято производить классификацию видов тестирования. Обычно выделяют следующие:
По объекту тестирования:
Функциональное тестирование (functional testing) это тестирование ПО в целях проверки реализуемости функциональных требований, то есть способности ПО в определённых условиях решать задачи, нужные пользователям. Функциональные требования определяют, что именно делает ПО, какие задачи оно решает.
Функциональные требования включают:
Функциональная пригодность (англ. suitability).
Точность (англ. accuracy).
Способность к взаимодействию (англ. interoperability).
Соответствие стандартам и правилам (англ. compliance).
Защищённость (англ. security).
Тестирование производительности (performance testing) Тестирование производительности — в инженерии программного обеспечения тестирование, которое проводится с целью определения, как быстро работает система или её часть под определённой нагрузкой. Также может служить для проверки и подтверждения других атрибутов качества системы, таких как масштабируемость, надёжность и потребление ресурсов.
Нагрузочное тестирование (load testing) — тестироание программного обеспечения на максимальную нагрузку.
Стресс-тестирование (stress testing)
Тестирование стабильности (stability / endurance / soak testing)
Юзабилити-тестирование (usability testing) — исследование, выполняемое с целью определения, удобен ли некоторый искусственный объект (такой как веб-страница, пользовательский интерфейс или устройство) для его предполагаемого применения. Таким образом, проверка эргономичности измеряет эргономичность объекта или системы. Проверка эргономичности сосредоточена на определённом объекте или небольшом наборе объектов, в то время как исследования взаимодействия человек-компьютер в целом — формулируют универсальные принципы.
Тестирование интерфейса пользователя (UI testing)
Тестирование безопасности (security testing)
Тестирование локализации (localization testing)
Тестирование совместимости (compatibility testing)
По знанию системы:
Тестирование чёрного ящика (black box) — тестирование с внешней стороны (стороны пользователя)
Тестирование белого ящика (white box) — тестирование со стороны исходного кода программного обеспечения.
Тестирование серого ящика (grey box)
По степени автоматизации:
Ручное тестирование (manual testing)
Автоматизированное тестирование (automated testing)
Полуавтоматизированное тестирование (semiautomated testing)
По степени изолированности компонентов:
Компонентное (модульное) тестирование (component/unit testing)
Интеграционное тестирование (integration testing)
Системное тестирование (system/end-to-end testing)
По времени проведения тестирования:
Альфа-тестирование (alpha testing)
Тестирование при приёмке (smoke testing)
Тестирование новой функциональности (new feature testing)
Регрессионное тестирование (regression testing)
Тестирование при сдаче (acceptance testing)
Бета-тестирование (beta testing)
По признаку позитивности сценариев:
Позитивное тестирование (positive testing)
Негативное тестирование (negative testing)
По степени подготовленности к тестированию:
Тестирование по документации (formal testing)
Тестирование ad hoc или интуитивное тестирование (ad hoc testing)
77. Методы проектирования ИС: каноническое, индустриальное и типовое. Выбор технологии проектирования
Проектирование ИС — процесс преобразования входной информации об объекте проектирования, о методах проектирования и об опыте проектирования аналогичных объектов в проект ИС.
Объектами проектирования ИС являются отдельные элементы функциональных и обеспечивающих частей, а также их комплексы.
В качестве субъектов проектирования ИС выступают:
• специализированная проектная организация;
• организация-заказчик, для которой необходимо разработать ИС.
Технология проектирования ИС — совокупность методологии, инструментальных средств проектирования, а также методов и средств организации проектирования.
Выбор технологии проектирования ИС определяется возможностью обеспечивать:
• соответствие стандарту ISO / I ЕС 12207 (поддержка процессов ЖЦ);
• гарантированное достижение целей разработки ИС в рамках бюджета, с заданным качеством и в установленное время;
• возможность декомпозиции проекта на составные части, разрабатываемые группами в 3 — 7 человек, с последующей интеграцией частей,
• минимальное время получения работоспособного ПО подсистем ИС;
• независимость получаемых проектных решений от средств реализации ИС (СУБД, ОС, языков и систем программирования);
• поддержку CASE-средств, обеспечивающих автоматизацию процессов, выполняемых на всех стадиях ЖЦ.
Основу технологии проектирования ИС составляет методология проектирования. Она предполагает наличие некоторой концепции (принципов проектирования), реализуемой набором методов.
Метод проектирования — способ создания проекта системы, поддерживаемый определёнными средствами проектирования.
Выделяются две основных технологии проектирования ИС:
• технология канонического проектирования ИС;
• технология индустриального проектирования ИС.
Индустриальная технология проектирования, в свою очередь, разбивается на два подкласса:
• автоматизированное (использование CASE-технологий);
• типовое (параметрически- или модельно-ориентированное) проектирование.
Каноническое проектирование (КП) отражает особенности ручной технологии индивидуального проектирования, осуществляемого на уровне исполнителей без использования каких-либо инструментальных средств. Применяется для небольших локальных ИС.
Особенности КП ИС:
Ориентировано на использование каскадной модели ЖЦ ИС.
Стадии и этапы работы описаны в стандарте ГОСТ 34.601-90 "Автоматизированные системы стадий создания".
Допускается объединять последовательные этапы и даже исключать некоторые из них на любой стадии проекта.
Допускается начинать выполнение работ следующей стадии до окончания предыдущей.
Стадии и этапы создания ИС, выполняемые организациями-участниками, прописываются в договорах и технических заданиях на выполнение работ:
Стадия 1. Формирование требований к ИС.
На начальной стадии проектирования выделяют следующие этапы работ:
обследование объекта и обоснование необходимости создания ИС;
формирование требований пользователей к ИС;
оформление отчета о выполненной работе и тактико-технического задания на разработку.
Стадия 2. Разработка концепции ИС.
изучение объекта автоматизации;
проведение необходимых научно-исследовательских работ;
разработка вариантов концепции ИС, удовлетворяющих требованиям пользователей;
оформление отчета и утверждение концепции.
Стадия 3. Техническое задание.
разработка и утверждение технического задания на создание ИС.
Стадия 4. Эскизный проект.
разработка предварительных проектных решений по системе и ее частям;
разработка эскизной документации на ИС и ее части.
Стадия 5. Технический проект.
разработка проектных решений по системе и ее частям;
разработка документации на ИС и ее части;
разработка и оформление документации на поставку комплектующих изделий;
разработка заданий на проектирование в смежных частях проекта.
Стадия 6. Рабочая документация.
разработка рабочей документации на ИС и ее части;
разработка и адаптация программ.
Стадия 7. Ввод в действие.
подготовка объекта автоматизации;
подготовка персонала;
комплектация ИС поставляемыми изделиями (программными и техническими средствами, программно-техническими комплексами, информационными изделиями);
строительно-монтажные работы;
пусконаладочные работы;
проведение предварительных испытаний;
проведение опытной эксплуатации;
проведение приемочных испытаний.
Стадия 8. Сопровождение ИС.
выполнение работ в соответствии с гарантийными обязательствами;
послегарантийное обслуживание.
Типовое проектирование ИС предполагает создание системы из готовых типовых элементов. Основополагающим требованием для применения методов типового проектирования является возможность декомпозиции проектируемой ИС на множество составляющих компонентов (подсистем, комплексов задач, программных модулей и т.д.). Для реализации выделенных компонентов выбираются имеющиеся на рынке типовые проектные решения, которые настраиваются на особенности конкретного предприятия.
Типовое проектное решение (ТПР)- это тиражируемое (пригодное к многократному использованию) проектное решение.
Для реализации типового проектирования используются два подхода: параметрически-ориентированное и модельно-ориентированное проектирование.
Параметрически-ориентированное проектирование включает следующие этапы: определение критериев оценки пригодности пакетов прикладных программ (ППП) для решения поставленных задач, анализ и оценка доступных ППП по сформулированным критериям, выбор и закупка наиболее подходящего пакета, настройка параметров (доработка) закупленного ППП.
Модельно-ориентированное проектирование заключается в адаптации состава и характеристик типовой ИС в соответствии с моделью объекта автоматизации.
78. Жизненный цикл ИС. Модели жизненного цикла.
Совокупность стадий и этапов, которые проходит ИС в своем развитии от момента принятия решения о создании системы до момента прекращения функционирования системы, называется жизненным циклом ИС.
Содержание жизненного цикла разработки ИС сводится к выполнению следующих стадий:
1. Планирование и анализ требований (предпроектная стадия) ─ системный анализ. Проводится исследование и анализ существующей информационной системы, определяются требования к создаваемой ИС, формируются технико-экономическое обоснование (ТЭО) и техническое задание (ТЗ) на разработку ИС;
2. Проектирование (техническое и логическое проектирование). В соответствии с требованиями формируются состав автоматизируемых функций (функциональная архитектура) и состав обеспечивающих подсистем (системная архитектура), проводится оформление технического проекта ИС;
3. Реализация (рабочее и физическое проектирование, кодирование). Разработка и настройка программ, формирование и наполнение баз данных, формулировка рабочих инструкций для персонала, оформление рабочего проекта;
4. Внедрение (опытная эксплуатация). Комплексная отладка подсистем ИС, обучение персонала, поэтапное внедрение ИС в эксплуатацию по подразделениям организации, оформление акта о приемо-сдаточных испытаниях ИС;
5. Эксплуатация ИС (сопровождение, модернизация). Сбор рекламаций и статистики о функционировании ИС, исправление недоработок и ошибок, оформление требований к модернизации ИС и ее выполнение (повторение стадий 2-5).
С точки зрения реализации перечисленных аспектов в технологиях проектирования ИС модели жизненного цикла, определяющие порядок выполнения стадий и этапов, претерпевали существенные изменения. Среди известных моделей жизненного цикла можно выделить следующие:
· каскадная модель (до 70-х годов) ─ последовательный переход на следующий этап после завершения предыдущего;
· итерационная модель (70-80-е годы) ─ с итерационными возвратами на предыдущие этапы после выполнения очередного этапа;
· спиральная модель (80-90-е годы) ─ прототипная модель, предполагающая постепенное расширение прототипа ИС.
В каскадной модели переход на следующий, иерархически нижний этап происходит только после полного завершения работ на текущем этапе (рис. 10).
Достоинство каскадной модели заключается в планировании времени осуществления всех этапов проекта, упорядочении хода конструирования.
Недостатки каскадной модели:
¨ реальные проекты часто требуют отклонения от стандартной последовательности шагов (недостаточно гибкая модель);
¨ цикл основан на точной формулировке исходных требований к ПО (реально в начале проекта требования заказчика определены лишь частично);
¨ результаты проекта доступны заказчику только в конце работы.

Рисунок 10. Классический жизненный цикл ИС
Итерационная модель. Построение комплексных ИС подразумевает согласование проектных решений, получаемых при реализации отдельных задач. Подход к проектированию "снизу вверх" предполагает необходимость таких итерационных возвратов, когда проектные решения по отдельным задачам объединяются в общие системные решения, и при этом возникает потребность в пересмотре ранее сформулированных требований. Вследствие большого числа итераций возникают рассогласования и несоответствия в выполненных проектных решениях и документации.
Спиральная модель ─ классический пример применения эволюционной стратегии конструирования.
Где, 1. начальный сбор требований и планирование проекта; 2. та же работа, но на основе рекомендаций заказчика; 3. анализ риска на основе начальных требований; 4. анализ риска на основе реакции заказчика; 5. переход к комплексной системе; 6. начальный макет системы; 7. следующий уровень макета; 8. сконструированная система; 9. оценивание заказчиком.
