

2.6.1 Протокол rip
RIP — это Routing Information Protocol — протокол маршрутной информации. RIP относится к широкоизвестному классу протоколов маршрутизации, основанных на алгоритме Беллмана-Форда, относящемуся к классу так называемых алгоритмов векторов расстояний. Этот протокол наиболее подходит для использования в качестве внутреннего (меж) шлюзового протокола (ЮР), т.е. для маршрутизации сообщений внутри автономной системы (AS), которая работает под неким единым началом и по единым принципам. RIP предназначен для работы в сетях (автономных системах) умеренных размеров, использующих достаточно однородную технологию. Он подходит для сетей многих компаний, научных и учебных заведений, использующих последовательные линии передачи данных, пропускные способности которых меняются в пределах сети незначительно.
ЮР в качестве метрики может использовать только статические функции (постоянные по времени). Использование динамических метрик приводит к возникновению неустойчивостей, которые RIP отрабатывать не умеет.
Алгоритмы векторов расстояний основаны на обмене между маршрутизаторами только информацией о "расстояниях" между ними, точнее о соответствующих метриках. При этом считается, что сами сети являются точечными объектами, т.е. расстояния между любыми двумя узлами одной сети равны нулю, поэтому расстояния между маршрутизаторами двух разных сетей равны расстоянию между этими сетями.
Каждый маршрутизатор имеет таблицу с перечислением всех других сетей данного домена маршрутизации с указанием тех своих соседей, через которых проходят пути к этим сетям, и соответствующих метрик — расстояний до этих сетей от сети данного маршрутизатора. Таким образом, эти таблицы расстояний индивидуальные у каждого маршрутизатора и отличаются от таблиц других маршрутизаторов.
Очевидно, что из этой таблицы расстояний составить собственно таблицу маршрутизации — пара пустяков — просто выбросить длины путей, и таблица готова. Вся проблема в том, как составить эти таблицы (вектора) расстояний так, чтобы они соответствовали действительности. Именно для этого и нужен алгоритм Беллмана-Форда. Давайте придумаем простенькую систему сетей и будем вести рассуждения на её примере. См. рис. 2.9. Пусть узлы А, B, С, D и Т являются маршрутизаторами сетей с аналогичными названиями. Пусть, далее, все линии, кроме линии C-D имеют "длины" 1, а линия C-D — 10. Можно считать, что реально это не длины, а, например, стоимости пересылки по этим линиям связи.
Советуем вам самим проследить, что происходит в этой системе с таблицами расстояний. Пусть, например, начальное состояние векторов расстояний такое, как показано в таблице на рис.2.10. Здесь специально придумано наиболее неопределенное начальное состояние таблиц, чтобы вы сами смогли убедиться, что алгоритм Беллмана-Форда приводит к нужному результату при любых начальных условиях. Естественно, расстояния между соседями должны всегда соответствовать действительности, идиотизировать их мы не имеем права, иначе, исчезнет источник достоверной информации о состоянии сети.
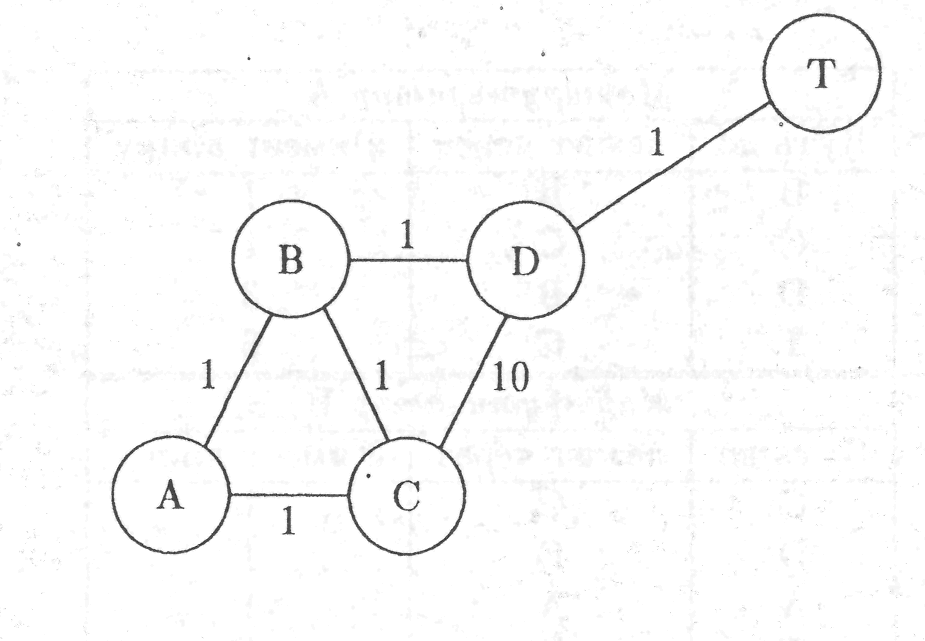
Рис. 2.9: Пример сети
Алгоритм Беллмана-Форда велит действовать так.
