

Чтение (ввод) визуальной информации.
Преобладающие на практике одноцветные, плоские изображения можно описать одним распределением типа B=B(x,y). Оно характеризует яркость В в зависимости от координат х и у любой точки изображения. При этом для бумаги и других непрозрачных материалов яркость точки носителя определяется величиной коэффициента отражения. Для диапозитивов и фотоплёнки – величиной коэф. пропускания. Для экранов – яркостью светового пятна.
Процесс ввода визуальной информации в ЭВМ состоит их 2-х процессов: Считывание и Кодирование.
Считывание сводится к определению координат элементов изображения в заданной координатной сетке. Кодирование считанной информации заключается в преобразовании её в цифровой код для последующей обработки в машине.
Чтоб представить визуальную информацию в цифровой форме необходимо:
Дискретизировать пространство;
Проквантовать яркость каждой точки.
Наиболее просто и естественно дискредитация достигается с помощью координатной сетки, образованной линиями, параллельными оси х и у декартовой системы координат. В каждом узле такой решётки делается отсчёт яркости или прозрачности носителя длительно воспринимаемой информации. Затем она квантуется и передаётся в память ЭВМ. Результат дискретизации и квантования представляется в виде матрицы, элементами которой служат отсчёты в узлах решётки. Такое представление визуальной информации называется рецепторным, естественным, поэлементным или матричным. Оно наиболее удобно описывает процесс ввода/вывода изображений и легко устанавливать однозначное соответствие между картиной и её представлением в памяти ЭВМ.
Широкий класс датчиков, использующихся для ввода изображения ЭВМ, представляют собой набор светочувствительных элементов – рецепторов, расположенных в углах рецепторной сетки. Они преобразуют световой сигнал в электрический. В процессе ввода рецепторы окрашиваются в определённой последовательности и снимаемые с них сигналы преобразуются в цифровую форму. Таким образом, получается последовательность отсчётов в углах координатной сетки. Например, при использовании телевизионных датчиков информация, содержащаяся в телевизионном кадре, считывается последовательно, т.е. отсчёты по времени образуют следующую последовательность:
…a11 a12 a13 a14 … a1n
…a21 a22 a23 a24 … a2n
………………………….
…am1 am2 am3 … amn
где аij – элемент матрицы отсчётов, располагаемый на i-ой строке и j-ом столбце, m – число строк матрицы, n – чисто столбцов.
При использовании других датчиков, например, твердотельных как ПЗС считыватель ШК, отсчёты могут выдаваться в другой последовательности. Этот способ представления находит применение во всех случаях как промежуточный при считывании визуальной информации. В связи с этим задачу кодирования визуальной информации рассматривают как задачу преобразования естественной формы представления в форму, удобную для хранения и обработки ЭВМ.
Д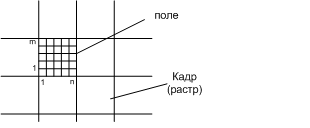 ля
решения задачи кодирования выделены
структурные единицы визуальной
информации. Всю подлежащую записи в
матрицу визуальную информацию называют
картиной или сценой. На размер картины
никаких ограничений не накладывается.
В частном случае её размеры могут
превышать размеры рецепторного поля,
используемого для ввода картины в
матрицу. В этом случае картина разбивается
на прямоугольные участки, называемые
растрами или кадрами. Каждый кадр
соответствует рецепторным размерам
датчика и содержит m x
n отсчётов, образующих
прямоугольную матрицу, состоящую из m
строк и n столбцов. Каждый
отсчёт характеризуется списком к-уровней
квантования видеосигнала. Обычно
полагают К=2^k, где к –
целое число. Иногда выделяют ещё одну
структурную единицу информации – поле.
ля
решения задачи кодирования выделены
структурные единицы визуальной
информации. Всю подлежащую записи в
матрицу визуальную информацию называют
картиной или сценой. На размер картины
никаких ограничений не накладывается.
В частном случае её размеры могут
превышать размеры рецепторного поля,
используемого для ввода картины в
матрицу. В этом случае картина разбивается
на прямоугольные участки, называемые
растрами или кадрами. Каждый кадр
соответствует рецепторным размерам
датчика и содержит m x
n отсчётов, образующих
прямоугольную матрицу, состоящую из m
строк и n столбцов. Каждый
отсчёт характеризуется списком к-уровней
квантования видеосигнала. Обычно
полагают К=2^k, где к –
целое число. Иногда выделяют ещё одну
структурную единицу информации – поле.
Поле – это часть кадра (растра), образованная несколькими соседними отсчётами. Параметры m, n и к выбирают в зависимости от требуемой точности представления информации с учётом возможностей оптического датчика.
Если в качестве датчика использовать телекамеру, работающую в стандартном режиме, число строк и столбцов растра обычно изменяется от 256 до 512, а число различных уровней не превышает 256 (к<=8) – число уровней яркости. В общем случае для поэлементной записи кадра требуется память, содержащая W= m*n*k бит информации. Для поэлементного представления кадра требуется значительный объём памяти. Например, если m=n=256, k=8? То требуется 65.6 Кбайт памяти на один кадр.
При определении способа размещения информации в памяти машины, необходимо учитывать тот факт, что память имеет словарную структуру (в виде слова), т.е. существует минимальное адресуемое слово фиксированной длины S. В общем случае S не равно k (и не кратно). В связи с этим существует два подхода размещения отчётов:
Для представления информации используются все разряды всех слов выделяемого раздела ОЗУ. В этом случае достигается максимальная компактность и требуется минимальный объём памяти. Однако такое размещение не удобно для обработки информации, т.к. отдельные отчеты будут располагаться в нескольких словах.
Каждый отсчёт целиком представляется несколькими машинными словами. Но при этом используются не все разряды слова, что влечёт увеличение требуемого объёма памяти. Например, если принять этот подход, когда расчёт располагается в отдельном слове, то для представления одного кадра потребуется n x m слов. В связи с этим задача кодирования визуальной информации формулируется как задача такого представления, которое занимает минимальный объём памяти. Практическая значимость минимизации объёма памяти становится очевидной для задач, анализирующих значительные размеры картин, содержащих большое чисто растров. Чтоб получить некоторую численную оценку рассмотрим пример, в котором размер картины 200 х 300 мм, каждый отсчёт представляется словом, содержащим 8 двоичных разрядов. При шаге рецепторной сетки 0.1 мм потребуется память в 6 Мбайт.