Как показано на рис. 11, спиральная модель определяет четыре действия, представляемые четырьмя квадрантами спирали:
· планирование ─ определение целей, вариантов и ограничений;
· анализ риска ─ анализ вариантов и распознавание (выбор) риска;
· конструирование ─ разработка продукта следующего уровня;
· оценивание ─ оценка заказчиком текущих результатов конструирования.
Интегрирующий аспект спиральной модели очевиден при учете радиального измерения спирали. С каждой итерацией по спирали (продвижением от центра к периферии) строятся все более полные версии ПО.
Спиральная модель жизненного цикла ИС реально отображает разработку программного обеспечения; позволяет явно учитывать риск на каждом витке эволюции разработки; включает шаг системного подхода в итерационную структуру разработки; использует моделирование для уменьшения риска и совершенствования программного изделия.
Недостатками спиральной модели являются:
· новизна (отсутствует достаточная статистика эффективности модели);
· повышенные требования к заказчику;
· трудности контроля и управления временем разработки.
В основе спиральной модели жизненного цикла лежит применение прототипной технологии или RAD-технологии (rapid application development ─ технологии быстрой разработки приложений). Основная идея этой технологии заключается в том, что ИС разрабатывается путем расширения программных прототипов, повторяя путь от детализации требований к детализации программного кода. При прототипной технологии сокращается число итераций, возникает меньше ошибок и несоответствий, которые необходимо исправлять на последующих итерациях, а само проектирование ИС осуществляется более быстрыми темпами, упрощается создание проектной документации. Для более точного соответствия проектной документации разработанной ИС все большее значение придается ведению общесистемного репозитария и использованию CASE-технологий.
79. Стадии создания автоматизированной системы: предпроектная стадия, стадия проектирования, внедрение, эксплуатация и сопровождение.
Стадии и этапы создания АС в общем случае приведены в таблице.
Стадии |
Этапы работ |
1. Формирование требований к АС |
1.1. Обследование объекта и обоснование необходимости создания АС. 1.2. Формирование требований пользователя к АС. 1.3. Оформление отчёта о выполненной работе и заявки на разработку АС (тактико-технического задания) |
2. Разработка концепции АС. |
2.1. Изучение объекта. 2.2. Проведение необходимых научно-исследовательских работ. 2.3. Разработка вариантов концепции АС, удовлетворяющего требованиям пользователя. 2.4. Оформление отчёта о выполненной работе. |
3. Техническое задание. |
Разработка и утверждение технического задания на создание АС. |
4. Эскизный проект. |
4.1. Разработка предварительных проектных решений по системе и её частям. 4.2. Разработка документации на АС и её части. |
5. Технический проект. |
5.1. Разработка проектных решений по системе и её частям. 5.2. Разработка документации на АС и её части. 5.3. Разработка и оформление документации на поставку изделий для комплектования АС и (или) технических требований (технических заданий) на их разработку. 5.4. Разработка заданий на проектирование в смежных частях проекта объекта автоматизации. |
6. Рабочая документация. |
6.1. Разработка рабочей документации на систему и её части. 6.2. Разработка или адаптация программ. |
7. Ввод в действие. |
7.1. Подготовка объекта автоматизации к вводу АС в действие. 7.2. Подготовка персонала. 7.3. Комплектация АС поставляемыми изделиями (программными и техническими средствами, программно-техническими комплексами, информационными изделиями). 7.4. Строительно-монтажные работы. 7.5. Пусконаладочные работы. 7.6. Проведение предварительных испытаний. 7.7. Проведение опытной эксплуатации. 7.8. Проведение приёмочных испытаний. |
8. Сопровождение АС |
8.1. Выполнение работ в соответствии с гарантийными обязательствами. 8.2. Послегарантийное обслуживание. |
80. Предпроектная стадия: объекты, сбор материалов.
При изучении существующей экономической системы разработчики должны уточнить границы изучения системы, определить круг пользователей будущей ЭИС различных уровней и выделить классы и типы объектов, подлежащих обследованию и последующей автоматизации.
Важнейшими объектами обследования могут являться:
- структурно-организационные звенья предприятия (например, отделы управления, цехи, участки, рабочие места);
- функциональная структура
- состав хозяйственных процессов и процедур;
- стадии (техническая подготовка, снабжение, производство, сбыт);
- элементы хозяйственного процесса (средства труда, предметы труда, ресурсы, продукция, финансы).
При каноническом проектировании основной единицей обработки данных является задача. Поэтому функциональная структура проблемной области на стадии предпроектного обследования изучается в разрезе решаемых задач и комплексов задач. При этом задача в содержательном аспекте рассматривается как совокупность операций преобразования некоторого набора исходных данных для получения результатной информации, необходимой для выполнения функции управления или принятия управленческого решения. В большинстве случаев исходные данные и результаты их преобразований представляются в форме экономических документов. Поэтому к числу объектов обследования относятся компоненты потоков информации (документы, показатели, файлы, сообщения).
Кроме того, объектами обследования служат:
- технологии, методы и технические средства их преобразования;
- материальные потоки и процессы их обработки.
Основной целью выполнения первого этапа предпроектного обследования "Cбор материалов" является:
- выявление основных параметров предметной области (например, предприятия или его части);
- установление условий, в которых будет функционировать проект ЭИС;
- выявление стоимостных и временных ограничений на процесс проектирования.
На этом этапе проектировщиками выполняется ряд технологических операций и решаются следующие задачи (технологическая сеть проектирования представлена на рис. 3.2:
Рис . 3.2. Технологическая сеть работ, выполняемых на этапе сбора
материалов обследования
П 1 ─ предварительное изучение предметной области;
П 2 ─ выбор технологии проектирования;
П 3 ─ выбор метода проведения обследования;
П 4 ─ выбор метода сбора материалов обследования;
П 5 ─ разработка программы обследования;
П 6 ─ разработка плана-графика сбора материалов обследования;
П 7 ─ сбор и формализация материалов обследования.
Д 1.1. ─ общие сведения об объекте;
Д 1.2. ─ примеры разработок проектов ЭИС для аналогичных систем;
U 2.1. ─ универсум технологий проектирования;
Д 2.1. ─ список ресурсов;
Д 2.2. ─ oписаниe выбранной технологии, методов и средств проектирования;
U 3.1. ─ универсум методов проведения обследования;
Д 3.1. ─ описание выбранного метода;
U 4.1. ─ универсум методов сбора материалов обследования;
Д 4.1. ─ описание выбранных методов;
Д 5.1. ─ программа обследования;
Д 6.1. ─ план-график выполнения работ на предпроектной стадии;
U 7.1. ─ универсум методов формализации;
Д 7.1. ─ общие параметры (характеристики) экономической системы;
Д 7.2. ─ организационная структура экономической системы;
Д 7.3. ─ методы и методики управления (алгоритм расчета экономических показателей);
Д 7.4. ─ параметры информационных потоков;
Д 7.5. ─ параметры материальных потоков.
Выполнение операции предварительного изучения предметной области (П 1) имеет своей целью на основе общих сведений об объекте (Д 1.1) выявить предварительные размеры объемов работ по проектированию и состав стоимостных и временных ограничений на процессы проектирования, а также найти примеры разработок проектов ЭИС для аналогичных систем (Д 1.2).
Важной операцией, определяющей все последующие работы по обследованию объекта и проектированию ЭИС, является выбор технологии проектирования (П 2). В настоящее время в универсум (U2.1) входит несколько типов технологий проектирования: технология оригинального, типового, автоматизированного и смешанного варианта проектирования. Для технологии оригинального проектирования характерно создание уникального проектного решения для экономической системы. При этом могут создаваться не только индивидуальные проекты, но и соответствующие методики проведения проектных работ. Поэтому технологию оригинального проектирования используют в том случае, если хотят, чтобы получаемый в результате проектирования индивидуальный проект в полной мере отображал все особенности соответствующего объекта управления при невысокой стоимости разработки, понятности и доступности получаемого решения заказчику. К числу ограничений по использованию оригинального проектирования можно отнести низкую степень автоматизации проектных работ, длительные сроки разработки, низкое качество документирования, отсутствие преемственности в проектных решениях.
Основными ограничениями при выборе технологии из некоторого универсума технологий (U2.1) могут служить: наличие денежных средств на приобретение и поддержку выбранной технологии, ограничения по времени проектирования, доступность соответствующих инструментальных средств и возможность обеспечения поддержки их эксплуатации собственными силами, наличие специалистов соответствующей квалификации (Д 2.1). Результатом выполнения этой операции служит получение описания выбранной технологии, методов и средств проектирования (Д 2.2).
81. Автоматизированное проектирование ИС. CASE – средства: основные понятия, классификация и области применения
CASE (Computer Aided Software/System Engineering) – технология автоматизированного проектирования информационных систем.
Предмет CASE-технологий – автоматизация процесса проектирования, разработки и реализации программного и информационного обеспечения ИС.
Цель CASE-технологий – добиться резкого роста производительности труда в инженерии программного и информационного обеспечения ИС, облегчить работу программистов, проектировщиков, аналитиков и руководителей проектов.
CASE-средство – программное средство, поддерживающее процессы жизненного цикла ИС, включая анализ требований к системе, проектирование прикладного ПО и БД, генерацию кода, тестирование, документирование, обеспечение качества, управление конфигурацией ПО и управление проектом, а также др. процессы
(ISO/IEC 14102:1995).
CASE-средства + системное ПО = Среда разработки ИС
Особенности CASE-средств:
мощные графические средства для описания и документирования ИС;
интеграция отдельных компонент CASE-средств, обеспечивающая управляемость процессом разработки ИС;
использование специальным образом организованного хранилища проектных метаданных (репозитория).
Состав CASE-средства:
репозиторий (хранение версий проекта и его отдельных компонентов, синхронизацию поступления информации от различных разработчиков при групповой разработке, контроль метаданных на полноту и непротиворечивость);
графические средства анализа и проектирования, обеспечивающие создание и редактирование иерархически связанных диаграмм, образующих модели ИС;
средства разработки приложений, включая языки 4GL и генераторы кодов;
средства конфигурационного управления;
средства документирования;
средства тестирования;
средства управления проектом;
средства реинжиниринга.
К настоящему моменту наиболее интенсивное развитие получили два главных направления применения CASE-средств:
1) BPR (business process reengineering) - перепроектирование бизнес-процессов. Под перепроектированием понимается "фундаментальное переосмысление и радикальное перепланирование критических бизнес-процессов, имеющее целью резко улучшить их выполнение с точки зрения затрат, качества обслуживания и скорости". При этом бизнес-процесс представляет собой некоторую деятельность, получающую входные данные одного или нескольких типов и выдающую результат, имеющий ценность для клиента. Например, процесс выполнения заказа на входе получает заказ и выдает в качестве результата заказанные товары. Другими словами, доставка заказанных товаров клиенту и есть та ценность, которую создает процесс.
2) Системный анализ и проектирование, включающее функциональное, информационное и событийное моделирование как вновь создаваемой, так и существующей системы.
82. Распределенные вычислительные системы и компьютерные сети: основные технологии, программные и аппаратные компоненты.
Распределенная вычислительная система (РВС) – это набор соединенных каналами связи независимых компьютеров, которые с точки зрения пользователя некоторого программного обеспечения выглядят единым целым.
