

Основы вычислительной техники. (Вторые вопросы в билетах)
Основные элементы компьютерных систем (процессор, регистры процессора, основная память, управление памятью, концепция виртуальной памяти, устройства ввода-вывода, системная шина).
Современная компьютерная система содержит центральный процессор, первичное и вторичное устройства хранения данных (память), устройства ввода и вывода, а также коммуникационные устройства (см. Рис. 1.1).
Рис. 1.1 Компоненты аппаратного обеспечения компьютера. |
|
В современном компьютере можно выделить
шесть основных компонентов. Центральный
процессор обрабатывает данные и
управляет другими устройствами
компьютера; первичная память хранит
выполняющиеся в данный момент программы
и обрабатываемые данные; вторичная
память хранит программы и данные для
дальнейшего использования; устройства
ввода преобразуют данные и инструкции
в форму, удобную для обработки в
компьютере; устройства вывода
представляют информацию, обработанную
компьютером, в виде, удобном для
человеческого восприятия; коммуникационные
устройства управляют приемом и
передачей данных в локальных и
глобальных сетях.
|
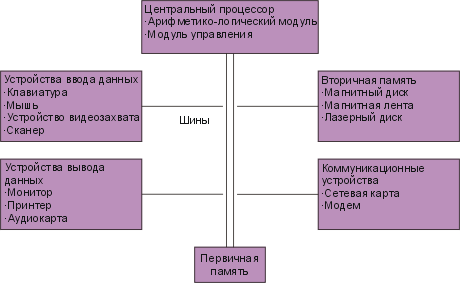
Центральный процессор преобразует поток данных в удобную для обработки форму, а также управляет другими компонентами компьютерной системы. Первичное хранилище данных временно хранит инструкции программы и данные во время обработки. Вторичное устройство хранения данных (магнитный или лазерный диск, магнитная лента) хранит данные и программы, которые не участвуют в обработке в данный момент. Устройства ввода, такие как клавиатура и мышь, преобразуют данные и команды в электронную форму, понятную компьютеру. Устройства вывода, такие как принтер и монитор, преобразуют электронные данные, представленные компьютером, и отображают их в той форме, в какой их могут понять люди. Коммуникационные устройства обеспечивают соединения между компьютерами и компьютерными сетями. Шина (bus) – это устройство для передачи данных и сигналов между различными частями компьютерной системы.
Центра́льный проце́ссор (ЦП; также центральное процессорное устройство — ЦПУ; англ. central processing unit, CPU, дословно — центральное обрабатывающее устройство) — электронный блок либо интегральная схема (микропроцессор), исполняющая машинные инструкции (код программ), главная часть аппаратного обеспечения компьютера или программируемого логического контроллера. Иногда называют микропроцессором или простопроцессором.
Главными характеристиками ЦПУ являются: тактовая частота, производительность, энергопотребление, нормы литографического процесса используемого при производстве (для микропроцессоров) и архитектура.
Ранние ЦП создавались в виде уникальных составных частей для уникальных, и даже единственных в своём роде, компьютерных систем. Позднее от дорогостоящего способа разработки процессоров, предназначенных для выполнения одной единственной или нескольких узкоспециализированных программ, производители компьютеров перешли к серийному изготовлению типовых классов многоцелевых процессорных устройств. Тенденция к стандартизации компьютерных комплектующих зародилась в эпоху бурного развития полупроводниковых элементов, мейнфреймов и миникомпьютеров, а с появлением интегральных схем она стала ещё более популярной. Создание микросхем позволило ещё больше увеличить сложность ЦП с одновременным уменьшением их физических размеров. Стандартизация и миниатюризация процессоров привели к глубокому проникновению основанных на них цифровых устройств в повседневную жизнь человека. Современные процессоры можно найти не только в таких высокотехнологичных устройствах, как компьютеры, но и в автомобилях, калькуляторах, мобильных телефонах и даже в детских игрушках. Чаще всего они представлены микроконтроллерами, где помимо вычислительного устройства на кристалле расположены дополнительные компоненты (память программ и данных, интерфейсы, порты ввода/вывода, таймеры и др.). Современные вычислительные возможности микроконтроллера сравнимы с процессорами персональных ЭВМ десятилетней давности, а чаще даже значительно превосходят их показатели.
Большинство современных процессоров для персональных компьютеров в общем основаны на той или иной версии циклического процесса последовательной обработки данных, изобретённого Джоном фон Нейманом.
Дж. фон Нейман придумал схему постройки компьютера в 1946 году.
Отличительной особенностью архитектуры фон Неймана является то, что инструкции и данные хранятся в одной и той же памяти.
В различных архитектурах и для различных команд могут потребоваться дополнительные этапы. Например, для арифметических команд могут потребоваться дополнительные обращения к памяти, во время которых производится считывание операндов и запись результатов.
Этапы цикла выполнения:
Процессор выставляет число, хранящееся в регистре счётчика команд, на шину адреса и отдаёт памяти команду чтения.
Выставленное число является для памяти адресом; память, получив адрес и команду чтения, выставляет содержимое, хранящееся по этому адресу, на шину данных и сообщает о готовности.
Процессор получает число с шины данных, интерпретирует его как команду (машинную инструкцию) из своей системы команд и исполняет её.
Если последняя команда не является командой перехода, процессор увеличивает на единицу (в предположении, что длина каждой команды равна единице) число, хранящееся в счётчике команд; в результате там образуется адрес следующей команды.
Данный цикл выполняется неизменно, и именно он называется процессом (откуда и произошло название устройства).
Во время процесса процессор считывает последовательность команд, содержащихся в памяти, и исполняет их. Такая последовательность команд называется программой и представляет алгоритм работы процессора. Очерёдность считывания команд изменяется в случае, если процессор считывает команду перехода, — тогда адрес следующей команды может оказаться другим. Другим примером изменения процесса может служить случай получения команды остановка или переключение в режим обработки прерывания.
Команды центрального процессора являются самым нижним уровнем управления компьютером, поэтому выполнение каждой команды неизбежно и безусловно. Не производится никакой проверки на допустимость выполняемых действий, в частности, не проверяется возможная потеря ценных данных. Чтобы компьютер выполнял только допустимые действия, команды должны быть соответствующим образом организованы в виде необходимой программы.
Скорость перехода от одного этапа цикла к другому определяется тактовым генератором. Тактовый генератор вырабатывает импульсы, служащие ритмом для центрального процессора. Частота тактовых импульсов называется тактовой частотой.
Регистр процессора — блок ячеек памяти, образующий сверхбыструю оперативную память (СОЗУ) внутри процессора; используется самим процессором и большой частью недоступен программисту: например, при выборке из памяти очередной команды она помещается врегистр команд (англ.), к которому программист обратиться не может.
Имеются также регистры, которые в принципе программно доступны, но обращение к ним осуществляется из программ операционной системы, например, управляющие регистры и теневые регистры дескрипторов сегментов. Этими регистрами пользуются в основном разработчики операционных систем.
Существуют также так называемые регистры общего назначения (РОН), представляющие собой часть регистров процессора, использующихся без ограничения в арифметических операциях, но имеющие определенные ограничения, например в строковых. РОН, не характерные для эпохи мейнфреймов типа IBM/370[1] стали популярными в микропроцессорах архитектуры X86 — i8085, i8086 и последующих[2].
Специальные регистры[3] содержат данные, необходимые для работы процессора — смещения базовых таблиц, уровни доступа и т. д.
Часть специальных регистров принадлежит устройству управления, которое управляет процессором путём генерации последовательности микрокоманд.
Доступ к значениям, хранящимся в регистрах, как правило, в несколько раз быстрее, чем доступ к ячейкам оперативной памяти (даже если кеш-память содержит нужные данные), но объём оперативной памяти намного превосходит суммарный объём регистров (объём среднего модуля оперативной памяти сегодня составляет 1-4 Гб[4], суммарная «ёмкость» регистров общего назначения/данных для процессора Intel 80386 и более новых 32 битов * 8 = 256 бит).
Все процессоры архитектуры x86 (даже многоядерные, большие и сложные) являются дальними потомками древнего Intel 8086 и совместимы с его архитектурой. Это значит, что программы на ассемблере 8086 будут работать и на всех современных процессорах x86.
Все внутренние регистры процессора Intel 8086 являются 16-битными:
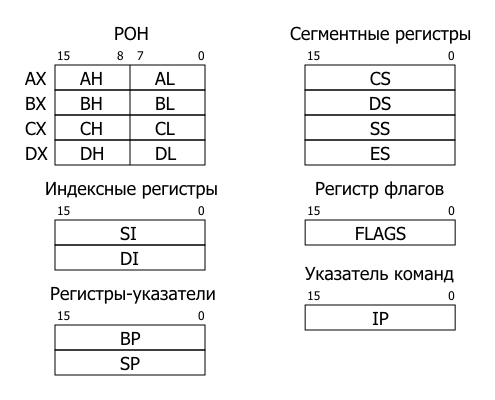
Всего процессор содержит 12 программно-доступных регистров, а также регистр флагов (FLAGS) и указатель команд (IP).
Регистры общего назначения (РОН) AX, BX, CX и DX используются для хранения данных и выполнения различных арифметических и логических операций. Кроме того, каждый из этих регистров поделён на 2 части по 8-бит, с которыми можно работать как с 8-битными регистрами (AH, AL, BH, BL, CH, CL, DH, DL). Младшие части регистров имеют в названии букву L (от слова Low), а старшие H (от слова High). Некоторые команды неявно используют определённый регистр, например, CX может выполнять роль счетчика цикла.
Индексные регистры предназначены для хранения индексов при работе с массивами. SI (Source Index) содержит индекс источника, а DI (Destination Index) — индекс приёмника, хотя их можно использовать и как регистры общего назначения.
Регистры-указатели BP и SP используются для работы со стеком. BP (Base Pointer) позволяет работать с переменными в стеке. Его также можно использовать в других целях. SP (Stack Pointer) указывает на вершину стека. Он используется командами, которые работают со стеком. (Про стек я подробно расскажу в отдельной части учебного курса)
Сегментные регистры CS (Code Segment), DS (Data Segment), SS (Stack Segment) и ES (Enhanced Segment) предназначены для обеспечения сегментной адресации. Код находится в сегменте кода, данные — в сегменте данных, стек — в сегменте стека и есть еще дополнительный сегмент данных. Реальный физический адрес получется путём сдвига содержимого сегментного регистра на 4 бита влево и прибавления к нему смещения (относительного адреса внутри сегмента). Подробнее о сегментной адресации рассказывается в части 31.
COM-программа всегда находится в одном сегменте, который является одновременно сегментом кода, данных и стека. При запуске COM-программы сегментные регистры будут содержать одинаковые значения.
Указатель команд IP (Instruction Pointer) содержит адрес команды (в сегменте кода). Напрямую изменять его содержимое нельзя, но процессор делает это сам. При выполнении обычных команд значение IP увеличивается на размер выполненной команды. Существуют также команды передачи управления, которые изменяют значение IP для осуществления переходов внутри программы.
Регистр флагов FLAGS содержит отдельные биты: флаги управления и признаки результата. Флаги управления меняют режим работы процессора:
D (Direction) — флаг направления. Управляет направлением обработки строк данных: DF=0 — от младших адресов к старшим, DF=1 — от старших адресов к младшим (для специальных строковых команд).
I (Interrupt) — флаг прерывания. Если значение этого бита равно 1, то прерывания разрешены, иначе — запрещены.
T (Trap) — флаг трассировки. Используется отладчиком для выполнения программы по шагам.
Признаки результата устанавливаются после выполнения арифметических и логических команд:
S (Sign) — знак результата, равен знаковому биту результата операции. Если равен 1, то результат — отрицательный.
Z (Zero) — флаг нулевого результата. ZF=1, если результат равен нулю.
P (Parity) — признак чётности результата.
C (Carry) — флаг переноса. CF=1, если при сложении/вычитании возникает перенос/заём из старшего разряда. При сдвигах хранит значение выдвигаемого бита.
A (Auxiliary) — флаг дополнительного переноса. Используется в операциях с упакованными двоично-десятичными числами.
O (Overflow) — флаг переполнения. CF=1, если получен результат за пределами допустимого диапазона значений.
