

6. Способи усунення тренда. Моделі згладжування для часових рядів, що не мають тренда: комбінована модель.
. Для того, щоб в цьому випадку можна було застосувати модель, призначену для процесів, що не мають тренда, можна поступити одним з наступних двох способів.
Спосіб 1. Розглянемо різниці або частки початкових даних. Таким чином, якщо є ряд даних Y1, Y2, ..., Yn, то розглядається ряд: Δ2, ..., Δn, де Δt = Yt – Yt-1, або ряд р2, ..., рn, де
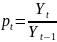 (4.3)
(4.3)
Якщо менеджер вважає, що можна нехтувати зміною в змодельованих квартальних темпах зростання, то він може розглядати р2, ..., рn як ряд, що не має тренда, і застосувати до нього наївну або будь-яку іншу модель, призначену для рядів, що не мають тренда.
Спосіб 2 полягає в розгляді залишків лінійної регресії і є одним з найчастіше використовуваних методів усунення тренда. Його називають методом детрендалізації.
Якщо коефіцієнт b2 лінійного рівняння регресії для ряду еi має нулі в перших чотирьох десяткових розрядах, то він може вважатися рівним нулю. Тепер можна побудувати модель для ряду без тренда для залишків еі, потім знайти відповідне змодельоване значення ek при k > 17, і додати його до відповідного значення тренда. Оскільки наївна модель припускає, що et-1≈ et, то її слід застосовувати у тому випадку, коли коефіцієнт кореляції r(et-1, et ) при t = 2, ..., n, позитивний і значно відрізняється від нуля. У такому разі говорять, що в моделі лінійної регресії є позитивна автокореляція першого порядку. Існує спеціальний тест (тест Дарбіна-Уотсона) на наявність автокореляції першого порядку.
Прогноз визначається шляхом додавання змодельованої помилки е19 до відповідного значення тренда.
7. Визначення початкових значень моделі.
Для обчислення значення моделі у момент t ми повинні знати її значення в попередній момент t - 1, то перед нами встає задача визначення початкових значень моделі (в даному випадку у момент часу t = 1).
Найпростіший
спосіб – узяти як початкове значення
 або
або
 .
.
У сучасному прогнозуванні досить поширений метод прогнозування назад (backcasting). Наприклад, можна розглянути модель, подібну моделі (4.7), з тією лише різницею, що рекурсивність здійснюється у зворотному напрямі:
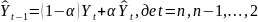 (4.10)
(4.10)
(4.11)
Початкове значення можна взяти відповідно до досвіду і розуміння прогнозистом процесу.
Найкращий спосіб визначення початкових значень, особливо для прогнозистів, що починають, полягає у виборі опції, «автоматично» присутньої у всіх статистичних пакетах.
5. Моделі згладжування з трендом: модель Холта, модель Брауна.
Модель Холта.
Застосуємо модель
експоненціального згладжування до
різниць
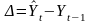 ,
з константою згладжування, рівною 1 –
β, де 0 ≤ β < 1. При цьому значення
моделі позначимо як Тt
і назвемо їх значеннями тренда. Таким
чином, одержуємо перше
рівняння Холта:
,
з константою згладжування, рівною 1 –
β, де 0 ≤ β < 1. При цьому значення
моделі позначимо як Тt
і назвемо їх значеннями тренда. Таким
чином, одержуємо перше
рівняння Холта:
 (4.12)
(4.12)
друге рівняння Холта:
 (4.13)
(4.13)
Побудова моделі зводиться до трьох основних етапів.
Ухвалюють рішення щодо величин параметрів моделі α і β. Якщо немає особливих переваг, то оптимальні значення α і β визначають як завжди, виходячи з мінімізації MSE.
Визначають початкові значення
 і Tt.
Що ж до Tt.,
то можна узяти Т1 = (Δ2
+ Δ4 )/2.
і Tt.
Що ж до Tt.,
то можна узяти Т1 = (Δ2
+ Δ4 )/2.Поперемінно знаходять і Tt. При цьому спочатку обчислюють і лише потім – Tt.
Модель подвійного експоненціального згладжування з трендом (модель Брауна – Brown's double exponential smoothing model with trend).
модель Брауна визначається наступною формулою:
 (4.15)
(4.15)
Прогноз на h кроків вперед визначається формулою:
 (4.16)
(4.16)