В этом определении фиксируются два существенных момента: автономность узлов РВС и представление системы пользователем, как единой структуры. При этом, основным связующим звеном распределенных вычислительных систем является программное обеспечение.
Распределенная вычислительная система представляет собой программно-аппаратный комплекс, ориентированный на решение определенных задач. С одной стороны, каждый вычислительный узел является автономным элементом.
С другой стороны, программная составляющая РВС должна обеспечивать пользователям видимость работы с единой вычислительной системой. В связи с этим выделяют следующие важные характеристики РВС:
− возможность работы с различными типами устройств:
− с различными поставщиками устройств;
− с различными операционными системами,
− с различными аппаратными платформами.
Вычислительные среды, состоящие из множества вычислительных систем на базе разных программно-аппаратных платформ, называются гетерогенными;
− возможность простого расширения и масштабирования;
− перманентная (постоянная) доступность ресурсов (даже если некоторые
элементы РВС некоторое время могут находиться вне доступа);
− сокрытие особенностей коммуникации от пользователей.
Для обеспечения работы гетерогенного оборудования РВС в виде единого
целого, стек программного обеспечения (ПО) обычно разбивают на два слоя.
На верхнем слое располагаются распределенные приложения, отвечающие за решение определенных прикладных задач средствами РВС. Их функциональные возможности базируются на нижнем слое – промежуточном программном обеспечении (ППО) . ППО взаимодействует с системным ПО и сетевым уровнем, для обеспечения прозрачности работы приложений в РВС (см. рис. 1).
Для того чтобы РВС могла быть представлена пользователю как единая система, применяют следующие типы прозрачности в РВС:
− прозрачный доступ к ресурсам – от пользователей должна быть скрыта разница в представлении данных и в способах доступа к ресурсам РВС;
− прозрачное местоположение ресурсов – место физического расположения требуемого ресурса должно быть несущественно для пользователя;
− репликация – сокрытие от пользователя того, что в реальности существует более одной копии используемых ресурсов;
− параллельный доступ – возможность совместного (одновременного) использования одного и того же ресурса различными пользователями независимо друг от друга. При этом факт совместного использования ресурса должен оставаться скрытым от пользователя;
− прозрачность отказов – отказ (отключение) каких-либо ресурсов РВС не должен оказывать влияния на работу пользователя и его приложения.
При использовании децентрализованного метода обнаружения ресурсов (например, в сети Gnutella) запрос на поиск отправляется всем узлам, известным отправителю. Эти узлы производят поиск ресурса у себя, и транслируют запрос далее. Таким образом, отсутствуют выделенные узлы для обнаружения и централизованное хранилище информации о ресурсах, доступных в сети.
Другим важным фактором является доступность ресурсов РВС. Примером централизованной доступности ресурсов в РВС может являться технология веб-сервисов. Существует только один сервер с выделенным IP-адресом, который предоставляет определенный веб-сервис или сайт. Если данный узел выйдет из строя или будет отключен от сети, данный сервис станет недоступна.
Естественно, можно применить методы репликации для расширения доступности определенного сайта или сервиса, но доступность определенного IP-адреса останется прежней.
Существуют системы, предоставляющие децентрализованные подходы к доступности ресурсов посредством множественного дублирования сервисов, которые могут обеспечить функциональность, необходимую пользователю.
Наиболее яркими примерами децентрализованной доступности ресурсов могут служить одноранговые вычислительные системы (BitTorrent, Gnutella, Napster),
где каждый узел играет роль, как клиента, так и сервера, который может предоставлять ресурсы и сервисы, аналогичные остальным устройствам данной сети
(поиск, передача данных и др.)
Еще одним критерием классификации РВС могут служить методы взаимодействия узлов. Централизованный подход к взаимодействию узлов основан на том, что взаимодействие между узлами всегда происходит через специальный центральный сервер. Таким образом, один узел не может обратиться к другому непосредственно.
Децентрализованный подход к взаимодействию реализуется в одноранговых вычислительных системах. Такой подход основывается на прямом взаимодействии между узлами РВС, т.к. каждый узел играет как роль клиента, так и роль сервера.
Компьютерные сети относятся к распределенным (или децентрализованным) вычислительным системам. Поскольку основным признаком распределенной вычислительной системы является наличие нескольких центров обработки данных, то наряду с компьютерными сетями к распределенным системам относят также мультипроцессорные компьютеры и многомашинные вычислительные комплексы.
Многомашинная система - это вычислительный комплекс, включающий в себя несколько компьютеров (каждый из которых работает под управлением собственной операционной системы), а также программные и аппаратные средства связи компьютеров, которые обеспечивают работу всех компьютеров комплекса как единого целого.
В вычислительных сетях программные и аппаратные связи являются еще более слабыми, а автономность обрабатывающих блоков проявляется в наибольшей степени - основными элементами сети являются стандартные компьютеры, не имеющие ни общих блоков памяти, ни общих периферийных устройств. Связь между компьютерами осуществляется с помощью специальных периферийных устройств - сетевых адаптеров, соединенных относительно протяженными каналами связи. Каждый компьютер работает под управлением собственной операционной системы, а какая-либо «общая» операционная система, распределяющая работу между компьютерами сети, отсутствует. Взаимодействие между компьютерами сети происходит за счет передачи сообщений через сетевые адаптеры и каналы связи. С помощью этих сообщений один компьютер обычно запрашивает доступ к локальным ресурсам другого компьютера. Такими ресурсами могут быть как данные, хранящиеся на диске, так и разнообразные периферийные устройства - принтеры, модемы, факс-аппараты и т. д. Разделение локальных ресурсов каждого компьютера между всеми пользователями сети - основная цель создания вычислительной сети.
Каким же образом сказывается на пользователе тот факт, что его компьютер подключен к сети? Прежде всего, он может пользоваться не только файлами, дисками, принтерами и другими ресурсами своего компьютера, но аналогичными ресурсами других компьютеров, подключенных к той же сети. Правда, для этого недостаточно снабдить компьютеры сетевыми адаптерами и соединить их кабельной системой. Необходимы еще некоторые добавления к операционным системам этих компьютеров. На тех компьютерах, ресурсы которых должны быть доступны всем пользователям сети, необходимо добавить модули, которые постоянно будут находиться в режиме ожидания запросов, поступающих по сети от других компьютеров. Обычно такие модули называются программными серверами (server), так как их главная задача - обслуживать (serve) запросы на доступ к ресурсам своего компьютера. На компьютерах, пользователи которых хотят получать доступ к ресурсам других компьютеров, также нужно добавить к операционной системе некоторые специальные программные модули, которые должны вырабатывать запросы на доступ к удаленным ресурсам и передавать их по сети на нужный компьютер. Такие модули обычно называют программными клиентами (client). Собственно же сетевые адаптеры и каналы связи решают в сети достаточно простую задачу - они передают сообщения с запросами и ответами от одного компьютера к другому, а основную работу по организации совместного использования ресурсов выполняют клиентские и серверные части операционных систем.
Пара модулей «клиент - сервер» обеспечивает совместный доступ пользователей к определенному типу ресурсов, например к файлам. В этом случае говорят, что пользователь имеет дело с файловой службой (service). Обычно сетевая операционная система поддерживает несколько видов сетевых служб для своих пользователей - файловую службу, службу печати, службу электронной почты, службу удаленного доступа и т. п.
83. Задача сетевого взаимодействия. Протокол, интерфейс, стек протоколов. Общая характеристика и уровни модели OSI.
При организации сетевого взаимодействия учитываются такие условия, как информационно-коммуникативная среда, создание определенной инфраструктуры, организация форм совместной деятельности. В результате этого возрастает качество образовательной деятельности. Каждый ее элемент самостоятелен и ценен чем-то своим, находится в постоянном развитии. Повторы, копирования при сетевой организации работы обесцениваются, а оригинальность, воображение, способность к творчеству растут. Изменяется содержание деятельности - изменяется и взаимодействие.
Важно заметить, что при сетевом взаимодействии происходит не только распространение инновационных разработок, а также идет процесс диалога между сетевыми школами и процесс отражения в них опыта друг друга, отображение тех процессов, которые происходят в системе образования в целом. Инновации в условиях образовательной сети приобретают эволюционный характер, что связано с непрерывным обменом информацией и опытом, отсутствием обязательного внедрения. Опыт участников сети оказывается востребованным не только в качестве примера для подражания, а также в качестве индикатора или зеркала, которое позволяет увидеть уровень собственного опыта и дополнить его чем-то новым, способствующим эффективности дальнейшей работы. У участников сети наблюдается потребность друг в друге, в общении равных по статусу специалистов и учреждений.
Для организации сетевого взаимодействия используются следующие методы: обмен файлами, организация видеоконференций, доступ к удалённой файловой системе, удалённый доступ к рабочему столу.
На практике протоколы и интерфейсы регламентируют технические требования, предъявляемые к программным и аппаратным средствам.
Разработка практических методов сетевого взаимодействия, как правило, подразумевает разработку не отдельных протоколов, а целых наборов протоколов. Такие наборы обычно включают в себя протоколы, относящиеся к нескольким смежным уровням эталонной модели OSI, и называются стеками (или семействами, наборами) протоколов (protocol stack, protocol suite). Наиболее известным стеком протоколов, обеспечивающим взаимодействие в сети Интернет, является стек протоколов TCP/IP.
Постоянное развитие информационных технологий приводит к появлению разнообразных информационных ресурсов, отличающихся друг от друга формами представления и методами обработки составляющих их информационных объектов. Поэтому в настоящее время в Интернет существует достаточно большое количество сервисов, обеспечивающих работу со всем спектром ресурсов.
Наиболее известными среди них являются:
• электронная почта (E-mail), обеспечивающая возможность обмена сообщениями одного человека с одним или несколькими абонентами;
• телеконференции, или группы новостей (Usenet), обеспечивающие возможность коллективного обмена сообщениями;
• сервис FTP – система файловых архивов, обеспечивающая хранение и пересылку файлов различных типов;
• сервис Telnet, предназначенный для управления удаленными компьютерами в терминальном режиме;
• World Wide Web (WWW, W3) – гипертекстовая (гипермедиа) система, предназначенная для интеграции различных сетевых ресурсов в единое информационное пространство;
• сервис DNS, или система доменных имен, обеспечивающий возможность использования для адресации узлов сети мнемонических имен вместо числовых адресов;
• сервис IRC, предназначенный для поддержки текстового общения в реальном времени (chat).
Протокол, интерфейс, стек протоколов
Многоуровневое представление средств сетевого взаимодействия имеет свою специфику, связанную с тем, что в процессе обмена сообщениями участвуют две стороны, то есть необходимо организовать согласованную работу двух иерархий, работающих на разных компьютерах.