Основная память - это устройство для хранения информации. Она состоит из оперативного запоминающего устройства (ОЗУ) и постоянного запоминающего устройства (ПЗУ). Оперативное запоминающее устройство (ОЗУ) ОЗУ-быстрая, полупроводниковая, энергозависимая память. В ОЗУ хранятся исполняемая в данный момент программа и данные, с которыми она непосредственно работает. Это значит, что когда вы запускаете какую-либо компьютерную программу, находящуюся на диске, она копируется в оперативную память, после чего процессор начинает выполнять команды, изложенные в этой программе. Часть ОЗУ, называемая "видеопамять", содержит данные, соответствующие текущему изображению на экране. При отключении питания содержимое ОЗУ стирается. Быстродействие (скорость работы) компьютера напрямую зависит от величины его ОЗУ, которое в современных компьютерах может доходить до 128 Мбайт. В первых моделях компьютеров оперативная память составляла не более 1 Мбайт. Современные прикладные программы часто требуют для своего выполнения не менее 4 Мбайт ОЗУ; в противном случае они просто не запускаются. ОЗУ - это память, используемая как для чтения, так и для записи информации. При отключении электропитания информация в ОЗУ исчезает (энергозависимость). Постоянное запоминающее устройство (ПЗУ) ПЗУ - быстрая, энергонезависимая память. ПЗУ - это память, предназначенная только для чтения. Информация заносится в нее один раз (обычно в заводских условиях) и сохраняется постоянно (при включенном и выключенном компьютере). В ПЗУ хранится информация, присутствие которой постоянно необходимо в компьютере. В ПЗУ находятся:
тестовые программы, проверяющие при каждом включении компьютера правильность работы его блоков;
программы для управления основными периферийными устройствами -дисководом, монитором, клавиатурой;
информация о том, где на диске расположена операционная система.
Основная память состоит из регистров. Регистр - это устройство для временного запоминания информации в оцифрованной (двоичной) форме. Запоминающим элементом в регистре является триггер - устройство, которое может находиться в одном из двух состояний, одно из которых соответствует запоминанию двоичного нуля, другое - запоминанию двоичной единицы. Триггер представляет собой крошечный конденсатор-батарейку, которую можно заряжать множество раз. Если такой конденсатор заряжен - он как бы запомнил значение "1", если заряд отсутствует - значение "0". Регистр содержит несколько связанных друг с другом триггеров. Число триггеров в регистре называется разрядностью компьютера. Производительность компьютера напрямую связана с разрядностью, которая бывает равной 8, 16, 32, 64, 128.
Основная память представляет собой единственный вид памяти, к которой ЦП может обращаться непосредственно. Основную память образуют запоминающие устройства с произвольным доступом. Каждая ячейка имеет уникальный адрес, позволяющий различать ячейки при обращении к ним для выполнения операций записи и считывания. Основная память может включать в себя два типа устройств: оперативные запоминающие устройства (ОЗУ) и постоянные запоминающие устройства (ПЗУ).
Преимущественную долю основной памяти образует ОЗУ, называемое оперативным, потому что оно допускает как запись, так и считывание информации, причем обе операции выполняются однотипно, практически с одной и той же скоростью. В англоязычной литературе ОЗУ соответствует аббревиатура RAM - Random Access Memory. Для большинства типов полупроводниковых ОЗУ характерна энергозависимость: даже при кратковременном прерывании питания хранимая информация теряется. Микросхема ОЗУ должна быть постоянно подключена к источнику питания и поэтому может использоваться только как временная память. Вторую группу полупроводниковых ЗУ основной памяти образуют энергонезависимые микросхемы ПЗУ (ROM - Read-Only Меmоrу). ПЗУ обеспечивает считывание информации, но не допускает ее изменения (в ряде случаев информация в ПЗУ может быть изменена, но этот процесс сильно отличается от считывания и требует значительно большего времени). Энергозависимые ОЗУ можно подразделить на две основные подгруппы: динамическую память (DRAM - Dynamic Rаndоm Access Меmory) и статическую память (SRAM - Static Rаndоm Access Меmory). В статических ОЗУ запоминающий элемент может хранить записанную информацию неограниченно долго (при наличии питающего напряжения). Запоминающий элемент динамического ОЗУ способен хранить информацию только в течение достаточно короткого промежутка времени, после которого информацию нужно восстанавливать заново, иначе она будет потеряна. Динамические ЗУ, как и статические, энергозависимы. Роль запоминающего элемента в статическом ОЗУ исполняет триггер. Taкой триггер представляет собой схему с двумя устойчивыми состояниями, обычно состоящую из четырех или шести транзисторов(см. рисунок ниже)
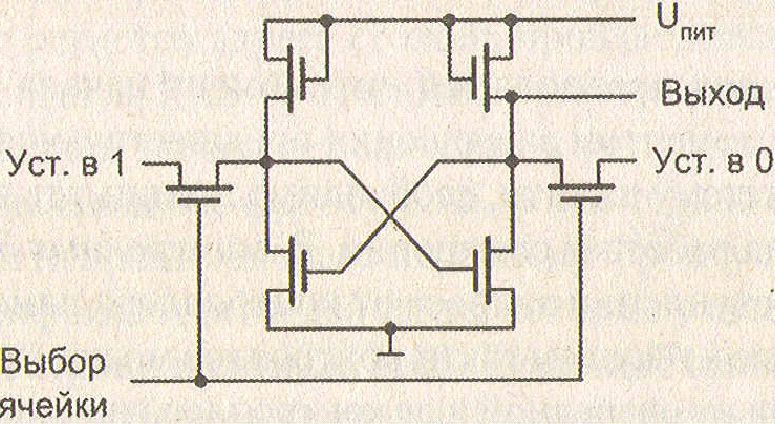
Схема элемента статического ЗУ
Запоминающий элемент (ЗЭ) динамической памяти значительно проще. Он состоит из одного конденсатора и запирающего транзистора (см. рисунок ниже). Простота схемы позволяет достичь высокой плотности размещения, в итоге, снизить стоимость. Главный недостаток подобной технологии связан с тем, что накапливаемый на конденсаторе заряд со временем теряется. Среднее время утечки заряда ЗЭ динамической памяти составляет сотни или даже десятки миллисекунд, поэтому, заряд необходимо успеть восстановить в течение данного отрезка времени, иначе информация будет утеряна. Периодическое восстановление заряда ЗЭ называется регенерацией и осуществляется каждые 2-10 мс.
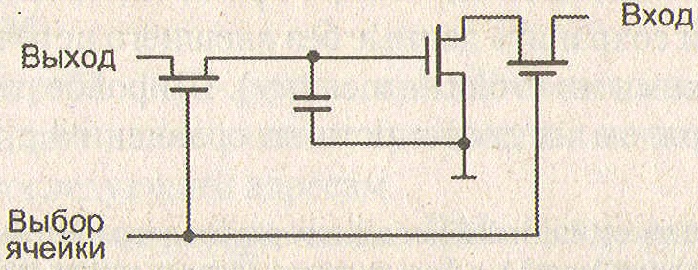
Схема элемента динамического ЗУ
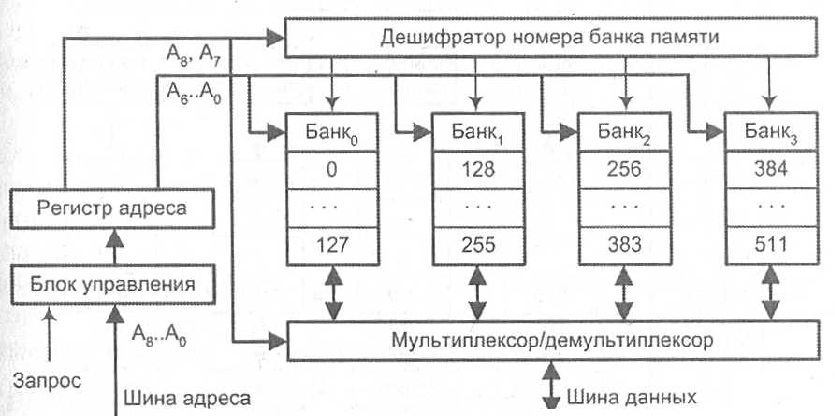
Адресное пространство памяти разбито на группы последовательных адресов. Каждая такая группа обеспечивается отдельным банком памяти. Для обращения используется 9-разрядный адрес, семь младших разрядов которого (А6 - А0) поступают параллельно на все банки памяти и выбирают в каждом из них одну ячейку. Два старших разряда адреса (А8, А7) содержат номер банка. Выбор банка обеспечивается либо с помощью дешифратора номера банка памяти, либо путем мультиплексирования информации (см. рисунок ниже, иллюстрирует оба варианта). В функциональном отношении такая ОП может рассматриваться как единое ЗУ, емкость которого равна суммарной емкости отдельных банков, а быстродействие - быстродействию отдельного банка.
Блок управления памятью или устройство управления памятью (англ. memory management unit, MMU) — компонент аппаратного обеспечения компьютера, отвечающий за управление доступом к памяти, запрашиваемым центральным процессором. Его функции заключаются в трансляции адресов виртуальной памяти в адреса физической памяти (то есть управление виртуальной памятью), защите памяти, управлении кеш-памятью, арбитражем шины и, в более простых компьютерных архитектурах (особенно 8-битных), переключением блоков памяти. Иногда также упоминается как блок управления страничной памятью (англ. Paged memory management unit, PMMU)
В настоящее время, чаще всего, упоминается в связи с организацией т. н. виртуальной памяти и, следовательно, критически важен для многих современных многозадачных операционных систем, включая все современные Windows NT и многие из UNIX‐подобных. Специальная редакция ядра Linux, μClinux, может работать без MMU.
Блок управления памятью в настоящее время очень часто включается в состав центрального процессора или чипсета компьютера.
Принцип работы современных MMU основан на разделении виртуального адресного пространства (одномерного массива адресов, используемых центральным процессором) на участки одинакового, как правило несколько килобайт, хотя, возможно, и существенно большего, размера равного степени 2, называемые страницами. Младшие n бит адреса (смещение внутри страницы) остаются неизменными. Старшие биты адреса представляют собой номер (виртуальной) страницы. MMU обычно преобразует номера виртуальных страниц в номера физических страниц используя буфер ассоциативной трансляции (англ. Translation Lookaside Buffer, TLB). Если преобразование при помощи TLB невозможно, включается более медленный механизм преобразования, основанный на специфическом аппаратном обеспечении или на программных системных структурах. Данные в этих структурах как правило называются элементами таблицы страниц (англ. page table entries (PTE)), а сами структуры — таблицами страниц (англ. page table, PT). Конкатенация номера физической страницы со смещением внутри страницы дает физический адрес.
Элементы PTE или TLB могут также содержать дополнительную информацию: бит признака записи в страницу (англ. dirty bit), время последнего доступа к странице (англ. accessed bit, для реализации алгоритма замещения страниц наиболее давно использованный (англ. least recently used, LRU), какие процессы (пользовательские (англ. user mode) или системные (англ. supervisor mode)) могут читать или записывать данные в страницу, необходимо ли кэшировать страницу.
Разработчикам программного обеспечения часто приходится решать проблему размещения в памяти больших программ, размер которых превышает объем доступной оперативной памяти. Один из вариантов решения данной проблемы – организация структур с перекрытием – рассмотрен в предыдущей лекции. При этом предполагалось активное участие программиста в процессе формирования перекрывающихся частей программы. Развитие архитектуры компьютеров и расширение возможностей операционной системы по управлению памятью позволило переложить решение этой задачи на компьютер. Одним из главных достижений стало появление виртуальной памяти (virtual memory). Впервые она была реализована в 1959 г. на компьютере "Атлас", разработанном в Манчестерском университете.
Суть концепции виртуальной памяти заключается в следующем. Информация, с которой работает активный процесс, должна располагаться в оперативной памяти. В схемах виртуальной памяти у процесса создается иллюзия того, что вся необходимая ему информация имеется в основной памяти. Для этого, во-первых, занимаемая процессом память разбивается на несколько частей, например страниц. Во-вторых, логический адрес (логическая страница), к которому обращается процесс, динамически транслируется в физический адрес (физическую страницу). И, наконец, в тех случаях, когда страница, к которой обращается процесс, не находится в физической памяти, нужно организовать ее подкачку с диска. Для контроля наличия страницы в памяти вводится специальный бит присутствия, входящий в состав атрибутов страницы в таблице страниц .
Таким образом, в наличии всех компонентов процесса в основной памяти необходимости нет. Важным следствием такой организации является то, что размер памяти, занимаемой процессом, может быть больше, чем размер оперативной памяти. Принцип локальности обеспечивает этой схеме нужную эффективность.
Возможность выполнения программы, находящейся в памяти лишь частично, имеет ряд вполне очевидных преимуществ.
Программа не ограничена объемом физической памяти. Упрощается разработка программ, поскольку можно задействовать большие виртуальные пространства, не заботясь о размере используемой памяти.
Поскольку появляется возможность частичного помещения программы (процесса) в память и гибкого перераспределения памяти между программами, можно разместить в памяти больше программ, что увеличивает загрузку процессора и пропускную способность системы.