Каждый маршрутизатор рассылает свою таблицу расстояний всем маршрутизаторам — его непосредственным соседям. Фактически это означает, что маршрутизатор сообщает всем своим соседям, что он думает, что от него добираться до разных сетей следует так-то (через таких-то его соседей), и что эти пути имеют такие-то длины. Соседи принимают это всерьёз и начинают корректировать с учётом этой информации свои собственные таблицы расстояний.
А именно, если маршрутизатор, положим для определённости, С видит, что его сосед, пусть это будет А, знает более короткий путь до некоторой сети, например до сети Т, чем он сам, естественно, маршрутизатор учитывает путь от него до соседа, просто складывая эти пути, т.е. если оказывается, что через соседа А путь до сети Т короче, то он изменяет запись в своей таблице расстояний, соответствующую сети Т, вписывает туда, что до сети Т путь лежит через этого самого соседа A и имеет длину:
(длина пути, сообщённая соседом А)+(длина пути до соседа А).
Если же маршрутизатор С видит, что тот его сосед (А), через который проходит путь от него (С) к сети Т, вдруг говорит, что путь от него (от А) до этого самой сети Т, оказывается, длиннее, чем он (А) думал раньше, то С безропотно меняет в записи в своей таблице, соответствующей сети Т, старое расстояние на новое, которое он вычисляет тем же очевидным образом:
(длина пути, сообщённая соседом)+(длина пути до соседа).
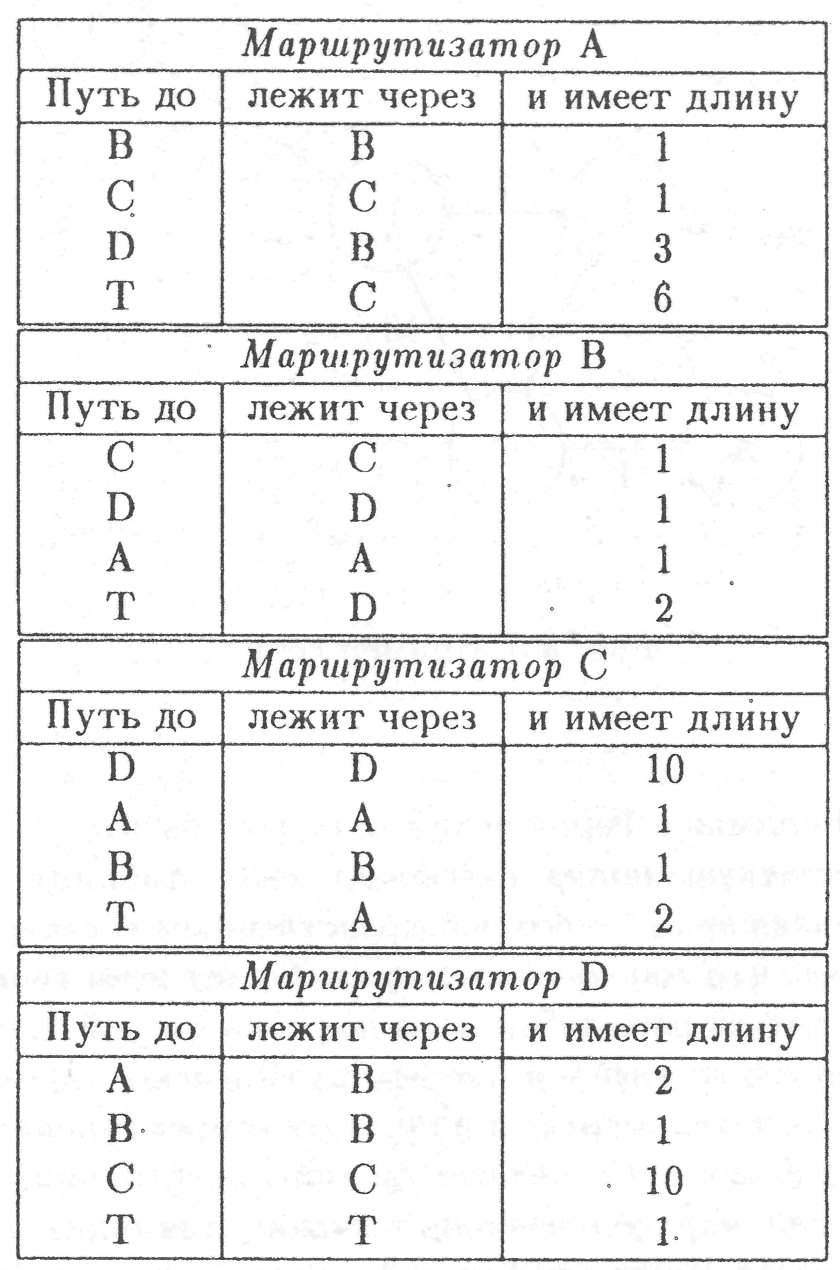
Рис. 2.10: Пример начального состояния таблицы расстояний
Очевидно, что расстояния между соседями должны быть известны заранее — это собственно и есть задаваемая метрика. И такие переговоры нужно повторять до полного удовлетворения. Вот, собственно, и весь алгоритм Беллмана-Форда.