Оба участника сетевого обмена должны принять множество соглашений. Соглашения должны быть приняты для всех уровней, начиная от самого низкого – уровня передачи битов – до самого высокого, реализующего сервис для пользователя. Декомпозиция предполагает четкое определение функции каждого уровня и интерфейсов между уровнями. Взаимодействие одноименных функциональных уровней по горизонтали осуществляется посредством протоколом. Протоколом называется набор правил и методов взаимодействия одноименных функциональных уровней объектов сетевого обмена. Взаимодействия функциональных уровней по вертикали осуществляется через интерфейсы. Интерфейс определяет набор функций, которые нижележащий уровень предоставляет вышележащему уровню. Таким образом, механизм передачи какого-либо пакета информации через сеть от клиентской программы, работающей на одном компьютере ПК 1, к клиентской программе, работающей на другом компьютере ПК 2, можно условно представить в виде последовательной пересылки этого пакета сверху вниз от верхнего уровня, обеспечивающего взаимодействие с пользовательским приложением, к нижнему уровню, организующему интерфейс с сетью, его трансляции на компьютер ПК 2 и обратной передачи верхнему уровню уже на ПК 2. Коммуникационные протоколы могут быть реализованы как программно, так и аппаратно. Протоколы нижних уровней часто реализуются комбинацией программных и аппаратных средств, а протоколы верхних уровней – как правило, чисто программными средствами. Протоколы реализуются не только компьютерами, но и другими сетевыми устройствами – концентраторами, мостами, коммутаторами, маршрутизаторами и т.д. В зависимости от типа устройств в нем должны быть встроенные средства, реализующие тот или иной набор протоколов. Иерархически организованный набор протоколов, достаточный для организации взаимодействия узлов в сети, называется стеком коммуникационных протоколов. В сети Интернет базовым набором протоколов является стек протоколов TCP/IP.
Сетевая модель OSI — абстрактная сетевая модель для коммуникаций и разработки сетевых протоколов. Предлагает взгляд на компьютерную сеть с точки зрения измерений. Каждое измерение обслуживает свою часть процесса взаимодействия. Благодаря такой структуре совместная работа сетевого оборудования и программного обеспечения становится гораздо проще и прозрачнее.
В настоящее время основным используемым стеком протоколов является TCP/IP, разработанный ещё до принятия модели OSI и вне связи с ней.
В литературе наиболее часто принято начинать описание уровней модели OSI с 7-го уровня, называемого прикладным, на котором пользовательские приложения обращаются к сети. Модель OSI заканчивается 1-м уровнем — физическим, на котором определены стандарты, предъявляемые независимыми производителями к средам передачи данных:
тип передающей среды (медный кабель, оптоволокно, радиоэфир и др.),
тип модуляции сигнала,
сигнальные уровни логических дискретных состояний (нуля и единицы).
Любой протокол модели OSI должен взаимодействовать либо с протоколами своего уровня, либо с протоколами на единицу выше и/или ниже своего уровня. Взаимодействия с протоколами своего уровня называются горизонтальными, а с уровнями на единицу выше или ниже — вертикальными. Любой протокол модели OSI может выполнять только функции своего уровня и не может выполнять функций другого уровня, что не выполняется в протоколах альтернативных моделей.
Каждому уровню с некоторой долей условности соответствует свой операнд — логически неделимый элемент данных, которым на отдельном уровне можно оперировать в рамках модели и используемых протоколов: на физическом уровне мельчайшая единица — бит, на канальном уровне информация объединена в кадры, на сетевом — в пакеты (датаграммы), на транспортном — в сегменты. Любой фрагмент данных, логически объединённых для передачи — кадр, пакет, датаграмма — считается сообщением. Именно сообщения в общем виде являются операндами сеансового, представительского и прикладного уровней.
К базовым сетевым технологиям относятся физический и канальный уровни.
Прикладной уровень— верхний уровень модели, обеспечивающий взаимодействие пользовательских приложений с сетью:
позволяет приложениям использовать сетевые службы:
удалённый доступ к файлам и базам данных,
пересылка электронной почты;
отвечает за передачу служебной информации;
предоставляет приложениям информацию об ошибках;
формирует запросы к уровню представления.
Протоколы прикладного уровня: RDP, HTTP, SMTP, SNMP, POP3, FTP, XMPP, OSCAR, Modbus, SIP, TELNET.
Представительный уровень обеспечивает преобразование протоколов и кодирование/декодирование данных. Запросы приложений, полученные с прикладного уровня, на уровне представления преобразуются в формат для передачи по сети, а полученные из сети данные преобразуются в формат приложений. На этом уровне может осуществляться сжатие/распаковка или кодирование/декодирование данных, а также перенаправление запросов другому сетевому ресурсу, если они не могут быть обработаны локально.
Уровень представлений обычно представляет собой промежуточный протокол для преобразования информации из соседних уровней. Это позволяет осуществлять обмен между приложениями на разнородных компьютерных системах прозрачным для приложений образом. Уровень представлений обеспечивает форматирование и преобразование кода. Уровень представлений имеет дело не только с форматами и представлением данных, он также занимается структурами данных, которые используются программами. Таким образом, уровень 6 обеспечивает организацию данных при их пересылке.
Сеансовый уровень модели обеспечивает поддержание сеанса связи, позволяя приложениям взаимодействовать между собой длительное время. Уровень управляет созданием/завершением сеанса, обменом информацией, синхронизацией задач, определением права на передачу данных и поддержанием сеанса в периоды неактивности приложений.
Транспортный уровень модели предназначен для обеспечения надёжной передачи данных от отправителя к получателю. При этом уровень надёжности может варьироваться в широких пределах. Существует множество классов протоколов транспортного уровня, начиная от протоколов, предоставляющих только основные транспортные функции (например, функции передачи данных без подтверждения приема), и заканчивая протоколами, которые гарантируют доставку в пункт назначения нескольких пакетов данных в надлежащей последовательности, мультиплексируют несколько потоков данных, обеспечивают механизм управления потоками данных и гарантируют достоверность принятых данных.
Канальный уровень предназначен для обеспечения взаимодействия сетей на физическом уровне и контроля за ошибками, которые могут возникнуть. Полученные с физического уровня данные он упаковывает в кадры, проверяет на целостность, если нужно, исправляет ошибки (формирует повторный запрос поврежденного кадра) и отправляет на сетевой уровень. Канальный уровень может взаимодействовать с одним или несколькими физическими уровнями, контролируя и управляя этим взаимодействием.
Физический уровень — нижний уровень модели, предназначенный непосредственно для передачи потока данных. Осуществляет передачу электрических или оптических сигналов в кабель или в радиоэфир и, соответственно, их приём и преобразование в биты данных в соответствии с методами кодирования цифровых сигналов. Другими словами, осуществляет интерфейс между сетевым носителем и сетевым устройством.
84. Структуризация и сегментация локальных сетей. Архитектура, характеристики и основные функции коммутаторов. Особенности функционирования при полнодуплексной работе.
Структуризация локальных сетей средствами канального уровня
Принцип использования разделяемой среды передачи данных позволяет строить эффективные вычислительные сети. Простота используемых протоколов обеспечивает невысокую стоимость построения сети. Пропускная способность достигает 100 Мбит/с и даже 1000 Мбит/с. Благодаря простой топологии такие сети обладают хорошей расширяемостью. Но масштабируемость таких сетей оставляет желать лучшего. С увеличением количества подключаемых компьютеров полезная пропускная способность сети резко уменьшается. Существует ограничение на количество подключаемых узлов, превышение которого резко уменьшает эффективность работы сети. Для построения больших вычислительных сетей, объединяющих сотни и тысячи узлов, используются коммутаторы (мосты). В последнее время производители пошли по пути объединения функций этих устройств в одном изделии. При небольшом увеличении стоимости потребитель получает больше возможностей при построении сетей. В отличие от концентраторов (хабов, повторителей), которые передают полученный кадр данных на все свои порты, коммутатор анализирует адрес, помещенный в кадр данных, и передает его только на порт, к которому подключен сегмент с узлом-получателем. Принцип работы коммутатора заключается в буферизации всех кадров, приходящих на его порты, и построении адресной таблицы, в которой адрес любого узла сети ставится в соответствие с портом коммутатора. Информация адресной таблицы динамически обновляется. При получении первого кадра от нового узла адрес этого узла записывается в адресную таблицу. Если в течение определенного времени от узла кадры не поступают, то запись в таблице об этом узле помечается как недействительная. Если адрес узла-получателя отсутствует в адресной таблице, то кадр пересылается на все порты, кроме порта, на который он пришел. Если узел-получатель есть в адресной таблице, то кадр передается на соответствующий порт. Операция продвижения кадра на другой порт сопровождается получением доступа к сегменту, подключенному к этому порту. Если узел-отправитель и узел-получатель находятся в одном сегменте, то кадр просто удаляется из буфера. Сегментация сети уменьшает нагрузку на отдельные сегменты сети и увеличивает полезную пропускную способность как отдельных сегментов, так и сети в целом. Сегментация, или разбиение сети на отдельные подсети, позволяет улучшить и другие свойства сети. При помощи мостов и коммутаторов можно управлять трафиком между подсетями. Улучшается управляемость сети, повышается безопасность данных.
Структуризация локальных сетей средствами сетевого уровня
Применение средств только канального уровня с использованием таких устройств, как концентраторы и коммутаторы, для построения больших вычислительных сетей имеет существенные ограничения и недостатки. Использование в качестве адреса назначения плоского МАС-адреса, связанного с сетевым адаптером, позволяет использовать лишь одноуровневую систему адресации, которая обладает недостаточной гибкостью при построении больших систем. Управление потоком информации при помощи коммутаторов на основе лишь данных кадра достаточно сложно. Сегментация вычислительной сети при помощи коммутаторов изолирует подсети в недостаточной мере в смысле защиты от широковещательных сообщений (широковещательных штормов). В разных сегментах вычислительной сети возможно использование разных базовых технологий. Но должна совпадать система адресации узлов. Например, Ethernet, Token Ring, FDDI, Fast Ethenet используют адресацию на основе МАС-адресов, а Х.25, ATM, Frame Relay - другие системы адресации. Другим ограничением применения коммутаторов для построения больших вычислительных сетей является обязательность отсутствия петель. Коммутатор может нормально работать только в случае, если между узлами есть только один маршрут. В то же время наличие избыточных связей является одним из основных способов для повышения надежности и улучшения трафика современной вычислительной сети. Для построения больших неоднородных вычислительных сетей используются средства сетевого уровня, основным используемым устройством которого является маршрутизатор. На сетевом уровне сеть называется составной сетью, состоящей из сетей, объединенных маршрутизаторами. Каждая сеть имеет свой номер. Каждый узел имеет номер внутри сети. Сетевой адрес узла состоит из этих номеров. Таким образом, в составных сетях каждый узел, кроме локального адреса, имеет дополнительный сетевой адрес. Данные, передаваемые на сетевом уровне, называются пакетами. Заголовки пакета, которыми снабжаются данные, содержат необходимую информацию о сети с узлом-получателем, и их формат не зависит от технологий, используемых внутри участвующих сетей. Пакет данных, который должен быть передан между узлами разных сетей, может транзитно передаваться через несколько сетей и связывающие их маршрутизаторы. Последовательность маршрутизаторов, которые проходит пакет данных, называется маршрутом. В общем случае в составной сети для передачи данных может и должно быть несколько маршрутов. Выбор оптимального маршрута является одной из основных задач маршрутизатора. Выбор маршрута следования пакета осуществляется на основе маршрутной информации, которая собирается маршрутизатором и записывается в специальную таблицу маршрутизации. В таблице маршрутизации номеру сети назначения ставится в соответствие сетевой адрес выходного порта маршрутизатора и сетевой адрес следующего маршрутизатора. В таблицу маршрутизации помещается и другая информация, позволяющая выбрать оптимальный по какому-либо критерию маршрут, например количество транзитных маршрутизаторов, которые необходимо пройти пакету, прежде чем пакет попадет в нужную сеть. Таблица маршрутизации создается автоматически путем периодического обмена между маршрутизаторами маршрутной информацией.