Объем ввода-вывода для выгрузки части программы на диск может быть меньше, чем в варианте классического свопинга, в итоге каждая программа будет работать быстрее.
Таким образом, возможность обеспечения (при поддержке операционной системы) для программы "видимости" практически неограниченной (характерный размер для 32-разрядных архитектур 232 = 4 Гбайт) адресуемой пользовательской памяти (логическое адресное пространство) при наличии основной памяти существенно меньших размеров (физическое адресное пространство) – очень важный аспект.
Но введение виртуальной памяти позволяет решать другую, не менее важную задачу – обеспечение контроля доступа к отдельным сегментам памяти и, в частности, защиту пользовательских программ друг от друга и защиту ОС от пользовательских программ. Каждый процесс работает со своими виртуальными адресами, трансляцию которых в физические выполняет аппаратура компьютера. Таким образом, пользовательский процесс лишен возможности напрямую обратиться к страницам основной памяти, занятым информацией, относящейся к другим процессам.
Например, 16-разрядный компьютер PDP-11/70 с 64 Кбайт логической памяти мог иметь до 2 Мбайт оперативной памяти. Операционная система этого компьютера тем не менее поддерживала виртуальную память, которая обеспечивала защиту и перераспределение основной памяти между пользовательскими процессами.
Напомним, что в системах с виртуальной памятью те адреса, которые генерирует программа (логические адреса), называются виртуальными, и они формируют виртуальное адресное пространство. Термин " виртуальная память " означает, что программист имеет дело с памятью, отличной от реальной, размер которой потенциально больше, чем размер оперативной памяти.
Хотя известны и чисто программные реализации виртуальной памяти, это направление получило наиболее широкое развитие после соответствующей аппаратной поддержки.
Следует отметить, что оборудование компьютера принимает участие в трансляции адреса практически во всех схемах управления памятью. Но в случае виртуальной памяти это становится более сложным вследствие разрывности отображения и многомерности логического адресного пространства. Может быть, наиболее существенным вкладом аппаратуры в реализацию описываемой схемы является автоматическая генерация исключительных ситуаций при отсутствии в памяти нужных страниц (page fault).
Любая из трех ранее рассмотренных схем управления памятью – страничной, сегментной и сегментно-страничной – пригодна для организации виртуальной памяти. Чаще всего используется cегментно-страничная модель, которая является синтезом страничной модели и идеи сегментации. Причем для тех архитектур, в которых сегменты не поддерживаются аппаратно, их реализация – задача архитектурно-независимого компонента менеджера памяти.
Сегментная организация в чистом виде встречается редко.
Компьютер обменивается информацией с внешним миром с помощью периферийных устройств. Только благодаря периферийным устройствам человек может взаимодействовать с компьютером, а также со всеми подключенными к нему устройствами. Любое подключенное периферийное устройство в каждый момент времени может быть или занято выполнением порученной ему работы или пребывать в ожидании нового задания. Влияние скорости работы периферийных устройств на эффективность работы с компьютером не меньше, чем скорость работы его центрального процессора. Скорость работы внешних устройств от быстродействия процессора не зависит. Наиболее распространенные периферийные устройства приведены на рисунке:

Периферийные устройства делятся на устройства ввода и устройства вывода. Устройства ввода преобразуют информацию в форму понятную машине, после чего компьютер может ее обрабатывать и запоминать. Устройства вывода переводят информацию из машинного представления в образы, понятные человеку.
Ниже приведена классификация устройств ввода:

Самым известным устройством ввода информации является клавиатура (keyboard) – это стандартное устройство, предназначенное для ручного ввода информации. Работой клавиатуры управляет контроллер клавиатуры, расположенный на материнской плате и подключаемый к ней через разъем на задней панели компьютера. При нажатии пользователем клавиши на клавиатуре, контроллер клавиатуры преобразует код нажатой клавиши в соответствующую последовательность битов и передает их компьютеру. Отображение символов, набранных на клавиатуре, на экране компьютера называется эхом. Обычная современная клавиатура имеет, как правило, 101-104 клавиши, среди которых выделяют алфавитно-цифровые клавиши, необходимые для ввода текста, клавиши управления курсором и ряд специальных и управляющих клавиш. Существуют беспроводные модели клавиатуры, в них связь клавиатуры с компьютером осуществляется посредством инфракрасных лучей.
Наиболее важными характеристиками клавиатуры являются чувствительность ее клавиш к нажатию, мягкость хода клавиш и расстояние между клавишами. На долговечность клавиатуры определяется количеством нажатий, которые она рассчитана выдержать. Клавиатура проектируется таким образом, чтобы каждая клавиша выдерживала 30-50 миллионов нажатий.
К манипуляторам относят устройства, преобразующие движения руки пользователя в управляющую информацию для компьютера. Среди манипуляторов выделяют мыши, трекболы, джойстики.
Мышь предназначена для выбора и перемещения графических объектов экрана монитора компьютера. Для этого используется указатель, перемещением которого по экрану управляет мышь. Мышь позволяет существенно сократить работу человека с клавиатурой при управлении курсором и вводе команд. Особенно эффективно мышь используется при работе графическими редакторами, издательскими системами, играми. Современные операционные системы также активно используют мышь для управляющих команд.
У мыши могут быть одна, две или три клавиши. Между двумя крайними клавишами современных мышей часто располагают скрол. Это дополнительное устройство в виде колесика, которое позволяет осуществлять прокрутку документов вверх-вниз и другие дополнительные функции.
Мышь состоит из пластикового корпуса, cверху находятся кнопки, соединенные с микропереключателями. Внутри корпуса находится обрезиненный металлический шарик, нижняя часть которого соприкасается с поверхностью стола или специального коврика для мыши, который увеличивает сцепление шарика с поверхностью. При движении манипулятора шарик вращается и переедает движение на соединенные с ним датчики продольного и поперечного перемещения. Датчики преобразуют движения шарика в соответствующие импульсы, которые передаются по проводам мыши в системный блок на управляющий контроллер. Контроллер передает обработанные сигналы операционной системе, которая перемещает графический указатель по экрану. В беспроводной мыши данные передаются с помощью инфракрасных лучей. Существуют оптические мыши, в них функции датчика движения выполняют приемники лазерных лучей, отраженных от поверхности стола.
Трекбол по функциям близок мыши, но шарик в нем больших размеров, и перемещение указателя осуществляется вращением этого шарика руками. Трекбол удобен тем, что его не требуется перемещать по поверхности стола, которого может не быть в наличии. Поэтому, по сравнению с мышью, он занимает на столе меньше места. Большинство переносных компьютеров оснащаются встроенным трекболом.
Джойстик представляет собой основание с подвижной рукояткой, которая может наклоняться в продольном и поперечном направлениях. Рукоятка и основание снабжаются кнопками. Внутри джойстика расположены датчики, преобразующие угол и направление наклона рукоятки в соответствующие сигналы, передаваемые операционной системе. В соответствии с этими сигналами осуществляется перемещение и управление графических объектов на экране.
Дигитайзер – это устройство для ввода графических данных, таких как чертежи, схемы, планы и т. п. Он состоит из планшета, соединенного с ним визира или специального карандаша. Перемещая карандаш по планшету, пользователь рисует изображение, которое выводится на экран.
Сканер – устройство ввода графических изображений в компьютер. В сканер закладывается лист бумаги с изображением. Устройство считывает его и пересылает компьютеру в цифровом виде. Во время сканирования вдоль листа с изображением плавно перемещается мощная лампа и линейка с множеством расположенных на ней в ряд светочувствительных элементов. Обычно в качестве светочувствительных элементов используют фотодиоды. Каждый светочувствительный элемент вырабатывает сигнал, пропорциональный яркости отраженного света от участка бумаги, расположенного напротив него. Яркость отраженного луча меняется из-за того, что светлые места сканируемого изображения отражают гораздо лучше, чем темные, покрытые краской. В цветных сканерах расположено три группы светочувствительных элементов, обрабатывающих соответственно красные, зеленые и синие цвета. Таким образом, каждая точка изображения кодируется как сочетание сигналов, вырабатываемых светочувствительными элементами красной, зеленой и синей групп. Закодированный таким образом сигнал передается на контроллер сканера в системный блок.
Различают сканеры ручные, протягивающие и планшетные. В ручных сканерах пользователь сам ведет сканер по поверхности изображения или текста. Протягивающие сканеры предназначены для сканирования изображений на листах только определенного формата. Протягивающее устройство таких сканеров последовательно перемещает все участки сканируемого листа над неподвижной светочувствительной матрицей. Наибольшее распространение получили планшетные сканеры, которые позволяют сканировать листы бусмги, книги и другие объекты, содержащие изображения. Такие сканеры состоят из пластикового корпуса, закрываемого крышкой. Верхняя поверхность корпуса выполняется из оптически прозрачного материала, на который кладется сканируемое изображение. После этого изображение закрывается крышкой и производится сканирование. В процессе сканирования под стеклом перемещается лампа со светочувствительной матрицей.
Главные характеристики сканеров - это скорость считывания, которая выражается количеством сканируемых станиц в минуту (pages per minute - ppm), и разрешающая способность, выражаемая числом точек получаемого изображения на дюйм оригинала (dots per inch - dpi).
После ввода пользователем исходных данных компьютер должен их обработать в соответствии с заданной программой и вывести результаты в форме, удобной для восприятия пользователем или для использования другими автоматическими устройствам посредством устройств вывода.
Выводимая информация может отображаться в графическом виде, для этого используются мониторы, принтеры или плоттеры. Информация может также воспроизводиться в виде звуков с помощьюакустических колонок или головных телефонов, регистрироваться в виде тактильных ощущений в технологии виртуальной реальности, распространяться в виде управляющих сигналов устройства автоматики, передаваться в виде электрических сигналов по сети.
Монитор (дисплей) является основным устройством вывода графической информации. По размеру диагонали экрана выделяют мониторы 14-дюймовые, 15-дюймовые, 17-дюймовые, 19-дюймовые, 21-дюймовые. Чем больше диагональ монитора, тем он дороже. По цветности мониторы бывают монохромные и цветные. Любое изображение на экране монитора образуется из светящихся разными цветами точек, называемых пикселями (это название происходит от PICture CELL - элемент картинки). Пиксель – это самый мелкий элемент, который может быть отображен на экране. Чем качественнее монитор, тем меньше размер пикселей, тем четче и контрастнее изображение, тем легче прочесть самый мелкий текст, а значит, и меньше напряжение глаз. По принципу действия мониторы подразделяются на мониторы с электронно-лучевой трубкой (Catode Ray Tube - CRT) и жидкокристаллические - (Liquid Crystal Display - LCD).
В мониторах с электронно-лучевой трубкой изображение формируется с помощью зерен люминофора – вещества, которое светится под воздействием электронного луча. Различают три типа люминофоров в соответствии с цветами их свечения: красный, зеленый и синий. Цвет каждой точки экрана определяется смешением свечения трех разноцветных точек (триады), отвечающих за данный пиксель. Яркость соответствующего цвета меняется в зависимости от мощности электронного пучка, попавшего в соответствующую точку. Электронный пучок формируется с помощью электронной пушки. Электронная пушка состоит из нагреваемого при прохождении электрического тока проводника с высоким удельным электрическим сопротивлением, эмитирующего электроны покрытия, фокусирующей и отклоняющей системы.
При прохождении электрического тока через нагревательный элемент электронной пушки, эмитирующее покрытие, нагреваясь, начинает испускать электроны. Под действием ускоряющего напряжения электроны разгоняются и достигают поверхности экрана, покрытой люминофором, который начинает светиться. Управление пучком электронов осуществляется отклоняющей и фокусирующей системой, которые состоят из набора катушек и пластин, воздействующих на электронный пучек с помощью магнитного и электрического полей. В соответствии с сигналами развертки, подаваемыми на электронную пушку, электронный луч побегает по каждой строчке экрана, последовательно высвечивая соответствующие точки люминофора. Дойдя до последней точки, луч возвращается к началу экрана. Таким образом, в течение определенного периода времени изображение перерисовывается. Частоту смены изображений определяет частота горизонтальной синхронизации. Это один из наиболее важных параметров монитора, определяющих степень его вредного воздействия на глаза. В настоящее время гигиенически допустимый минимум частоты горизонтальной синхронизации составляет 80 Гц, у профессиональных мониторов она составляет 150 Гц.
Современные мониторы с электронно-лучевой трубкой имеют специальное антибликовое покрытие, уменьшающее отраженный свет окон и осветительных приборов. Кроме того, монитор покрывают антистатическим покрытием и пленкой, защищающей от электромагнитного излучения. Дополнительно на монитор можно установить защитный экран, который необходимо подсоединить к заземляющему проводу, что также защитит от электромагнитного излучения и бликов. Уровни излучения мониторов нормируются в соответствии со стандартами LR, MPR и MPR-II.
