

1. Файлы субд (sql Server, Oracle, Firebird, Access и т. Д.)
В большинстве случаев извлечение данных из СУБД не вызывает проблем, поскольку структура данных в них жестко задана, соответствует определенным стандартам и общепринятым требованиям. Кроме того, за целостностью и непротиворечивостью данных в СУБД обычно следят опытные инженеры.
2. Структурированные файлы различных форматов (Excel, csv-файлы, html-документы и т. Д.)
Такие файлы очень широко распространены, поскольку средства их создания (в большинстве случаев это типовые офисные приложения) общедоступны и не требуют высокой квалификации персонала и высокой производительности систем. Здесь проблем больше, поскольку пользователь может допускать ошибки, пропуски, вводить противоречивые данные, терять фрагменты данных и т. д. Пользователи офисных приложений часто понятия не имеют о том, что такое тип данных, и уж тем более не связывают вводимые ими данные с задачами будущего анализа. Очевидно, что в этой ситуации при извлечении данных можно столкнуться с чем угодно.
3. Неструктурированные источники(рисунки, видео и прочее).
Если избежать использования неструктурированных источников не получается, нужно применить специальные средства их преобразования в структурированный вид. Когда источник невелик, возможно, это удастся сделать вручную. Но в большинстве случаев приходится разрабатывать специальный инструментарий, учитывающий особенности организации данных в источнике и то, какую структуру из них следует создать. Существуют также готовые программные системы для решения этой задачи. Конечная цель структурирования – так упорядочить данные в файле, чтобы их в том или ином виде можно было загрузить в реляционную таблицу.
Проблемы извлечения данных из разнотипных источников и перенос их в хранилище данных с целью дальнейшей аналитической обработки:
Исходные данные расположены в источниках самых разнообразных типов и форматов, созданных в различных приложениях, и, кроме того, могут использовать различную кодировку, в то время как для решения задач анализа данные должны быть преобразованы в единый универсальный формат, который поддерживается хранилищем данных.
Данные в источниках обычно излишне детализированы, тогда как для решения задач анализа в большинстве случаев требуются обобщенные данные.
Исходные данные, как правило, являются «грязными», то есть содержат различные факторы, которые мешают их корректному анализу.
ETL (extraction, transformation, loading – «извлечение», «преобразование», «загрузка») – комплекс методов, реализующих процесс переноса исходных данных из различных источников в хранилище данных
С точки зрения процесса ETL архитектуру ХД можно представить в виде трех компонентов:
источник данных;
промежуточная область;
получатель данных.
Основные этапы процесса переноса данных
1. Извлечение данных. Данные извлекаются из одного или нескольких источников и подготавливаются к преобразованию. Для корректного представления данных после их загрузки в ХД из источников должны извлекаться не только сами данные, но и информация, описывающая их структуру, из которой будут сформированы метаданные для хранилища
З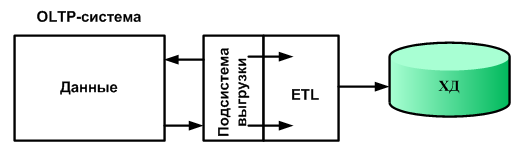 агрузка
данных – запись преобразованных
данных в соответствующую систему
хранения
агрузка
данных – запись преобразованных
данных в соответствующую систему
хранения
Два основных способа извлечения данных:
С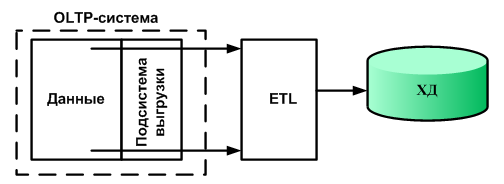 помощью специализированных программных
средств
помощью специализированных программных
средств
Средствами той системы, в которой они хранятся
2. Преобразование данных. Производятся преобразование форматов и коди-ровки данных, а также их обобщение и очистка.
Является вторым этапом ETL-процесса, следующий за извлечением. Его цель – подготовка данных к размещению в хранилище данных и приведение их к виду, наиболее удобному для последующего анализа.
В процессе преобразования может быть задействован самый разнообразный инструментарий, начиная от простейших средств ручного редактирования данных до систем, реализующих весьма сложные методы обработки и очистки данных.
Операции, используемые в процессе преобразования данных
1. Преобразование структуры данных
2. Агрегирование данных (Способы вычисления агрегатов: среднее, сумма, максимум, минимум, количество, медиана)
3. Перевод значений
4. Создание новых данных
5. Очистка данных
Типичные ошибки, соответствующие структурным единицам баз данных
1. На уровне ячейки - Орфографические ошибки, пропуски данных, фиктивные значения, логические несоответствия, закодированные и составные значения.
2. На уровне записи - Противоречия между ячейками.
3. На уровне таблицы - Дублирование записей, противоречивые записи.
4. На уровне отдельной БД - Целостность данных.
5. На уровне множества БД - Различные правила назначения имен полей, различия в используемых типах полей, одинаковые названия полей для разных атрибутов, различная временная шкала
Место выполнения преобразований данных
В процессе извлечения данных
В промежуточной области перед загрузкой данных в хранилище
В процессе загрузки данных в хранилище данных
Все операции преобразования, которые могут потребоваться при переносе данных в ХД, обычно не сосредотачиваются на одном шаге ETL-процесса, а распределяются по различным этапам в зависимости от того, где выполнение преобразования более эффективно