Дизайн коммутаторов наиболее часто описывается следующими четырьмя категориями:
-с разделяемой памятью;
Пакеты, предназначенные для разных портов, хранятся в специально отведенных раздельных областях памяти. Будут ли эти разделы фиксированной длины или переменной, зависит от особенностей реализации обсуждаемой архитектуры. Очевидно, что разделы переменной длины требуют более сложного управления, однако такой подход позволяет в большинстве случаев решить проблемы переполнения и значительно снизить потерю пакетов. Для выполнения операций записи и чтения за один такт память делается двухпортовой. Поскольку увеличение количества портов требует соответствующего повышения быстродействия памяти, то эта архитектура плохо расширяется. Кроме этого, контроллер, осуществляющий управление буферами, должен обрабатывать заголовки пакетов и маршрутные теги с той же скоростью, с которой работает память. Поэтому такой дизайн наиболее часто используется в небольших скоростных коммутаторах для объединения локальных сетей. Однако даже для коммутаторов средней (по количеству портов) величины требуемая частота внутренней шины становится чрезмерно большой. Так, для коммутатора с 32 входными портами и 16-разрядной шиной при скорости поступления данных 155 Mbps на порт необходимая тактовая частота внутренней шины составила бы 310 MHz.
-с разделяемой средой передачи;
Эта архитектура широко использовалась в ранних поколениях многопортовых коммутаторов, предназначенных для сетей Ethernet со скоростью передачи 10 Mbps. Пакеты поступали на шину последовательно. Если применялось мультиплексирование с разделением по времени (Time Division Multiplexing -- TDM), то каждому временному слоту соответствовал определенный выходной порт. Другое решение базировалось на адресных фильтрах, которые направляли пакет к нужному порту на основе маршрутной информации, содержащейся в заголовке пакета. Для коммутации могла также использоваться адресная шина.
-с полносвязной топологией "каждый с каждым";
При этом подходе между любой из N2 пар входных и выходных портов существует независимый путь. Поступающие во входные порты пакеты передаются по отдельным шинам ко всем выходным портам, и там в работу включаются адресные фильтры. Такие коммутаторы обычно оборудуются выходными буферами, количество которых в классическом варианте равно N2.
Полносвязный дизайн имеет ряд плюсов. В частности, легко реализуются широковещательный и многоадресный режимы передачи. Поскольку адресные фильтры и буфера должны работать со скоростью поступления данных в порт, такая архитектура легко масштабируется. Правда, за это нужно платить квадратичным ростом числа выходных буферов. Поэтому компанией AT&T был предложен так называемый коммутатор с выбыванием (knockout switch), с L буферами для каждого выходного порта, т. е. их общее количество составляло N x L. Это решение основывалось на предположении, что одновременное поступление на вход более чем L пакетов является маловероятным событием. Если же оно все же произойдет, то дополнительный элемент, называемый концентратором, отберет первые L, а остальные отбросит. Изменяя величину L, можно регулировать долю потерянных пакетов. Отметим, что для коммутаторов с выбыванием количество выходных буферов при увеличении числа портов растет линейно, как N x L, а не квадратично.
-с пространственным разделением.
При пространственном разделении между парами входных и выходных портов могут существовать как единственный, так и множественные пути. Простейшим примером такой архитектуры является коммутационная матрица (crossbar). В ней на каждом такте синхронизирующего генератора контроллер анализирует адресную информацию поступивших на входные порты пакетов и устанавливает соединения между портами по выделенному каналу. Маршрутизация в коммутационной матрице сходна с таковой в ячеистой сети. Поскольку пропускная способность выделенного канала определяется только физическими характеристиками передающей среды, то суммарная скорость передачи данных в таких коммутаторах может достигать более 100 Gbps. Однако в некоторых случаях при неравномерно распределенном относительно портов трафике производительность матричных коммутаторов может оказаться ниже, чем устройств с разделяемой памятью. Стандартным методом решения проблем, возникающих при конкуренции за выходной порт, является использование той или иной схемы буферизации. Для сокращения числа коммутационных элементов, необходимых при внутренней коммутации каналов, были разработаны многокаскадные сетевые архитектуры внутренних соединений (Multistage Interconnection Networks -- MIN). Прежде чем переходить к рассмотрению этого важного класса коммутаторов, напомним некоторые определения. Говорят, что сеть является самомаршрутизирующейся (self-routing), если состояние каждого бета-элемента определяется только информацией, содержащейся во входном пакете. Архитектура коммутатора называется неблокирующей (non-blocking), если одновременно может выполняться коммутация пакетов при любой перестановке путей от различных входных к различным выходным портам. Показано, что минимальное число бета-элементов, необходимое для перестраиваемой неблокирующей сети, равно N log2 N. Такие сети, также известные как сети Бенеша (Benes network), не являются самомаршрутизирующимися. В этом случае для определения состояния всех коммутационных элементов необходим контроллер. Следовательно, для построения перестраиваемой неблокирующей самомаршрутизирующейся коммутационной сети необходимо большее, чем указано выше, число коммутационных элементов. Представленная ниже архитектура является попыткой найти компромисс между степенью использования соединений, долей потерянных пакетов и сложностью дизайна. В число наиболее распространенных многокаскадных архитектур входят баньяноподобные коммутационные сети. Такое название они получили потому, что их схема напоминает корни тропического растения баньян (индийской смоковницы). Это самомаршрутизирующаяся архитектура, которая, однако, использует немного меньше бета-элементов, чем необходимо для построения неблокирующего коммутатора. Более точно их число равно (N/2) log2 N. Значит, можно получить такую комбинацию путей, что пакеты не смогут коммутироваться одновременно. Поэтому для обеспечения приемлемого количества потерянных пакетов необходима какая-нибудь схема буферизации. Баньяноподобные сети строятся с помощью взаимосвязанных каскадов коммутационных элементов. Базовый коммутационный элемент 2x2 может маршрутизировать входящие пакеты, основываясь на значении управляющего бита в поле адреса выходного порта: при значении "0" пакет коммутируется "прямо", в противном случае -- "наискосок". На рис. 5б представлена схема коммутатора 4 x 4, состоящего из двух каскадов. Здесь для принятия решения о маршруте необходимо использовать уже два адресных бита. При этом первый бит может указывать номер коммутационного элемента, в то время как второй -- адрес порта. Трехкаскадная сеть 8 x 8 формируется рекурсивно. Для нахождения маршрута используются три бита. По значению первого выполняется коммутация в первом каскаде, после которого пакеты направляются на "верхнюю" или "нижнюю" сеть 4 x 4, где повторяется описанный ранее алгоритм.
Полнодуплексный режим работы возможен только при существовании независимых каналов обмена данными для каждого направления и при соединении "точка-точка" двух взаимодействующих устройств. Естественно, необходимо, чтобы МАС-узлы взаимодействующих устройств поддерживали этот специальный режим. В случае, когда только один узел будет поддерживать полнодуплексный режим, второй узел будет постоянно фиксировать коллизии и приостанавливать свою работу, в то время как другой узел будет продолжать передавать данные, которые никто в этот момент не принимает.
Так как переход на полнодуплексный режим работы требует изменения логики работы МАС-узлов и драйверов сетевых адаптеров, то он сначала был опробован при соединении двух коммутаторов. Уже первые модели коммутатора EtherSwitch компании Kalpana поддерживали полнодуплексный режим при взаимном соединении, поддерживая скорость взаимного обмена 20 Мб/с.
85. Межсетевое взаимодействие средствами стека TCP/IP. Принципы маршрутизации в IP –сетях. Структуризация IP –сетей.
В настоящее время стек TCP/IP является самым популярным средством организации составных сетей. До 1996 года бесспорным лидером был стек IPX/SPX компании Novell, но затем картина резко изменилась - стек TCP/IP по темпам роста числа установок намного стал опережать другие стеки, а с 1998 года вышел в лидеры и в абсолютном выражении. Именно поэтому дальнейшее изучение функций сетевого уровня будет проводиться на примере стека TCP/IP.
Многоуровневая структура стека TCP/IP
В стеке TCP/IP определены 4 уровня. Каждый из этих уровней несет на себе некоторую нагрузку по решению основной задачи - организации надежной и производительной работы составной сети, части которой построены на основе разных сетевых технологий.
Уровень межсетевого взаимодействия
Стержнем всей архитектуры является уровень межсетевого взаимодействия, который реализует концепцию передачи пакетов в режиме без установления соединений, то есть дейтаграммным способом. Именно этот уровень обеспечивает возможность перемещения пакетов по сети, используя тот маршрут, который в данный момент является наиболее рациональным. Этот уровень также называют уровнем internet, указывая тем самым на основную его функцию - передачу данных через составную сеть.
Основным протоколом сетевого уровня (в терминах модели OSI) в стеке является протокол IP (Internet Protocol). Этот протокол изначально проектировался как протокол передачи пакетов в составных сетях, состоящих из большого количества локальных сетей, объединенных как локальными, так и глобальными связями. Поэтому протокол IP хорошо работает в сетях со сложной топологией, рационально используя наличие в них подсистем и экономно расходуя пропускную способность низкоскоростных линий связи. Так как протокол IP является дейтаграммным протоколом, он не гарантирует доставку пакетов до узла назначения, но старается это сделать.
К уровню межсетевого взаимодействия относятся и все протоколы, связанные с составлением и модификацией таблиц маршрутизации, такие как протоколы сбора маршрутной информации RIP (Routing Internet Protocol) и OSPF (Open Shortest Path First), а также протокол межсетевых управляющих сообщений ICMP (Internet Control Message Protocol). Последний протокол предназначен для обмена информацией об ошибках между маршрутизаторами сети и узлом-источником пакета. С помощью специальных пакетов ICMP сообщает о невозможности доставки пакета, о превышении времени жизни или продолжительности сборки пакета из фрагментов, об аномальных величинах параметров, об изменении маршрута пересылки и типа обслуживания, о состоянии системы и т. п.
Основной уровень
Поскольку на сетевом уровне не устанавливаются соединения, то нет никаких гарантий, что все пакеты будут доставлены в место назначения целыми и невредимыми или придут в том же порядке, в котором они были отправлены. Эту задачу -обеспечение надежной информационной связи между двумя конечными узлами -решает основной уровень стека TCP/IP, называемый также транспортным.
На этом уровне функционируют протокол управления передачей TCP (Transmission Control Protocol) и протокол дейтаграмм пользователя UDP (User Datagram Protocol). Протокол TCP обеспечивает надежную передачу сообщений между удаленными прикладными процессами за счет образования логических соединений. Этот протокол позволяет равноранговым объектам на компьютере-отправителе и компьютере-получателе поддерживать обмен данными в дуплексном режиме. TCP позволяет без ошибок доставить сформированный на одном из компьютеров поток байт в любой другой компьютер, входящий в составную сеть. TCP делит поток байт на части - сегменты, и передает их ниже лежащему уровню межсетевого взаимодействия. После того как эти сегменты будут доставлены средствами уровня межсетевого взаимодействия в пункт назначения, протокол TCP снова соберет их в непрерывный поток байт.