Жидкокристаллические мониторы имеют меньшие размеры, потребляют меньше электроэнергии, обеспечивают более четкое статическое изображение. В них отсутствуют типичные для мониторов с электронно-лучевой трубкой искажения. Принцип отображения на жидкокристаллических мониторах основан на поляризации света. Источником излучения здесь служат лампы подсветки, расположенные по краям жидкокристаллической матрицы. Свет от источника света однородным потоком проходит через слой жидких кристаллов. В зависимости от того, в каком состоянии находится кристалл, проходящий луч света либо поляризуется, либо не поляризуется. Далее свет проходит через специальное покрытие, которое пропускает свет только определенной поляризации. Там же происходит окраска лучей в нужную цветовую палитру. Жидкокристаллические мониторы практически не производят вредного для человека излучения.
Для получения копий изображения на бумаге применяют принтеры, которые классифицируются:
по способу получения изображения: литерные, матричные, струйные, лазерные и термические;
по способу формирования изображения: последовательные, строчные, страничные;
по способу печати: ударные, безударные;
по цветности: чёрно-белые, цветные.
Наиболее распространены принтеры матричные, лазерные и струйные принтеры. Матричные принтеры схожи по принципу действия с печатной машинкой. Печатающая головка перемещается в поперечном направлении и формирует изображение из множества точек, ударяя иголками по красящей ленте. Красящая лента перемещается через печатающую головку с помощью микроэлектродвигателя. Соответствующие точки в месте удара иголок отпечатываются на бумаге, расположенной под красящей лентой. Бумага перемещается в продольном направлении после формирования каждой строчки изображения. Полиграфическое качество изображения, получаемого с помощью матричных принтеров низкое и они шумны во время работы. Основное достоинство матричных принтеров - низкая цена расходных материалов и невысокие требования к качеству бумаги.
Струйный принтер относится к безударным принтерам. Изображение в нем формируется с помощью чернил, которые распыляются через капилляры печатающей головки.
Лазерный принтер также относится к безударным принтерам. Он формирует изображение постранично. Первоначально изображение создается на фотобарабане, который предварительно электризуется статическим электричеством. Луч лазера в соответствии с изображением снимает статический заряд на белых участках рисунка. Затем на барабан наносится специальное красящее вещество – тонер, который прилипает к фотобарабану на участках с неснятым статическим зарядом. Затем тонер переносится на бумагу и нагревается. Частицы тонера плавятся и прилипают к бумаге.
Для ускорения работы, принтеры имеют собственную память, в которой они хранят образ информации, подготовленной к печати.
К основным характеристикам принтеров можно относятся:
- ширина каретки, которая обычно соответствую бумажному формату А3 или А4;
- скорость печати, измеряемая количеством листов, печатаемы в минуту
- качество печати, определяемое разрешающей способностью принтера - количеством точек на дюйм линейного изображения. Чем разрешение выше, тем лучше качество печати.
- расход материалов: лазерным принтером - порошка, струйным принтером - чернил, матричным принтером - красящих лент.
Плоттер (графопостроитель) – это устройство для отображения векторных изображений на бумаге, кальке, пленке и других подобных материалах. Плоттеры снабжаются сменными пишущими узлами, которые могут перемещаться вдоль бумаги в продольном и поперечном направлениях. В пишущий узел могут вставляться цветные перья или ножи для резки бумаги. Графопостроители могут быть миниатюрными, и могут быть настолько большими, что на них можно вычертить кузов автомобиля или деталь самолета в натуральную величину.
Компьютерная ши́на (от англ. computer bus, bidirectional universal switch — двунаправленный универсальный коммутатор) — в архитектуре компьютера подсистема, которая передаёт данные между функциональными блоками компьютера. Обычно шина управляется драйвером. В отличие от связи точка-точка, к шине можно подключить несколько устройств по одному набору проводников. Каждая шина определяет свой набор коннекторов (соединений) для физического подключения устройств, карт и кабелей.
Ранние компьютерные шины представляли собой параллельные электрические шины с несколькими подключениями, но сейчас данный термин используется для любых физических механизмов, предоставляющих такую же логическую функциональность, как параллельные компьютерные шины. Современные компьютерные шины используют как параллельные, так и последовательные соединения и могут иметь параллельные (multidrop) и цепные (daisy chain) топологии. В случае USB и некоторых других шин могут также использоваться хабы (концентраторы).
FSB
Front Side Bus (FSB) — это магистральный канал, обеспечивающий соединение процессора и внутренних устройств: памяти, видеокарты, устройств хранения информации и т. п.
Наиболее часто можно встретить систему организации внешнего интерфейса процессора, которая предполагает, что параллельная мультиплексированная процессорная шина, носящая название FSB, соединяет процессор (порой два процессора, четыре или даже больше) и системный контроллер, который обеспечивает доступ к оперативной памяти и внешним устройствам. Этот системный контроллер обычно называется «северным мостом» (от англ. Northbridge). Он, наряду с «южным мостом» (от англ. Southbridge), входит в состав набора системной логики, который, однако, чаще фигурирует под названием «чипсет» (от англ. Chipset).
Northbridge
Северный мост начал именоваться именно так из-за своего расположения на материнской плате. Он представляет собой микрочип, визуально расположенный «под» процессором, однако в верхней части материнской платы, как бы в «северной» ее части.
Системный контроллер служит для передачи команд центрального процессора к оперативной памяти, и видеоконтроллеру (в случае встроенного видеоконтроллера, северный мост, производимый компанией Intel, именуется GMCH (от англ. Chipset Graphics and Memory Controller Hub), а также конвертацию этих команд в форму, необходимую для обращения к оперативной памяти. Порой, для увеличения потенциальной производительности системы, к северному мосту подключаются наиболее производительные периферийные устройства, например, видеокарты с шиной PCI Express, а менее производительные устройства (BIOS, устройства PCI, интерфейсы устройств хранения информации, ввода и т. п.) могут подключаться к так называемому южному мосту. Северный мост соединен с материнской платой посредством согласующего интерфейса, также контроллер соединяется шиной и с южным мостом.
Северным мостом определяются параметры (пропускная способность, частота, а также тип): системной шины, оперативной памяти (тип используемой памяти, а также ее максимальный объем), подключенного видеоконтроллера (режим работы, возможность использования SLI (от англ. Scalable Link Interface, что означает «масштабируемый интерфейс» и фактически означает возможность работы 2 (3 — 3-Way SLI, или даже 4 — Quad SLI) видеоадаптеров одновременно, что чрезвычайно повышает производительность видео).
В настоящее время в процессорах серии Core i-x с разъемом LGA 1156 северный мост встроен в процессор и связывается с ядрами по внутренней шине QPI со скоростью соединения 2.5^109 операций в секунду. Из факта поглощения процессором северного моста вытекает неактуальность использования шины FSB и внешней шины QPI в подобных системах.
Southbridge
Еще одним компонентом чипсета является функциональный контроллер ввода-вывода (от англ. I/O Controller Hub, ICH), так называемый южный мост, служащий для связи центрального процессора (через северный мост) с устройствами, не столь критичными к скорости взаимодействия:
Контроллеры PCI (X, E), прерываний, SMBus (I2C), LPC, IDE/SATA DMA, IRQ, ISA;
Super I/O: контроллер floppy-дисководов; контроллер LPT-порта; Контроллер COM-портов; MIDI, джойстик, инфракрасный порт и т.п.
Часы реального времени RTC (от англ. Real Time Clock);
BIOS (CMOS), вместе с энергонезависимыми системами обеспечения;
Системы энергообеспечения APM и ACPI;
Звуковой контроллер (AC97);
Может включать в себя контроллеры Ethernet, USB, RAID, FireWire и т. п.
Особенностью южного моста является его взаимодействие с внешними устройствами. Как следствие, он довольно чувствителен различным негативным факторам, влияющим на нормальную работу устройств (короткое замыкание, перегрев, деформация материнской платы и т. п.). Замена южного моста, как правило, составляет стоимость самой материнской платы, поэтому замена его нерациональна из-за ее высокой стоимости и обычно не проводится.
BSB
Шина BSB (от англ. Back Side Bus) служит для соединения центрального процессора с кэш-памятью второго уровня для процессоров, в которых используется двойная независимая шина DIB (от англ. Dual Independent Bus), которая также называется вторичным (или внешним) КЭШем (и носит обозначение L2-cache).
QPB
Компанией Intel была разработана системная шина QPB (от англ. Quad Pumped Bus), передающая 4 64-разрядных блока данных или 2 адреса за такт, тогда как пытавшаяся получить лицензию на системную шину GTL+ для создания своих новых процессоров, компания AMD вынуждена была при создании процессоров серии К7 лицензировать шину EV6 для процессоров AMD Athlon и Athlon XP передающую данные два раза за такт (Double Data Rate).
Данная шина оказалась значительно сложнее в производстве, чем предыдущие исполнения. Данное обстоятельство не могло не сказаться на серьезном увеличении количества транзисторов, используемых для реализации вышеуказанного принципа передачи данных, как для процессора, так и для самого чипсета.
DMI
DMI (от англ. Direct Media Interface) – шина, которая была разработана компанией Intel, для соединения южного и северного мостов материнской платы. Для разъема LGA 1156 со встроенным контроллером памяти (продукты Core i3, Core i5 и некоторые серии Core i7 (800, к примеру)), DMI соединяет процессор и чипсет PCH (от англ. Platform Controller Hub) по технологии CtC (от англ. Chip-to-Chip).
PCH является, по сути, аналогом южного моста, однако представляет из себя совершенно новый P55 Ibex Peak. Фактически, в новом решении сочетается расширенный функционал предыдущих версий южных мостов компании Intel, а также дополнительный контроллер PCI-e для периферии.
Первыми чипсетами, построенными с помощью технологии DMI, были устройства серии Intel i915, на основе сокета LGA 1156, получившие свое распространение с 2004 года.
Пропускная способность DMI составляет 2 Гбайт/с. Из-за столь невысоких значений, инженеры Intel пошли на революционное решение, встроив контроллер памяти, PCI-e и непосредственно интерфейс DMI в сам процессор.
HyperTransport
HyperTransport (ранее известная, как Lightning Data Transport) – технология последовательной/параллельной связи, разработанная с использованием технологии P2P (от англ. «point-to-point»), которая обеспечивает достаточно высокую скорость при низком уровне латентности (от англ. Low-latency responses), которая обеспечивает межпроцессорную связь, связь процессоров с сопроцессорами и процессоры с I/O Controller Hub. Имеет оригинальную схему на основе соединений, тоннелей, последовательного объединения нескольких тоннелей в цепь и мостов (для организации маршрутизации пакетов между цепями) для более простого масштабирования всей системы.
HyperTransport оптимизирует внутрисистемные связи заменой шин и мостов на их физическом уровне. Также тут используется DDR (от англ. Double Data Rate), что позволяет производить до 5.2x109 посылок в секунду с частотой синхронизации сигнала на уровне 2.6 гигагерц.
Версии HyperTransport:
|
QPI
Очередной шаг в совершенствовании научно-технического процесса был обозначен инженерами компании Intel созданием нового типа системной шины QPI (от англ. Quick Path Interconnect, ранее известной, как Common-System Interface, или CSI). Она заключается в интегрированном контроллере памяти и быстрой последовательной шины P2P для доступа к распределенной и разделяемой памяти.
Необходимость повышения скорости обработки и обмена данными диктует более жесткие требования к пропускной способности шины. С развитием технологии и характеристик процессоров нового поколения, использование FSB уже неактуально и в полной мере является наглядным изображением пресловутого эффекта «бутылочного горлышка». Результатом модернизации технологии FSB было создание шины нового поколения – QPI. Общая пропускная способность данного нового вида системной шины достигает невероятных (для предшественников) значений в 25.6 ГБ/с.
Первые процессоры, построенные на технологии использования системной шины QPI, поступили на рынок в начале 2008 года. Данная технология является прямым конкурентом консорциума, во главе с компанией AMD, выпустившей системную шину HyperTransport.
Название микроструктуры процессорного ряда компании Intel - Nehalem произошло от названия небольшого города в США неподалеку от головного офиса компании Intel в г. Санта-Клара (основанного в 18 веке) в Калифорнии. Nehalem является продолжением процесса модернизации модельного ряда архитектур Intel x86. Свое продолжение в 2010 году QPI получила в процессоре серии Itanium 9300, получив кодовое имя Tukwila, что является большим шагом вперед для систем, построенных на базе Itanium. Вместе с QuickPath в процессоре используется встроенный контроллер памяти, и интерфейс памяти прямо использует интерфейс QPI для взаимодействия с другими процессорами и I/OCH. Именно в этих продуктах наиболее типичным решением и стала системная шина QPI, что делает вероятной возможность использования одного чипсета процессорами Tukwila и Nehalem.