Существует математически строгое доказательство того, что этот алгоритм порождает сходящуюся последовательность векторов расстояний, причём, эта последовательность сходится к нужному вектору состояний для каждого маршрутизатора. Да, естественно, доказательство основано на условиях теоремы, рассматривающей только случай стационарной сети, т.е. сети, в которой топология постоянна во времени: линии не рвутся, маршрутизаторы не ломаются и т.д.
Предполагается, что участники этого процесса не перестают рассылать сообщения, и сами сообщения не вязнут навечно в недрах сети. При этом почти не делается никаких предположений о том, в каком порядке рассылаются сообщения с векторами расстояний, и в какие моменты времени может происходить изменение векторов расстояний. Как вы сами видите, условия теоремы содержат очень слабые требования.
Отсутствие ограничений на моменты рассылки сообщений позволяет всем маршрутизаторам работать асинхронно, по своим собственным часам.
Отсутствие ограничений на начальные состояния векторов расстояний, кроме лишь того, что все расстояния должны быть неотрицательными, означает, что если топология сети изменяется, то процесс всё равно будет продолжать сходиться, но, скорее всего, уже к новому вектору расстояний. Действительно, при изменении топологии сети мы можем просто забыть, всё что прежде было, и считать, что мы начинаем всё сначала.
Итак, процесс сходится за конечное время при отсутствии изменений в топологии сети. Если изменения случаются, то процесс будет постоянно сходиться, но сама равновесная точка будет скакать под действием этих изменений топологии. При этом ебудетсли изменения топологии сети достаточно редки, то процесс будет успевать сходиться, и хоть какое-то время будет осуществляться корректная маршрутизация, а если изменения топологии будут слишком часты, то алгоритм утратит дееспособность и маршрутизация совсем разладится.
Однако, исходный алгоритм Беллмана-Форда не предусматривает случая, когда некая сеть или её маршрутизатор становятся совсем недоступны, так как это фактически равносильно тому, что этот маршрутизатор перестаёт рассылать сообщения. В таком случае, теорема о сходимости неприменима, а процесс, совершенно очевидно, никогда не сойдётся.
Поэтому RIP развивает алгоритм Беллмана-Форда, обвешивая его разными хитростями. Покажем, как постепенно приходится навешивать парочку таких уловок.
Для случаев обрыва линий RIP должен иметь механизм диагностики обрыва. Диагностика выполняется просто: если сеть не отвечает соседу слишком долго, считается, что линия связи оборвана. Этой линии присваивается метрика, называемая "бесконечностью". В действительности, это просто число, которое реальной метрикой быть не может, будем пока считать, что оно является только признаком этой "бесконечности" и никаким иным целям не служит. "Бесконечность" при сложении с любым числом даёт опять "бесконечность". И "бесконечность" больше любого другого числа.
Теперь самостоятельно составьте таблицы расстояний для каждого маршрутизатора для приведённого примера сети, соответствующих стационарному состоянию системы сетей, убедитесь, что они порождают корректные таблицы маршрутизации.
Что будет со сходимостью, например, в случае обрыва линии B-D. Промоделируйте, что будет твориться в сети теперь. Особенно внимательно следите за тем, что будет происходить с маршрутизацией сообщений от А к Т и от С к Т. Видите? До А и С быстро дошло, что путь к Т через В теперь закрыт. А продолжает считать, что путь к Т по-прежнему открыт через С, а С считает, что путь к Т открыт через А. Это может длится довольно долго, очевидно, тем дольше, чем больше "длина" линии C-D.
Для борьбы с такими зацикливаниями было решено использовать пресловутую "бесконечность". Её сделали обычным конечным числом, но оставили правило, гласящее, что сумма "бесконечности" и любого числа есть "бесконечность". При такой трактовке "бесконечности" вышеописанное кивание А и С друг на друга, очевидно, будет продолжаться до тех пор, пока они постепенно не доведут длину путей к Т, проложенных друг через друга до "бесконечности"+1. Уловка сработала, но для её практического использования следует придумать, каким числом должна быть "бесконечность". Очевидно, что с одной стороны, это число должно быть достаточно большим, чтобы никакой реальный путь не мог иметь такую большую длину. Однако, с другой стороны, это число должно быть как можно меньше, чтобы вышеописанный процесс "счёта до бесконечности" продолжался как можно меньшее время. Сначала в качестве компромиса было выбрано 15. Позже, с ростом Internet "бесконечность" довели до 30. Очевидно, что эта самая "бесконечность" ограничивает сверху возможную длину пути, что может быть нежелательно в больших сетях.
Существует множество других уловок, придуманных для избавления от "счёта до бесконечности", но все они носят частный характер, и только "бесконечность" по-прежнему остаётся надёжной гарантией от зацикливаний в общем случае.
На этом мы кончим наш рассказ о RIP. Более подробно о RIP вы можете прочитать в RFC 1058, 1721-1724.