Протокол UDP обеспечивает передачу прикладных пакетов дейтаграммным способом, как и главный протокол уровня межсетевого взаимодействия IP, и выполняет только функции связующего звена (мультиплексора) между сетевым протоколом и многочисленными службами прикладного уровня или пользовательскими процессами.
Прикладной уровень
Прикладной уровень объединяет все службы, предоставляемые системой пользовательским приложениям. За долгие годы использования в сетях различных стран и организаций стек TCP/IP накопил большое количество протоколов и служб прикладного уровня. Прикладной уровень реализуется программными системами, построенными в архитектуре клиент-сервер, базирующимися на протоколах нижних уровней. В отличие от протоколов остальных трех уровней, протоколы прикладного уровня занимаются деталями конкретного приложения и «не интересуются» способами передачи данных по сети. Этот уровень постоянно расширяется за счет присоединения к старым, прошедшим многолетнюю эксплуатацию сетевым службам типа Telnet, FTP, TFTP, DNS, SNMP сравнительно новых служб таких, например, как протокол передачи гипертекстовой информации HTTP.
Уровень сетевых интерфейсов
Идеологическим отличием архитектуры стека TCP/IP от многоуровневой организации других стеков является интерпретация функций самого нижнего уровня - уровня сетевых интерфейсов. Протоколы этого уровня должны обеспечивать интеграцию в составную сеть других сетей, причем задача ставится так: сеть TCP/IP должна иметь средства включения в себя любой другой сети, какую бы внутреннюю технологию передачи данных эта сеть не использовала. Отсюда следует, что этот уровень нельзя определить раз и навсегда. Для каждой технологии, включаемой в составную сеть подсети, должны быть разработаны собственные интерфейсные средства.
Принципы маршрутизации в IP сетях
Рассмотрим на примере, как происходит поиск нужного компьютера в составной сети и как устанавливается соответствие символьного имени МАС-адресу.
Рассмотрим очень важный момент, касающийся принципов, на основании которых в сетях IP происходит выбор маршрута передачи пакета между сетями.
Сначала необходимо обратить внимание на тот факт, что не только маршрутизаторы, но и конечные узлы — компьютеры — должны принимать участие в выборе маршрута.
Здесь в локальной сети имеется несколько маршрутизаторов, и компьютер должен выбирать, какому из них следует отправить пакет.
Длина маршрута может существенно измениться в зависимости от того, какой маршрутизатор выберет компьютер для передачи своего пакета на сервер, расположенный, например, в Германии, если маршрутизатор 1 соединен выделенной линией с маршрутизатором в Копенгагене, а маршрутизатор 2 имеет спутниковый канал, соединяющий его с Токио.
В стеке TCP/IP маршрутизаторы и конечные узлы принимают решения о том, кому передавать пакет для его успешной доставки узлу назначения на основании так называемых таблиц маршрутизации (routing tables).
Таблица 2.2 представляет собой типичный пример таблицы маршрутов, использующей IP-адреса сетей.
В этой таблице в столбце «Адрес сети назначения» указываются адреса всех сетей, которым данный маршрутизатор может передавать пакеты. В стеке TCP/IP принят так называемый одноша-говый подход к оптимизации маршрута продвижения пакета (next-hop routing) — каждый маршрутизатор и конечный узел принимают участие в выборе только одного шага передачи пакета. Поэтому в каждой строке таблицы маршрутизации указывается не весь маршрут в виде последовательности IP-адресов маршрутизаторов, через которые должен пройти пакет, а только один IP-адрес — адрес следующего маршрутизатора, которому нужно передать пакет. Вместе с пакетом следующему маршрутизатору передается ответственность за выбор следующего шага маршрутизации. Одношаговый подход к маршрутизации означает распределенное решение задачи выбора маршрута. Это снимает ограничение на максимальное количество транзитных маршрутизаторов на пути пакета.
Таблица маршрутов
Адрес сети |
Адрес следующего |
Номер выходного |
Расстояние |
назначения |
маршрутизатора |
порта |
до сети назначения |
56.0.0.0 |
198.21.17.7 |
1 |
20 |
56.0.0.0 |
213.34.12.4 |
2 |
130 |
116.0.0.0 |
213.34.12.4 |
2 |
1450 |
129.13.0.0 |
198.21.17.6 |
1 |
50 |
198.21.17.0 |
— |
2 |
0 |
213.34.12.0 |
— |
1 |
0 |
default |
198.21.17.7 |
1 |
|
Альтернативой одношаговому подходу является указание в пакете всей последовательности маршрутизаторов, которые пакет дол-ясен пройти на своем пути. Такой подход называется маршрутизацией от источника — Source Routing. В этом случае выбор маршрута производится конечным узлом или первым маршрутизатором на пути пакета, а все остальные маршрутизаторы только отрабатывают выбранный маршрут, осуществляя коммутацию пакетов, то есть передачу их с одного порта на другой. Алгоритм Source Routing применяется в сетях IP только для отладки, когда маршрут задается в поле Резерв (IP OPTIONS) пакета.
В случае, если в таблице маршрутов имеется более одной строки, соответствующей одному и тому же адресу сети назначения, при принятии решения о передаче пакета используется та строка, в которой указано наименьшее значение в поле «Расстояние до сети назначения».
При этом под расстоянием понимается любая метрика, используемая в соответствии с заданным в сетевом пакете классом сервиса. Это может быть количество транзитных маршрутизаторов в данном маршруте (количество хопов), время прохождения пакета по линиям связи, надежность линий связи или другая величина, отражающая качество данного маршрута по отношению к конкретному классу сервиса. Если маршрутизатор поддерживает несколько классов сервиса пакетов, то таблица маршрутов составляется и применяется отдельно для каждого вида сервиса (критерия выбора маршрута).
Для отправки пакета следующему маршрутизатору требуется знание его локального адреса, но в стеке TCP/IP в таблицах маршрутизации принято использование только IP-адресов для сохранения их универсального формата, не зависящего от типа сетей, входящих в интерсеть. Для нахождения локального адреса по известному IP-адресу необходимо воспользоваться протоколом ARP.
Конечный узел, как и маршрутизатор, имеет в своем распоряжении таблицу маршрутов унифицированного формата и на основании ее данных принимает решение, какому маршрутизатору нужно передавать пакет для сети N. Решение о том, что этот пакет нужно маршрутизировать, компьютер принимает в том случае, когда он видит, что адрес сети назначения пакета отличается от адреса его собственной сети (каждому компьютеру при конфигурировании администратор присваивает его IP-адрес или несколько IP-адресов, если компьютер одновременно подключен к нескольким сетям). Когда компьютер выбрал следующий маршрутизатор, то он просматривает кэш- таблицу адресов своего протокола ARP и, может быть, находит там соответствие IP-адреса следующего маршрутизатора его МАС-адресу. Если же нет, то по локальной сети передается широковещательный ARP-запрос и локальный адрес извлекается из ARP-ответа.
После этого компьютер формирует кадр протокола, используемого на выбранном порту, например кадр Ethernet, в который помещает МАС-адрес маршрутизатора. Маршрутизатор принимает этот кадр, извлекает из него пакет IP и просматривает свою таблицу маршрутизации для нахождения следующего маршрутизатора. При этом он выполняет те же действия, что и конечный узел.
Структуризация сетей IP с помощью масок
Часто администраторы сетей испытывают неудобства, из-за того, что количество централизовано выделенных им номеров сетей недостаточно для того, чтобы структурировать сеть надлежащим образом, например, разместить все слабо взаимодействующие компьютеры по разным сетям.
В такой ситуации возможны два пути. Первый из них связан с получением от NIC дополнительных номеров сетей. Второй способ, употребляющийся более часто, связан с использованием так называемых масок, которые позволяют разделять одну сеть на несколько сетей.
Маска - это число, двоичная запись которого содержит единицы в тех разрядах, которые должны интерпретироваться как номер сети.
Например, для стандартных классов сетей маски имеют следующие значения:
255.0.0.0 - маска для сети класса А,
255.255.0.0 - маска для сети класса В,
255.255.255.0 - маска для сети класса С.
В масках, которые использует администратор для увеличения числа сетей, количество единиц в последовательности, определяющей границу номера сети, не обязательно должно быть кратным 8, чтобы повторять деление адреса на байты.
Пусть, например, маска имеет значение 255.255.192.0 (11111111 11111111 11000000 00000000). И пусть сеть имеет номер 129.44.0.0 (10000001 00101100 00000000 00000000), из которого видно, что она относится к классу В. После наложения маски на этот адрес число разрядов, интерпретируемых как номер сети, увеличилось с 16 до 18, то есть администратор получил возможность использовать вместо одного, централизованно заданного ему номера сети, четыре:
129.44.0.0 (10000001 00101100 00000000 00000000)
129.44.64.0 (10000001 00101100 01000000 00000000)
129.44.128.0 (10000001 00101100 10000000 00000000)
129.44.192.0 (10000001 00101100 11000000 00000000)
Например, IP-адрес 129.44.141.15 (10000001 00101100 10001101 00001111), который по стандартам IP задает номер сети 129.44.0.0 и номер узла 0.0.141.15, теперь, при использовании маски, будет интерпретироваться как пара:
129.44.128.0 - номер сети, 0.0. 13.15 - номер узла.
Таким образом, установив новое значение маски, можно заставить маршрутизатор по-другому интерпретировать IP-адрес. При этом два дополнительных последних бита номера сети часто интерпретируются как номера подсетей.
86. Основные функции протокола IP. Структура IP-пакета. Механизм фрагментации IP-пакетов.
Основу транспортных средств стека протоколов TCP/IP составляет протокол межсетевого взаимодействия (Internet Protocol, IP). Он обеспечивает передачу дейтаграмм от отправителя к получателям через объединенную систему компьютерных сетей.
Название данного протокола - Intrenet Protocol - отражает его суть: он должен передавать пакеты между сетями. В каждой очередной сети, лежащей на пути перемещения пакета, протокол IP вызывает средства транспортировки, принятые в этой сети, чтобы с их помощью передать этот пакет на маршрутизатор, ведущий к следующей сети, или непосредственно на узел-получатель.
Протокол IP относится к протоколам без установления соединений. Перед IP не ставится задача надежной доставки сообщений от отправителя к получателю. Протокол IP обрабатывает каждый IP-пакет как независимую единицу, не имеющую связи ни с какими другими IP-пакетами. В протоколе IP нет механизмов, обычно применяемых для увеличения достоверности конечных данных: отсутствует квитирование - обмен подтверждениями между отправителем и получателем, нет процедуры упорядочивания, повторных передач или других подобных функций. Если во время продвижения пакета произошла какая-либо ошибка, то протокол IP по своей инициативе ничего не предпринимает для исправления этой ошибки. Например, если на промежуточном маршрутизаторе пакет был отброшен по причине истечения времени жизни или из-за ошибки в контрольной сумме, то модуль IP не пытается заново послать испорченный или потерянный пакет. Все вопросы обеспечения надежности доставки данных по составной сети в стеке TCP/IP решает протокол TCP, работающий непосредственно над протоколом IP. Именно TCP организует повторную передачу пакетов, когда в этом возникает необходимость.
IP-пакет состоит из заголовка и поля данных. Заголовок, как правило, имеющий длину 20 байт, имеет следующую структуру (рис. 5.12).
Поле Номер версии (Version), занимающее 4 бит, указывает версию протокола IP. Сейчас повсеместно используется версия 4 (IPv4), и готовится переход на версию 6 (IPv6).