Каждое ядро процессора содержит интегрированный контроллер памяти и скоростное соединение для подключения иных компонентов. Данная структура служит для обеспечения следующих аспектов:
Огромной производительности и удобства работы с памятью;
Динамически изменяемой полосы эффективного пропускания при связи процессора с иными компонентами системы;
Значительного увеличения характеристик RAS (от англ. Reliability, Availability, Serviceability, что дословно означает «надежность, доступность и обслуживаемость») - достигается для достижения наилучшего баланса между ценой, производительностью и энергоэффективностью.
Чипсеты с разъемом LGA 1366 используют шину DMI для связи между северным мостом и южным мостом. А процессоры для сокета LGA 1156 вообще не имеют внешнего интерфейса QuickPath, т.к. чипсеты для данного сокета взаимодействуют с однопроцессорными конфигурациями, а функционал северного моста же напрямую встроен в сам процессор, что заставляет использовать шину DMI для связи процессора с аналогом южного моста. Однако, встроенная шина QPI используется в процессорах сокета LGA 1156 для связи ядер и встроенного контроллера PCI-e внутри самого процессора.
Данные, передаваемые в виде датаграмм (пакетов) в системной шине QPI передаются по паре односторонних каналов, каждый из которых состоит из 20 пар проводов. Общая ширина канала составляет 20 бит, при этом 16 бит служат для передачи исключительно данных (полезной нагрузки). Максимальная пропускная способность одного канала варьируется от 4.8^109 до 6.4^109 транзакций в секунду, следовательно, общая максимальная пропускная способность одного соединения приближается к значениям от 19.2 до 25.6 ГБ/с в двух направлениях, что составляет, соответственно, от 9.6 до 12.8 ГБ/с в каждую сторону.
В настоящее время системную шину QPI используют, в основном, для серверных решений. Связано это обстоятельство с тем, что QPI приобретает максимальную эффективность (и КПД) именно в загруженности пересылкой данных в оба направления, как в случае с многосокетными рабочими станциями или, собственно, серверами.
Как показывают тесты, для пользовательских машин использовать решения на основе QPI нецелесообразно, так как даже намеренное снижение пропускной способности QPI в 2 раза никоим образом не влияет на получаемые результаты в тестах, даже при условии использования связки из 3 наиболее производительных графических адаптеров.
PCI
PCI (от англ. Peripheral Component Interconnect bus) – шина для соединения материнской платы с периферийными устройствами различного рода.
Начало PCI было положено в начале 1992 года компанией Intel (для замены шины VLB (от англ. Vesa Local Bus)), которая допустила полноценное использование возможностей процессоров 486, Pentium и Pentium Pro, при этом стандарт шины с самого начала был открыт, что гарантировало возможность создания устройств для шины PCI без обязательства лицензирования.
В 1993 году в ходе маркетинговой политики по продвижению PCI на рынке вышла PCI 2.0. В 1995 году данная модель модифицировалась до версии PCI 2.1.
PCI имела реальную тактовую частоту на уровне 33 МГц, тактовой частотой для версии 2.1 стало значение в 66 МГц, что позволило повысить скорость передачи данных до 533 Мбайт/с. Вместе с тем, и в операционных системах (Windows 95, к примеру) уже была предусмотрена поддержка шины PCI 2.1, которая стала настолько популярной, что вскоре была использована при создании платформ процессоров Alpha, MIPS, PowerPC, SPARC и т.д.
Однако, ничего не стоит на месте, включая научно-технический процесс, поэтому в связи с разработкой шины PCI Express, AGP и PCI практически не используются в решениях высшего ценового диапазона.
PCI Express
PCI Express получила свое кодовое название 3GIO (от англ. 3rd Generation I/O) – компьютерная шина, использующая последовательную передачу данных, обеспечиваемую высокопроизводительным физическим протоколом на основе программной модели шины PCI.
В связи с тем, что использование параллельной передачи данных, при попытке увеличить производительность, будет означать физическое ее расширение, последовательная передача данных обладает возможностью масштабирования (1x, 2x, 4x, 8x, 16x и 32x) а, значит, более приоритетна в разработке. Топология PCI Express, в общем случае, представляет собой звезду со взаимодействием между собой устройств через среду, образованную коммутаторами, с прямой связью каждого устройства соединением P2P.
Очередными отличительными особенностями PCI Express являются:
Возможность горячей замены карт;
Последовательность;
Спецификация;
Возможность создания виртуальных каналов, гарантирования полосы пропускания и количество времени отклика, а также сбора статистики QoS (от англ. Quality of Service)
Возможность влиять на энергопотребление оборудования ASMP (от англ. Active State Power Management) – перевод устройства в режим уменьшенного энергопотребления в случае его простоя в течение конкретного (задаваемого программно) интервала времени;
Контроль целостности информации и структуры данных, предназначенных для передачи – алгоритм Data Link прикрепляет к пакету данных (в передаче) контрольную сумму последовательности и ее номер, что позволяет обнаруживать все одиночные и двойные ошибки, а также ошибки в нечетном числе бит – CRC (от англ. Cyclic Redundancy Check).
В отличие от PCI (использование подключения к общей 32-разрядной параллельной двунаправленной шине), PCI Express использует двунаправленное последовательной соединение P2P, а соединение между двумя устройствами состоит из 1 (2, 4, 8, 16, 32) двунаправленных линий. На электрическом уровне каждое соединение способно подключаться к PCI Express всего лишь 4 проводниками.
Преимущества подобного решения налицо:
Устройство корректно работает в таком же слоте, или большей пропускной способности;
Корректная работа слота возможна даже при использовании не всех линий (однако в таком случае необходимо подключение и заземление всех проводников питания);
Физическая составляющая слота не позволит допустить некорректную работу системы, в случае попытки вставить устройство в слот с меньшей пропускной способностью, дифференциацией размеров слотов x1 (x2, x4, x8, x16, x32).
Чтобы высчитать пропускную способность PCI Express, нужно учесть битрейт, дуплексность связи и процент (отношение) эффективного количества «полезной нагрузки» бит к общему количеству (в PCI Express 1.0 и 2.x это отношение выглядело, как 8 бит информации / 10 бит служебных данных). Перемножая все три значения, получим скорость передачи данных. Так общая пропускная способность шины PCI Express 3.0 достигает 1 Гбайт/с для каждой линии при сигнальной скорости передачи данных в 8 GT/s (для 2.0 этот показатель был равен 5 GT/s, а для 1.0 – вообще 2.5 GT/s). А для планируемого к стандартизации и спецификации к 2014-2015 гг. стандарта 4.0 планируется удвоить показатель сигнальной скорости до 16 GT/s или даже более, что будет, по-меньшей мере, в 2 раза быстрее PCI Express 3.0
В настоящее время развитие технологий дает потребителям возможность выбирать технологию себе по вкусу из огромного количества вариантов. Решение различного рода задач потребителей задает необходимость определяться с наилучшим соотношением «цена-качество-целесообразность». К примеру: обыватель не замечает разницы в производительности между системами, построенных на базе сокета LGA 1366 (используется системная шина QPI) и сокета LGA 1156(1155) (используется системная шина DMI) в силу достаточности технологии, связанной с LGA 1156 и отсутствием задач, для которых ресурс данной системы был бы недостаточен. Лишь настоящие ценители и коллекционеры не откажут себе в радости приобретения компьютера, ресурс которого не будет использован и на 50%. Для потребителей-корпораций и крупных фирм нередко уже недостаточно производительности шины DMI.
Разрыв в разнице задач растет соответственно уровню потребителя. Кто знает, какие технологии используются в суперкомпьютерах мировых держав, однако ясно одно: именно эти технологии мы и будем использовать в ближайшем будущем.
Исполнение команд (базовый цикл исполнения программы, выборка и исполнение программы, выполнения программы без прерываний и с их использованием, циклы команд с использованием прерываний, классы прерываний).
Программа в ЭВМ реализуется центральным процессором (ЦП) посредством последовательного исполнения образующих эту программу команд. Действия, требуемые для выборки (извлечения из основной памяти) и выполнения команды, называют циклом команды. В общем случае цикл команды включает в себя несколько составляющих (этапов):
выборку команды;
формирование адреса следующей команды;
декодирование команды;
вычисление адресов операндов;
выборку операндов;
исполнение операции;
формирование признака результата;
запись результата.
Перечисленные этапы выполнения команды в дальнейшем будем называть стандартным циклом команды. Отметим, что не все из этапов присутствуют при выполнении любой команды (зависит от типа команды), однако этапы выборки, декодирования, формирования адреса следующей команды и исполнения операции имеют место всегда. В определенных ситуациях возможны еще два этапа:
косвенная адресация;
реакция на прерывание.
Стандартный цикл команды Кратко охарактеризуем каждый из вышеперечисленных этапов стандартного цикла команды. При изучении данного материала следует учитывать, что приводимое описание имеет целью лишь дать представление о сущности каждого из этапов. В то же время распределение функций по разным этапам цикла команды и последовательность выполнения некоторых из них в реальных ЭВМ могут отличаться от излагаемых.
Этап выборки команды Цикл любой команды начинается с того, что центральный процессор извлекает команду из памяти, используя адрес, хранящийся в счетчике команд (СК). Двоичный код команды помещается в регистр команды (РК) и с этого момента становится «видимым» для процессора. Если длина команды совпадает с разрядностью ячейки памяти, то все понятно. Однако, система команд многих ЭВМ предполагает несколько форматов команд, причем в разных форматах команда может занимать 1, 2 или более ячеек, а этап выборки команды можно считать завершенным лишь после того, как в РК будет помещен полный код команды. Информация о фактической длине команды содержится в полях кода операции и способа адресации. Обычно эти поля располагают в первом слове кода команды, и для выяснения необходимости продолжения процесса выборки необходимо предварительное декодирование их содержимого. Такое декодирование может быть произведено после того, как первое слово кода команды окажется в РК. В случае многословного формата команды процесс выборки продолжается вплоть до занесения в РК всех слов команды.
Этап формирования адреса следующей команды Для большинства ЭВМ характерно размещение соседних команд программы в смежных ячейках памяти. Если извлеченная команда не нарушает естественного порядка выполнения программы, то для вычисления адреса следующей выполняемой команды достаточно увеличить содержимое счетчика команд на длину текущей команды, представленную количеством занимаемых кодом команды ячеек памяти. Длина команды, а также то, способна ли она изменить естественный порядок выполнения команд программы, выясняются в ходе ранее упоминавшегося предварительного декодирования. Если извлеченная команда способна изменить последовательность выполнения программы (команда условного или безусловного перехода, вызова процедуры и т.п), процесс формирования адреса следующей команды переносится на этап исполнения операции. В силу сказанного, в ряде ЭВМ рассматриваемый этап цикла команды следует не за выборкой команды, а находится в конце цикла.
Этап декодирования команды После выборки команды она должна быть декодирована, для чего ЦП расшифровывает находящийся в РК код команды. В результате декодирования выясняются следующие вопросы: находится ли в РК полный код команды или требуется дозагрузка остальных слов команды; какие последующие действия нужны для выполнения данной команды; если команда использует операнды, то откуда они должны быть взяты (номер регистра или адрес ячейки основной памяти); если команда формирует результат, то куда этот результат должен быть направлен. Ответы на два первых вопроса дает расшифровка кода операции, результатом которой может быть унитарный код, где каждый разряд соответствует одной из команд. На практике вместо унитарного кода могут встретиться самые разнообразные формы представления результатов декодирования, например адрес ячейки специальной управляющей памяти, где хранится первая микрокоманда микропрограммы для реализации указанной в команде операции. Полное выяснение всех аспектов команды, помимо расшифровки кода операции, требует также анализа адресной части команды, включая поле способа адресации. По результатам декодирования производится подготовка электронных схем ЭВМ к выполнению предписанных командой действий.
Этап вычисления адресов операндов Этап имеет место, если в процессе декодирования команды выясняется, что команда использует операнды. Если операнды размещаются в основной памяти, осуществляется вычисление их исполнительных адресов, с учетом указанного в команде способа адресации. Так, в случае индексной адресации для получения исполнительного адреса производится суммирование содержимого адресной части команды и содержимого индексного регистра.
Этап выборки операндов Вычисленные на предыдущем этапе исполнительные адреса используются для считывания операндов из памяти и занесения в определенные регистры процессора. Например, в случае арифметической команды операнд после извлечения из памяти может быть загружен во входной регистр АЛУ. Однако чаще операнды предварительно заносятся в специальные вспомогательные регистры процессора, а их пересылка на вход АЛУ происходит на этапе исполнения операции.