Поле Длина заголовка (IHL) IP-пакета занимает 4 бит и указывает значение длины заголовка, измеренное в 32-битовых словах. Обычно заголовок имеет длину в 20 байт (пять 32-битовых слов), но при увеличении объема служебной информации эта длина может быть увеличена за счет использования дополнительных байт в поле Опции (IP Options). Наибольший заголовок занимает 60 октетов.
Поле Тип сервиса (Type of Service) занимает один байт и задает приоритетность пакета и вид критерия выбора маршрута. Первые три бита этого поля образуют подполе приоритета пакета (Precedence), Приоритет может иметь значения от самого низкого - 0 (нормальный пакет) до самого высокого - 7 (пакет управляющей информации). Маршрутизаторы и компьютеры могут принимать во внимание приоритет пакета и обрабатывать более важные пакеты в первую очередь. Поле Тип сервиса содержит также три бита, определяющие критерий выбора маршрута. Реально выбор осуществляется между тремя альтернативами: малой задержкой, высокой достоверностью и высокой пропускной способностью. Установленный бит D (delay) говорит о том, что маршрут должен выбираться для минимизации задержки доставки данного пакета, бит Т - для максимизации пропускной способности, а бит R - для максимизации надежности доставки. Во многих сетях улучшение одного из этих параметров связано с ухудшением другого, кроме того, обработка каждого из них требует дополнительных вычислительных затрат. Поэтому редко, когда имеет смысл устанавливать одновременно хотя бы два из этих трех критериев выбора маршрута. Зарезервированные биты имеют нулевое значение.
Поле Общая длина (Total Length) занимает 2 байта и означает общую длину пакета с учетом заголовка и поля данных. Максимальная длина пакета ограничена разрядностью поля, определяющего эту величину, и составляет 65 535 байт, однако в большинстве хост-компьютеров и сетей столь большие пакеты не используются. При передаче по сетям различного типа длина пакета выбирается с учетом максимальной длины пакета протокола нижнего уровня, несущего IP-пакеты. Если это кадры Ethernet, то выбираются пакеты с максимальной длиной в 1500 байт, умещающиеся в поле данных кадра Ethernet. В стандарте предусматривается, что все хосты должны быть готовы принимать пакеты вплоть до 576 байт длиной (приходят ли они целиком или по фрагментам). Хостам рекомендуется отправлять пакеты размером более чем 576 байт, только если они уверены, что принимающий хост или промежуточная сеть готовы обслуживать пакеты такого размера.
Поле Идентификатор пакета (Identification) занимает 2 байта и используется для распознавания пакетов, образовавшихся путем фрагментации исходного пакета. Все фрагменты должны иметь одинаковое значение этого поля.
Поле Флаги (Flags) занимает 3 бита и содержит признаки, связанные с фрагментацией. Установленный бит DF (Do not Fragment) запрещает маршрутизатору фрагментировать данный пакет, а установленный бит MF (More Fragments) говорит о том, что данный пакет является промежуточным (не последним) фрагментом. Оставшийся бит зарезервирован.
Поле Смещение фрагмента (Fragment Offset) занимает 13 бит и задает смещение в байтах поля данных этого пакета от начала общего поля данных исходного пакета, подвергнутого фрагментации. Используется при сборке/разборке фрагментов пакетов при передачах их между сетями с различными величинами MTU. Смещение должно быть кратно 8 байт.
Поле Время жизни (Time to Live) занимает один байт и означает предельный срок, в течение которого пакет может перемещаться по сети. Время жизни данного пакета измеряется в секундах и задается источником передачи. На маршрутизаторах и в других узлах сети по истечении каждой секунды из текущего времени жизни вычитается единица; единица вычитается и в том случае, когда время задержки меньше секунды. Поскольку современные маршрутизаторы редко обрабатывают пакет дольше, чем за одну секунду, то время жизни можно считать равным максимальному числу узлов, которые разрешено пройти данному пакету до того, как он достигнет места назначения. Если параметр времени жизни станет нулевым до того, как пакет достигнет получателя, этот пакет будет уничтожен. Время жизни можно рассматривать как часовой механизм самоуничтожения. Значение этого поля изменяется при обработке заголовка IP-пакета.
Идентификатор Протокол верхнего уровня (Protocol) занимает один байт и указывает, какому протоколу верхнего уровня принадлежит информация, размещенная в поле данных пакета (например, это могут быть сегменты протокола TCP, дейтаграммы UDP, пакеты ICMP или OSPF). Значения идентификаторов для различных протоколов приводятся в документе RFC «Assigned Numbers».
Контрольная сумма (Header Checksum) занимает 2 байта и рассчитывается только по заголовку. Поскольку некоторые поля заголовка меняют свое значение в процессе передачи пакета по сети (например, время жизни), контрольная сумма проверяется и повторно рассчитывается при каждой обработке IP-заголовка. Контрольная сумма - 16 бит - подсчитывается как дополнение к сумме всех 16-битовых слов заголовка. При вычислении контрольной суммы значение самого поля «контрольная сумма» устанавливается в нуль. Если контрольная сумма неверна, то пакет будет отброшен, как только ошибка будет обнаружена.
Поля IP-адрес источника (Source IP Address) и IP-адрес назначения (Destination IP Address) имеют одинаковую длину - 32 бита - и одинаковую структуру.
Поле Опции (IP Options) является необязательным и используется обычно только при отладке сети. Механизм опций предоставляет функции управления, которые необходимы или просто полезны при определенных ситуациях, однако он не нужен при обычных коммуникациях. Это поле состоит из нескольких подполей, каждое из которых может быть одного из восьми предопределенных типов. В этих подполях можно указывать точный маршрут прохождения маршрутизаторов, регистрировать проходимые пакетом маршрутизаторы, помещать данные системы безопасности, а также временные отметки. Так как число подполей может быть произвольным, то в конце поля Опции должно быть добавлено несколько байт для выравнивания заголовка пакета по 32-битной границе.
Поле Выравнивание (Padding) используется для того, чтобы убедиться в том, что IP-заголовок заканчивается на 32-битной границе. Выравнивание осуществляется нулями.
Существующие сети очень многообразны, каждая сеть имеет свою индивидуальную настройку, которая по мнению администратора поможет уменьшить коллизии, увеличить быстродействие и удобство работы соответственно. Есть такое понятие как MTU. MTU – максимальный размер Ethernet кадра, другими словами - максимально возможный размер «блока» который может передать протокол канального уровня. Логично заметить, что напрямую от этого параметра зависит скорость передачи данных в сети, ведь чем больше размер пакетов тем быстрее вся информация передастся на удаленный компьютер. У различных сетей это значение может быть разное. И как же тогда быть когда нам надо доставить данные в сеть с меньшим значением MTU? Как раз для этого и был разработан механизм фрагментации. Фрагментация это процесс разбития IP пакета в соответствии со значением MTU и последующей передачи его на канальный уровень. Как раз для этого механизма в заголовке IP пакета присутствуют спец. поля Идентификатор, Флаги , Смещение фрагмента. Для начала рассмотрим назначение этих полей: Идентификатор(ID) – «имя» фрагмента, по этому полю удаленный хост определяет все фрагменты одного целостного IP пакета. Размер 16 бит. Флаги(Flags) – это поле содержит 3 бита, 2 из них определяют фрагментирован ли пакет и последний ли это фрагмент. Младший бит всегда равен 0. Бит DF: 0 – фрагментация разрешена, 1 – фрагментация запрещена Бит MF: 0 – последний фрагмент или пакет не фрагментирован, 1 – не последний фрагмент. Смещение фрагмента(Fragment Offset) – определяет смещение данных этого фрагмента относительно их позиции в целостном IP пакете. Смещение считается по 64 бита (8 октетов). Размер 13 бит. Рассмотрим процесс фрагментации на примере пакета который отправили из сети с сети FDDI (MTU=4500) в сеть Ethernet (MTU=1500). Хост-отправитель выставил такие служебные поля: На маршрутизаторе который соединяет нашу сеть с сетью отправителя произойдет фрагментация пакета: Ну а теперь как всегда пояснения. Пакет который нам отправили пришел на «пограничный» маршрутизатор. После определения несоответствия значения MTU маршрутизатор запустил механизм фрагментации IP пакета. На наш компьютер придут 3 пакета, которые удовлетворяют значениям MTU. Как видим у исходного пакета бит DF = 0, значит мы можем фрагментировать этот пакет, бит MF сброшен, в данном случае это означает что это единственный фрагмент. И теперь посмотрим на те пакеты которые получил наш ПК. Значение поля ID у всех фрагментов одинаково, что свидетельствуют о том что это фрагменты одного цельного IP пакета. Поле Total Length не относиться к фрагментации, но я решил для наглядности его показать, как мы видим все пакеты удовлетворили стандартному значению MTU для Ethernet. бит DF у всех остался 0 (пакет можно фрагментировать). Теперь разберем у всех 3 фрагментов бит MF и смещение фрагмента: Первый фрагмент – бит MF = 1, значит этот фрагмент не последний. Поле смещения = 0 т.к. это первый фрагмент, поэтому данные содержащиеся в нем будут начальными данными всего IP пакета. Второй фрагмент – бит MF = 1, значит этот фрагмент не последний. Поле смещения = 185. Теперь смотрим как это получилось: смещение записывается порциями по 64 бита или 8 октетов (64\8=8).общая длина фрагмента у нас 1500 октетов, отнимаем 20 октетов, которые содержаться в IP заголовке, получаем 1480 октетов. Теперь делим на 8, что бы получить смещение, 1480\8=135. Третий фрагмент – бит MF = 0, значит этот фрагмент последний. Поле смещения = 370 т.к. у нас одинаковая длина октетов. Получается такое же смещение относительно второго фрагмента, значит 185+185 = 370. По сети фрагменты путешествуют как обычные IP пакеты. Собираются воедино только на узле-получателе. Фрагментация имеет и свои минусы: 1)Трата ресурсов отправителя и звеньевых маршрутизаторов. Для того что бы выполнить фрагментацию надо высчитать контрольную сумму для всех фрагментов, скопировать каждому заголовок оригинального IP пакет (разумеется внести туда изменения). 2)Если любой из фрагментов не дошел то все дошедшие фрагменты удаляются и приходиться заново посылать весь IP пакет и выполнить все что написано выше.
87. Локальные вычислительные сети (ЛВС). Основные топологии ЛВС.
Лока́льная вычисли́тельная сеть — компьютерная сеть, покрывающая обычно относительно небольшую территорию или небольшую группу зданий (дом, офис, фирму, институт). Также существуют локальные сети, узлы которых разнесены географически на расстояния более 12 500 км (космические станции и орбитальные центры). Несмотря на такие расстояния, подобные сети всё равно относят к локальным.
Построение сети
Существует множество способов классификации сетей. Основным критерием классификации принято считать способ администрирования. То есть в зависимости от того, как организована сеть и как она управляется, её можно отнести к локальной, распределённой, городской или глобальной сети. Управляет сетью или её сегментом сетевой администратор. В случае сложных сетей их права и обязанности строго распределены, ведётся документация и журналирование действий команды администраторов.
Компьютеры могут соединяться между собой, используя различные среды доступа: медные проводники (витая пара), оптические проводники (оптические кабели) и через радиоканал (беспроводные технологии). Проводные связи устанавливаются через Ethernet, беспроводные — через Wi-Fi, Bluetooth, GPRS и прочие средства. Отдельная локальная вычислительная сеть может иметь связь с другими локальными сетями через шлюзы, а также быть частью глобальной вычислительной сети (например,Интернет) или иметь подключение к ней.