Этап исполнения операции На этом этапе реализуется указанная в команде операция. В силу различия сущности каждой из команд ЭВМ, содержание этого этапа сугубо индивидуально.
Этап формирования признака результата На этом этапе определяется, каким получился результат операции. Результат может быть положительным, отрицательным, равным нулю и т.п. Сформированный признак заносится в регистр признака результата (РПР) для дальнейшего использования устройством управления.
Этап записи результата Этап записи результата присутствует в цикле тех команд, которые предполагают занесение результата в регистр или ячейку основной памяти. Фактически его можно считать частью этапа исполнения, особенно для тех команд, которые помещают результат сразу в несколько мест.
Машинный цикл с косвенной адресацией Многие команды предполагают чтение операндов из памяти или запись в память. В простейшем случае в адресном поле таких команд явно указывается исполнительный адрес соответствующей ячейки ОП. Однако часто используется и другой способ указания адреса, когда адрес операнда хранится в какойто ячейке памяти, а в команде указывается адрес ячейки, содержащей адрес операнда. Как уже отмечалось ранее, подобный прием называется косвенной адресацией. Чтобы прочитать или записать операнд, сначала нужно извлечь из памяти его адрес и только после этого произвести нужное действие (чтение или запись операнда), иными словами, требуется выполнить два обращения к памяти. Это, естественно, отражается и на цикле команды, в котором появляется косвенная адресация. Этап косвенной адресации можно отнести к этапу вычисления адресов операндов, поскольку его сущность сводится к определению исполнительного адреса операнда. Иными словами, содержимое адресного поля команды в регистре команд используется для обращения к ячейке ОП, в которой хранится адрес операнда, после чего извлеченный из памяти исполнительный адрес операнда помещается в адресное поле регистра команды на место косвенного адреса. Дальнейшее выполнение команды протекает стандартным образом.
Машинный цикл с прерыванием Практически во всех ЭВМ предусмотрены средства, благодаря которым модули ввода/вывода (и не только они) могут прервать выполнение текущей программы для внеочередного выполнения другой программы, с последующим возвратом к прерванной. Первоначально прерывания были введены для повышения эффективности вычислений при работе с медленными периферийными устройствами. Положим, что процессор пересылает данные на принтер, используя стандартный цикл команды. После каждой операции записи ЦП будет вынужден делать паузу в ожидании подтверждения от принтера об обработке символа. Длительность этой паузы может составлять сотни и тысячи циклов команды. Ясно, что такое использование ЦП очень неэффективно. В случае прерываний, пока протекает операция ввода/вывода, ЦП способен выполнять другие команды. В упрощенном виде процедуру прерывания можно описать следующим образом. Объект, требующий внеочередного обслуживания, выставляет на соответствующем входе ЦП сигнал запроса прерывания (ЗП). ЗП могут возникать, как в самой ЭВМ, так и в её внешней среде. К первым относятся:
ошибки в работе аппаратуры;
переполнение разрядной сетки;
попытка деления на «0»;
выход из установленной для данной программы области памяти;
затребование периферийным устройствам операции ввода/ вывода.
К внешним запросам относятся:
запрос прерывания от другой ЭВМ;
запрос от различного рода датчиков.
Перед переходом к очередному циклу команды процессор проверяет этот вход на наличие запроса. Обнаружив запрос, ЦП запоминает информацию, необходимую для продолжения нормальной работы после возврата из прерывания, и переходит к выполнению прерывающей программы. По завершении обработки прерывания ЦП восстанавливает состояние прерванного процесса, используя запомненную информацию, и продолжает выполнение прерванной программы. Описанный процесс иллюстрирует рис. 22.1.
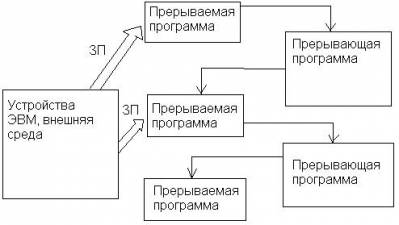 Рис.
22.1. Передача управления при прерываниях
Рис.
22.1. Передача управления при прерываниях
В терминах цикла команды сказанное выглядит так. Для учета прерываний к циклу команды добавляется этап прерывания, в ходе которого процессор проверяет, не поступил ли запрос прерывания. Если запроса нет, ЦП переходит к этапу выборки следующей команды программы. При наличии запроса процессор:
Приостанавливает выполнение текущей программы и запоминает содержимое всех регистров, которые будут использоваться программой обработки прерывания. Это называется сохранением слова состояния программы (ССП). В первую очередь необходимо сохранить содержимое счетчика команд, аккумулятора и регистра признаков. ССП обычно сохраняется в стеке.
Заносит в счетчик команд начальный адрес программы обработки прерывания. Теперь процессор продолжает с этапа выборки первой команды обработчика прерывания. Обработчик (обычно он входит в состав операционной системы) определяет природу прерывания и выполняет необходимые действия. Когда программа обработки прерывания завершается, процессор может возобновить выполнение прерванной программы с точки, где она была прервана. Для этого он восстанавливает ССП (содержимое СК и других регистров) и начинает с цикла выборки очередной команды прерванной программы.
Во всех компьютерах предусмотрен механизм, с помощью которого различные устройства (ввода-вывода, памяти) могут прервать нормальную работу процессора. Основные общепринятые классы прерываний перечислены в табл. 1.1.

Прерывания в основном предназначены для повышения эффективности работы. Например, большинство устройств ввода-вывода работают намного медленнее, чем процессор. Предположим, что процессор передает данные на принтер по схеме, показанной рис. 1.2. После каждой операции процессор вынужден делать паузу и ждать, пока принтер не примет данные. Длительность этой паузы может быть в сотни и даже тысячи раз больше длительности цикла команды, в которой участвуют обращения к памяти. Ясно, что подобное использование процессора является неэффективным. Такое положение дел проиллюстрировано на рис. 1.5,а. Программа пользователя содержит ряд вызовов процедуры записи WRITE, в промежутках между которыми расположены другие команды. В отрезках 1, 2 и 3 находятся последовательности команд кода, в которых не используется ввод-вывод. При вызове процедуры WRITE управление передается системной утилите ввода-вывода, которая выполняет соответствующие операции. Программа ввода-вывода состоит из трех частей. Последовательность команд, обозначенных на рисунке цифрой 4, которые служат для подготовки к собственно операциям ввода-вывода. В эту последовательность могут входить копирование выводимых данных в специальный буфер и подготовка набора параметров, необходимых для управления устройством. Собственно команды ввода-вывода. Если программа не использует прерываний, ей следует ждать, пока устройство ввода-вывода не выполнит требуемые операции (или периодически проверять его состояние путем опроса). При этом программе не остается ничего другого, как просто ждать, постоянно проверяя, завершилась ли операция ввода-вывода. Последовательность команд, обозначенных на рисунке цифрой 5, которые служат для завершения операции. Эта последовательность может содержать в себе установку флагов, свидетельствующих об успешном или неудачном завершении операции.
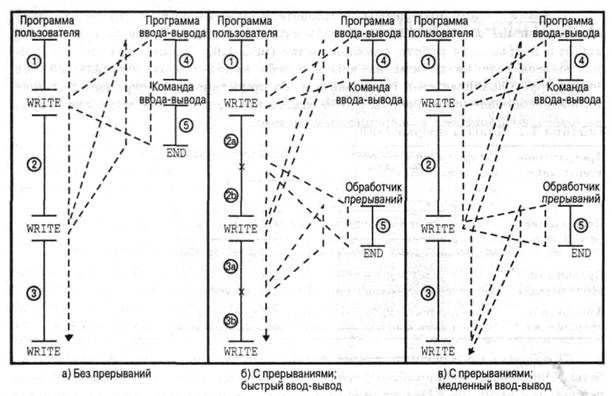
Из-за того что для выполнения операции ввода-вывода может потребоваться сравнительно длительный промежуток времени, программа замедляет работу, ожидая завершения операции. Таким образом, там, где встречается вызов WRITE, производительность программы существенно уменьшается.
Диаграмма состояний цикла команды Все вышеизложенное можно подытожить в виде рис. 2.18, где содержание цикла команды описано с помощью диаграммы состояний. На этой диаграмме цикл команды представляется в виде последовательности состояний. Для каждой конкретной команды некоторые состояния могут быть нулевыми, а некоторые другие могут неоднократно повторяться. Полный цикл команды может включать в себя следующие состояния:
Вычисление адреса команды. Определение исполнительного адреса команды, которая должна выполняться следующей.
Выборка команды. Чтение команды из ячейки памяти и занесение ее в РК.
Декодирование команды. Анализ команды с целью выяснения типа подлежащей выполнению операции и операндов.
Вычисление адреса операнда. Определение исполнительного адреса операнда, если операция предполагает обращение к операнду, хранящемуся в памяти или же доступному посредством ввода.
Выборка операнда. Выборка операнда из памяти или его ввод с устройства ввода.
Операция с данными. Выполнение операции, указанной в команде.
Формирование признака результата. Определение признака выполненной операции.
Запись результата. Запись результата в память или вывод на устройство вывода.
Состояния
в верхней части диаграммы описывают
обмен между ЦП и памятью либо между ЦП
и модулем ввода/вывода. Состояния в
нижней части обозначают только внутренние
операции ЦП. Вычисление адреса операнда
встречается дважды, поскольку команда
может включать в себя чтение, запись
или то и другое, однако действия,
выполняемые в этом состоянии, в обоих
случаях одни и те же, поэтому используется
один и тот же идентификатор
состояния.
Следует отметить, что
диаграмма допускает множественные
операнды и результаты, как того требуют
некоторые команды. Кроме того, в ряде
ЭВМ единственная команда может определять
операцию над вектором (одномерным
массивом чисел) или строкой (одномер
ным массивом символов), что требует
повторяющихся операций выборки и/или
записи.
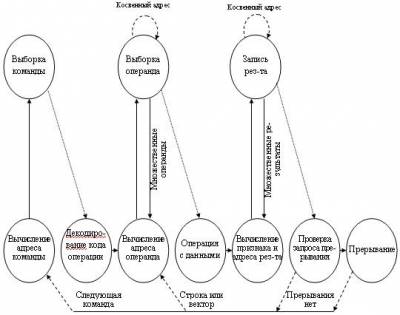
Рис. 22.2. Диаграмма состояний цикла команды
Диаграмма отражает также возможность этапов прерывания и косвенной адресации.
Операционные системы (предназначение и функции операционных систем, предоставляемые сервисы, простые пакетные операционные системы, многозадачные пакетные операционные системы, операционные системы, работающие в режиме разделения времени, причины развития операционных систем)
Операцио́нная систе́ма, сокр. ОС (англ. operating system, OS) — комплекс управляющих и обрабатывающих программ, которые, с одной стороны, выступают как интерфейс между устройствами вычислительной системы и прикладными программами, а с другой стороны — предназначены для управления устройствами, управления вычислительными процессами, эффективного распределения вычислительных ресурсов между вычислительными процессами и организации надёжных вычислений. Это определение применимо к большинству современных операционных систем общего назначения.
В логической структуре типичной вычислительной системы операционная система занимает положение между устройствами с их микроархитектурой, машинным языком и, возможно, собственными (встроенными) микропрограммами — с одной стороны — и прикладными программами с другой.
Разработчикам программного обеспечения операционная система позволяет абстрагироваться от деталей реализации и функционирования устройств, предоставляя минимально необходимый набор функций (см.: интерфейс программирования приложений).
В большинстве вычислительных систем операционная система является основной, наиболее важной (а иногда и единственной) частью системного программного обеспечения. С 1990-х годов наиболее распространёнными операционными системами являются системы семейства Windows и системы класса UNIX (особенно Linux и Mac OS).
Основные функции:
Исполнение запросов программ (ввод и вывод данных, запуск и остановка других программ, выделение и освобождение дополнительной памяти и др.).
Загрузка программ в оперативную память и их выполнение.
Стандартизованный доступ к периферийным устройствам (устройства ввода-вывода).
Управление оперативной памятью (распределение между процессами, организация виртуальной памяти).
Управление доступом к данным на энергонезависимых носителях (таких как жёсткий диск, оптические диски и др.), организованным в той или иной файловой системе.
Обеспечение пользовательского интерфейса.
Сохранение информации об ошибках системы.
Дополнительные функции:
Параллельное или псевдопараллельное выполнение задач (многозадачность).
Эффективное распределение ресурсов вычислительной системы между процессами.
Разграничение доступа различных процессов к ресурсам.
Организация надёжных вычислений (невозможности одного вычислительного процесса намеренно или по ошибке повлиять на вычисления в другом процессе), основана на разграничении доступа к ресурсам.
Взаимодействие между процессами: обмен данными, взаимная синхронизация.
Защита самой системы, а также пользовательских данных и программ от действий пользователей (злонамеренных или по незнанию) или приложений.
Многопользовательский режим работы и разграничение прав доступа (см.: аутентификация, авторизация).
Компоненты операционной системы:
Загрузчик
Ядро
Командный процессор (интерпретатор)
Драйверы устройств
Интерфейс
Операционные системы различаются особенностями реализации алгоритмов управления ресурсами компьютера, областями использования. Так, в зависимости от алгоритма управления процессором, операционные системы делятся на:
Однозадачные и многозадачные
Однопользовательские и многопользовательские
Однопроцессорные и многопроцессорные системы
Локальные и сетевые.
По числу одновременно выполняемых задач операционные системы делятся на два класса:
Однозадачные (MS DOS)
Многозадачные (OS/2, Unix, Windows)
В зависимости от областей использования многозадачные ОС подразделяются на три типа:
Системы пакетной обработки (ОС ЕС)
Системы с разделением времени (Unix, Linux, Windows)
Системы реального времени (RT11)
Приведем краткий список сервисов, предоставляемых типичными операционными системами. Разработка программ. Содействуя программисту при разработке программ, операционная система предоставляет ему разнообразные инструменты и сервисы, например редакторы или отладчики. Обычно эти сервисы реализованы в виде программ-утилит, которые поддерживаются операционной системой, хотя и не входят в ее ядро. Такие программы называются инструментами разработки приложений.
Исполнение программ. Для запуска программы требуется выполнить ряд действий. Следует загрузить в основную память команды и данные, инициализировать устройства ввода-вывода и файлы, а также подготовить другие ресурсы. Операционная система выполняет всю эту рутинную работу вместо пользователя.
Доступ к устройствам ввода-вывода. Для управления работой каждого устройства ввода-вывода нужен свой особый набор команд или контрольных сигналов. Операционная система предоставляет пользователю единообразный интерфейс, который скрывает все эти детали, и обеспечивает программисту доступ к устройствам ввода-вывода с помощью простых команд чтения и записи. Контролируемый доступ к файлам. При работе с файлами управление со стороны операционной системы предполагает не только глубокое понимание природы устройств ввода-вывода (дисковода, лентопротяжного устройства), но и знание структур данных, записанных в файлах. Многопользовательские операционные системы, кроме того, могут обеспечивать работу механизмов защиты при обращении к файлам.
Системный доступ. Операционная система управляет доступом к совместно используемой или общедоступной вычислительной системе в целом, а также к отдельным системным ресурсам. Она должна обеспечивать защиту ресурсов и данных от несанкционированного использования, а также разрешать конфликтные ситуации.
Обнаружение ошибок и их обработка. При работе компьютерной системы могут происходить разнообразные сбои. К их числу относятся внутренние и внешние ошибки, возникшие в аппаратном обеспечении (например, ошибки памяти, отказ или сбой устройств). Возможны и различные программные ошибки, такие, как арифметическое переполнение, попытка обратиться к ячейке памяти, доступ к которой запрещен, или невозможность выполнения запроса приложения. В каждом из этих случаев операционная система должна выполнить действия, минимизирующие влияние ошибки на работу приложения. Реакция операционной системы на ошибку может быть различной — от простого сообщения об ошибке до аварийного останова программы, вызвавшей ее.
Учет использования ресурсов. Хорошая операционная система должна иметь средства учета использования различных ресурсов и отображения параметров производительности. Эта информация крайне важна в любой системе, особенно в связи с необходимостью дальнейших улучшений и настройки вычислительной системы для повышения ее производительности.
Последовательная обработка данных.
В самых первых компьютерах, в период от конца 40-х до средины 50-х годов, программы непосредственно взаимодействовали с аппаратным обеспечением машины; операционных систем в то время еще не было. Эти компьютеры управлялись с пульта управления, состоящего из сигнальных ламп, тумблеров, некоторого устройства для ввода данных и принтера. Программы, машинные коды и данные загружались через устройство ввода данных (например, устройство ввода с перфокарт). Если из-за ошибки происходил останов программы, о возникновении сбойной ситуации свидетельствовали аварийные сигнальные лампы. Чтобы определить причину ошибки, программист должен был проверить состояние регистров процессора и основной памяти. Если программа успешно завершала свою работу, ее выходные данные распечатывались на принтере. Ранние системы имели две основные проблемы: Расписание работы. На большинстве машин нужно было предварительно заказать машинное время, записавшись в специальный график. Обычно пользователь мог заказать время, кратное некоторому периоду, например, получасу. Тогда, записавшись на 1 час, он мог закончить работу за 45 минут, что приводило к простою компьютера. С другой стороны, если пользователь не укладывался в отведенное время, он должен был прекращать работу, прежде чем задача завершит выполнение. Время подготовки к работе. Для запуска каждой программы, называемой заданием (job), нужно было загрузить в память компилятор и саму программу, обычно составленную на языке высокого уровня (исходный текст), сохранить скомпилированную программу (объектный код), а затем загрузить и скомпоновать объектный код с библиотечными функциями. Для каждого из этих этапов могли понадобиться установка и съем магнитных лент или загрузка колоды перфокарт. При возникновении фатальной ошибки беспомощному пользователю не оставалось ничего другого, как начинать весь подготовительный процесс заново. Таким образом, значительное время затрачивалось лишь на то, чтобы подготовить программу к собственно исполнению. Такой режим работы можно назвать последовательной обработкой данных. Это название отражает тот факт, что пользовательские программы исполнялись на компьютере последовательно. Спустя некоторое время в попытке повысить эффективность последовательной обработки были разработаны различные системные инструменты. К ним относятся библиотеки функций, редакторы связей, загрузчики, отладчики и драйверы ввода-вывода, существующие в виде программного обеспечения, общедоступного для всех пользователей.
Простые пакетные системы.
Первые машины были очень дорогими, поэтому было важно использовать их как можно эффективнее. Простои, происходившие из-за несогласованности расписания, а также время, затраченное на подготовку задачи, — все это обходилось слишком дорого; эти непроизводительные затраты были непозволительной роскошью. Чтобы повысить эффективность работы, была предложена концепция пакетной операционной системы. Похоже, первые пакетные операционные системы (и вообще первые операционные системы какого бы то ни было типа) были разработаны в средине 50-х годов в компании General Motors для машин IBM 701 [WEIZ81]. Впоследствии эта концепция была усовершенствована и внедрена определенным кругом пользователей на IBM 704. В начале 60-х годов некоторые поставщики разработали пакетные операционные системы для своих компьютеров. Одной из заметных систем того времени является IBSYS фирмы IBM, разработанная для компьютеров 7090/7094 и оказавшая значительное влияние на другие системы. Главная идея, лежащая в основе простых пакетных схем обработки, состоит в использовании программы, известной под названием монитор (monitor). Используя операционную систему такого типа, пользователь не имеет непосредственного доступа к машине. Вместо этого он передает свое задание на перфокартах или магнитной ленте оператору компьютера, который собирает разные задания в пакеты и помещает их в устройство ввода данных. Так они передаются монитору. Каждая программа составлена таким образом, что при завершении ее работы управление переходит к монитору, который автоматически загружает следующую программу. Чтобы понять работу этой схемы, рассмотрим ее с точки зрения монитора и процессора. Работа схемы с точки зрения монитора. Монитор управляет последовательностью событий. Чтобы это было возможно, большая его часть должна всегда находиться в основной памяти и быть готовой к работе (рис. 2.3). Эту часть монитора называют резидентным монитором. Оставшуюся часть составляют утилиты и общие функции, которые загружаются в виде подпрограмм, вызываемых программой пользователя в начале выполнения каждого задания (если они для него требуются). Монитор считывает с устройства ввода данных (обычно это устройство ввода с перфокарт или магнитная лента) по одному заданию. При этом текущее задание размещается в области памяти, предназначенной для программ пользователя, и ему передается управление. По завершении задания оно возвращает управление монитору, который сразу же начинает считывать следующее задание. Результат исполнения каждого задания направляется на устройство вывода, например принтер. Работа схемы с точки зрения процессора. Допустим, в некоторый момент времени процессор исполняет команды, которые находятся в той части основной памяти, которую занимает монитор. Это приводит к тому, что в другую область памяти считывается новое задание. После того как задание полностью считано, монитор отдает процессору команду перехода, по которой он должен начать исполнение программы пользователя. Процессор переходит к обработке программы пользователя и выполняет ее команды до тех пор, пока не дойдет до конца или пока не возникнет сбойная ситуация. В любом из этих двух случаев следующей командой, которую процессор извлечет из памяти, будет команда монитора. Таким образом, фраза "контроль передается заданию" означает, что процессор перешел к извлечению и выполнению команд программы пользователя. Фраза же "контроль возвращается монитору" означает, что теперь процессор извлекает из памяти и выполняет команды монитора.
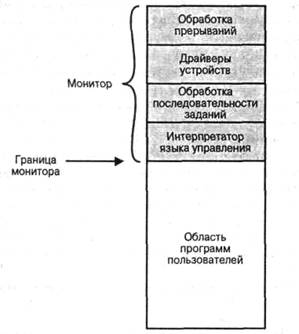
Как видите, монитор решает проблему разработки графика. Задания в пакетах выстраиваются в очередь и выполняются без простоев настолько быстро, насколько это возможно. Кроме того, монитор помогает в подготовке программы к исполнению. В каждое задание включаются простые команды языка управления заданиями (job control language — JCL). Это специальный тип языка программирования, используемый для того, чтобы отдавать команды монитору. Рассмотрим простой пример, в котором нужно принять на обработку программу пользователя, составленную на языке FORTRAN, и дополнительные данные, используемые этой программой. Все команды языка FORTRAN и данные находятся на отдельных перфокартах или в отдельных записях на магнитной ленте. Каждое задание, кроме операторов языка FORTRAN и данных, содержит команды управления заданием, каждая из которых начинается знаком $. Формат задания в целом выглядит следующим образом:
Чтобы выполнить это задание, монитор читает строку $FTN и загружает с запоминающего устройства большой емкости (обычно это лента) компилятор соответствующего языка. Компилятор преобразует программу пользователя в объектный код, который записывается в память или на запоминающее устройство. Если этот код заносится в память, то операция называется "компиляция, загрузка и запуск". Если же он записывается на магнитную ленту, то нужна дополнительная команда $LOAD. Монитор, к которому вернулось управление после компиляции, читает эту команду и обращается к загрузчику, который загружает объектную программу в память (на место компилятора) и передает ей управление. В таком режиме различные подсистемы совместно используют один и тот же участок основной памяти, хотя в каждый момент времени работает только одна из этих подсистем. Во время выполнения программы пользователя по каждой команде ввода считывается только одна строка данных. Команда ввода программы пользователя обращается к подпрограмме ввода, которая является составной частью операционной системы. Подпрограмма ввода проверяет, не произошло ли случайное считывание строки языка JCL. Если это произошло, управление передается монитору. При успешном (или неудачном) завершении задания пользователя монитор проверяет строки задания, пока не дойдет до строки с командой на языке управления, что защищает систему от программ, в которых оказалось слишком много или слишком мало строк с данными (иначе очередным заданием могли оказаться излишние данные предыдущего задания, или часть нового задания могла бы рассматриваться как недостающие данные предыдущего задания). Таким образом, монитор, или пакетная операционная система, — это обычная компьютерная программа. Ее работа основана на способности процессора выбирать команды из различных областей основной памяти; при этом происходит передача и возврат управления. Желательно также использование и других возможностей аппаратного обеспечения. Защита памяти. Во время работы программы пользователя она не должна носить изменения в область памяти, в которой находится монитор. Если е такая попытка предпринята, аппаратное обеспечение процессора должно обнаружить ошибку и передать управление монитору. Затем монитор снимет задачу с выполнения, распечатает сообщение об ошибке и загрузит следующее задание. Таймер. Таймер используется для того, чтобы предотвратить ситуацию, когда одна задача захватит безраздельный контроль над системой. Таймер выставляется в начале каждого задания. По истечении определенного промежутка времени программа пользователя останавливается и управление передается монитору. Привилегированные команды. Некоторые команды машинного уровня имеют повышенные привилегии и могут исполняться только монитором. Если процессор натолкнется на такую команду во время исполнения программы пользователя, возникнет ошибка, при которой управление будет передано монитору. В число привилегированных команд входят команды ввода-вывода; это значит, что все устройства ввода-вывода контролируются монитором. Это, например, предотвращает случайное чтение программой пользователя команд управления, относящихся к следующему заданию. Если программе пользователя нужно произвести ввод-вывод, она должна запросить для выполнения этих операций монитор. Прерывания. В первых моделях компьютеров этой возможности не было. Она придает операционной системе большую гибкость при передаче управления программе пользователя и его возобновлении. Конечно, операционную систему можно разработать и без учета описанных выше возможностей. Однако поставщики компьютеров скоро поняли, что это приведет к хаосу, поэтому даже сравнительно простые пакетные операционные системы обращались к таким возможностям аппаратного обеспечения. При работе пакетных операционных систем машинное время распределялось между исполнением программы пользователя и монитора. При этом в жертву приносились два вида ресурсов: монитор занимал некоторую часть оперативной памяти, им же потреблялось некоторое машинное время. И то и другое приводило к непроизводительным издержкам. Несмотря на это, простые пакетные системы существенно повышали эффективность использования компьютера.