Чаще всего локальные сети построены на технологиях Ethernet или Wi-Fi. Следует отметить, что ранее использовались протоколы Frame Relay, Token ring, которые на сегодняшний день встречаются всё реже, их можно увидеть лишь в специализированных лабораториях, учебных заведениях и службах. Для построения простой локальной сети используются маршрутизаторы, коммутаторы, точки беспроводного доступа, беспроводные маршрутизаторы, модемы и сетевые адаптеры. Реже используются преобразователи (конвертеры) среды, усилители сигнала (повторители разного рода) и специальные антенны.
Маршрутизация в локальных сетях используется примитивная, если она вообще необходима. Чаще всего это статическая либо динамическая маршрутизация (основанная на протоколе RIP).
Иногда в локальной сети организуются рабочие группы — формальное объединение нескольких компьютеров в группу с единым названием.
Сетевой администратор — человек, ответственный за работу локальной сети или её части. В его обязанности входит обеспечение и контроль физической связи, настройка активного оборудования, настройка общего доступа и предопределённого круга программ, обеспечивающих стабильную работу сети.
Технологии локальных сетей реализуют, как правило, функции только двух нижних уровней модели OSI - физического и канального. Функциональности этих уровней достаточно для доставки кадров в пределах стандартных топологий, которые поддерживают LAN: звезда (общая шина), кольцо и дерево. Однако из этого не следует, что компьютеры, связанные в локальную сеть, не поддерживают протоколы уровней, расположенных выше канального. Эти протоколы также устанавливаются и работают на узлах локальной сети, но выполняемые ими функции не относятся к технологии LAN.
Адресация
В локальных сетях, основанных на протоколе IPv4, могут использоваться специальные адреса, назначенные IANA (стандарты RFC 1918 и RFC 1597):
10.0.0.0—10.255.255.255;
172.16.0.0—172.31.255.255;
192.168.0.0—192.168.255.255.
Такие адреса называют частными, внутренними, локальными или «серыми»; эти адреса не доступны из сети Интернет. Необходимость использовать такие адреса возникла из-за того, что при разработке протокола IP не предусматривалось столь широкое его распространение, и постепенно адресов стало не хватать. Для решения этой проблемы был разработан протокол IPv6, однако он пока малопопулярен. В различных непересекающихся локальных сетях адреса могут повторяться, и это не является проблемой, так как доступ в другие сети происходит с применением технологий, подменяющих или скрывающих адрес внутреннего узла сети за её пределами — NAT или прокси дают возможность подключить ЛВС к глобальной сети (WAN). Для обеспечения связи локальных сетей с глобальными применяются маршрутизаторы (в роли шлюзов и файрволов).
Конфликт IP адресов — распространённая ситуация в локальной сети, при которой в одной IP-подсети оказываются два или более компьютеров с одинаковыми IP-адресами. Для предотвращения таких ситуаций и облегчения работы сетевых администраторов применяется протокол DHCP, позволяющий компьютерам автоматически получать IP-адрес и другие параметры, необходимые для работы в сети TCP/IP.
LAN и VPN
Связь с удалённой локальной сетью, подключенной к глобальной сети, из дома/командировки/удалённого офиса часто реализуется через VPN. При этом устанавливается VPN-подключение к пограничному маршрутизатору.
Особенно популярен следующий способ организации удалённого доступа к локальной сети:
Обеспечивается подключение снаружи к маршрутизатору, например по протоколу PPPoE, PPTP или L2TP (PPTP+IPSec).
Так как в этих протоколах используется PPP, то существует возможность назначить абоненту IP-адрес. Назначается свободный (не занятый) IP-адрес из локальной сети.
Маршрутизатор (VPN, Dial-in сервер) добавляет proxyarp — запись на локальной сетевой карте для IP-адреса, который он выдал VPN-клиенту. После этого, если локальные компьютеры попытаются обратиться напрямую к выданному адресу, то они после ARP-запроса получат MAC-адрес локальной сетевой карты сервера и трафик пойдёт на сервер, а потом и в VPN-туннель.
Топология - это конфигурация сети, способ соединения элементов сети (то есть компьютеров) друг с другом. Чаще всего встречаются три способа объединения компьютеров в локальную сеть: "звезда", "общая шина" и "кольцо".
Соединение типа "звезда". Каждый компьютер через специальный сетевой адаптер подключается отдельным кабелем к объединяющему устройству. При необходимости можно объединить вместе несколько сетей с топологией "звезда", при этом конфигурация сети получается разветвленной.
Достоинства: При соединении типа "звезда" легко искать неисправность в сети.
Недостатки: Соединение не всегда надежно, поскольку выход из строя центрального узла может привести к остановке сети.

Соединение "общая шина". Все компьютеры сети подключаются к одному кабелю; этот кабель используется совместно всеми рабочими станциями по очереди. При таком типе соединения все сообщения, посылаемые каждым отдельным компьютером, принимаются всеми остальными компьютерами в сети.
Достоинства: в топологии "общая шина" выход из строя отдельных компьютеров не приводит всю сеть к остановке.
Недостатки: несколько труднее найти неисправность в кабеле и при обрыве кабеля (единого для всей сети) нарушается работа всей сети.
Соединение типа "кольцо". Данные передаются от одного компьютера к другому; при этом если один компьютер получает данные, предназначенные для другого компьютера, то он передает их дальше (по кольцу).
Достоинства: балансировка нагрузки, возможность и удобство прокладки кабеля.
Недостатки: физические ограничения на общую протяженность сети.

От схемы зависит состав оборудования и программного обеспечения. Топологию выбирают, исходя из потребностей предприятия. Если предприятие занимает многоэтажное здание, то в нем может быть применена схема "снежинка", в которой имеются файловые серверы для разных рабочих групп и один центральный сервер для всего предприятия.

88. Многопользовательские вычислительные системы
Корпоративные компьютеры (иногда называемые мини-ЭВМ или main frame) представляют собой вычислительные системы, обеспечивающие совместную деятельность большого количества интеллектуальных работников в какой-либо организации, проекте при использовании единых информационно-вычислительных ресурсов. Это многопользовательские вычислительные системы, имеющие центральный блок большой вычислительной мощности и со значительными информационными ресурсами, к которому подсоединено большое количество рабочих мест с минимальной оснащенностью (обычно это клавиатура, устройства позиционирования типа «мышь» и, возможно, устройство печати). В качестве рабочих мест, подсоединяемых к центральному блоку корпоративного компьютера, могут выступать и персональные компьютеры. Сфера использования корпоративных компьютеров - обеспечение управленческой деятельности в крупных финансовых и производственных организациях. Организация различных информационных систем для обслуживания большого количества пользователей в рамках одной функции (биржевые и банковские системы, бронирование и продажа билетов населению и т.п.). Суперкомпьютеры представляют собой вычислительные системы с предельными характеристиками вычислительной мощности и информационных ресурсов и используются в военной и космической областях, и фундаментальных научных исследованиях, глобальном прогнозировании погоды. Данная классификация довольно условленна, так как интенсивное развитие технологий электронных компонентов и совершенствование архитектуры компьютеров, а также наиболее важных их элементов приводят к размыванию границ между средствами вычислительной техники.
Особенности и характеристики современных многопользовательских вычислительных систем
Среднее время наработки на отказ. Время наработки на отказ современных многопользовательских вычислительных систем оценивается в 12-15 лет. Надёжность многопользовательских вычислительных систем — это результат их почти 60-летнего совершенствования. Группа разработки операционной системы VM/ESA затратила 20 лет на удаление ошибок, и в результате была создана система, которую можно использовать в самых ответственных случаях.
Повышенная устойчивость систем. Многопользовательские вычислительные системы могут изолировать и исправлять большинство аппаратных и программных ошибок за счёт использования следующих принципов:
Дублирование: два резервных процессора, резервные модули памяти, альтернативные пути доступа к периферийным устройствам.
Горячая замена всех элементов вплоть до каналов, плат памяти и центральных процессоров.
Целостность данных. В многопользовательская вычислительная системаах используется память с коррекцией ошибок. Ошибки не приводят к разрушению данных в памяти, или данных, ожидающих вывода на внешние устройства. Дисковые подсистемы построенные на основе RAID-массивов с горячей заменой и встроенных средств резервного копированиязащищают от потерь данных.
Рабочая нагрузка. Рабочая нагрузка многопользовательских вычислительных систем может составлять 80-95 % от их пиковой производительности. Операционная система многопользовательской вычислительной системы будет обрабатывать всё сразу, причём все приложения будут тесно сотрудничать и использовать общие компоненты ПО.
Пропускная способность. Подсистемы ввода-вывода многопользовательских вычислительных систем разработаны так, чтобы работать в среде с высочайшей рабочей нагрузкой на ввод-вывод данных.
Масштабирование. Масштабирование многопользовательских вычислительных систем может быть как вертикальным, так и горизонтальным. Вертикальное масштабирование обеспечивается линейкой процессоров с производительностью от 5 до 200 MIPS и наращиванием до 12 центральных процессоров в одном компьютере. Горизонтальное масштабирование реализуется объединением ЭВМ в Sysplex (System Complex) — многомашинный кластер, выглядящий с точки зрения пользователя единым компьютером. Всего в Sysplex можно объединить до 32 машин. Географически распределённый Sysplex называют GDPS. В случае использования операционной системы VM для совместной работы можно объединить любое количество компьютеров. Программное масштабирование — на одной многопользовательской вычислительной системе может быть сконфигурировано фактически бесконечное число различных серверов. Причем все серверы могут быть изолированы друг от друга так, как будто они выполняются на отдельных выделенных компьютерах и в то же время совместно использовать аппаратные и программные ресурсы и данные.
Доступ к данным. Поскольку данные хранятся на одном сервере, прикладные программы не нуждаются в сборе исходной информации из множества источников, не требуется дополнительное дисковое пространство для их временного хранения, не возникают сомнения в их актуальности. Требуется небольшое количество физических серверов и значительно более простое программное обеспечение. Всё это, в совокупности, ведёт к повышению скорости и эффективности обработки.
Защита. Встроенные в аппаратуру возможности защиты, такие как криптографические устройства, и Logical Partition, и средства защиты операционных систем, дополненные программными продуктами RACF или VM:SECURE, обеспечивают надёжную защиту.
Пользовательский интерфейс. Пользовательский интерфейс у многопользовательских вычислительных систем всегда оставался наиболее слабым местом. Сейчас же стало возможно для прикладных программ многопользовательских вычислительных систем в кратчайшие сроки и при минимальных затратах обеспечить современный веб-интерфейс.
Сохранение инвестиций — использование данных и существующих прикладных программ не влечёт дополнительных расходов по приобретению нового программного обеспечения для другой платформы, переучиванию персонала, переноса данных и т. д.
89. Сетевые Службы. Сетевые файловые системы: принципы функционирования, интерфейс.
Практически все современные ОС являются сетевыми, т.е. позволяют пользователям получать доступ, как к локальным ресурсам, так и к ресурсам других компьютеров, подключенных к сети.
При работе в сети ОС опираются на функции ОС по управлению локальными ресурсами. Сетевые службы реализуют специфические функции по организации совместной работы пользователей сети.