Многозадачные пакетные системы.
Процессору часто приходилось простаивать даже при автоматическом выполнении заданий под управлением простой пакетной операционной системы. Проблема заключается в том, что устройства ввода-вывода работают намного медленнее, чем процессор. На рис. 2.4 представлены соответствующие расчеты, выполненные для программы, которая обрабатывает файл с записями, причем для обработки одной записи требуется в среднем 100 машинных команд. В этом примере 96% всего времени процессор ждет, пока устройства ввода-вывода закончат передачу данных в файл и из него. На рис. 2.5,а показана такая ситуация для одной программы. Некоторое время процессор исполняет команды; затем, дойдя до команды ввода-вывода, он должен подождать, пока она не закончится. Только после этого процессор сможет продолжить работу.

Рис. 2.4. Пример использования системы
Эффективность использования процессора можно повысить. Мы знаем, что памяти должно хватить, чтобы разместить в ней операционную систему (резидентный монитор) и программу пользователя. Представим, что в памяти достаточно места для операционной системы и двух программ пользователя. Теперь, когда одно из заданий ждет завершения операций ввода-вывода, процессор может переключиться на другое задание, для которого в данный момент ввод-вывод, скорее всего, не требуется (рис. 2.5,6). Более того, если памяти достаточно для размещения большего количества программ, то процессор может выполнять их параллельно, переключаясь с одной на другую (рис. 2.5,в). Такой режим известен как многозадачность (multiprogramming) и является основной чертой современных операционных систем.

в) Многозадачность — три программы
Рис. 2.5. Пример многозадачности
Приведем простой пример, иллюстрирующий преимущества многозадачности. Рассмотрим компьютер, имеющий 256 К слов памяти, не используемых операционной системой, диск, терминал и принтер. На обработку одновременно приняты три программы, JOB1, JOB2 и JOB3, атрибуты которых перечислены в табл. 2.1. Предположим, что для выполнения заданий JOB2 и JOB3 использование процессора минимально, и задание JOB3 постоянно обращается к диску и принтеру. В простой среде с пакетной обработкой эти задания выполняются последовательно. Для завершения JOB1 требуется 5 мин. Задание JOB2 должно ждать, пока пройдут эти 5 мин, после чего оно выполняется в течение 15 мин. По истечении 20 мин начинает работу задание JOB3; его выполнение заканчивается через 30 мин после того, как оно было принято на обработку. Средний процент использования ресурсов, производительность и время отклика показаны в столбце табл. 2.2, соответствующем однозадачности, а на рис. 2.6,а показано использование различных устройств в этом режиме. Очевидно, что эффективность использования всех ресурсов, усредненная по всему периоду времени (30 мин), является крайне низкой.
Таблица 2.1. Свойства трех программ-примеров
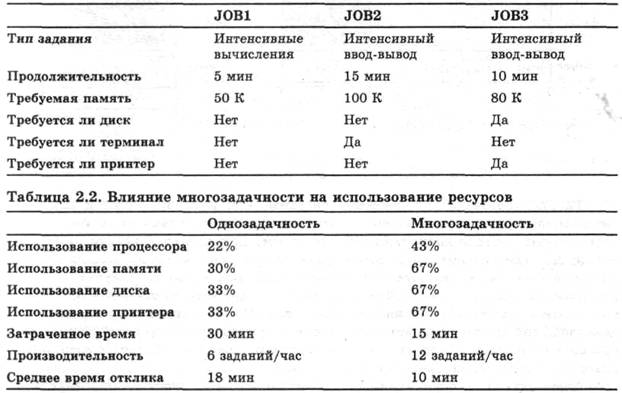
Теперь предположим, что задания выполняются одновременно под управлением многозадачной операционной системы. Из-за того что они используют разные ресурсы, их совместное выполнение на компьютере длится минимальное время (при условии, что заданиям J0B2 и J0B3 предоставляется достаточно процессорного времени для поддержки осуществляемого ими ввода и вывода в активном состоянии). Для выполнения задания J0B1 потребуется 5 мин, но к этому времени задание J0B2 будет выполнено на треть, а задание J0B3 — на половину. Все три задания будут выполнены через 15 мин. Если посмотреть на столбец табл. 2.2, соответствующий многозадачному режиму, его преимущества станут очевидны, как и из гистограммы, приведенной на рис. 2.6,6.
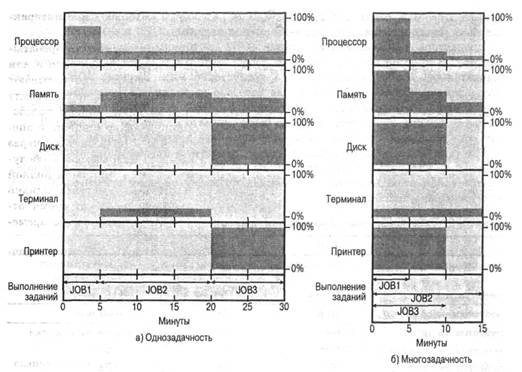
Работа многозадачной пакетной системы, как и работа простой пакетной системы, базируется на некоторых аппаратных особенностях компьютера. Наиболее значительными дополнениями, полезными для многозадачности, являются аппаратное обеспечение, поддерживающее прерывания ввода-вывода, и прямой доступ к памяти. Используя эти возможности, процессор генерирует команду ввода-вывода для одного задания и переходит к другому на то время, пока контроллером устройства выполняется ввод-вывод. После завершения операции ввода-вывода процессор получает прерывание, и управление передается программе обработки прерываний из состава операционной системы. Затем операционная система передает управление другому заданию. Многозадачные операционные системы сложнее систем последовательной обработки заданий. Для того чтобы можно было обрабатывать несколько заданий одновременно, они должны находиться в основной памяти, а для этого требуется система управления памятью. Кроме того, если к работе готовы несколько заданий, процессор должен решить, какое из них следует запустить, для чего необходим некоторый алгоритм планирования.
Системы, работающие в режиме разделения времени.
Использование многозадачности в пакетной обработке может привести к существенному повышению эффективности. Однако для многих заданий желательно обеспечить такой режим, в котором пользователь мог бы непосредственно взаимодействовать с компьютером. В самом деле, во многих случаях интерактивный режим является обязательным условием работы. Многозадачность не только позволяет процессору одновременно обрабатывать несколько заданий в пакетном режиме, но может быть использована и для обработки нескольких интерактивных заданий. Такую организацию называют разделением времени, потому что процессорное время распределяется между различными пользователями. В системе разделения времени несколько пользователей одновременно получают доступ к системе с помощью терминалов, а операционная система чередует исполнение программ каждого пользователя через малые промежутки времени. Таким образом, если нужно одновременно обслужить n пользователей, каждому из них предоставляется лишь 1/и часть полной скорости компьютера, не считая затрат на работу операционной системы. Однако, принимая во внимание относительно медленную реакцию человека, время отклика на компьютере с хорошо настроенной системой будет сравнимо со временем реакции пользователя. Как пакетная обработка, так и разделение времени используют многозадачность. Основные отличия этих двух режимов перечислены в табл. 2.3.
Таблица 2.3. Пакетная многозадачность и разделение времени

Одной из первых операционных систем разделения времени была система CTSS (Compatible Time-Sharing System) [CORB62], разработанная в Массачусетском технологическом институте группой, известной как Project MAC. Первоначально система была разработана для IBM 709, а затем перенесена на IBM 7094. По сравнению с более поздними системами, CTSS была довольно примитивна. Она работала на машине с основной памятью емкостью 32000 36-битовых слов, из которых 5000 слов занимал монитор. Когда управление должно было быть передано очередному интерактивному пользователю, его программа и данные загружались в остальные 27000 слов основной памяти. Программа всегда загружалась так, что ее начало находилось в ячейке номер 5000, что упрощало управление как монитором, так и памятью. Приблизительно через каждые 0.2 с системные часы генерировали прерывание. При каждом прерывании таймера управление передавалось операционной системе, и процессор мог перейти в распоряжение другого пользователя. Таким образом, данные текущего пользователя через регулярные интервалы времени выгружались, а вместо них загружались другие. Перед считыванием программы и данных нового пользователя программа и данные предыдущего пользователя записывались на диск для сохранения до дальнейшего выполнения. Впоследствии, когда очередь этого пользователя наступит снова, код и данные его программы будут восстановлены в основной памяти. Чтобы уменьшить обмен с диском, содержимое памяти, занимаемое данными пользователя, записывается на него лишь в том случае, если для загрузки новой программы не хватает места. Этот принцип проиллюстрирован на рис. 2.7. Предположим, что всего работает четыре пользователя, которым нужны следующие объемы памяти:
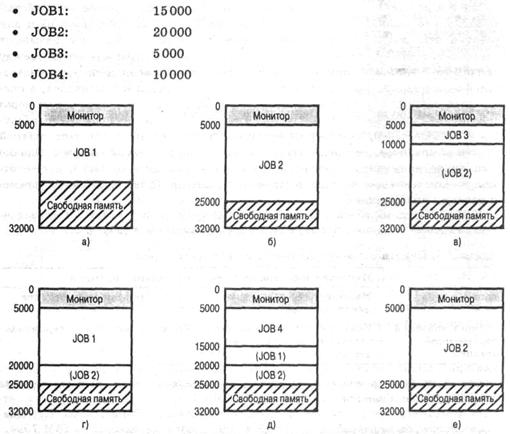
Рис. 2.7. Работа CTSS
Сначала монитор загружает задание JOB1 и передает ему управление (о). Затем он принимает решение передать управление заданию JOB2. Из-за того, что JOB2 занимает больше памяти, чем JOB1, сначала нужно сохранить данные JOB1, а затем можно загружать JOB2 (б). Затем для обработки загружается JOB3. Но поскольку это задание меньше, чем JOB2, часть задания JOB2 может оставаться в основной памяти, сокращая время записи на диск (в). Позже монитор вновь передает управление заданию JOB1. Чтобы загрузить его в память, на диск необходимо записать еще часть задания JOB2 (г). При загрузке задания JOB4 в памяти остается часть заданий JOB1 и JOB2 (д). Если теперь будет активизировано задание JOB1 или JOB2, то потребуется лишь частичная его загрузка. Следующим в этом примере запускается задание JOB2. Для этого требуется, чтобы JOB4 и оставшаяся в памяти часть JOB1 были записаны на диск, а в память была считана недостающая часть JOB2. Подход CTSS по сравнению с современными принципами разделения времени является примитивным, но вполне работоспособным. Его простота позволяла использовать монитор минимальных размеров. Из-за того что задание всегда загружалось в одно и то же место в памяти, не было необходимости применять во время загрузки методы перемещения (которые рассматриваются позже). Необходим был лишь метод записи, позволяющий уменьшить активность диска. Работая на машине 7094, CTSS могла обслуживать до 32 пользователей. С появлением разделения времени и многозадачности перед создателями операционных систем появилось много проблем. Если в памяти находится несколько заданий, их нужно защищать друг от друга, иначе одно задание может, например, изменить данные другого задания. Если в интерактивном режиме работают несколько пользователей, то файловая система должна быть защищена, чтобы к каждому конкретному файлу доступ был только у определенных пользователей. Нужно разрешать конфликтные ситуации, возникающие при работе с различными ресурсами, например с принтером и устройствами хранения данных.
Большинство операционных систем постоянно развиваются. Происходит это в силу следующих причин:
а) обновление и возникновение новых видов аппаратного обеспечения;
б) новые сервисы. В операционной системе могут быть добавлены новые инструменты для контроля и оценки производительности, чтобы поддержать высокую эффективность работы, с имеющимся инструментарием пользователя;
в) исправление. В каждой операционной системе есть ошибки. Время от времени они обнаруживаются и исправляются. Необходимость регулярного изменения операционных систем, накладываются определённые ограничения на устройство. Очевидно, что эти системы должны иметь модульную конструкцию, чётко определённую взаимодействием модулей. Для больших программ важную роль играет хорошее и полное документирование.